






jdk建议使用JDK1.8.11 Tar hadoop.tar.gz建议使用Hadoop2.7.3
配置环境变量
-
cd /usr/soft/
-
tar -zxvf hadoop-2.7.3.tar.gz

-
vi /etc/profile
进入配置环境变量,把下面的粘贴进去后保存退出
export HADOOP_HOME=/usr/soft/hadoop-2.7.3
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME

配置hadoop伪分布式模式
总共需要修改:
Core-site.xm(文件系统核心)
Hdfs-site.xm(配置副本数伪分布式副本个数(伪分布只有1个副本,完全分布最少3个))
Yarn-site.xm(设置站点名称 和 辅助节点管理)
mapred-site.xml(设置映射化简模型框架为yarn)
-
开始配置整个文件系统的核心,整个文件系统要启动起来全靠这个
Core-site.xm
找到这个文件并修改它

<property> <name>fs.defaultFS</name> <value>hdfs://192.168.1.11:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/soft/hadoop-2.7.3/tmp</value> </property>
步骤含义:fs就是非欧c s ting 的英文缩写(是他的专用属性)默认址文件系统;(就是我当前要开启的是文件系统,讲白了就是我要写文件,要做个盘出来,这个盘呢用的是远程地址,因为将来这个主机不一定在你这,可能在别人那)默认开放端口是9000端口,ip地址根据Linux实时的IP地址来定;

-
cd /usr/soft/hadoop-2.7.3/
进入此路径 -
mkdir tmp
创建文件
因为刚刚在配置文件里面的添加的那个文件是不存在的,所以要去创建一个
步骤含义:配一个临时时内存文件(存放临时文件):/usr/soft/hadoop-2.7.3/tmp (启动的时候万一需要临时碎片文件,我需要找个文件来存)
如果有其他服务占用的也是9000端口记得把那个服务的端口改一下; -
ls
查看当前路径下文件

Hdfs-site.xml
找到这个文件并修改它
(配置副本数伪分布式副本个数)

<property> <name>dfs.replication</name> <value>1</value> </property>

mapred-site.xml
(设置映射化简模型框架为yarn)
拷贝/usr/soft/hadoop-2.7.3/etc/hadoop/里面的mapred-site.xml.template文件(这是一个模板)
-
cd /usr/soft/hadoop-2.7.3/etc/hadoop/
[root@node01 hadoop]# 进入后开头点缀是这个,虚拟机名字因人而异
-
cp mapred-site.xml.template mapred-site.xml
------------- 拷贝模板,把他的后缀名去掉,变成前面这样

-
回车后会拷贝出一个文件 mapred-site.xml 打开它
( 把下面这这段内同粘贴到里面(设置映射化简模型框架为yarn)<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
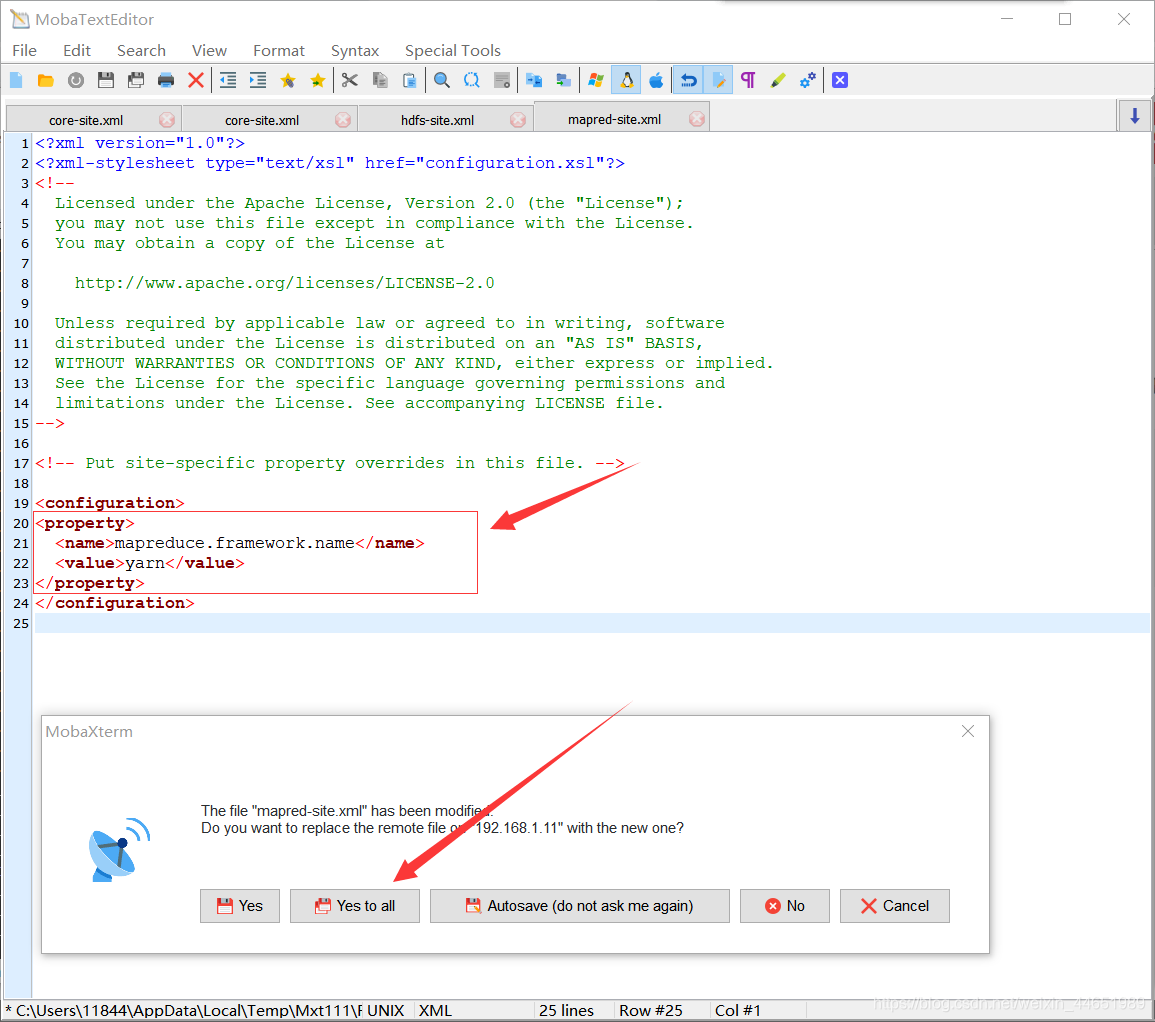
Yarn-site.xml
找到这个文件并修改它
(设置站点名称 和 辅助节点管理)

-
把中间的
<!-- Site specific YARN configuration properties -->这一行注释去掉
加上下面这段(辅助节点管理 和 站点名称)
图片上少了一个s,在代码里加上了<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.localhost</name> <value>localhost</value> </property>

配置java路径
打开 hadoop-env.sh 文件(hadoop是基于Java的,所以配置一下Java的路径,防止Hadoop找不到)
找到这一行 export JAVA_HOME=${JAVA_HOME}
修改成虚拟机上的Java文件路径 export JAVA_HOME=/usr/soft/jdk1.8.0_111/
配置SSH
(安全套接字处理)
目的是使用脚本启动远程服务器,必须使用shell登陆远程服务,但每个登陆都需要输入密码就非常麻烦,所以需要配置无密配置,需要在NameNode上生成私钥,把公钥发给DataNode
·如果没有做过公私钥,建议走1,反之走2
1
- cd ~
返回根目录 - ssh-keygen -t rsa -P ‘’
生成无秘公私钥 - cd .ssh/
进入此路径 - cat id_rsa.pub >> authorized_keys
管道命令,因为是伪分布式,所以把公钥复制给自己 - ls
检查一下公钥是否生成
- chmod 600 authorized_keys
chmod(关键字)把authorized_key权限设置为600(给公钥授权) - ssh 192.168.1.11
检查是否需要密码登录,这一次会询问yes/no(后面是当前IP) - exit
登出
- ssh 192.168.1.11
这次登录没有询问,说明设置无秘登录成功
如果还是不行,请退出,然后按照2,一步一步的做


- 如果还是要输入密码
直接把我下面的命令粘贴进去,省事~
cd ~
cd .ssh/
ls
rm -rf id_rsa.pub
rm -rf id_rsa
rm -rf authorized_keys
ssh-keygen -t rsa -P ‘’
执行到这个命令时中间需要点一次回车
cat id_rsa.pub >> authorized_keys
chmod 600 authorized_keys
ssh 192.168.1.13
这时可以直接登录了!

2
- cd ~
进入根目录 - cd .ssh/
进入此文件夹 - ls
查看目录下文件(查看是否以有公私钥)
如果有,按下面步骤来
authorized_keys id_rsa id_rsa.pub known_hosts
[root@node01 .ssh]# rm authorized_keys 删除查询到的三个密钥 1
rm:是否删除普通文件 “authorized_keys”?y 会询问是否删除 2
[root@node01 .ssh]# ls 3
id_rsa id_rsa.pub known_hosts
[root@node01 .ssh]# rm -r id_rsa 会询问是否删除 4
rm:是否删除普通文件 “id_rsa”?y 5
[root@node01 .ssh]# rm -rf id_rsa.pub 不会询问 6
[root@node01 .ssh]# ls 检查是否删除 7 然后去生成公私钥
known_hosts
rm 删除命令
rm -r 将指定目录下的所有文件与子目录递归删除(每次都要询问)
rm -f 强制删除文件或目录
rm -i 删除已有文件或目录之前先询问用户
rm -rf 不再询问是否确定删除(直接删除)
rm -rf id_rsa.pub
rm -rf id_rsa
rm -rf authorized_keys
- ssh-keygen -t rsa -P ‘’
生成无秘公私钥
额外补充:
其中公共密钥保存在 ~/.ssh/id_rsa.pub
私有密钥保存在 ~/.ssh/id_rsa
scp是操作远程文件,cp是操作本机 下面这个是拷贝公钥到另一台服务器的实例
[root@linuxA]$ scp ~/.ssh/id_rsa.pub root@linuxB:/home/user1/.ssh/authorized_keys
root@linuxB’s password:
id_rsa.pub 100% 228 3.2MB/s 00:00
[root@linuxA]$
这样就完成了。之后在LinuxA上使用ssh scp sftp 之类的访问linuxB时,就不用输入密码
- cat id_rsa.pub >> authorized_keys
管道命令,生成公钥(捕捉密钥授权给auth~这个文件) - ls
检查一下公钥是否生成
- chmod 600 authorized_keys
chmod(关键字)把authorized_key权限设置为600(给公钥授权) - ssh 192.168.1.11
检查是否需要密码登录,这一次会询问yes/no(后面是当前IP) - exit
登出
- ssh 192.168.1.11
这次登录没有询问,说明设置无秘登录成功
格式化NameNode节点
-
cat /etc/profile
格式化之前先输入命令,查看环境变量是否配置完成
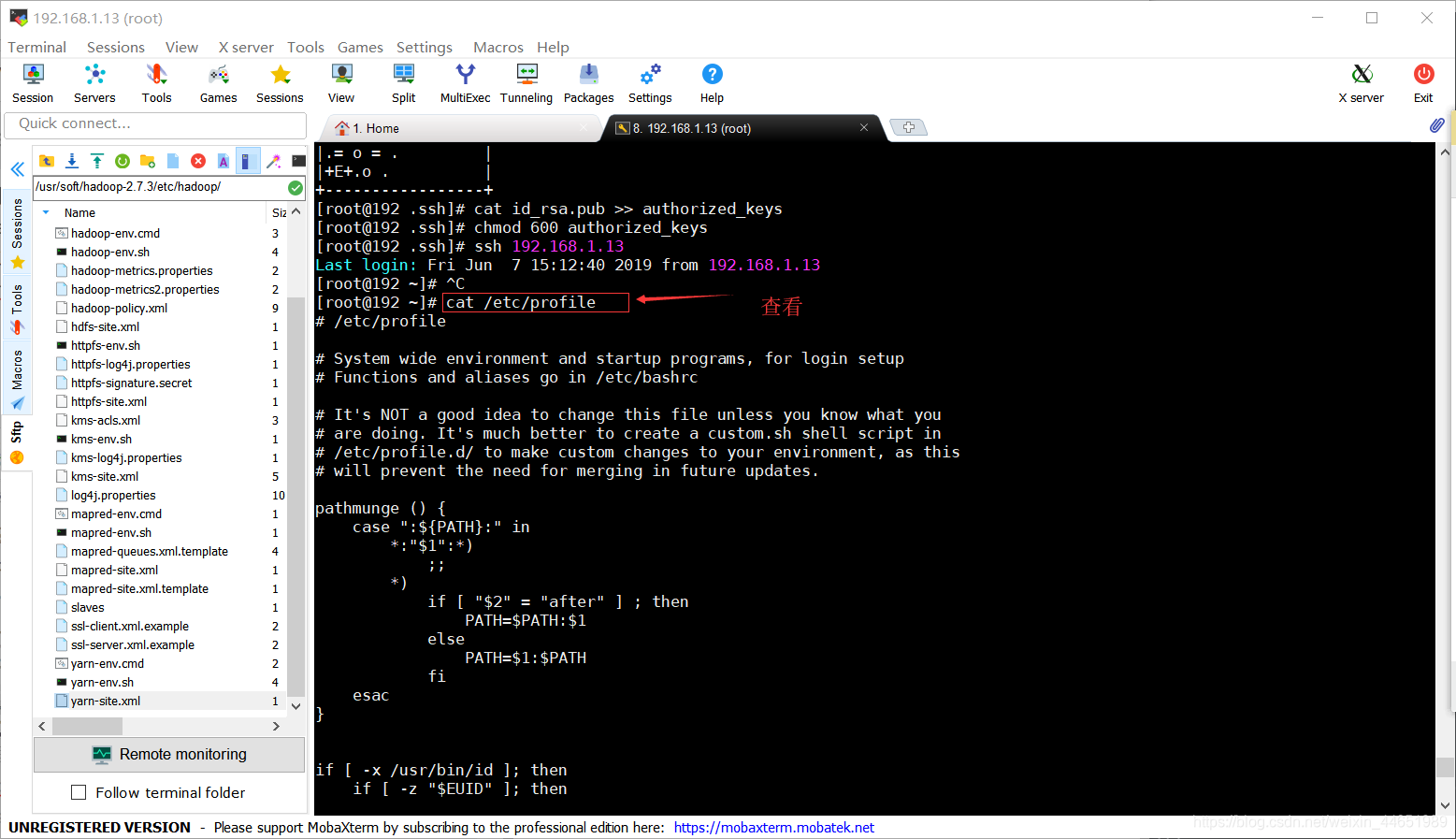

-
hdfs namenode -format
格式化(就像一般拿到一个新硬盘都要格式化一下,防止有病毒)

启动Hadoop -
start-all.sh
启动(还有一个启动命令,这个相对简单点)
如果报下面这个错
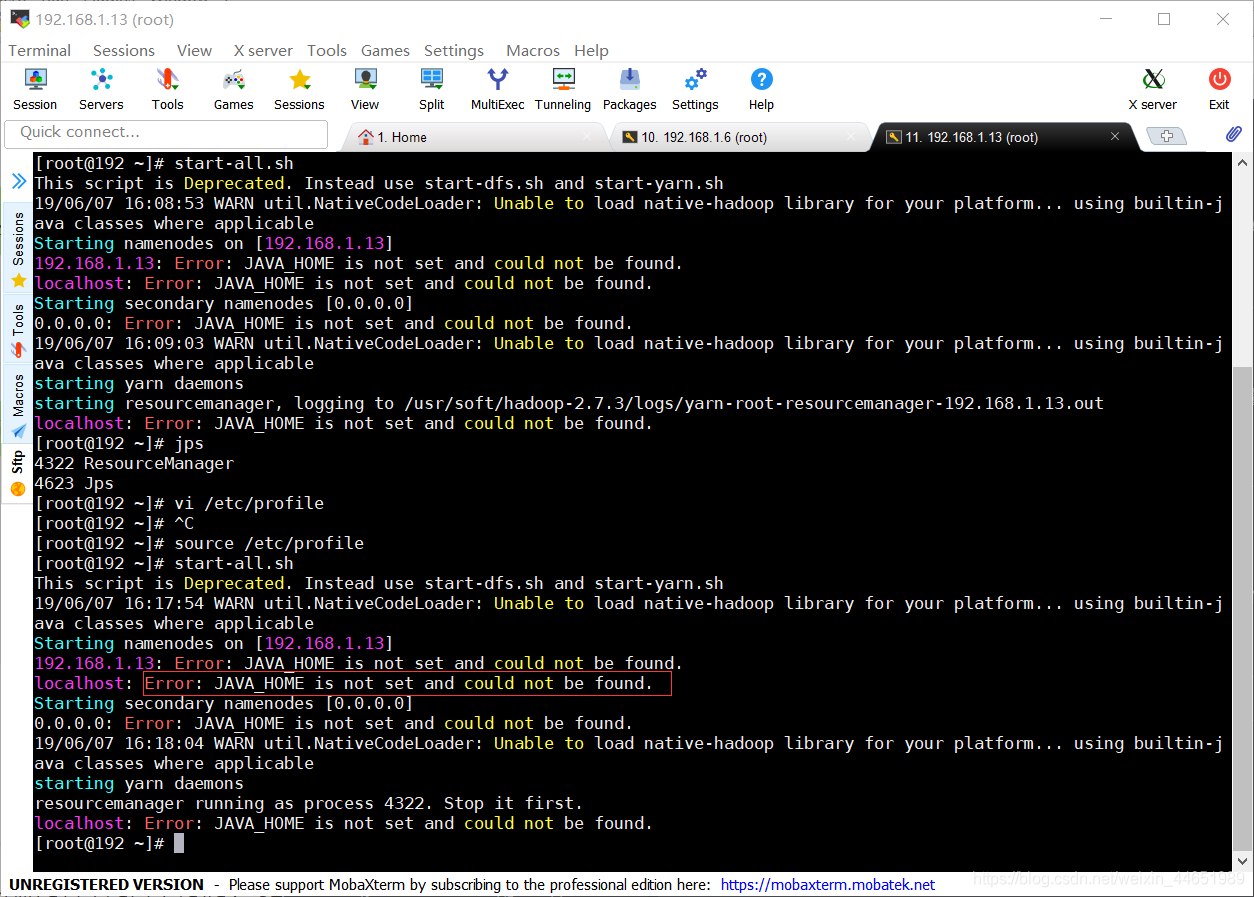
去改个东西(jdk路径出错了)




-
jps
查看hadoop文件系统的进程
正确启动后,下面会有6个进程(前面的编号估计会不一样)如果少了,说明前面配置文件改错了
















 1432
1432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









