







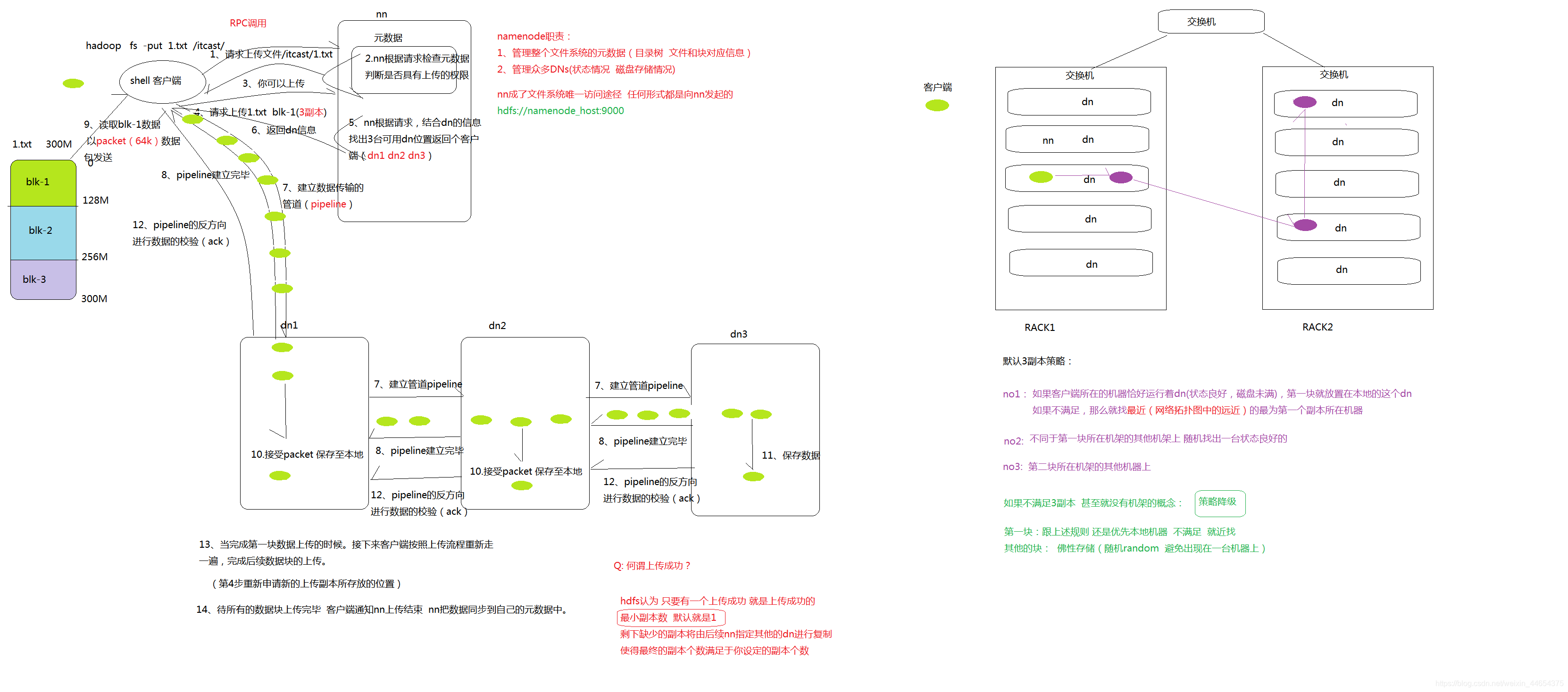
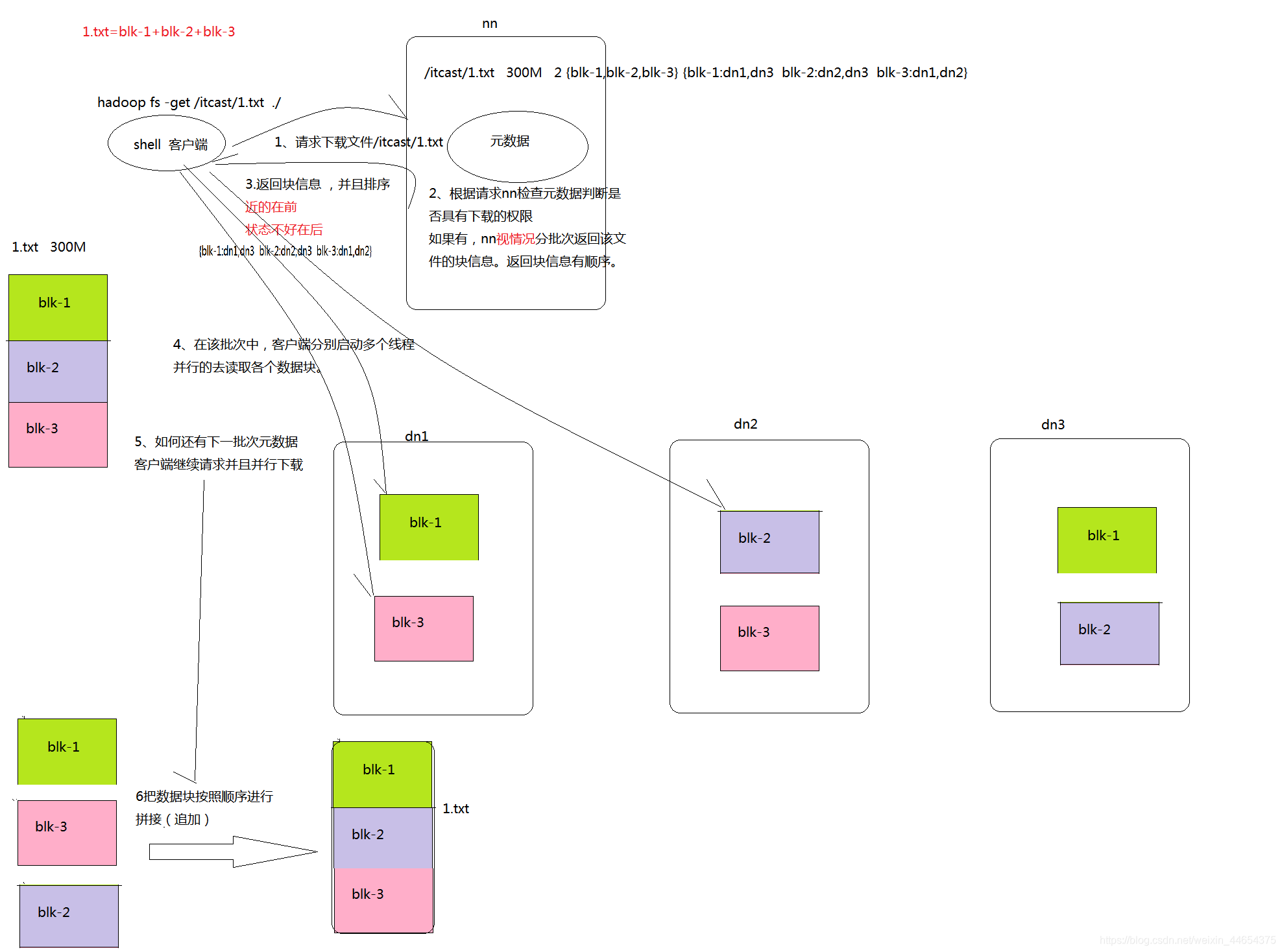
- hdfs概述
- namenode
管理了整个文件系统的元数据 (metadata)
管理众多datanode
对外提供服务的唯一入口
rpc端口:9000 使用文件系统的端口 hdfs://node-1:9000
http端口:50070 hdfs webui页面的端口 查看端口 http://node-1:50070 - datanode
负责具体数据块的存储
定时需要向nn进行通信汇报
- namenode
- dn汇报机制
dn启动的时候 会去向nn进行注册 并且汇报自己持有哪些块信息
接下来每隔一段时间进行如下的汇报
每隔3秒 发送心跳 目的:报活
每隔6小时 汇报自己持有的数据块
hdfs主从架构 两者各司其职 共同
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









