







赛题简述
根据给定的数据集,建立模型,预测房屋租金。
数据集中的数据类别包括租赁房源、小区、二手房、配套、新房、土地、人口、客户、真实租金等
典型的回归预测
得分指标
𝑅2:
残差平方和:𝑆𝑆𝑟𝑒𝑠=∑(𝑦𝑖−𝑦̂ 𝑖)2
总平均值:𝑆𝑆𝑡𝑜𝑡=∑(𝑦𝑖−𝑦⎯⎯⎯𝑖)2
得到𝑅2的表达式为 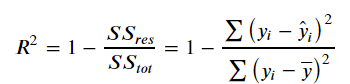
𝑅2用于度量因变量的变异中可由自变量解释部分所占的比例,取值范围是 0~1。
𝑅2越接近1,表明回归平方和占总平方和的比例越大,回归线与各观测点越接近,用x的变化来解释y值变化的部分就越多,回归的拟合程度就越好。
所以 𝑅2也称为**拟合优度(Goodness of Fit)**的统计量。
数据概况
1. 租赁基本信息:
ID——房屋编号
area——房屋面积
rentType——出租方式:整租/合租/未知
houseType——房型
houseFloor——房间所在楼层:高/中/低
totalFloor——房间所在的总楼层数
houseToward——房间朝向
houseDecoration——房屋装修
tradeTime——成交日期
tradeMoney——成交租金
2. 小区信息:
CommunityName——小区名称
city——城市
region——地区
plate——区域板块
buildYear——小区建筑年代
saleSecHouseNum——该板块当月二手房挂牌房源数
3. 配套设施:
subwayStationNum——该板块地铁站数量
busStationNum——该板块公交站数量
interSchoolNum——该板块国际学校的数量
schoolNum——该板块公立学校的数量
privateSchoolNum——该板块私立学校数量
hospitalNum——该板块综合医院数量
DrugStoreNum——该板块药房数量
gymNum——该板块健身中心数量
bankNum——该板块银行数量
shopNum——该板块商店数量
parkNum——该板块公园数量
mallNum——该板块购物中心数量
superMarketNum——该板块超市数量
4. 其他信息:
totalTradeMoney——该板块当月二手房成交总金额
totalTradeArea——该板块二手房成交总面积
tradeMeanPrice——该板块二手房成交均价
tradeSecNum——该板块当月二手房成交套数
totalNewTradeMoney——该板块当月新房成交总金额
totalNewTradeArea——该板块当月新房成交的总面积
totalNewMeanPrice——该板块当月新房成交均价
tradeNewNum——该板块当月新房成交套数
remainNewNum——该板块当月新房未成交套数
supplyNewNum——该板块当月新房供应套数
supplyLandNum——该板块当月土地供应幅数
supplyLandArea——该板块当月土地供应面积
tradeLandNum——该板块当月土地成交幅数
tradeLandArea——该板块当月土地成交面积
landTotalPrice——该板块当月土地成交总价
landMeanPrice——该板块当月楼板价(元/m^{2})
totalWorkers——当前板块现有的办公人数
newWorkers——该板块当月流入人口数(现招聘的人员)
residentPopulation——该板块常住人口
pv——该板块当月租客浏览网页次数
uv——该板块当月租客浏览网页总人数
lookNum——线下看房次数
导入包及数据
#coding:utf-8
#导入warnings包,利用过滤器来实现忽略警告语句。
import warnings
warnings.filterwarnings('ignore')
# GBDT
from sklearn.ensemble import GradientBoostingRegressor
# XGBoost
import xgboost as xgb
# LightGBM
import lightgbm as lgb
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
#载入数据
data_train = pd.read_csv('./train_data.csv')
data_train['Type'] = 'Train'
data_test = pd.read_csv('./test_a.csv')
data_test['Type'] = 'Test'
data_all = pd.concat([data_train, data_test], ignore_index=True)
1.总体情况一览
使用到的函数:
df.info(): 总体维度,index的信息,列的数量,每一列缺失值信息,数据类型
df.describe():数值型列的count、mean、四分位值、最大最小值等信息
df.head():默认前十行
(还可以用到df[feature].value_counts()查看某一列的特征值及counts)
print(data_train.info())
print(data_train.describe())
data_train.head()
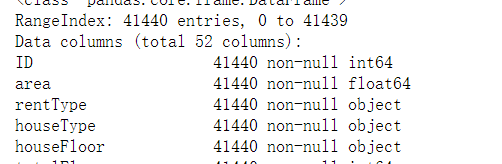 info
info
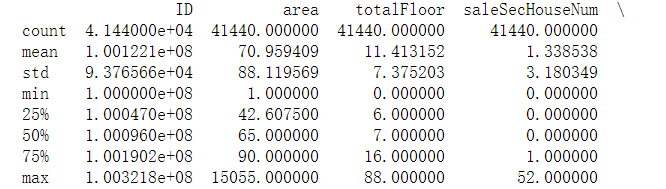 describe
describe
2.辨析分类特征与连续特征
#分类特征
categorical_feas = ['rentType', 'houseType', 'houseFloor', 'region', 'plate', 'houseToward', 'houseDecoration',
'communityName','city','region','plate','buildYear']
#连续特征
numerical_feas=['ID','area','totalFloor','saleSecHouseNum','subwayStationNum',
'busStationNum','interSchoolNum','schoolNum','privateSchoolNum','hospitalNum',
'drugStoreNum','gymNum','bankNum','shopNum','parkNum','mallNum','superMarketNum',
'totalTradeMoney','totalTradeArea','tradeMeanPrice','tradeSecNum','totalNewTradeMoney',
'totalNewTradeArea','tradeNewMeanPrice','tradeNewNum','remainNewNum','supplyNewNum',
'supplyLandNum','supplyLandArea','tradeLandNum','tradeLandArea','landTotalPrice',
'landMeanPrice','totalWorkers','newWorkers','residentPopulation','pv','uv','lookNum']
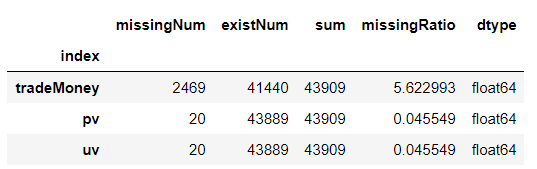
3.缺失值分析
def missing_values(df):
alldata_na = pd.DataFrame(df.isnull().sum(),columns = {'missingNum'})
alldata_na['existNum'] = len(df) - alldata_na['missingNum']
alldata_na['sum'] = len(df)
alldata_na['missingRatio'] = alldata_na['missingNum']/len(df)*100
alldata_na['dtype'] = df.dtypes
alldata_na = alldata_na[alldata_na['missingNum'] > 0].reset_index().sort_values(by = ['missingNum','index'],ascending = [False,True])
#原本alldata_na的index就是pv和uv,但经过reset_index后变成了0,1,将原来的index挤出来成了新的一列['index']
alldata_na.set_index('index',inplace = True) #将['index']重新变为index
return alldata_na
missing_values(data_all)
4.单调特征列分析
#2.单调特征列分析(很可能是时间)
def incresing(vals): #vals是values的简写,即df中某一列的值
cnt = 0 #记录单调特征值的数量
len_ = len(vals)
for i in range(len_-1):
if vals[i+1] > vals[i]:
cnt += 1
return cnt
fea_cols = [col for col in data_train.columns]
for col in fea_cols: #对每一列进行检验
cnt = incresing(data_train[col].values)
if cnt / data_train.shape[0] >= 0.55:
print('单调特征:',col)
print('单调特征值个数:', cnt)
print('单调特征值比例:', cnt / data_train.shape[0])

5.统计特征值频次大于100的特征
def more_100_features(df):
for feature in categorical_feas:
df_value_counts = pd.DataFrame(data_train[feature].value_counts()) #做成df index还是特征值
df_value_counts = df_value_counts.reset_index() #重设index
df_value_counts.columns = [feature,'counts']
print(df_value_counts[df_value_counts['counts'] >= 100])
#将每个特征的统计表格中特征值>=100的特征打印出来
more_100_features(data_train)

6.label分布
查看一下tradeMoney特征值的分布情况
# Labe 分布
fig,axes = plt.subplots(2,3,figsize=(20,5))
fig.set_size_inches(20,12)
sns.distplot(data_train['tradeMoney'],ax=axes[0][0])
sns.distplot(data_train[(data_train['tradeMoney']<=20000)]['tradeMoney'],ax=axes[0][1])
sns.distplot(data_train[(data_train['tradeMoney']>20000)&(data_train['tradeMoney']<=50000)]['tradeMoney'],ax=axes[0][2])
sns.distplot(data_train[(data_train['tradeMoney']>50000)&(data_train['tradeMoney']<=100000)]['tradeMoney'],ax=axes[1][0])
sns.distplot(data_train[(data_train['tradeMoney']>100000)]['tradeMoney'],ax=axes[1][1])

总结
拿到一个任务首先就是明确他是一个分类任务还是回归任务,看一下数据集的基本情况,大概有多少缺失值,明确数值型特征还有类别型特征,如果特征没有明确说明的话,还要找一下有没有单调性特征,这样的特征很可能代表时间。对于某些特殊的指标还可以看一下其特征值的分布情况,根据需要编写函数,如查看其频次大于100的数量。
这一步挺重要,做好了可以让后面的数据预处理事半功倍















 3621
3621











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









