






因为要循环一些品牌名,并将其作为工作表名字保存,但是循环到一些品牌之后就出现问题了,因为windows明明规则不能包括/\:*?"<>|
查找资料,得到结果
import re
a='1/\:*?"<>|2|*?'
print(re.sub(r'[\/\\\:\*\?\"\<\>\|]','', a))#只要存在特殊字符中的一个就替换为空


后期将会深入学习python正则表达式的知识,很重要!
2019/7/27 续写:
在以上代码re.sub(r’[/\??"<>|]’,’’, a))
[ ]中写的很麻烦,明明我们只需要匹配/??"<>|,这些特殊字符,为什么有那么多反斜杠\呢?
另外表达式到底是什么意思呢?
这就是正则表达式,接下来记录一下
1、中括号的意义[ ],表示匹配其中的任一字符,注意是任一个,不是任意,如果是k[abc],则匹配出的是ka,kb,kc
2、反斜杠\的用法,反斜杠在python中是转义字符,也就是说它不代表本身的反斜杠,如果要表示反斜杠那么只能\,第一个反斜杠将后一个反斜杠转义为真正的反斜杠,另外其他的一些字符,也需要用反斜杠转义,因为有些时候这些字符也不是表示本身的意思,需要用反斜杠把他们变成本身的意义。
3、r的用法,上面讲到转义反斜杠,其实我们可以在在之前加上一个r让反斜杠不具有转义的本质,直接就是表现为反斜杠。r后面接的内容里面是什么就是什么,不用转义。
那么本身我们要匹配’[/:?"<>|]‘中的一个,但是因为有些是特殊字符,我们索性将每个特殊字符前面都加转义’[/\??"<>|]’,这样也能得到结果。
上面讲到r后是什么就是什么,不用转义,我们产生尝试r’[/:?"<>|]’,但是我们匹配不到反斜杠,我的理解是[ ]的优先级更高,在中括号内,f反斜杠作为转义字符转义了冒号:,匹配出来的其实只有冒号本身。因此还是建议在复杂的情况下,我们直接反斜杠转义,但是层次清晰的情况下是用r即可。
因此替换或去除不能用于文件名的字符的最终算法如下:
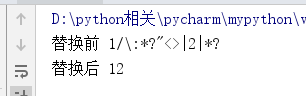
import re
a='1/\:*?"<>|2|*?'
print('替换前',a)
print('替换后',re.sub('[\/\\\:\*\?\"\<\>\|]','', a))















 783
783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









