







-
文中对于short text 多标签分类任务的处理中,使用了两种机制相结合的方式来提升这个短文本多标签分类的性能;
- 第一个模块是similarity graph模块,这个模块就是存储实例和标签之间出现的概率信息,其中结点用来表示相应的数据信息,而边用来存储一个称为是“匹配度”的概率信息,是指instance和label之间的匹配度
- 第二个模块是restart random walk model,利用这个模块来计算标签和标签之间的潜在语义信息;
- 最终实例的概率分布表示向量可以通过文中提到的模型的方法获得;
-
文中表示除了对于多标签分类研究的必要性,同时指出由于单标签的分类方法并没有考虑标签的相关性和共现信息,因此导致单标签的这些方法不能够应用到多标签上面来;
-
目前在多标签领域的处理多标签数据任务的方法有两种:
- 一种是让多标签数据进行合理的转换,从而可以将单标签的分类方法应用上去,这种方法又称为是PT方法;其中具有代表性的PT方法是BR方法,即Binary Relevance方法,这种方法在没有考虑多标签的标签相关性的情况下,即有多少个标签就训练多少个分类器,对于多个分类器使用相同的train sample不同的label信息进行同时训练然后最终再将这些分类器得到的多标签预测结果结合起来,作为最终的结果;但是由于这种方法并没有考虑到标签相关性信息,所以效果较差;所以后面产生了CCA(Classifier Chain algorithm)进行改进;
- 第二种方法是让模型进行改进来匹配多标签数据;这里提到的就是Random k-Labelsets这种方法
-
本文中提到的处理短文本多标签的方法是multi-label short-text classification algorithm which combines the similarity graph and the restart random walk model(简称为SGaRW);
-
文中对于多标签任务问题处理描述为是一个得分排序问题,就是对于一个sample,对于它得到的各个label的分数进行打分,然后取得分最大的那K个标签作为这个sample最终的标签信息;
-
Similarity Graph
-
文中对于这个模块进行了详解,首先这个相似图模块是基于WordNet外部信息库生成的直接权重图,用 G = ( V , E ) G=(V,E) G=(V,E)表示,其中 V = { i t e m s e t , s e n s e s e t } V=\{itemset,senseset\} V={itemset,senseset}表示node,而E表示边;
-
对于 V = { i t e m s e t , s e n s e s e t } V=\{itemset,senseset\} V={itemset,senseset}, i t e m s e t itemset itemset 结点表示由词组成的结点,每一个结点表示一个不同的词; s e n s e s e t senseset senseset 结点是由含义组成的,每一个 s e n s e s e t senseset senseset 结点表示相应的解释含义信息;
-
而对于两个不同的结点之间的边 < v i , v j > <v_i,v_j> <vi,vj> 这个则是可以在 i t e m s e t s itemsets itemsets 也可以在 s e n s e s e t s sensesets sensesets之间构建,同时,也可以在 i t e m s e t itemset itemset和 s e n s e s e t senseset senseset 之间构建;
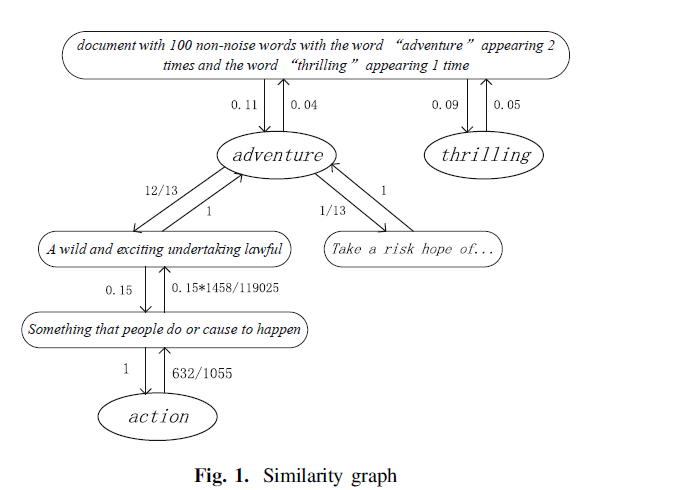
文中使用了这样的一个图来表示这个相似图表示的信息,其中的边表示的是条件概率信息,对于从adventure到{“a wild and exciting undertaking lawful”}这句话之间的边表示的是在我们看到adventure这个词之后,率先想到这个含义的概率是多大,其中这个概率信息是通过wordNet中第一个含义使用的频率来统计的;反之,就是在看到后面那个含义之后率先想到那个词的概率有多大;
-
-
Implement Multi-label Classification of Short Text
-
下面是如何使用文中的方法来实现短文本多标签分类:
- 首先是使用Similarity Graph先构建出short text和label之间的关系图,其中仍然是使用 G = ( V , E ) G=(V,E) G=(V,E) 的方法,顶点集合V中的元素表示的是senseset,即这里的短文本,用短文本表示应该对应的标签的含义信息,这的确是很形象;而label表示itemset,因为标签本身就是一个词,所以使用itemset来表示这样的一个label信息也是很合适的;
- 接着是使用上面构建好的Similarity Graph,在这个基础上使用random walk 算法来捕捉得到label和label之间的相关性信息,也就是如果标签 v i v_i vi和 v j v_j vj都是同一个sample的标签,这样我们就会在这两个标签之间画上一条线,表示这两个标签之间也是有关联信息的,从而挖掘出标签之间的潜在信息;
- 最终通过上面的方法,等到模型收敛之后,我们对于输入进来的测试实例,最终会得到相应的概率向量,其中的每一个元素部分表示的就是该标签划分给这个实例的概率大小;
-
下面叙述如何构建这样的一个Similarity Graph,具体的图构造信息已经在上面叙述过了,下面计算两个顶点之间的 w i j w_{ij} wij ,即边的权重关系,表示text和label之间的相关关系,这个关系的值使用“亲和力分数”来表示;
-
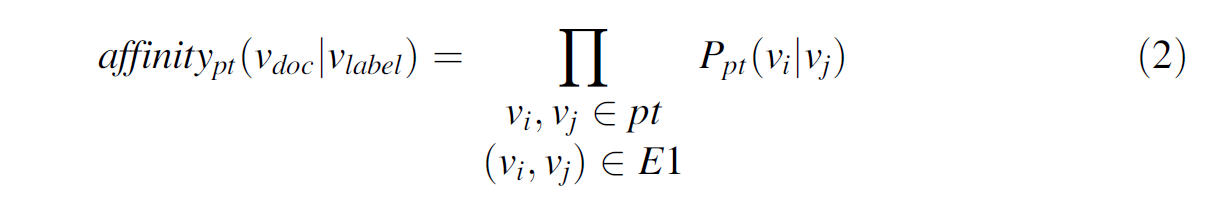
如上面的公式2中所示,这个公式表示的是在标签先看到之后预测出该text的条件概率,但是文中指出的是从doc到label的亲和力分数,后面的计算部分,指的是,可能在从doc到label之间的直接路径上不是直达的,可能需要经过好多的节点,而我们需要计算从起始点到终点的概率问题,所以就需要将在这条路径上出现的边的权重(概率值)依次相乘,最终得到我们想要的最终概率问题;其中 p t pt pt表示从doc到label的顶点序列集合, v i v_i vi和 v j v_j vj 都表示在这条路径上出现的节点;
-
由于通过上面概率的计算公式我们可以得到,这个公式使用了概率的乘法法则,使用这种法则的结果就会导致随着路径的不断增长,最终起点和终点的亲和分数也将会不断的下降;
-
同时由于从一个doc到一个label的中间路径不止一个,所以这里又对于上面得到的 a f f i n i t y p t ( v d o c ∣ v l a b e l ) affinity_{pt}(v_{doc}|v_{label}) affinitypt(vdoc∣vlabel) 使用了加法法则,用来计算将不同路径的概率分数进行加和,最终得到的从doc到label的概率结果;
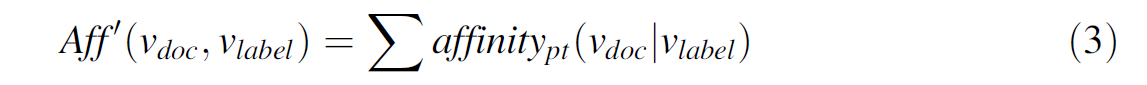
-
文中又考虑到了亲和力分数的不平衡性,即从doc到label和从label到doc之间的亲和力分数可能是不同的,所以模型中使用的方法就是
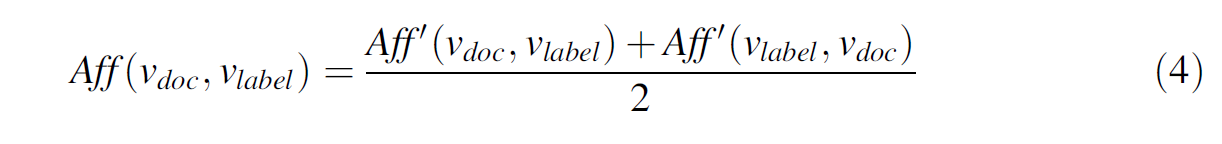
进行取平均操作;
-
最终将上面得到的 A f f Aff Aff分数作为最终的text和label的相关性分数,并将对于实例x的最终预测结果 H ( x ) H(x) H(x) 向量表示为
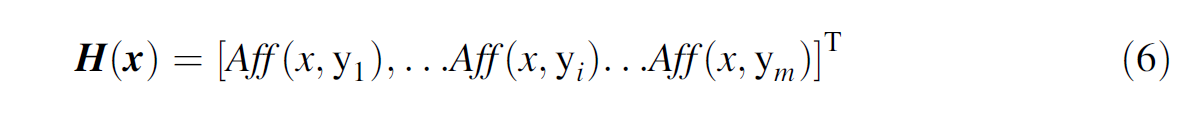
-
-
下面是运用Random Walk on Label Dependency Graph:
-
首先这个模块的功能是用来评估label和label之间的相关关系,如果两个label在同一时间被划分给同一个sample,那么就认为这两个label之间有相关关系,从何在label y i y_i yi和 y j y_j yj 之间加上一条边,边上的权重 w i j w_{ij} wij为这两个标签同时共同相关的sample个数;
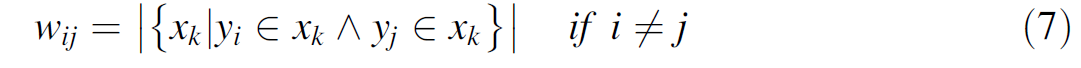
-
然后,通过构建一个m×m维矩阵来label之间的邻接关系,每一个值 s i j s_{ij} sij 表示这两个label之间的关联信息,

其中 m j m_j mj表示第j行中不为0的连边的个数;应该是 l a b e l j {label_j} labelj 和哪些label有关联的个数;
-
下面是重启随机步的工作流程:
-
首先是从一个随机的顶点位置来开始检索全图;
-
然后这个作为检索器的迭代过程是以一种概率的方式传到他的邻接节点中来,其中的这个概率是跟他们边节点的权重成正比的;或者说这个概率是从邻接节点返回初始节点的概率,知道最终达到稳定状态;

-
首先是对于sample x i x_i xi 的各个节点到m个label的概率初始向量,该向量中的每一个值表示该label是这个sample的标签的概率,向量中的每一个元素初始定义为 1 m {\frac{1}{m}} m1 ;文中提到对于每一个标签预测结果在一定程度上也是取决于其他标签,也就是对于标签的预测不仅仅由sample决定,同时在一定程度上也是可以由其他标签的作用起到增强影响的;
-
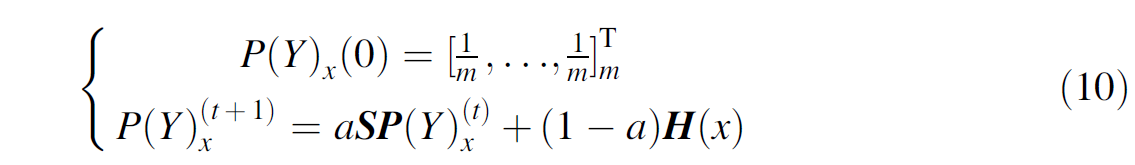
计算公式如上,其中 P ( Y ) ( t ) P(Y)^{(t)} P(Y)(t) 表示在第t次时sample x和每一个标签之间的相关性信息, H ( x ) H(x) H(x) 表示上面说的初始定义的实例x跟每一个标签的概率信息,即之前构建的Similarity Graph中的text和label之间的亲和力分数;
S即为在通过上面的随机步计算之后得到的label和label之间的相关性矩阵;
-
-
-
-
-
总体上来说,本文中的模型通过在不同的 α α α 进行测试最终确定效果最好的 α α α 值为0.00007,此时,Hamming Loss是较小的,Jaccard index是最大的,同时Accuracy是较大的;之后通过对于给予模型的train set数量和test set数量的表现上来看肯定是train set的数量越大最终的效果越好,最终在固定test set数量不变的情况下,模型的效果将会随着train set中的数据数量的增加Hamming Loss不断减小、同时Accuracy不断增大;
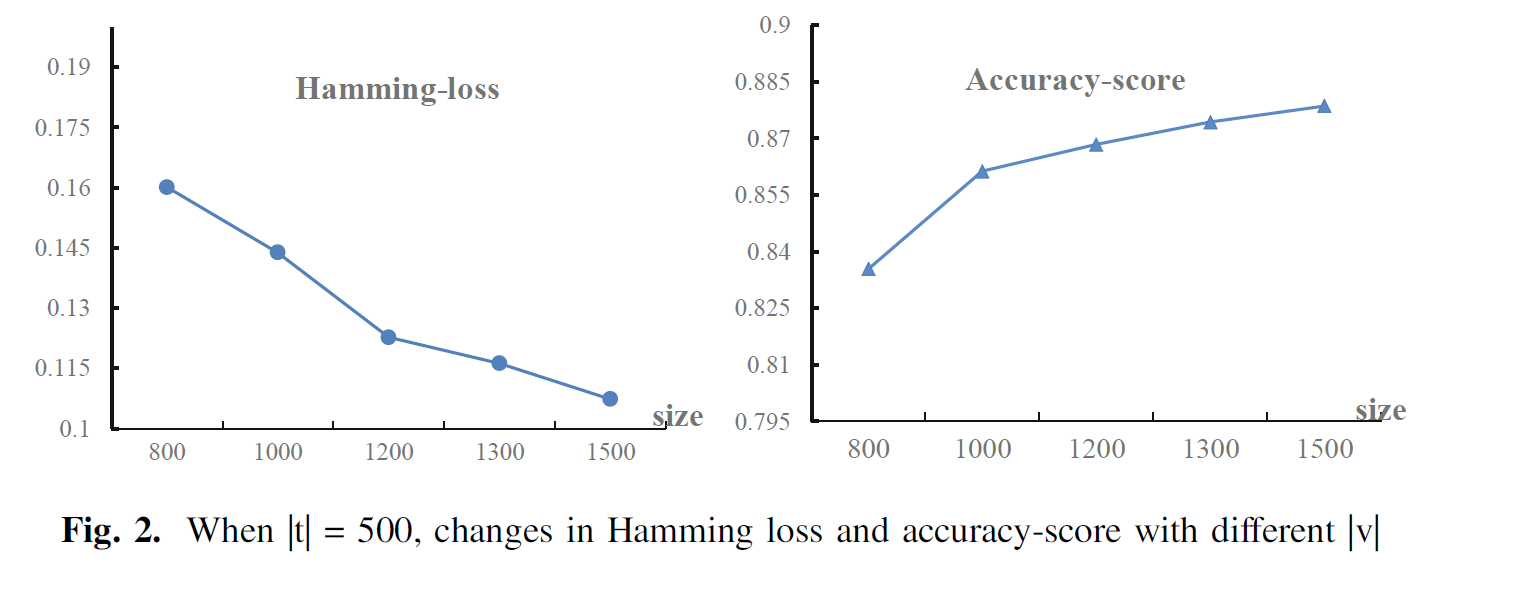
-
在跟其他的模型效果相比较的表现中,肯定也是文中提到的SGaRW的效果要更好;
-
总之文中的 S G a R W SGaRW SGaRW 模型的工作流程就是,首先,通过依靠外部的信息WordNet加上本身的short text信息和label信息最终构建出这样的一个Similarity Graph,用这个图表示label和text之间的初始概率信息,以及标签之间的依赖性信息;通过重启随机步机制来计算对于一个sample的最终稳定标签向量,这个向量中的元素信息表示该标签是这个实例的label的概率;














评论

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
查看更多评论
添加红包








