






概述
这是一个非常牛的算法,也是非常复杂得一个算法,里面设计大量的数学知识。
但是整体而言,这是一个监督学习分类算法,我们可以将神经网络算法理解成如下结构,也就是输入经过线性函数和激活函数(非线性)最后输出。

更复杂的结构如下:
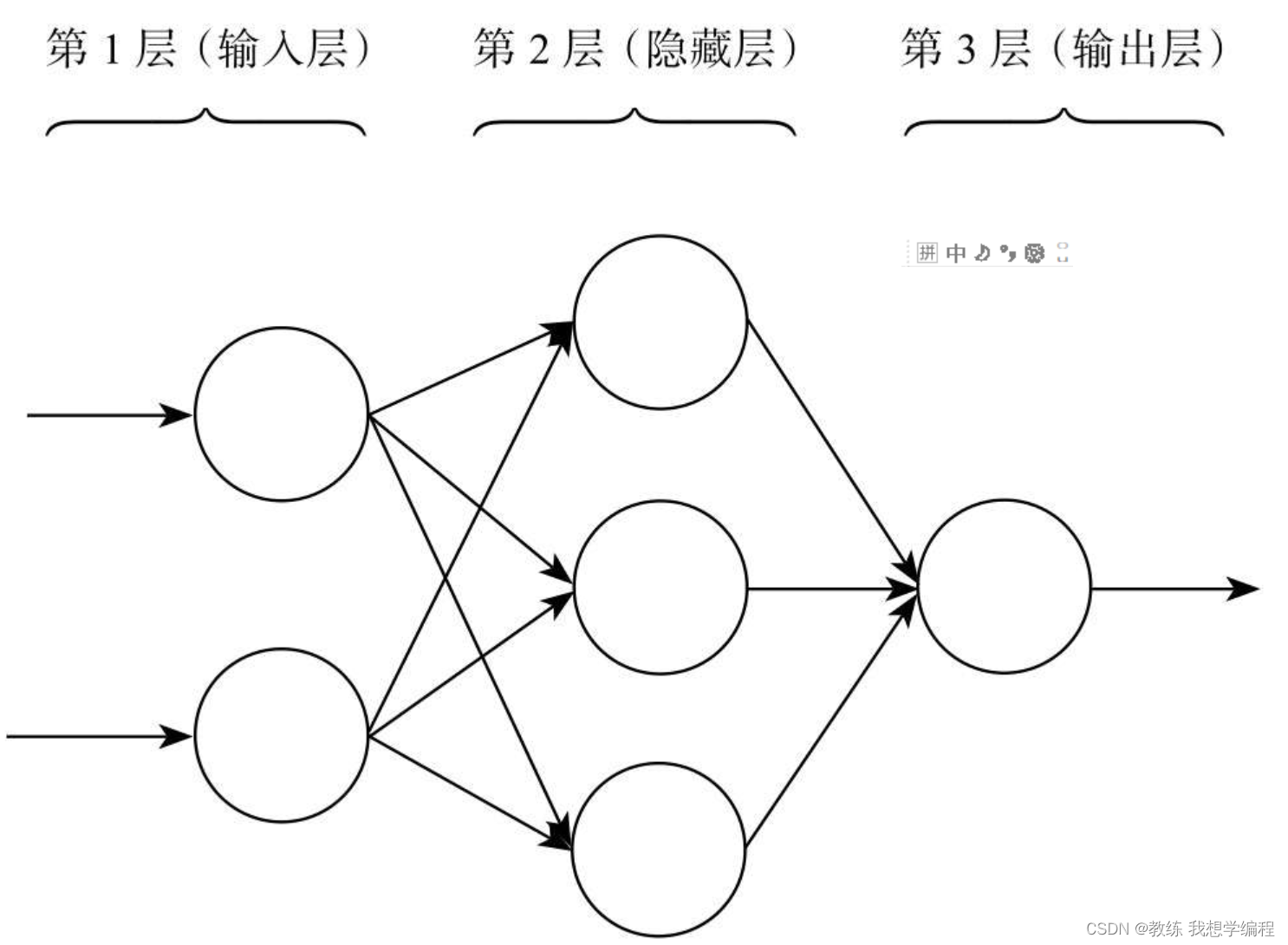
为了训练,神经网络引入了正向传播和反向传播机制。正向传播扮演的是传播输入的功能。输入层的神经元首先接收输入,通过激励函数产生输出,这是第一步。输入层的输出则作为隐藏层的输入,再通过激励函数产生输出,这是第二步。输入就这样一层一层传递下去,这个过程有点像击鼓传花,一直到输出层产生输出,正向传播就完成了。偏差的传递也类似,但因为方向相反,所以称之为反向传播:首先通过输出层获取偏差,同样要计算一个值往后传递,但这时就不是通过激励函数了,而是要获知每个输入方向所贡献的偏差值。
这话有点儿拗口,什么意思呢?说白了就是,预测这事儿是你一嘴我一舌大家一起商量得到的,当然大家的地位(权重)不同,有人说话分量轻,有人说话分量重。现在知道预测错了,刚才说话分量重的对结果影响大,那么说明犯的错也严重些,刚才说话分量轻的错就轻一些。根据这个原则,把得到的偏差按照说话分量分配一下,自己犯的错自己“领”回家。输出层就这样把偏差反向传播到隐藏层,让里层的神经元得到了偏差,就能把训练继续下去了。同样,隐藏层的神经元得到偏差后,不但自己调整权值,而且照葫芦画瓢,继续往后传播偏差。同样一层接一层地往后传播,一直到输入层。整个神经网络就完成了一轮权值更新。
代码实战
# 导入第三方包
import pandas as pd
from sklearn.datasets import load_iris
from sklearn import model_selection
from sklearn.neural_network import MLPClassifier
X, y = load_iris(return_X_y=True)
# 样本拆分
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y,
test_size=0.25, random_state=1234)
# 模型拟合
# criterion='gini' 默认是用criterion='gini' 基尼系数,也可以选择criterion='entropy',基尼系数是最好的
clf=MLPClassifier().fit(X_train, y_train)
# 模型在测试数据集上的预测
gnb_pred = clf.predict(X_test)
print("预测值{}".format(gnb_pred))
print("原值{}".format(y_test))
print("得分:{}".format(clf.score(X_test,y_test)))

可解释性差是神经网络算法乃至于其下衍生出来的“网红”分支深度学习算法的共同毛病,对于神经网络算法究竟是怎么完成学习的,外部无从得知,也难以了解,所以也被称为“黑盒算法”。通过调节神经网络算法的各种参数能够使得分类效果明显提升,但这种提升缺乏配套的理论解释,往往需要依靠经验,因此也被人批评为机器学习领域的“炼金术”。此外,神经网络算法采用的梯度下降等优化算法,在部分情况下可能陷入局部最优解的情况,导致预测精度下降。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









