






概述
关联分析是数据挖掘中一种简单而实用的技术,它通过深入分析数据集,寻找事物间的关联性,挖掘频繁出现的组合,并描述组合内对象同时出现的模式和规律。例如,对超市购物的数据进行关联分析,通过发现顾客所购买的不同商品之间的关系,分析顾客的购买习惯,设计商品的组合摆放位置,制定相应的营销策略,从而制造需求,提高销售额,创造额外收入。
核心思想:
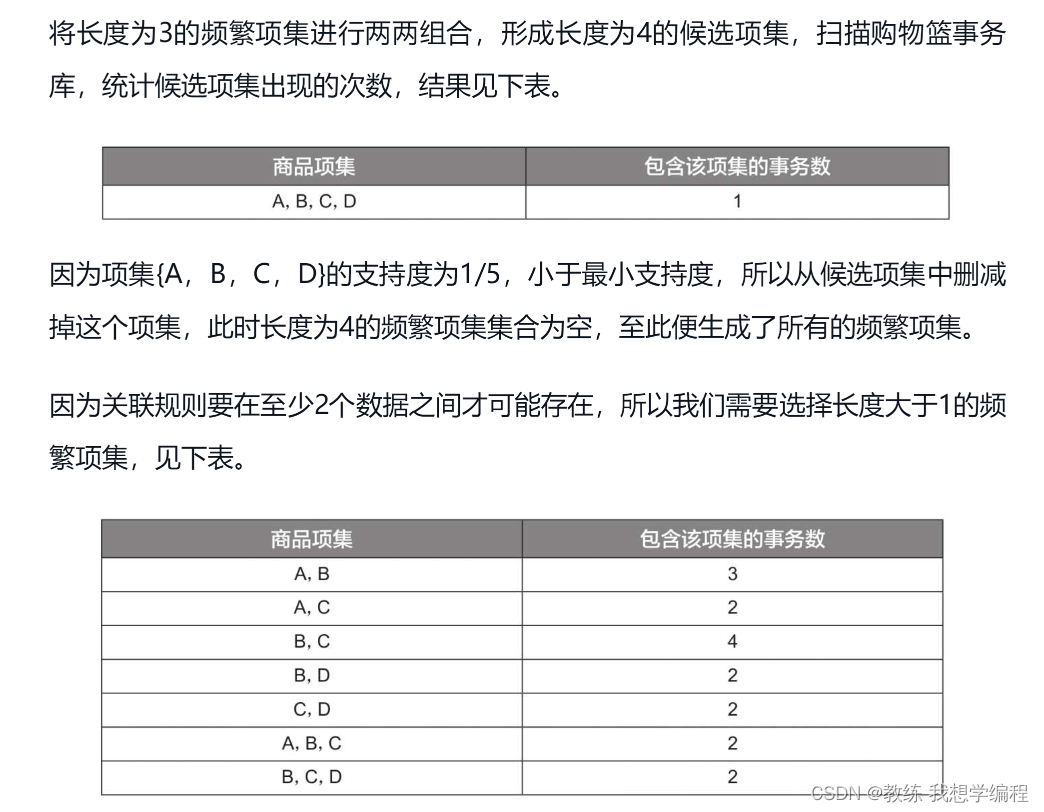
每条记录中有购买的商品集合,首先要找到这些商品集合出现的次数,可以是父级,比如有条记录商品是{A,B},那么可以看其他记录中的商品列表中是否包含{A,B},如果包含就算一次出现,这就是支持度的分子项,分母项是所有记录。这个支持度必须满足人为设定的限制,超过这个限制的就叫做频繁项集,才能参与后面的计算。
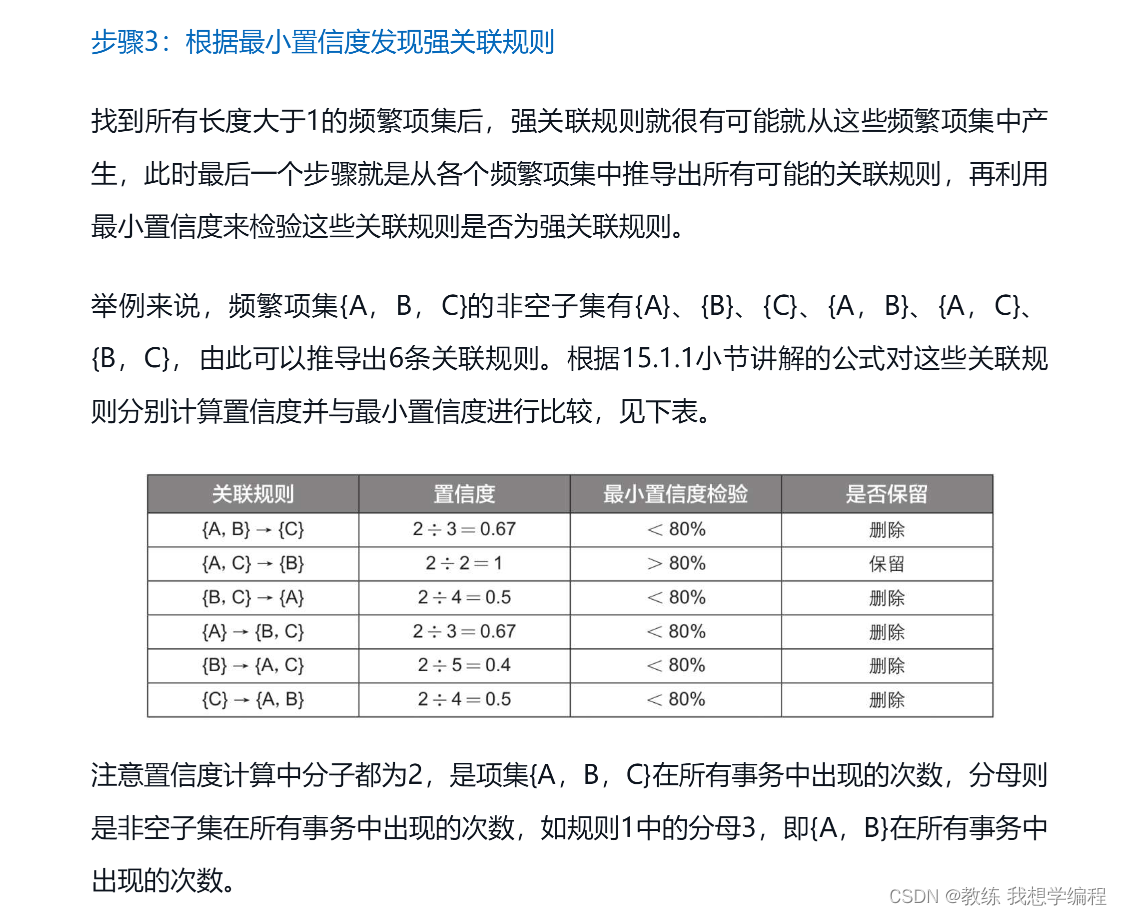
其次是置信度,这个看似很复杂其实原理很简单,就是计算某个频繁项集(可以是包含这个项集的父级)的出现次数作为分母,这个项集和你关心的那个产品组成的新的集合(或者这个新的集合的父级)的出现的次数作为分子,很显然,分子一定是小于分母的。“购买了商品A和商品B的人中有67%的人也购买了商品C”,这句话就是置信度的本质
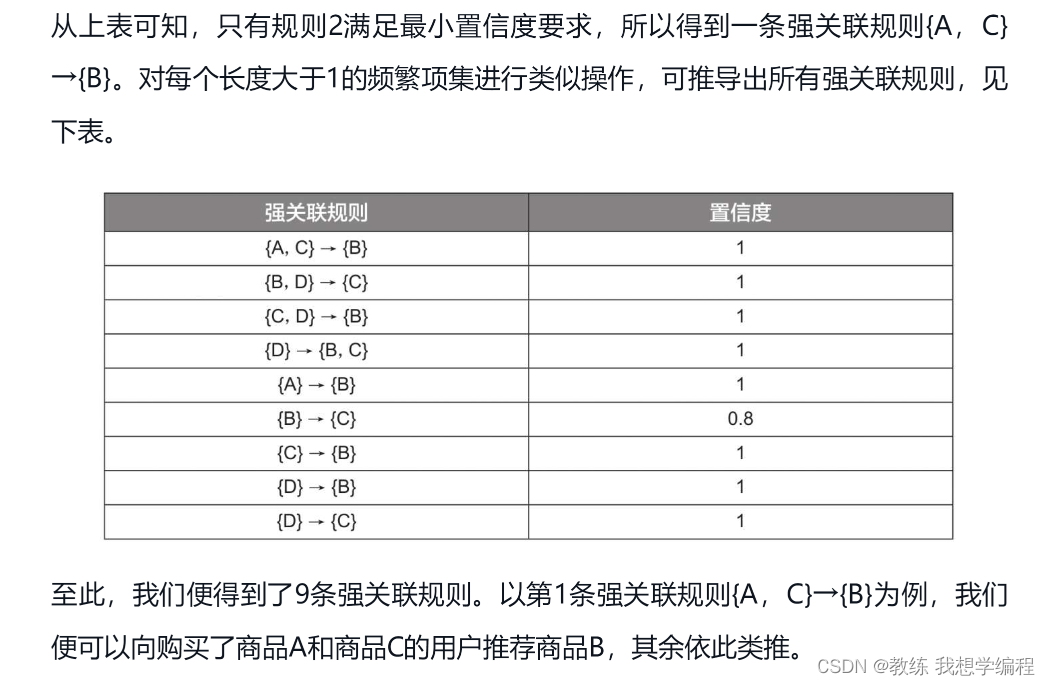
筛选出满足置信度的关系即可。
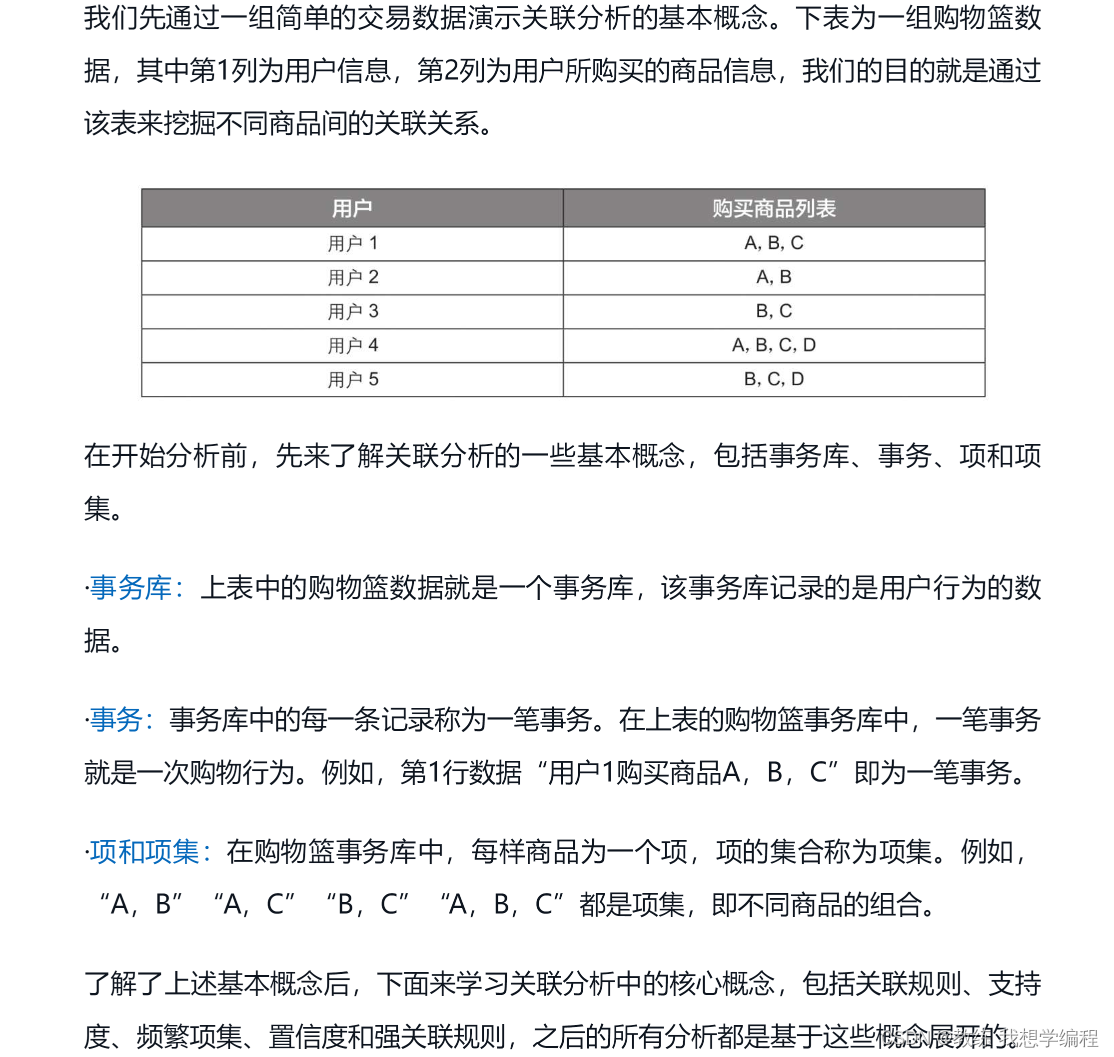



案例演示

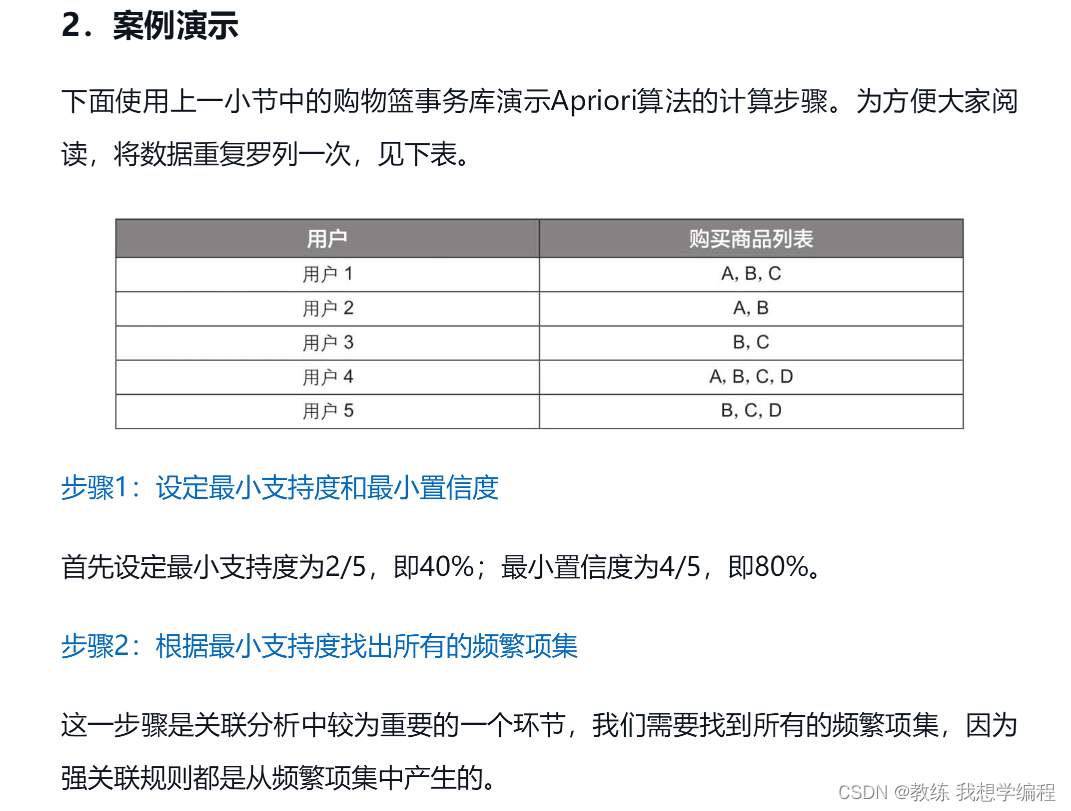

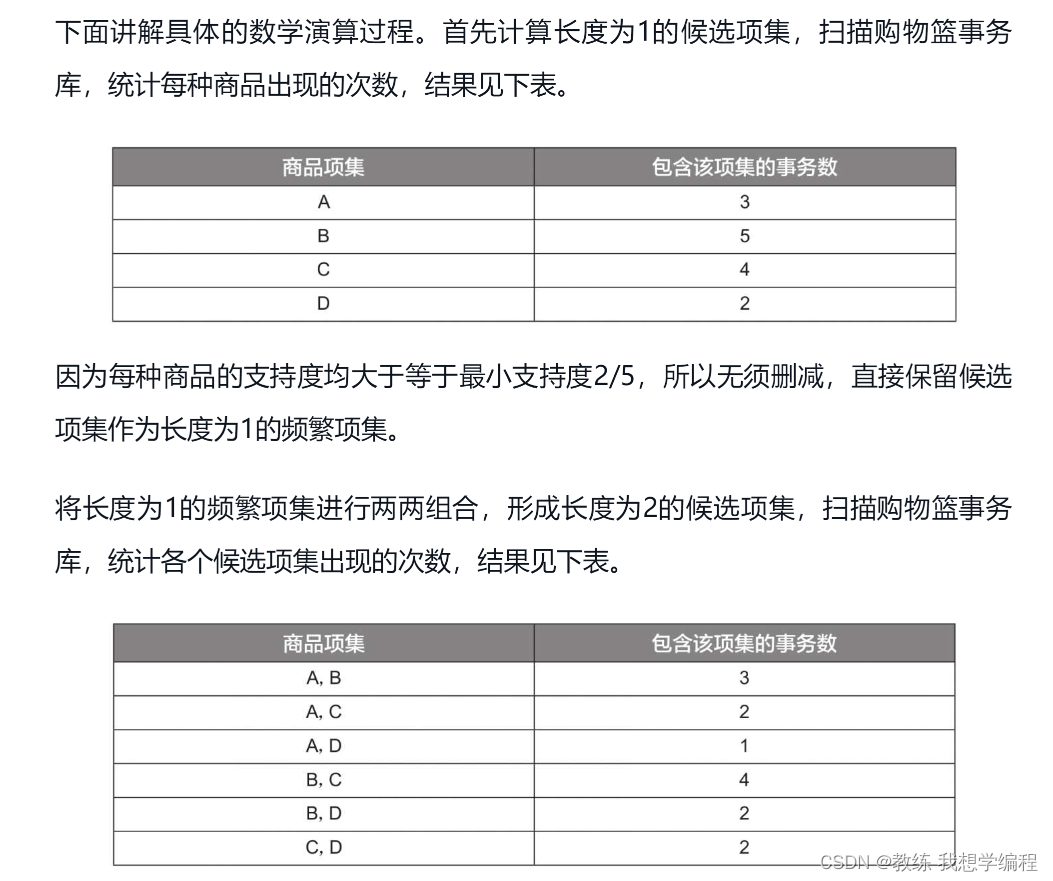
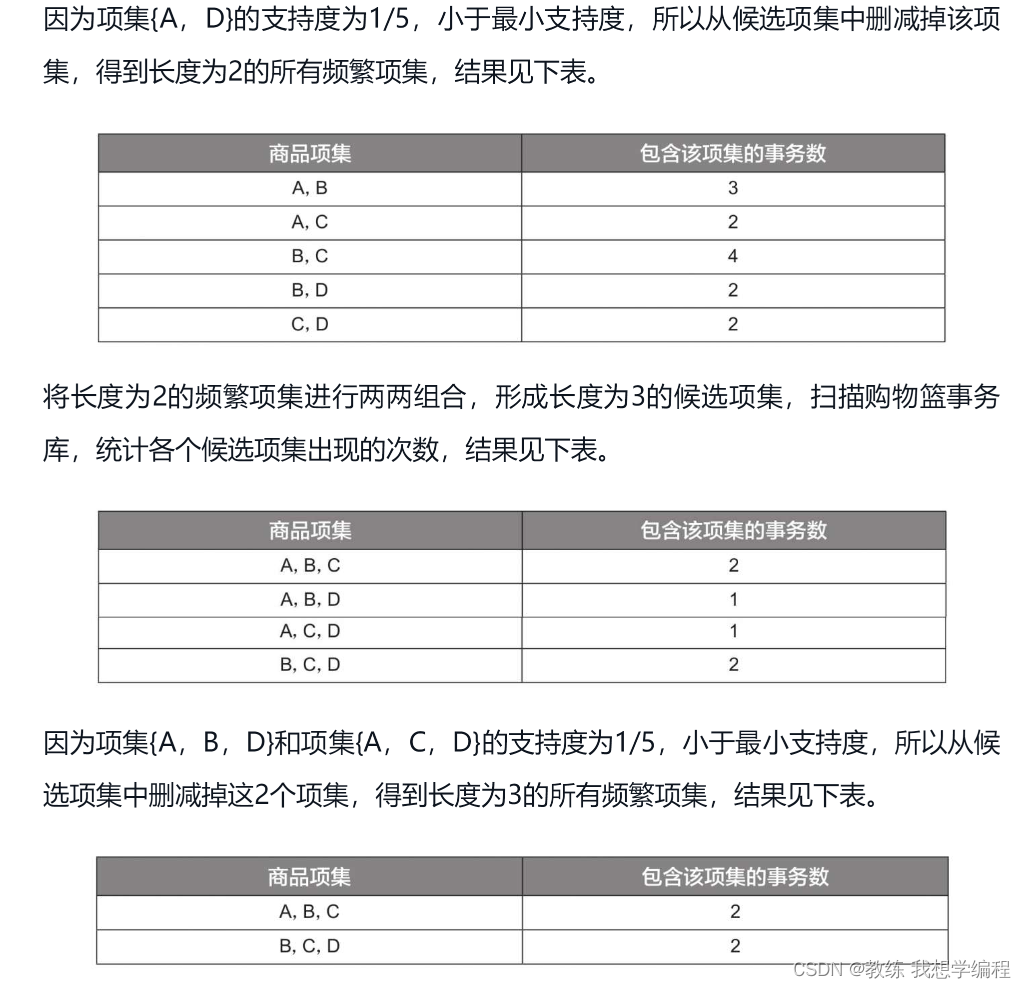
代码实战
在Python中则可以利用apyori库和mlxtend库快速推导强关联规则。apyori库是一个经典的库,它使用起来较为简单,不过有时会漏掉一些强关联规则;mlxtend库的使用稍显麻烦,但是它能捕捉到所有的强关联规则。
这里还是推荐使用mlxtend,更加全面,其实也麻烦不到哪里去。
# # 15.1.3 Apriori算法的代码实现
# # 1.apyori库代码实现关联规则
transactions = [['A', 'B', 'C'], ['A', 'B'], ['B', 'C'], ['A', 'B', 'C', 'D'], ['B', 'C', 'D']]
from apyori import apriori
rules = apriori(transactions, min_support=0.4, min_confidence=0.8)
results = list(rules)
print(results)
print(type(results[0].ordered_statistics))
for i in results:
for j in i.ordered_statistics:
X = j.items_base
Y = j.items_add
x = ', '.join([item for item in X])
y = ', '.join([item for item in Y])
if x != '':
print(x + ' → ' + y)

# # 2.mlxtend库代码实现关联规则
transactions = [['A', 'B', 'C'], ['A', 'B'], ['B', 'C'], ['A', 'B', 'C', 'D'], ['B', 'C', 'D']]
from mlxtend.preprocessing import TransactionEncoder
TE = TransactionEncoder()
data = TE.fit_transform(transactions)
print(data)
import pandas as pd
df = pd.DataFrame(data, columns=TE.columns_)
print(df)
from mlxtend.frequent_patterns import apriori
items = apriori(df, min_support=0.4, use_colnames=True)
print(items)
items['itemsets'].apply(lambda x: len(x))
print(items[items['itemsets'].apply(lambda x: len(x)) >= 2])
from mlxtend.frequent_patterns import association_rules
rules = association_rules(items, min_threshold=0.8)
print(rules)
for i, j in rules.iterrows():
X = j['antecedents']
Y = j['consequents']
x = ', '.join([item for item in X])
y = ', '.join([item for item in Y])
print(x + ' → ' + y)















 1814
1814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









