










Ceph概述:
概述:Ceph是根据加州大学Santa Cruz分校的Sage Weil的博士论文所设计开发的新一代自由软件分布式文件系统,其设计目标是良好的可扩展性(PB级别以上)、高性能、高可靠性。Ceph其命名和UCSC(Ceph 的诞生地)的吉祥物有关,这个吉祥物是“Sammy”,一个香蕉色的蛞蝓,就是头足类中无壳的软体动物。这些有多触角的头足类动物,是对一个分布式文件系统高度并行的形象比喻。 其设计遵循了三个原则:数据与元数据的分离,动态的分布式的元数据管理,可靠统一的分布式对象存储机制。
Ceph存储架构
ceph存储集群有几个不同的软件守护进程组成,每个守护进程负责Ceph的一个独特功能并添加到相应的组件中。每个守护京城是彼此独立的。这是保持Ceph存储集群比黑匣子似的商业存储系统更加便宜的诸多特性中的一个。下图简要阐述了每个Ceph组件的功能;
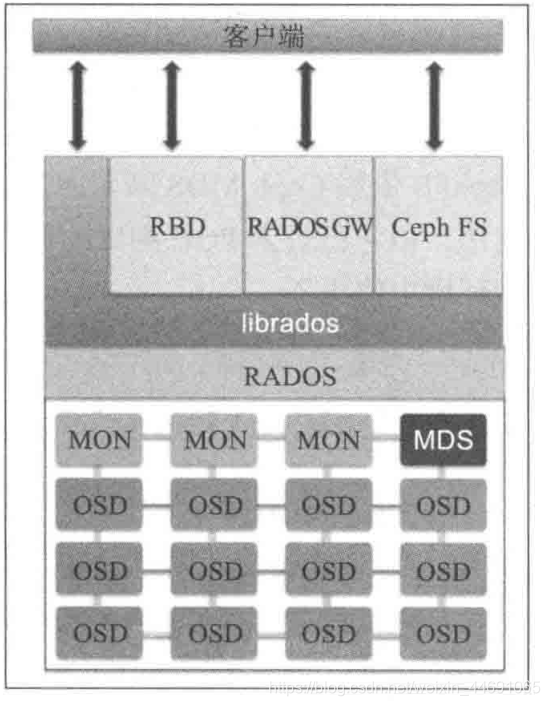
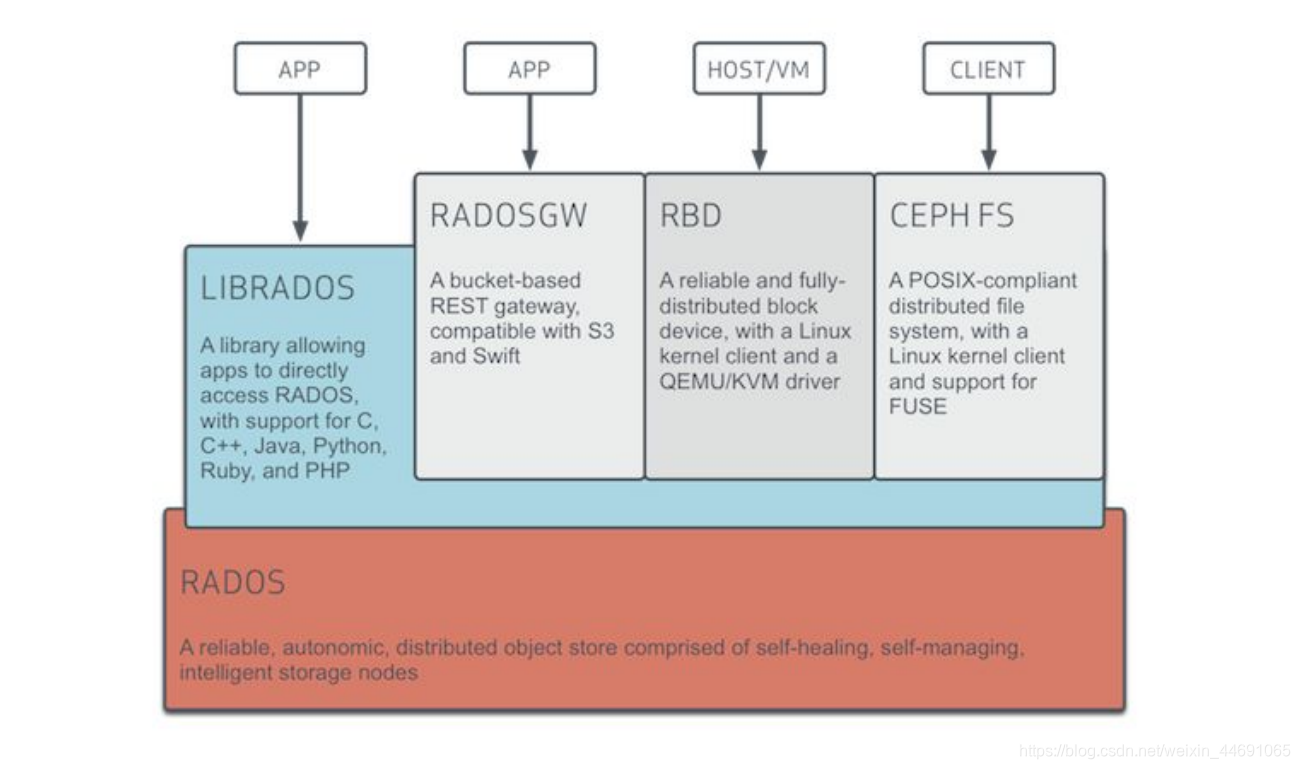
Ceph的底层是RADOS(Reliable Autonomic Distributed Object Store 可靠、自动、分布式对象存储)是Ceph存储的基础。由自恢复、自管理的智能存储节点组成,Ceph中一切都以对象的形式存储,而RADOS就负责存储这些对象,而不考虑他们的数据类型,RADOS层还确保数据的一致性和可靠性。对于数据一致性,它执行数据复制、故障检测与恢复,还包括数据在集群节点间的迁移和再平衡。
Librados 是一个本地C语言库,它允许应用直接访问RADOS的库,这样就可以绕过其他接口层与Ceph集群进行交互,是一种简化访问RADOS的方法,它目前支持PHP、Ruby、Java、Python、C和C++语言。他提供Ceph储存集群的一个本地接口RADOS,并且是其他服务(RBD、RGW、)的基础,以及为CephGW提供POSIX接口。librados支持直接访问RADOS,使得开发者能够创建自己的接口来访问Ceph集群存储。librados提供了丰富的API子集,高效地在一个对象中储存键/值对
RBD(块设备接口)是连接虚拟机,可靠和完全分布式的块设备存储,具有内核和QEMV/KVM两种接口,他们能无缝地访问Ceph块设备。
RADOSGW Ceph对象储存接口,也就是对象网关,也称作RADOS网关,它是一个代理,可以将HTTP请求转换为RADOS,同时也可以把RADOS请求转换为HTTP请求,从而提供RESTful对象存储,与S3和Swift兼容。
CephFS CephFS是一个文件系统,依赖MDS来跟踪文件层次结构(元数据)。Ceph是一个兼容POSIX的文件系统,他利用Ceph储存集群来保存用户数据。Linux内核驱动支持CephFS使得CephFS高度适用于各大Linux操作系统发行版。CephFs将数据和元数据分开存储,为上层的应用程序提供较高的性能以及可靠性。
Ceph MDS 是元数据服务器,只有Ceph文件系统(CephFS)才需要,其他储存方法不需要,如果基于对象不需要MDS服务。
Monitor节点
-
Monitor监控节点,通过一系列的map来跟跟踪整个集群,所有节点必须向mon来报告状态,并分享每一个的状态信息
-
Monitor负责监控整个集群的健康状况,他们以守护进程的形式存在,这些守护进程通过集群的关键信息来维护集群成员的状态、对等节点及集群配置信息;
-
Monitor节点不为客户端存储和提供数据,它为客户端及其他节点提供更新和map服务,客户端和节点定期与mon确认自己持有的是否是最新的map
Cluster map的概念
-OSD故障的仲裁
-Paxos一致性
Cluster map包括:
mon map、OSD map、PG map、CRUSH map及MDS map
Monitor map:它维护这mon节点间端到端的信息,包括Ceph集群的ID、mon节点主机名、IP地址及端口号。它还存储着当前map的创建版本和最后一次修改的信息。
OSD map:它存储着一些行间的信息,如集群的ID,OSD map的创建版本和最后一次修改信息,以及与池相关的信息(如池名字、池ID、类型、副本数、归置组),它还存储着OSD的一些信息,如数目,状态,权重,最近处于clean状态的间隔以及OSD的主机等信息。
PG map:它存储着归置组的版本、时间戳、最新OSD map版本、容量充满的比例以及容量接近充满的比例等信息(占满率)。它同时也跟踪每个归置组的ID、对象数、状态时间戳、OSD的up set、acting set、pg的状态、最后还有各储存池的数据使用情况,统计清洗信息。
MDS map:它存储着当前MDS map版本、map创建和修改时间、数据和元数据池的ID。还包含了存储元数据的存储池,元数据的服务器列表,还有哪些元数据是up或者in的。
CRUSH map(包括四个部分)
Devices: 表示集群中当前或者历史的OSD,如果id对应的OSD在集群中还存在, 那么device的名称就是osd的名称,比如osd.1;如果device id对应的osd在集群中 不存在了,那么device name的名称是device+id,比如device0
Bucket Types: Bucket定义了CRUSH层级结构中Bucket的类型。比如rows, racks, chassis, hosts等
Bucket instances: 对集群中的资源,定义它属于某个类型的bucket。比如物理机 的bucket type为host
Rules: 定义了选择bucket的规则;
CRUSH map 存储着集群的存储信息、故障域的层次结构、OSD的列表、bucket的列表、rule的列表(Rules:故障域中定义如何存储数据的规则。)
一个典型的Ceph集群包含多个mon节点,多mon节点的Ceph架构使用了quorum(仲裁),使用paxos算法为集群提供了分布式决策机制。集群的mon节点应该是奇数个,最低要求是一个,推荐是3个mon节点。开始仲裁操作时,至少保证一半以上的mon节点始终属于可用的状态,这样可以防止脑裂问题;
所谓脑裂问题(类似于精神分裂),就是同一个集群中的不同节点,对于集群的状态有了不一样的理解。
在所有集群mon中,其中有一个领导者leader,如果leader不可用,其他mon也有权成为leader。
OSD节点
-
OSD全称Object Storage Device,存储实际数据,并响应客户端的操作。一个Ceph集群一般都有很多个OSD。一块物理磁盘对应一块osd。
-
OSD分为主OSD和从OSD,是及进行分级存储。
-
每个OSD节点进行互相通讯
-
OSD是对象存储模式,文件系统支持Btrfs、XFS、ext4格式;
MDS节点
-
Ceph MDS是元数据服务器,只有CephFS才需要,MDS作为一个守护进程运行,允许客户端随意挂载一个POSIX文件系统。MDS不像客户端提供数据,数据通过OSD来提供。
-
MDS节点比较占资源,他们需要更强的CPU处理能力,它依赖大量的数据缓存,因为他们需要快速的访问数据
pg(placement group)
-
pg是不可见的,但是在Ceph中扮演非常重要的角色;pg是Ceph执行re-balance时的基本单位。在对象数量比较多时,跟踪pool中每一个对象的位置开销很大。
-
为了高效地跟踪对象的位置,Ceph将一个pool分为多个PG;先将对象分到PG中,然后再将PG放到 primary OSD上。如果一个OSD挂了,Ceph会将存放在这个OSD上的所有PG移动或复制到别的地方。
-
可以将pg看成一个逻辑容器,这个容器包含多个对象,同时这个逻辑容器被映射到多个OSD上,pg是保障Ceph存储系统的可伸缩性和性能必不可少的部分;
pool
-
pool是存储在ceph中对象的逻辑组,
-
pool由pg组成。在创建pool的时候,我们需要提供pool中pg的数量和对象的副本数。 pool会将某个对象按照副本数分布在多个osd上,保证数据的可靠性。
-
ceph集群可以有多个pool 每个pool有多个pg,pg数量在pool创建的时候指定好 一个pg包含多个对象 pg分布在多个osd上面。第一个映射的osd是primary osd,后面的是secondary osd ,很多pg映射到一个osd。
-
池可以通过创建需要的副本数来保障数据的高可用性,比如通过复制或者纠删码的方式。
-
纠删码(EC)特性就是Ceph的新功能,纠删码就是一种数据保护方法,他首先将数据分解成块,接着编码,然后以分布式的的方式去存储。
-
当数据写入一个池的时候,Ceph的池会映射到一个CRUSH规则集,CRUSH规则集就是通过识别池来实现集群内对象的分布和副本数;CRUSH规则集为Ceph提供了新的功能
例如,
-
我们可以创建一个SSD硬盘的faster池,也就是缓存池;
-
缓存池:
-
所有的客户端I/O操作都首先由缓存池处理。之后,再将数据写回到现有的数据池中。客户端能够在缓存池上享受高性能,而它们的数据显而易见最终是被写入到常规池中的。
-
一般来说,缓存层构建在昂贵/速度更快的SSD磁盘上,这样才能为客户提供更好的I/O性能。
CRUSH算法
-
CRUSH是Ceph的只能数据分发机制,是整个Ceph数据存储机制的核心,Ceph使用crush算法来准确的计算数据应该被写入哪里挥着从哪里读取。Crush算法按需计算计算元数据,而不是存储与按市局,从而消除传统的元数据存储方法的所有限制。
-
CRUSH查找
-
CRUSH机制以这样一种方式工作:元数据计算的负载是分布式的并且只在需要时执行,元数据的计算过程也被称作crush查找。
Ceph数据流动方向
Object的磁盘操作
-
Object通过一致性HASH算法存入PG
-
PG通过CRUSH算法,确定要放在哪个OSD中
-
客户端只负责写Primary OSD,由Primary OSD负责将数据复制到其他Slave OSD
-
随机读取任意一个OSD
数据的方向就是:
Data—-> Object—-> PG—-> pool—-> OSD
映射:
(pool_Object)—-> (pool_Pg)—-> (OSD set)—-> Disk
OSD的状态变化-reblance
OSD临时故障
– PGLog
– PG的Replicate OSD接管Primary角色,并记录权威PGLog
– PG减少复制份数
– OSD上线后Primary同步PGlog,replicate发送pull同步数据
OSD永久故障
– PGLog不足以记录所有数据时
– OSD恢复时backfill(回填)介入,primary的backfill会统治monitor将一个
– replicate临时提升为primary
新增OSD
– Monitor将更新后的pgmap发还给OSD,OSD状态为up&out
– OSD与其他相关OSD进行通讯,实现新的Map
– 该OSD与相关OSD之间进行PG数据复制,完成复制后,状态修改为up&in
– 主OSD与从OSD的数据同步
– 6秒一次heartbeat
– 与monitor节点通讯汇报自己的 状态及其他OSD故障
– Up/down
– In/out
Heartbeat作用:
Heartbeat主要用于及时发现OSD的状态变化(down/up),由mon更新osd map 并同步到相关的osd
OSD之间的heartbeat:
选择heartbeat对象,基本就是这个OSD负责的pg,所包含其他OSD0的集合;
比如OSD包含pg1.1、pg1.2、pg1.3
Pg1.1包含OSD0、OSD1、OSD5
Pg1.2包含OSD0、OSD6、OSD7
Pg1.3包含OSD0、OSD2、OSD3
那么OSD的heartbeat对象就是OSD1、OSD2、OSD3、OSD5、OSD6、OSD7
OSD1向mon汇报有OSD down
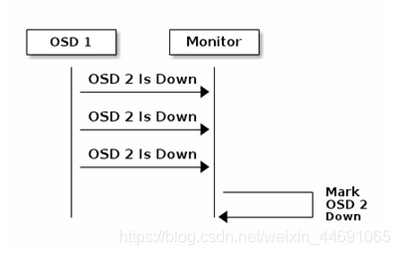
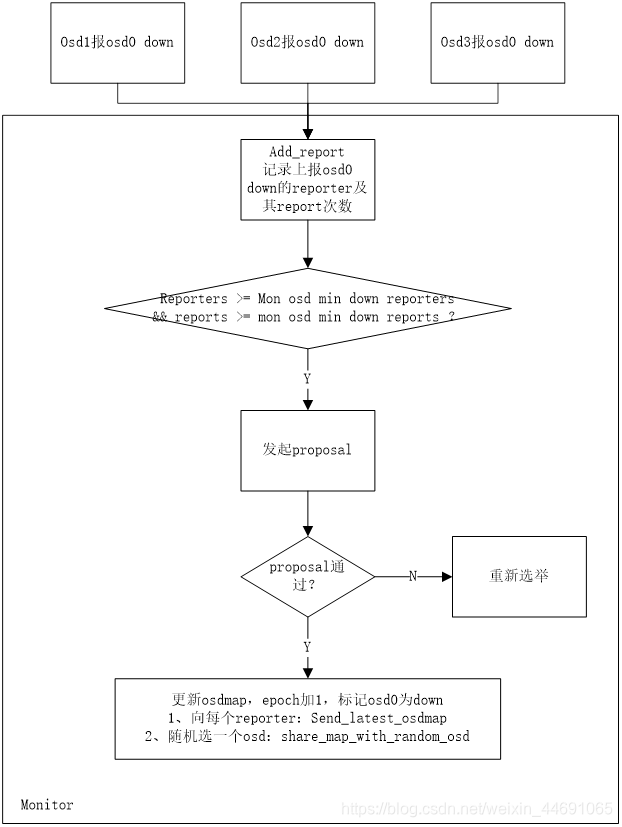
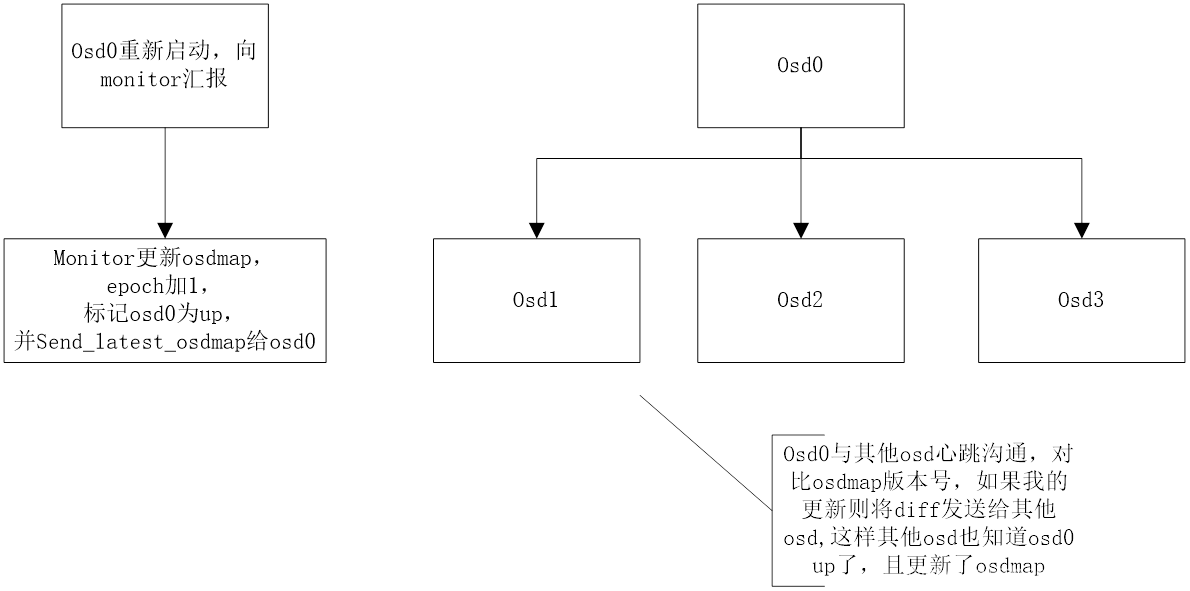
如果osd在peering发起或者进行期间,无法与某个osd连通,则会定时(通过osd mon heartbeat interval配置)ping monitor以获取最新的osdmap。

自汇报
-
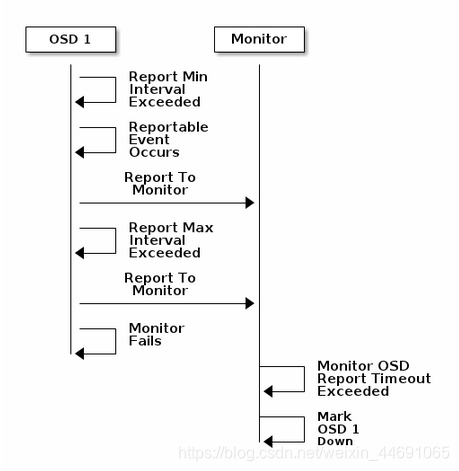
如果osd有需要汇报的事件,比如检测到有osd down、pg map状态变化等,osd会在osd mon report intervalmin配置的事件间隔内,向monitor汇报;否则会在osd mon report intervalmax配置的事件间隔内向monitor汇报。
-
如果osd超过一定时间(可以通过 mon osd reporttimeout配置)没有向monitor汇报,monitor会将osd标记为down。














 321
321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









