







1. 概述
MapReduce是Hadoop内提供的分布式计算的组件,基于它写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理上T级别的数据集。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上。
MapReduce提供了2个编程接口,Map和Reduce。其中Map接口提供了分散的功能,由服务器分布式对数据进行处理;Reduce接口提供聚合功能,将分布式处理的结果汇总统计
2. 编程思想
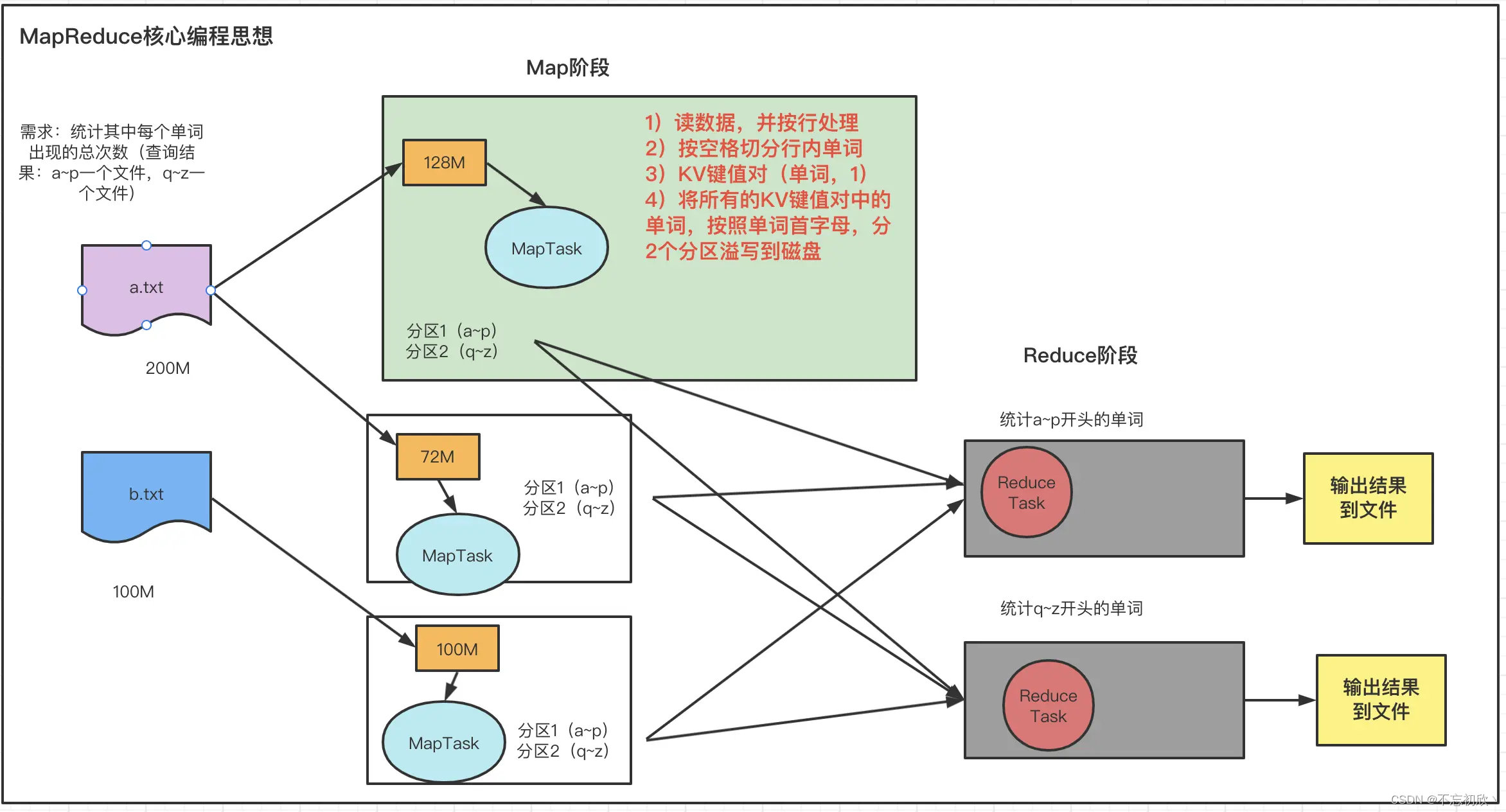
- MapReduce运行程序一般需要分成2个阶段:map阶段和reduce阶段。
- Map阶段的并发Map Task,完全并行运行,互不相干
- Reduce阶段的并发ReduceTask,完全互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出
MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行
3. 执行原理
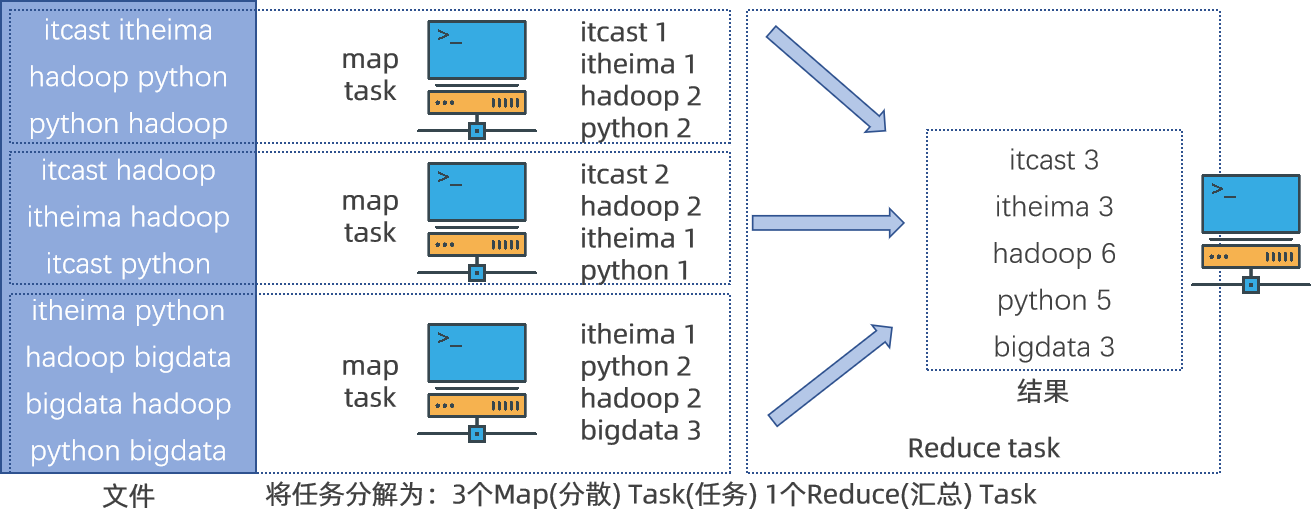
如上图,一个Map/Reduce 作业(job) 把输入的数据文件切分为若干独立的数据块,由 map任务(task)以完全并行的方式处理它们。框架会对map的输出先进行排序, 然后把结果输入给reduce任务进行聚合操作。通常作业的输入和输出都会被存储在文件系统中。 整个框架负责任务的调度和监控,以及重新执行已经失败的任务。
- 首先将需要执行的需求,分解成多个Map Task和Reduce Task
- 将Map Task 和 Reduce Task分配到对应的服务器上去执行
4. 优缺点
优点:
- 良好扩展性:可以动态增加服务器,解决计算资源不够问题。
- 高容错性:任何一台机器挂掉,可以将任务转移到其他节点。
- 适合海量数据计算(TB、PB)几千台服务器共同计算。
缺点:
- 计算过程存在大量的网络IO和磁盘IO操作,因此处理速度比较慢,只能处理分钟、小时级别任务
- 不擅长DAG有向无环图
- 编程复杂,没有直接写SQL














 1196
1196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









