







常用单词:
Array: 数组
LinkedList:链表
list:线性表
stack: 栈
queue: 队列
链表
基本介绍
四种常见的链表包括:单向链表,单向循环链表,双向链表,双向循环链表
栈

括号匹配, 浏览器后退功能(历史记录)


队列

消息队列: 中间件,用于系统间的解耦,异步
https://www.zhihu.com/question/54152397?sort=created



树
概念串:
1.二叉树概念:节点(节点度degree,层次level,深度depth), 子节点父节点兄弟节点(child,parent,sibling), 森林(forest)几个树的集合
2.两种二叉树类别:
~普通二叉树-- 满二叉树 –完全二叉树(满二叉树一定是完全二叉树)-堆.
~二叉树 --二叉搜索树(BST) – 平衡二叉搜索树(AVL)
只有完全二叉树才可以使用顺序表存储:即堆

堆性质: 用数组连续存储(存储结构)的节点值大于子节点值(功能逻辑结构)的完全二叉树(基本逻辑结构)
应用:堆排序
1.通过子节点与父节点的递归比较,建立堆,把最大堆堆顶的最大数取出,
2.通过子节点与父节点的递归比较,将剩余的堆继续调整为最大堆,再次将堆顶的最大数取出
平衡二叉查找树(binary search tree)-- AVL
用链表实现(存储结构)的左子树-根-右子树为小-中-大结构(功能逻辑结构)的二叉树(基本逻辑结构)。 本质即层次性的二分查找
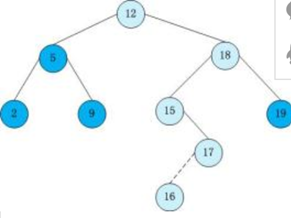
应用:二分查找
如果想查找某个数字X,从根节点开始比较。如果X比根节点大,则去与根节点的右节点比较,如此类推,直到找到X(或子节点为空)为止。
例:如果想找25:从根节点开始比较:25>15。去根节点右边,与下一个节点(20)比较,结果25>20。接着去右边,与下一个节点(25)比较,结果25=25,查找成功
-平衡二叉查找树:基于二叉查找树的优化,优化其时间复杂度
二叉查找树的形状不固定,如果变成线性排列的话,查找速度变为遍历,效率极低。
1.引入平衡因子机制。 左子树深度与右子树深度相差不大于一, 就说明这棵树平衡

2.最小不平衡子树:

3.平衡二叉查找树应用:将二叉查找树通过旋转 ,变为平衡二叉查找树
按照平衡二叉树的插入方式插入一个元素,使得整个树不平衡了
1.找到要调整的三个点:判断每棵子树的平衡因子,找到最小不平衡树
从最小不平衡树的根节点走向插入的元素(导致不平衡的元素),最先经过的三个点就是要调整的三个点
2.如何调整(中序遍历+搜索树性质):对整棵树进行一次中序遍历,三个点的前中后位置就是旋转后应该在的位置 + 二叉搜索树的性质(左根右大小)
对排序树进行一次中序遍历,实际上就是树节点从小到大的序列
图
图:概念递增关系: 无向图(边edge)-- 有向图(Arc弧,出度入度Degree)–网network(权weight)
顶点vertex
顶点到顶点: path
1.树的前中后序遍历
树的遍历就是递归的进行 根左右,左根右,左右根的访问
所谓遍历就是:大树化小树,小树化元素。 左根右 指的是 左子树,根,右子树
BFS在树遍历中就是层序遍历
前序遍历就是右手原则的深度优先遍历
2.深度,广度优先遍历
深度优先遍历
1.固定一个方向递进下去 2.回溯上来。
顾名思义,深度优先,则是以深度为准则,先一条路走到底,直到达到目标。这里称之为递归下去。
否则既没有达到目标又无路可走了,那么则退回到上一步的状态,走其他路。这便是回溯上来。(右手原则) 右手原则指的是自己代入迷宫的 第一视角,面对岔路口只走最右手
广度优先遍历:
一层层的向外延伸, 一次只延伸一层节点。
3.最小生成树: 解决连通权值和最小问题(Krusca,Prim)
.Kruscal算法:在不构成环的前提下,一直取图中的最小边(以边为导向)连通9个点,就需要至少8个边
Prim算法:在不构成环的前提下,一直找离最小生成树最近的点并接入最小生成树(以点为导向),每次只能取一个点和一个边

两者比较: 最终的结果肯定是相同的
1.Prim算法是直接查找,多次寻找邻边的权重最小值,而Kruskal是需要先对权重排序后查找的
2.Kruskal在算法效率上是比Prim快的,因为Kruskal只需一次对权重的排序就能找到最小生成树,而Prim算法需要多次对邻边排序才能找到
3.边比较少时(边比点少),用Kruscal算法
点少时,用prim算法
–最短路径算法:求从一个顶点出发,到任意一个点的最短路径(Dijkstra迪杰斯特拉)
1.访问距离起始点最近的点B
2.计算B点所有邻接点到起始点A的距离(即起始点到B点的距离+B到邻接点的距离)
3.与表中路径比较, 如果比已知最短路径更短, 更新路径和距离
4.完成对B点的访问,将B点移出unvisit序列
重复上述步骤
核心思想是基于已知的最短路径,逐步比较出其他最短路径。然后比较出了到每个点的最短路径

访问一个点,得到新路径,比较之前已有路径得出最短距离,完成访问所有点,也就找到了起始点到所有点的最短距离
哈希表
哈希表: 顺序(逻辑)结构,树形结构,图形结构,哈希表结构
哈希表是一种基本逻辑结构(与线性,树,图并列),特点是
哈希表的元素间没有任何逻辑联系(即元素的索引没有任何联系),即通过哈希表内的一个元素,你无法找到另一个元素
哈希表这种基本逻辑,描述的是元素的地址与元素的值之间的关系。线性表,树,图三种基本逻辑结构描述的是元素间地址的关系
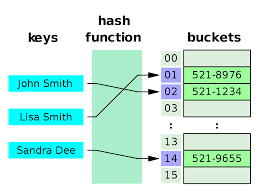
1.采取取余法(mod 12)作为哈希算法: 元素值 – 元素地址索引(即哈希值)
2.采用开放定址法的线性探测(满了就向后插)作为 解决哈希冲突的方法















 20万+
20万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









