






1. Docker的基础命令
$ sudo yum install docker-io
$ sudo service docker start
$ sudo chkconfig docker on
$ sudo docker pull centos
$ sudo docker images centos
$ sudo docker run -i -t centos /bin/bash
删除:
docker rm docker ps --no-trunc -aq
保存:
sudo docker commit aa6e2fc0b94c custom/httpd
可以让docker 跑起来之后直接在bash下:
docker run -t -i ljf/fedora-ssh-root /bin/bash
1,Docker配置nginx服务
这里介绍的是用Centos,但是Centos7.0版本还有很多问题
导致无法使用docker,可以参考(www.bubuko.com/infodetail-1314362.html )
2、通过yum命令直接安装,yum install docker
3、启动Docker,并将其设置为开机启动
(1)启动,systemctl start docker.service
(2)开机启动,systemctl enable docker.service
(3)帮助,docker --help
(4)概要信息,docker info
(5)镜像查看,docker images
(6)容器查看,即进程查看,docker ps -a
4、安装镜像,可以到https://registry.hub.docker.com/search?q=library查看官方的镜像。镜像,基于当前系统、Docker,制作的文件集合,即可以是操作系统、程序,如centos镜像、ubuntu镜像、mysql镜像、Nginx镜像
5、安装程序镜像,以Nginx为例,
(1)下载镜像,docker pull nginx:1.9
(2)启动容器,docker run -d -p 8080:80 nginx:1.9,把容器内的nginx的80端口,映射到当前服务器的8080端口,当前服务器的ip是192.168.0.191,浏览器输入http://192.168.0.191:8080/,就可以看到nginx已启动,
(3)再启动多一个容器,docker run -d -p 8081:80 nginx:1.9,浏览器输入http://192.168.0.191:8081/,就可以看到另外一f个nginx已启动
(4)到这里就能体现出Docker部署应用和传统部署应用的区别了,传统部署的话,需要人工拷贝多一份nginx,再配置端口,而Docker部署的话,在已制作好的镜像基础上,一条命令就可以部署一个新的应用
2. Docker 创建 apache 镜像, 跑一个html项目
http://www.linuxidc.com/Linux/2015-07/120124p2.htm
-
首先要pull一个 fedora 的镜像:
$docker pull fedora -
通过交互式命令进入docker 实力安装好所需模块创建image:
docker run -d -t fedora /bin/bash
2.
安装httpd, dnf -y update && dnf -y install httpd && dnf -y clean all
3.
跑脚本,dnf -y install git && git clone https://github.com/gaiada/run-apache-foreground.git && cd run-apach* && ./install && dnf erase git
4.
保存做好的容器,docker commit angry_noble gaiada/apache
5.
测试, docker run -p 80:80-d -t gaiada/apache /etc/httpd/run_apache_foreground
3. 通过Dockerfile 创建docker实例
1. mkdir /imagebuilder
2. cd /imagebuilder
3. vim Dockerfile
FROM fedora
MAINTAINER CarlosAlberto
LABEL version=“0.1”
RUN dnf -y update && dnf -y install httpd && dnf -y clean all
ENV APACHE_RUN_USER apache
ENV APACHE_RUN_GROUP apache
ENV APACHE_LOG_DIR /var/log/httpd
ENV APACHE_LOCK_DIR /var/lock/httpd
ENV APACHE_RUN_DIR /var/run/httpd
ENV APACHE_PID_FILE /var/run/httpd/httpd.pid
EXPOSE 80
CMD ["/usr/sbin/httpd","-D",“FOREGROUND”]
4. [root@localhost imagebuilder]# docker build -t=“lujfeng-apache” .
docker 镜像到此就创建完成。
4. 把项目跑到docker 容器
1. 把项目拷贝到/angularpage
2. setenforce 0, 否则会出现403 forbidden
3. docker run -p 8090:80 -d -t -v /angularpage:/var/www/html lujfeng-apache
输入:http://localhost:8090/InfoList.html 测试项目
这样跑起来的项目依然是在localhost的端口查看,如何让我们的Docker拥有自己的IP?
这样我们就可以输入:http://xxx.xxx.x.xx:xxxx/InfoList.html
-
将这个镜像配置成可以ssh登录的:
$mkdir /dockerFilesFolder
$vim Dockerfile将下面的内容拷贝然后save:
选择一个已有的os镜像作为基础
FROM fedora
安装openssh-server和sudo软件包,并且将sshd的UsePAM参数设置成no
RUN dnf install -y openssh-server sudo
#安装openssh-clients
RUN dnf install -y openssh-clients
添加测试用户root,密码root,并且将此用户添加到sudoers里
RUN echo “root:root” | chpasswd
RUN echo “root ALL=(ALL) ALL” >> /etc/sudoers
下面这两句比较特殊,在centos6上必须要有,否则创建出来的容器sshd不能登录
RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
启动sshd服务并且暴露22端口
RUN mkdir /var/run/sshd
EXPOSE 22
CMD ["/usr/sbin/sshd", “-D”]
构建命令:
cd /dockerFilesFolder
docker build -t="lujfeng-ssh" . (这里最后的dot一定要有,否则找不到Dockerfile)
Step 0 : FROM fedora
—> e055abe0368a
Step 1 : MAINTAINER crxy
—> Using cache
—> c6d1721a2601
Step 2 : RUN dnf install -y openssh-server sudo
—> Running in 3a6b16433018
完成之后会看到输入命令: docker images 会看到自己的镜像
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
lujfeng-ssh-test latest 4258eb9994a8 12 seconds ago 367.5 MB
输入命令测试镜像:docker run --name lujfeng0 --hostname lujfeng0 -d -P -p 8090:80 lujfeng-ssh-test
2:下载pipework
下载地址:https://github.com/jpetazzo/pipework.git
3:把下载的zip包上传到宿主机服务器上,解压,改名字
unzip pipework-master.zip
mv pipework-master pipework
cp -rp pipework/pipework /usr/local/bin/
4:安装bridge-utils
yum -y install bridge-utils
5:创建网络
brctl addbr br0
ip link set dev br0 up
ip addr add 192.168.2.1/24 dev br0
6:给容器设置固定ip
pipework br0 lujfeng0 192.168.2.22/24
7: vim /etc/hosts
写入: 192.168.2.22 lujfeng0
delete bridge:
ip link set veth1pl25496 down
brctl delbr veth1pl25496
error:Link veth1pl8271 exists and is up
because the ip address has been assign to a docker instance
8: 验证一下
[root@hadoopMaster hadoop-2.7.2]# ping lujfeng0
PING lujfeng0 (192.168.2.22) 56(84) bytes of data.
64 bytes from lujfeng0 (192.168.2.22): icmp_seq=1 ttl=64 time=0.070 ms
64 bytes from lujfeng0 (192.168.2.22): icmp_seq=2 ttl=64 time=0.045 ms
[root@hadoopMaster hadoop-2.7.2]# ssh root@192.168.2.22
The authenticity of host ‘192.168.2.22 (192.168.2.22)’ can’t be established.
RSA key fingerprint is SHA256:WAYY7oAC5WJkwYQhfmkzS02LHHMOKhqJDwym2FsWV7k.
RSA key fingerprint is MD5:f7:1a:76:ba:45:fb:4b:86:3c:13:87:64:ff:fc:27:33.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added ‘192.168.2.22’ (RSA) to the list of known hosts.
root@192.168.2.22’s password:
[root@lujfeng0 ~]#
到这里, 一个有ssh 和 id 地址的镜像就做完了。
然后将http://192.168.2.22:8090/InfoList.html 输入地址栏就可以访问到
参考命令:
docker run --name hadoop0 --hostname hadoop0 -d -P -p 80:80 -v ~/AngularJs\ Pagination/:/var/www/html ljf/centos-ssh-httpd-root
docker run --name hadoop0 --hostname hadoop0 -P -p 8090:80 -d -t -v /angularpage:/var/www/html lujfeng-apache
blog.csdn.net/xu470438000/article/details/50512442
使用docker搭建部署hadoop分布式集群
经过以上步骤,我们已经实现了一个具备ssh 和 自己IP 的镜像,接下来的步骤是如何部署hadoop 2.7.2
基于以上的镜像,我们接下ssh到容器内部
-
添加Java 和 hadoop的环境变量
export JAVA_HOME=/usr/local/jdk1.8
export PATH= J A V A H O M E / b i n : JAVA_HOME/bin: JAVAHOME/bin:PATH
export CLASSPATH=.: J A V A H O M E / l i b / t . j a r : JAVA_HOME/lib/t.jar: JAVAHOME/lib/t.jar:JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/hadoop/hadoop-2.7.2
export PATH= H A D O O P H O M E = / b i n : HADOOP_HOME=/bin: HADOOPHOME=/bin:PATH
export HADOOP_CLASSPATH=KaTeX parse error: Expected 'EOF', got '#' at position 73: …环导致system down #̲export PATH=/us…PATH:/usr/bin/pythonexport JAVA_HOME=/usr/local/jdk1.8
export PATH= J A V A H O M E / b i n : JAVA_HOME/bin: JAVAHOME/bin:PATH
export CLASSPATH=.: J A V A H O M E / l i b / t . j a r : JAVA_HOME/lib/t.jar: JAVAHOME/lib/t.jar:JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/hadoop/hadoop-3.0.0
export PATH= H A D O O P H O M E = / b i n : HADOOP_HOME=/bin: HADOOPHOME=/bin:PATH
export HADOOP_CLASSPATH=$JAVA_HOME/lib/tools.jar -
配置hadoop
1. mkdir hdfs tmp
2. mkdir hdfs/data
3. mkdir hdfs/name
rm -rf hdfs
rm -rf tmp
mkdir hdfs tmp
mkdir hdfs/data
mkdir hdfs/name
chmod -R 777 hdfs
chmod -R 777 tmp -
修改配置文件:
Core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoopMaster:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/hadoop/hadoop-3.0.0/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/hadoop/hadoop-2.7.2/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/hadoop/hadoop-2.7.2/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoopMaster:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoopMaster:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoopMaster:19888</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoopMaster:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoopMaster:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoopMaster:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoopMaster:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoopMaster:8088</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
</configuration>
修改hadoop-env.sh、yarn-env.sh 中的 JAVA HOME 路径:
-site
hadoop-env.sh
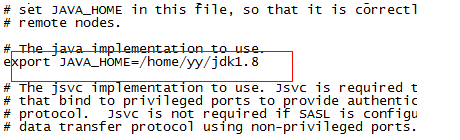
yarn-env.sh

Hadoop-3.0.0 补充:
在hadoop-env.sh 中,加入
export JAVA_HOME=/usr/local/jdk1.8
export HADOOP_HOME=/hadoop-3.0.0
如果namenode 没有启动的话,跑 command 格式化namenode
bin/hadoop namenode -format
[root@hadoopMaster sbin]# ./start-all.sh
Starting namenodes on [hadoopMaster]
Starting datanodes
Starting secondary namenodes [hadoopMaster]
Starting resourcemanager
Starting nodemanagers
[root@hadoopMaster sbin]# jps
24290 Jps
22375 DataNode
21943 NameNode
23464 ResourceManager
22958 SecondaryNameNode
23871 NodeManager
5. 给docker 容器安装需要的命令:
dnf install -y which procps
6. 配置 slaves 文件,这里默认让主机也做slaves:
vim /hadoop/hadoop-2.7.2/etc/hadoop/slaves
hadoopMaster
hadoop0
lujfeng0
vi /etc/hosts
192.168.0.10 hadoopMaster
192.168.2.11 hadoop0
192.168.2.22 lujfeng0
- 配置ssh
在 lujfeng0 上面 配置ssh,
$ssh-kengen
将生成的id_rsa.pub 复制到其他机器的authenticated_keys 里面, 这样lujfeng0 就可以登录到其他机器了
这里就不赘怎么去配置ssh了
关于hadoop-3.0.0 的补充:
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [hadoopMasterNode]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
Starting resourcemanager
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
Starting nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
解决办法:
[root@hadoopMasterNode sbin]# export HDFS_NAMENODE_USER=“root”
[root@hadoopMasterNode sbin]# export HDFS_DATANODE_USER=“root”
[root@hadoopMasterNode sbin]# export HDFS_SECONDARYNAMENODE_USER=“root”
[root@hadoopMasterNode sbin]# export YARN_RESOURCEMANAGER_USER=“root”
[root@hadoopMasterNode sbin]# export YARN_NODEMANAGER_USER=“root”
关于ssh key, 生成出来的pub key 也要放在自己的.ssh authorized_key 里面,因为有可能出error permission denied
- 测试!
主节点:
[root@hadoopMaster hadoop-2.7.2]# jps
25680 NameNode
28326 Jps
26118 DataNode
26743 SecondaryNameNode
27098 ResourceManager
27357 NodeManager
lujfeng0:
[root@lujfeng0 /]# jps
349 DataNode
653 Jps
415 NodeManager
hadoop0:
[root@hadoop0 ~]# jps
3265 NodeManager
3193 DataNode
3452 Jps
如果跑出来以上的进程,那么就集群搭建成功!!
测试hdfs
关于测试脚本 wc.jar , 可以参考引文里的 How to build wc.jar file for wordcount
bin/hadoop fs -mkdir -p(nested folder) /user/lujfeng/
bin/hadoop fs -put /ielts/ /user/lujfeng/
bin/hadoop jar wc.jar WordCount /user/lujfeng/ielts /user/lujfeng/output2
bin/hadoop fs -cat /user/output22/part-r-00000
(美作:theater) 1
00:00 1
- 1
- 1
- 1
12 1 - 1
- 1
- 1
注意,一定要保证主节点和子节点里面的/etc/hosts 都有对应的名称和IP , 否则会导致无法访问到HDFS 例如 bin/hadoop fs -cat /user/output22/part-r-00000 , 会报错说找不到hadoopMaster
地址栏输入:
hadoopmaster:8088/cluster/nodes 就可以看到跑起来的节点数

start hadoop:
bin/hdfs namenode –format
sbin/start-all.sh

RPC(remote procedure call)的协议有很多,比如最早的CORBA,Java RMI,Web Service的RPC风格,Hessian,Thrift,甚至Rest API。
Name node is in safe mode.
solution:
bin/hadoop dfsadmin -safemode leave
Run the commands for all the nodes
#!/bin/bash
declare -a nodes=(
“n1.mycompany.com”
“n2.mycompany.com”
“n3.mycompany.com”
“n4.mycompany.com”
“n5.mycompany.com”
)
for i in “
n
o
d
e
s
[
@
]
"
d
o
s
s
h
"
{nodes[@]}" do ssh "
nodes[@]"dossh"i” “$1”
done
example:
./do.sh “hostname”
Copy all the file of n1 to other nodes:
#!/bin/bash
declare -a nodes=(
“n2.mycompany.com”
“n3.mycompany.com”
“n4.mycompany.com”
“n5.mycompany.com”
)
for i in “${nodes[@]}”
do
scp “
1
"
"
1" "
1""i”:"$1"
done
example:
./do_copy.sh /etc/hosts
参考文档:
How to build wc.jar file for wordcount
https://hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html
http://blog.csdn.net/segen_jaa/article/details/47816665
http://blog.csdn.net/xu470438000/article/details/50512442
http://jingyan.baidu.com/article/f00622283a76c0fbd3f0c839.html
BUG:INFO mapreduce.Job: Job job_1469501501248_0001 running in uber mode : false
http://blog.csdn.net/dai451954706/article/details/50464036














 1682
1682











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









