







Java小白修炼手册
本文章均来自廖雪峰老师官网,仅记录自己的学习过程,并无商用。在此,也感谢廖雪峰老师!
文章目录
数组
- 使用for each循环打印也很麻烦。幸好Java标准库提供了Arrays.toString(),可以快速打印数组内容
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
int[] ns = { 1, 1, 2, 3, 5, 8 };
System.out.println(Arrays.toString(ns));
}
}
- Java的标准库已经内置了排序功能,我们只需要调用JDK提供的Arrays.sort()就可以排序(jdk1.8不能用)
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
int[] ns = { 28, 12, 89, 73, 65, 18, 96, 50, 8, 36 };
Arrays.sort(ns);
System.out.println(Arrays.toString(ns));
}
}
3.二维数组取数
for (int[] arr : ns) {
for (int n : arr) {
System.out.print(n);
System.out.print(', ');
}
System.out.println();
}
- 三维数组
int[][][] ns = {
{
{1, 2, 3},
{4, 5, 6},
{7, 8, 9}
},
{
{10, 11},
{12, 13}
},
{
{14, 15, 16},
{17, 18}
}
};
重载与多态与抽象与接口
- 重载:同一方法名不同参数
- 多态:子类重写父类
- 多态:针对某个类型的方法调用,其真正执行的方法取决于运行时期实际类型的方法
- 抽象:为抽象类本身被设计成只能用于被继承,因此,抽象类可以强迫子类实现其定义的抽象方法,否则编译会报错。因此,抽象方法实际上相当于定义了“规范
- 抽象:父类的方法本身不需要实现任何功能,仅仅是为了定义方法签名,目的是让子类去覆写它,
- 面向抽象:
上层代码只定义规范(例如:abstract class Person);
不需要子类就可以实现业务逻辑(正常编译);
具体的业务逻辑由不同的子类实现,调用者并不关心。
如果不实现抽象方法,则该子类仍是一个抽象类; - 抽象与接口
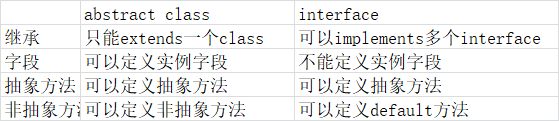
- 接口:接口继承
一个interface可以继承自另一个interface。interface继承自interface使用extends,它相当于扩展了接口的方法.
interface Hello {
void hello();
}
interface Person extends Hello {
void run();
String getName();
}
静态字段和静态方法
虽然实例可以访问静态字段,但是它们指向的其实都是Person class的静态字段。所以,所有实例共享一个静态字段。
因此,不推荐用实例变量.静态字段去访问静态字段,因为在Java程序中,实例对象并没有静态字段。在代码中,实例对象能访问静态字段只是因为编译器可以根据实例类型自动转换为类名.静态字段来访问静态对象。
推荐用类名来访问静态字段。可以把静态字段理解为描述class本身的字段(非实例字段)。对于上面的代码,更好的写法是:
Person.number = 99;
System.out.println(Person.number);
因为静态方法属于class而不属于实例,因此,静态方法内部,无法访问this变量,也无法访问实例字段,它只能访问静态字段。
通过实例变量也可以调用静态方法,但这只是编译器自动帮我们把实例改写成类名而已。
通常情况下,通过实例变量访问静态字段和静态方法,会得到一个编译警告。
静态方法经常用于工具类。例如:
Arrays.sort()
Math.random()
静态方法也经常用于辅助方法。注意到Java程序的入口main()也是静态方法
接口的静态字段
因为interface是一个纯抽象类,所以它不能定义实例字段。但是,interface是可以有静态字段的,并且静态字段必须为final类型:
public interface Person {
public static final int MALE = 1;
public static final int FEMALE = 2;
}
实际上,因为interface的字段只能是public static final类型,所以我们可以把这些修饰符都去掉,上述代码可以简写为:
public interface Person {
// 编译器会自动加上public statc final:
int MALE = 1;
int FEMALE = 2;
}
编译器会自动把该字段变为public static final类型。
包
要特别注意:包没有父子关系。java.util和java.util.zip是不同的包,两者没有任何继承关系
自动导入的是java.lang包,但类似java.lang.reflect这些包仍需要手动导入
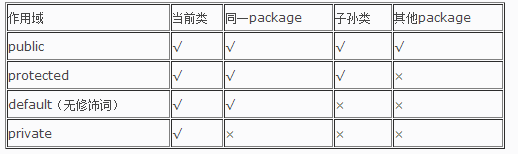
修饰符
一个.java文件只能包含一个public类,但可以包含多个非public类。
classpath和jar
因为Java是编译型语言,源码文件是.java,而编译后的.class文件才是真正可以被JVM执行的字节码。因此,JVM需要知道,如果要加载一个abc.xyz.Hello的类,应该去哪搜索对应的Hello.class文件。
所以,classpath就是一组目录的集合,它设置的搜索路径与操作系统相关。例如,在Windows系统上,用;分隔,带空格的目录用""括起来,可能长这样:
C:\work\project1\bin;C:\shared;“D:\My Documents\project1\bin”
在Linux系统上,用:分隔,可能长这样:
/usr/shared:/usr/local/bin:/home/liaoxuefeng/bin
现在我们假设classpath是.;C:\work\project1\bin;C:\shared,当JVM在加载abc.xyz.Hello这个类时,会依次查找:
<当前目录>\abc\xyz\Hello.class
C:\work\project1\bin\abc\xyz\Hello.class
C:\shared\abc\xyz\Hello.class
注意到.代表当前目录。如果JVM在某个路径下找到了对应的class文件,就不再往后继续搜索。如果所有路径下都没有找到,就报错。
classpath的设定方法有两种:
在系统环境变量中设置classpath环境变量,不推荐;
在启动JVM时设置classpath变量,推荐。
不要把任何Java核心库添加到classpath中!JVM根本不依赖classpath加载核心库!
更好的做法是,不要设置classpath!默认的当前目录.对于绝大多数情况都够用了。
jar
jar包里的第一层目录,不能是bin,而应该是hong、ming、mr。
字符串和编码
- 大写"HELLO".toLowerCase();
- 是否包含字串"Hello".contains(“ll”); // true
- 搜索字串
"Hello".indexOf("l"); // 2
"Hello".lastIndexOf("l"); // 3
"Hello".startsWith("He"); // true
"Hello".endsWith("lo"); // true
- 提取字串
"Hello".substring(2); // "llo"
"Hello".substring(2, 4); "ll"
5.去除字符串
使用trim()方法可以移除字符串首尾空白字符。空白字符包括空格,\t,\r,\n:
" \tHello\r\n ".trim(); // "Hello"
另一个strip()方法也可以移除字符串首尾空白字符。它和trim()不同的是,
类似中文的空格字符\u3000也会被移除
"\u3000Hello\u3000".strip(); // "Hello"
" Hello ".stripLeading(); // "Hello "
" Hello ".stripTrailing(); // " Hello"
- 判断字符串
"".isEmpty(); // true,因为字符串长度为0
" ".isEmpty(); // false,因为字符串长度不为0
" \n".isBlank(); // true,因为只包含空白字符
" Hello ".isBlank(); // false,因为包含非空白字符
6.其他
替换子串
要在字符串中替换子串,有两种方法。一种是根据字符或字符串替换:
String s = "hello";
s.replace('l', 'w'); // "hewwo",所有字符'l'被替换为'w'
s.replace("ll", "~~"); // "he~~o",所有子串"ll"被替换为"~~"
另一种是通过正则表达式替换:
String s = "A,,B;C ,D";
s.replaceAll("[\\,\\;\\s]+", ","); // "A,B,C,D"
上面的代码通过正则表达式,把匹配的子串统一替换为","。关于正则表达式的用法我们会在后面详细讲解。
分割字符串
要分割字符串,使用split()方法,并且传入的也是正则表达式:
String s = "A,B,C,D";
String[] ss = s.split("\\,"); // {"A", "B", "C", "D"}
拼接字符串
拼接字符串使用静态方法join(),它用指定的字符串连接字符串数组:
String[] arr = {"A", "B", "C"};
String s = String.join("***", arr); // "A***B***C"
格式化字符串
字符串提供了formatted()方法和format()静态方法,可以传入其他参数,替换占位符,然后生成新的字符串:
public class Main {
public static void main(String[] args) {
String s = "Hi %s, your score is %d!";
System.out.println(s.formatted("Alice", 80));
System.out.println(String.format("Hi %s, your score is %.2f!", "Bob", 59.5));
}
}
7.类型转换
String.valueOf(123); // "123"
String.valueOf(45.67); // "45.67"
String.valueOf(true); // "true"
String.valueOf(new Object()); // 类似java.lang.Object@636be97c
int n1 = Integer.parseInt("123"); // 123
int n2 = Integer.parseInt("ff", 16); // 按十六进制转换,255
//Integer有个getInteger(String)方法,它不是将字符串转换为int,而是把该字符串对应的系统变量转换为Integer
Integer.getInteger("java.version"); // 版本号,11
char[] cs = "Hello".toCharArray(); // String -> char[]
String s = new String(cs); // char[] -> String
编码
转换编码后,就不再是char类型,而是byte类型表示的数组。
byte[] b1 = "Hello".getBytes(); // 按ISO8859-1编码转换,不推荐
byte[] b2 = "Hello".getBytes("UTF-8"); // 按UTF-8编码转换
byte[] b2 = "Hello".getBytes("GBK"); // 按GBK编码转换
byte[] b3 = "Hello".getBytes(StandardCharsets.UTF_8); // 按UTF-8编码转换
byte[] b = ...
String s1 = new String(b, "GBK"); // 按GBK转换
String s2 = new String(b, StandardCharsets.UTF_8); // 按UTF-8转换
Java的String和char在内存中总是以Unicode编码表示
StringBuider(线程安全)
它是一个可变对象,可以预分配缓冲区,这样,往StringBuilder中新增字符时,
不会创建新的临时对象
StringBuilder sb = new StringBuilder(1024);
for (int i = 0; i < 1000; i++) {
sb.append(',');
sb.append(i);
}
String s = sb.toString();
包装类型
基本类型:byte,short,int,long,boolean,float,double,char
引用类型:所有class和interface类型
引用类型可以赋值为null,表示空,但基本类型不能赋值为null:
String s = null;
int n = null; // compile error!
自动拆箱(Integer->int)和装箱(int->Integer)
int i = 100;
Integer n = Integer.valueOf(i);
int x = n.intValue();
所有的包装类型都是不变类。我们查看Integer的源码可知,它的核心代码如下:
public final class Integer {
private final int value;
}
因此,一旦创建了Integer对象,该对象就是不变的。
对两个Integer实例进行比较要特别注意:绝对不能用==比较,
因为Integer是引用类型,必须使用equals()比较;
指定进制
public class Main {
public static void main(String[] args) {
System.out.println(Integer.toString(100)); // "100",表示为10进制
System.out.println(Integer.toString(100, 36)); // "2s",表示为36进制
System.out.println(Integer.toHexString(100)); // "64",表示为16进制
System.out.println(Integer.toOctalString(100)); // "144",表示为8进制
System.out.println(Integer.toBinaryString(100)); // "1100100",表示为2进制
}
}
所有的整数和浮点数的包装类型都继承自Number,因此,可以非常方便地直接通过包装类型获取各种基本类型:
// 向上转型为Number:
Number num = new Integer(999);
// 获取byte, int, long, float, double:
byte b = num.byteValue();
int n = num.intValue();
long ln = num.longValue();
float f = num.floatValue();
double d = num.doubleValue();
JavaBean
//要枚举一个JavaBean的所有属性,可以直接使用Java核心库提供的Introspector
public class Main {
public static void main(String[] args) throws Exception {
BeanInfo info = Introspector.getBeanInfo(Person.class);
for (PropertyDescriptor pd : info.getPropertyDescriptors()) {
System.out.println(pd.getName());
System.out.println(" " + pd.getReadMethod());
System.out.println(" " + pd.getWriteMethod());
}
}
}
class Person {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
枚举
没有使用枚举前,编译器不会报错
public class Weekday {
public static final int SUN = 0;
public static final int MON = 1;
public static final int TUE = 2;
public static final int WED = 3;
public static final int THU = 4;
public static final int FRI = 5;
public static final int SAT = 6;
}
使用这些常量来表示一组枚举值的时候,有一个严重的问题就是,编译器无法检查每个值的合理性。例如:
if (weekday == 6 || weekday == 7) {
if (tasks == Weekday.MON) {
// TODO:
}
}
上述代码编译和运行均不会报错,但存在两个问题:
注意到Weekday定义的常量范围是0~6,并不包含7,编译器无法检查不在枚举中的int值;
定义的常量仍可与其他变量比较,但其用途并非是枚举星期值。
使用枚举后(enum)
为了让编译器能自动检查某个值在枚举的集合内,并且,不同用途的枚举需要不同的类型来标记,不能混用,我们可以使用enum来定义枚举类
public class Main {
public static void main(String[] args) {
Weekday day = Weekday.SUN;
if (day == Weekday.SAT || day == Weekday.SUN) {
System.out.println("Work at home!");
} else {
System.out.println("Work at office!");
}
}
}
enum Weekday {
SUN, MON, TUE, WED, THU, FRI, SAT;
}
注意到定义枚举类是通过关键字enum实现的,我们只需依次列出枚举的常量名。
和int定义的常量相比,使用enum定义枚举有如下好处:
首先,enum常量本身带有类型信息,即Weekday.SUN类型是Weekday,编译器会自动检查出类型错误。例如,下面的语句不可能编译通过:
int day = 1;
if (day == Weekday.SUN) { // Compile error: bad operand types for binary operator '=='
}
其次,不可能引用到非枚举的值,因为无法通过编译。
最后,不同类型的枚举不能互相比较或者赋值,因为类型不符。例如,不能给一个Weekday枚举类型的变量赋值为Color枚举类型的值:
Weekday x = Weekday.SUN; // ok!
Weekday y = Color.RED; // Compile error: incompatible types
这就使得编译器可以在编译期自动检查出所有可能的潜在错误。
通过enum定义的枚举类,和其他的class有什么区别?
答案是没有任何区别。enum定义的类型就是class,只不过它有以下几个特点:
定义的enum类型总是继承自java.lang.Enum,且无法被继承;
只能定义出enum的实例,而无法通过new操作符创建enum的实例;
定义的每个实例都是引用类型的唯一实例;
可以将enum类型用于switch语句。
我们自己无法按定义普通class那样来定义enum,必须使用enum关键字,这是Java语法规定的。
因为enum是一个class,每个枚举的值都是class实例
name()
返回常量名,例如:
String s = Weekday.SUN.name(); // "SUN"
ordinal()
返回定义的常量的顺序,从0开始计数,例如:
int n = Weekday.MON.ordinal(); // 1
改变枚举常量定义的顺序就会导致ordinal()返回值发生变化。例如:
public enum Weekday {
SUN, MON, TUE, WED, THU, FRI, SAT;
}
和
public enum Weekday {
MON, TUE, WED, THU, FRI, SAT, SUN;
}
的ordinal就是不同的。如果在代码中编写了类似if(x.ordinal()==1)这样的语句,就要保证enum的枚举顺序不能变。新增的常量必须放在最后。
有些童鞋会想,Weekday的枚举常量如果要和int转换,使用ordinal()不是非常方便?比如这样写:
String task = Weekday.MON.ordinal() + "/ppt";
saveToFile(task);
但是,如果不小心修改了枚举的顺序,编译器是无法检查出这种逻辑错误的。要编写健壮的代码,就不要依靠ordinal()的返回值。因为enum本身是class,所以我们可以定义private的构造方法,并且,给每个枚举常量添加字段:
默认情况下,对枚举常量调用toString()会返回和name()一样的字符串。但是,toString()可以被覆写,而name()则不行。我们可以给Weekday添加toString()方法:
// enum
public class Main {
public static void main(String[] args) {
Weekday day = Weekday.SUN;
if (day.dayValue == 6 || day.dayValue == 0) {
System.out.println("Work at home!");
} else {
System.out.println("Work at office!");
}
}
}
enum Weekday {
MON(1), TUE(2), WED(3), THU(4), FRI(5), SAT(6), SUN(0);
public final int dayValue;
private Weekday(int dayValue) {
this.dayValue = dayValue;
}
}
public class Main {
public static void main(String[] args) {
Weekday day = Weekday.SUN;
if (day.dayValue == 6 || day.dayValue == 0) {
System.out.println("Today is " + day + ". Work at home!");
} else {
System.out.println("Today is " + day + ". Work at office!");
}
}
}
enum Weekday {
MON(1, "星期一"), TUE(2, "星期二"), WED(3, "星期三"), THU(4, "星期四"), FRI(5, "星期五"), SAT(6, "星期六"), SUN(0, "星期日");
public final int dayValue;
private final String chinese;
private Weekday(int dayValue, String chinese) {
this.dayValue = dayValue;
this.chinese = chinese;
}
@Override
public String toString() {
return this.chinese;
}
}
BigInteger&&BigDecimal
java.math.BigInteger就是用来表示任意大小的整数(任意精度准确)
BigInteger内部用一个int[]数组来模拟一个非常大的整数
对BigInteger做运算的时候,只能使用实例方法,例如,加法运算:
BigInteger i1 = new BigInteger("1234567890");
BigInteger i2 = new BigInteger("12345678901234567890");
BigInteger sum = i1.add(i2); // 12345678902469135780
和long型整数运算比,BigInteger不会有范围限制,但缺点是速度比较慢。
BigInteger和Integer、Long一样,也是不可变类,并且也继承自Number类。因为Number定义了转换为基本类型的几个方法:
转换为byte:byteValue()
转换为short:shortValue()
转换为int:intValue()
转换为long:longValue()
转换为float:floatValue()
转换为double:doubleValue()
因此,通过上述方法,可以把BigInteger转换成基本类型。如果BigInteger表示的范
围超过了基本类型的范围,转换时将丢失高位信息,即结果不一定是准确的。如果需
要准确地转换成基本类型,可以使用intValueExact()、longValueExact()等方法,
在转换时如果超出范围,将直接抛出ArithmeticException异常。
和BigInteger类似,BigDecimal可以表示一个任意大小且精度完全准确的浮点数。
BigDecimal用scale()表示小数位数,例如:
BigDecimal d1 = new BigDecimal("123.45");
BigDecimal d2 = new BigDecimal("123.4500");
BigDecimal d3 = new BigDecimal("1234500");
System.out.println(d1.scale()); // 2,两位小数
System.out.println(d2.scale()); // 4
System.out.println(d3.scale()); // 0
通过BigDecimal的stripTrailingZeros()方法,可以将一个BigDecimal格式化为一个相等的,但去掉了末尾0的BigDecimal:
BigDecimal d1 = new BigDecimal("123.4500");
BigDecimal d2 = d1.stripTrailingZeros();
System.out.println(d1.scale()); // 4
System.out.println(d2.scale()); // 2,因为去掉了00
BigDecimal d3 = new BigDecimal("1234500");
BigDecimal d4 = d3.stripTrailingZeros();
System.out.println(d3.scale()); // 0
System.out.println(d4.scale()); // -2
对BigDecimal做加、减、乘时,精度不会丢失,但是做除法时,存在无法除尽的情况,这时,就必须指定精度以及如何进行截断:
BigDecimal d1 = new BigDecimal("123.456");
BigDecimal d2 = new BigDecimal("23.456789");
BigDecimal d3 = d1.divide(d2, 10, RoundingMode.HALF_UP); // 保留10位小数并四舍五入
BigDecimal d4 = d1.divide(d2); // 报错:ArithmeticException,因为除不尽
还可以对BigDecimal做除法的同时求余数:
public class Main {
public static void main(String[] args) {
BigDecimal n = new BigDecimal("12.345");
BigDecimal m = new BigDecimal("0.12");
BigDecimal[] dr = n.divideAndRemainder(m);
System.out.println(dr[0]); // 102
System.out.println(dr[1]); // 0.105
}
}
比较BigDecimal
在比较两个BigDecimal的值是否相等时,要特别注意,使用equals()方法不但要求两个BigDecimal的值相等,还要求它们的scale()相等:
BigDecimal d1 = new BigDecimal("123.456");
BigDecimal d2 = new BigDecimal("123.45600");
System.out.println(d1.equals(d2)); // false,因为scale不同
System.out.println(d1.equals(d2.stripTrailingZeros())); // true,因为d2去除尾部0后scale变为2
System.out.println(d1.compareTo(d2)); // 0
必须使用compareTo()方法来比较,它根据两个值的大小分别返回负数、正数和0,分别表示小于、大于和等于。
总是使用compareTo()比较两个BigDecimal的值,不要使用equals()!
常用工具类
ava的核心库提供了大量的现成的类供我们使用。本节我们介绍几个常用的工具类。
Math
顾名思义,Math类就是用来进行数学计算的,它提供了大量的静态方法来便于我们实现数学计算:
求绝对值:
Math.abs(-100); // 100
Math.abs(-7.8); // 7.8
取最大或最小值:
Math.max(100, 99); // 100
Math.min(1.2, 2.3); // 1.2
计算xy次方:
Math.pow(2, 10); // 2的10次方=1024
计算√x:
Math.sqrt(2); // 1.414...
计算ex次方:
Math.exp(2); // 7.389...
计算以e为底的对数:
Math.log(4); // 1.386...
计算以10为底的对数:
Math.log10(100); // 2
三角函数:
Math.sin(3.14); // 0.00159...
Math.cos(3.14); // -0.9999...
Math.tan(3.14); // -0.0015...
Math.asin(1.0); // 1.57079...
Math.acos(1.0); // 0.0
Math还提供了几个数学常量:
double pi = Math.PI; // 3.14159...
double e = Math.E; // 2.7182818...
Math.sin(Math.PI / 6); // sin(π/6) = 0.5
生成一个随机数x,x的范围是0 <= x < 1:
Math.random(); // 0.53907... 每次都不一样
如果我们要生成一个区间在[MIN, MAX)的随机数,可以借助Math.random()实现,计算如下:
// 区间在[MIN, MAX)的随机数
public class Main {
public static void main(String[] args) {
double x = Math.random(); // x的范围是[0,1)
double min = 10;
double max = 50;
double y = x * (max - min) + min; // y的范围是[10,50)
long n = (long) y; // n的范围是[10,50)的整数
System.out.println(y);
System.out.println(n);
}
}
Random
Random用来创建伪随机数。所谓伪随机数,是指只要给定一个初始的种子,产生的随机数序列是完全一样的。
要生成一个随机数,可以使用nextInt()、nextLong()、nextFloat()、nextDouble():
Random r = new Random();
r.nextInt(); // 2071575453,每次都不一样
r.nextInt(10); // 5,生成一个[0,10)之间的int
r.nextLong(); // 8811649292570369305,每次都不一样
r.nextFloat(); // 0.54335...生成一个[0,1)之间的float
r.nextDouble(); // 0.3716...生成一个[0,1)之间的double
有童鞋问,每次运行程序,生成的随机数都是不同的,没看出伪随机数的特性来。
这是因为我们创建Random实例时,如果不给定种子,就使用系统当前时间戳作为种子,因此每次运行时,种子不同,得到的伪随机数序列就不同。
如果我们在创建Random实例时指定一个种子,就会得到完全确定的随机数序列:
import java.util.Random;
public class Main {
public static void main(String[] args) {
Random r = new Random(12345);
for (int i = 0; i < 10; i++) {
System.out.println(r.nextInt(100));
}
// 51, 80, 41, 28, 55...
}
}
Run
前面我们使用的Math.random()实际上内部调用了Random类,所以它也是伪随机数,只是我们无法指定种子。
SecureRandom
有伪随机数,就有真随机数。实际上真正的真随机数只能通过量子力学原理来获取,而我们想要的是一个不可预测的安全的随机数,SecureRandom就是用来创建安全的随机数的:
SecureRandom sr = new SecureRandom();
System.out.println(sr.nextInt(100));
SecureRandom无法指定种子,它使用RNG(random number generator)算法。JDK的SecureRandom实际上有多种不同的底层实现,有的使用安全随机种子加上伪随机数算法来产生安全的随机数,有的使用真正的随机数生成器。实际使用的时候,可以优先获取高强度的安全随机数生成器,如果没有提供,再使用普通等级的安全随机数生成器:
import java.util.Arrays;
import java.security.SecureRandom;
import java.security.NoSuchAlgorithmException;
public class Main {
public static void main(String[] args) {
SecureRandom sr = null;
try {
sr = SecureRandom.getInstanceStrong(); // 获取高强度安全随机数生成器
} catch (NoSuchAlgorithmException e) {
sr = new SecureRandom(); // 获取普通的安全随机数生成器
}
byte[] buffer = new byte[16];
sr.nextBytes(buffer); // 用安全随机数填充buffer
System.out.println(Arrays.toString(buffer));
}
}
SecureRandom的安全性是通过操作系统提供的安全的随机种子来生成随机数。这个种子是通过CPU的热噪声、读写磁盘的字节、网络流量等各种随机事件产生的“熵”。
在密码学中,安全的随机数非常重要。如果使用不安全的伪随机数,所有加密体系都将被攻破。因此,时刻牢记必须使用SecureRandom来产生安全的随机数。
需要使用安全随机数的时候,必须使用SecureRandom,绝不能使用Random!
需要使用安全随机数的时候,必须使用SecureRandom,绝不能使用Random!
异常
Java异常

Java规定:
必须捕获的异常,包括Exception及其子类,但不包括RuntimeException及其子类,这种类型的异常称为Checked Exception。
不需要捕获的异常,包括Error及其子类,RuntimeException及其子类。
直接把main()方法定义为throws Exception;因为main()方法声明了可能抛出Exception,也就声明了可能抛出所有的Exception,因此在内部就无需捕获了。代价就是一旦发生异常,程序会立刻退出。
如果我们不捕获UnsupportedEncodingException,会出现编译失败的问题:
// try...catch
import java.io.UnsupportedEncodingException;
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
byte[] bs = toGBK("中文");
System.out.println(Arrays.toString(bs));
}
static byte[] toGBK(String s) {
return s.getBytes("GBK");
}
}
Run
编译器会报错,错误信息类似:unreported exception UnsupportedEncodingException; must be caught or declared to be thrown,并且准确地指出需要捕获的语句是return s.getBytes("GBK");。意思是说,像UnsupportedEncodingException这样的Checked Exception,必须被捕获。
这是因为String.getBytes(String)方法定义是:
public byte[] getBytes(String charsetName) throws UnsupportedEncodingException {
...
}
在方法定义的时候,使用throws Xxx表示该方法可能抛出的异常类型。调用方在调用的时候,必须强制捕获这些异常,否则编译器会报错。
在toGBK()方法中,因为调用了String.getBytes(String)方法,就必须捕获UnsupportedEncodingException。我们也可以不捕获它,而是在方法定义处用throws表示toGBK()方法可能会抛出UnsupportedEncodingException,就可以让toGBK()方法通过编译器检查:
捕获异常
多catch语句
可以使用多个catch语句,每个catch分别捕获对应的Exception及其子类。JVM在捕获到异常后,会从上到下匹配catch语句,匹配到某个catch后,执行catch代码块,然后不再继续匹配。
存在多个catch的时候,catch的顺序非常重要:子类必须写在前面
简单地说就是:多个catch语句只有一个能被执行。例如:
public static void main(String[] args) {
try {
process1();
process2();
process3();
} catch (IOException e) {
System.out.println(e);
} catch (NumberFormatException e) {
System.out.println(e);
}
}
捕获多种异常
如果某些异常的处理逻辑相同,但是异常本身不存在继承关系,那么就得编写多条catch子句:
public static void main(String[] args) {
try {
process1();
process2();
process3();
} catch (IOException e) {
System.out.println("Bad input");
} catch (NumberFormatException e) {
System.out.println("Bad input");
} catch (Exception e) {
System.out.println("Unknown error");
}
}
因为处理IOException和NumberFormatException的代码是相同的,所以我们可以把它两用|合并到一起:
public static void main(String[] args) {
try {
process1();
process2();
process3();
} catch (IOException | NumberFormatException e) { // IOException或NumberFormatException
System.out.println("Bad input");
} catch (Exception e) {
System.out.println("Unknown error");
}
}
##抛出异常
异常的传播
当某个方法抛出了异常时,如果当前方法没有捕获异常,异常就会被抛到上层调用方法,直到遇到某个try ... catch被捕获为止:
// exception
public class Main {
public static void main(String[] args) {
try {
process1();
} catch (Exception e) {
e.printStackTrace();
}
}
static void process1() {
process2();
}
static void process2() {
Integer.parseInt(null); // 会抛出NumberFormatException
}
}
异常的转换
如果在main()中捕获IllegalArgumentException,我们看看打印的异常栈:
// exception
public class Main {
public static void main(String[] args) {
try {
process1();
} catch (Exception e) {
e.printStackTrace();
}
}
static void process1() {
try {
process2();
} catch (NullPointerException e) {
throw new IllegalArgumentException();
}
}
static void process2() {
throw new NullPointerException();
}
}
Run
打印出的异常栈类似:
java.lang.IllegalArgumentException
at Main.process1(Main.java:15)
at Main.main(Main.java:5)
这说明新的异常丢失了原始异常信息,我们已经看不到原始异常NullPointerException的信息了。
为了能追踪到完整的异常栈,在构造异常的时候,把原始的Exception实例传进去,新的Exception就可以持有原始Exception信息。对上述代码改进如下:
// exception
public class Main {
public static void main(String[] args) {
try {
process1();
} catch (Exception e) {
e.printStackTrace();
}
}
static void process1() {
try {
process2();
} catch (NullPointerException e) {
throw new IllegalArgumentException(e);
}
}
static void process2() {
throw new NullPointerException();
}
}
finally
如果我们在try或者catch语句块中抛出异常,finally语句是否会执行?例如
public class Main {
public static void main(String[] args) {
try {
Integer.parseInt("abc");
} catch (Exception e) {
System.out.println("catched");
throw new RuntimeException(e);
} finally {
System.out.println("finally");
}
}
}
第一行打印了catched,说明进入了catch语句块。第二行打印了finally,说明执行了finally语句块。
因此,在catch中抛出异常,不会影响finally的执行。JVM会先执行finally,然后抛出异常。
异常屏蔽
异常屏蔽
如果在执行finally语句时抛出异常,那么,catch语句的异常还能否继续抛出?例如:
// exception
public class Main {
public static void main(String[] args) {
try {
Integer.parseInt("abc");
} catch (Exception e) {
System.out.println("catched");
throw new RuntimeException(e);
} finally {
System.out.println("finally");
throw new IllegalArgumentException();
}
}
}
执行上述代码,发现异常信息如下:
catched
finally
Exception in thread "main" java.lang.IllegalArgumentException
at Main.main(Main.java:11)
这说明finally抛出异常后,原来在catch中准备抛出的异常就“消失”了,因为只能抛出一个异常。没有被抛出的异常称为“被屏蔽”的异常(Suppressed Exception)
绝大多数情况下,在finally中不要抛出异常。因此,我们通常不需要关心Suppressed Exception。
自定义异常
在一个大型项目中,可以自定义新的异常类型,但是,保持一个合理的异常继承体系是非常重要的。
一个常见的做法是自定义一个BaseException作为“根异常”,然后,派生出各种业务类型的异常。
BaseException需要从一个适合的Exception派生,通常建议从RuntimeException派生:
public class BaseException extends RuntimeException {
}
其他业务类型的异常就可以从BaseException派生:
public class UserNotFoundException extends BaseException {
}
public class LoginFailedException extends BaseException {
}
...
自定义的BaseException应该提供多个构造方法:
public class BaseException extends RuntimeException {
public BaseException() {
super();
}
public BaseException(String message, Throwable cause) {
super(message, cause);
}
public BaseException(String message) {
super(message);
}
public BaseException(Throwable cause) {
super(cause);
}
}
空指针异常
使用空字符串"" 空数组 而不是默认的null可避免很多NullPointerException,
编写业务逻辑时,用空字符串""表示未填写比null安全得多
如果产生了NullPointerException,例如,调用a.b.c.x()时产生了NullPointerException,原因可能是:
a是null;
a.b是null;
a.b.c是null;















 206
206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









