利用 PCA 对半导体制造数据降维
数据集secom.data是半导体数据集,该数据集总共590个特征,要求利用pca算法对数据
(1)对数据清洗,清洗的方法就是将每个特征里取值为null值的用该特征的平均值代替。
(2)对清洗后的数据利用pca降维,只保留20个主成分。得到降维后的数据,以及前20个主成分对应的方差占总方差的
百分比并画出示意图。注:请使用sklearn中的pca进行降维
import numpy as np
np.set_printoptions(suppress=True)
data=np.genfromtxt('secom.data')
n,m=data.shape
print(m)
print(n)
print('处理前',data)
for i in range(m):
inx=np.nonzero(~np.isnan(data[:,i]))
meanVal=np.mean(data[inx,i])
data[np.nonzero(np.isnan(data[:,i])),i]=meanVal
print('处理后',data)

from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
pca=PCA(n_components=20)
pca.fit(data)
ratio=pca.explained_variance_ratio_
print(ratio)
x=np.linspace(1,20,num=20)
plt.plot(x,ratio)
print(x)
plt.scatter(x,ratio,marker='^',c='r')
plt.xticks(x)
plt.show()
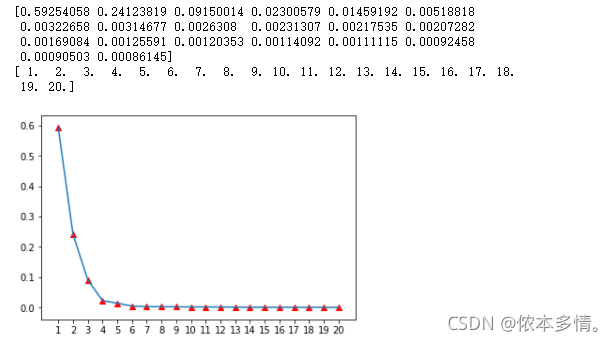








 本文介绍了一种处理半导体制造数据的方法,首先通过填充缺失值(用特征平均值替换NaN)来清洗数据,然后利用sklearn库中的PCA算法进行降维,保留前20个主成分。PCA降维后的数据显示了数据的主要分布,同时展示了这20个主成分解释的方差百分比,有助于理解数据的主要特征和信息损失情况。
本文介绍了一种处理半导体制造数据的方法,首先通过填充缺失值(用特征平均值替换NaN)来清洗数据,然后利用sklearn库中的PCA算法进行降维,保留前20个主成分。PCA降维后的数据显示了数据的主要分布,同时展示了这20个主成分解释的方差百分比,有助于理解数据的主要特征和信息损失情况。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











