









 博主在尝试使用云服务器进行点云目标检测模型训练时遇到环境配置问题,特别是 SparseConvNet 的编译错误。尝试了降低 CUDA 版本和 Pillow 版本,但问题仍然存在。最终,博主转向实验室的 2080ti 机子,通过 Docker 成功部署环境并跑通了模型。过程中进行了数据预处理,训练并展示了模型效果。
博主在尝试使用云服务器进行点云目标检测模型训练时遇到环境配置问题,特别是 SparseConvNet 的编译错误。尝试了降低 CUDA 版本和 Pillow 版本,但问题仍然存在。最终,博主转向实验室的 2080ti 机子,通过 Docker 成功部署环境并跑通了模型。过程中进行了数据预处理,训练并展示了模型效果。
因为实验室贫穷,只有一台2080ti的机子,所以一开始打算用云服务器,后面发现云服务器实在是折磨人,所以又回到实验室的2080ti机子。本文分为两部分:云服务器(失败)和实验室机子(docker部署跑通)。
1. 云服务器(失败😥可以直接跳过)
云服务器好处是可以选择各种版本,尝试过后发现在python版本上必须是python3.7, python3.6和3.8都会报不同的错误。
实际上最麻烦的是SparseConvNet,根据下面这篇博客的分析,新版的这个网络需要的环境是cuda 10 和 python 3.7, torch 1.3.0,否则在sh build.sh这一步就会卡死无法编译。
【点云目标检测】 SECOND 调试记录_梦醒时分1218的博客-CSDN博客
这个镜像可以安装以上版本的环境,在sh build.sh这一步可以过去(注意此时的gcc版本为7),但是问题在于训练时numba.cuda报错
Traceback (most recent call last):
File "/root/miniconda3/envs/myconda/lib/python3.7/site-packages/numba/cuda/cudadrv/driver.py", line 237, in ensure_initialized
self.cuInit(0)
File "/root/miniconda3/envs/myconda/lib/python3.7/site-packages/numba/cuda/cudadrv/driver.py", line 303, in safe_cuda_api_call
self._check_error(fname, retcode)
File "/root/miniconda3/envs/myconda/lib/python3.7/site-packages/numba/cuda/cudadrv/driver.py", line 343, in _check_error
raise CudaAPIError(retcode, msg)
numba.cuda.cudadrv.driver.CudaAPIError: [-1] Call to cuInit results in UNKNOWN_CUDA_ERROR
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "create_data.py", line 9, in <module>
from second.core import box_np_ops
File "/mnt/second.pytorch/second/core/box_np_ops.py", line 7, in <module>
from second.core.non_max_suppression.nms_gpu import rotate_iou_gpu_eval
File "/mnt/second.pytorch/second/core/non_max_suppression/__init__.py", line 2, in <module>
from second.core.non_max_suppression.nms_gpu import (nms_gpu, rotate_iou_gpu,
File "/mnt/second.pytorch/second/core/non_max_suppression/nms_gpu.py", line 36, in <module>
@cuda.jit('(int64, float32, float32[:, :], uint64[:])')
File "/root/miniconda3/envs/myconda/lib/python3.7/site-packages/numba/cuda/decorators.py", line 101, in kernel_jit
return Dispatcher(func, [func_or_sig], targetoptions=targetoptions)
File "/root/miniconda3/envs/myconda/lib/python3.7/site-packages/numba/cuda/compiler.py", line 936, in __init__
self.compile(sigs[0])
File "/root/miniconda3/envs/myconda/lib/python3.7/site-packages/numba/cuda/compiler.py", line 1107, in compile
**self.targetoptions)
File "/root/miniconda3/envs/myconda/lib/python3.7/site-packages/numba/core/compiler_lock.py", line 35, in _acquire_compile_lock
return func(*args, **kwargs)
File "/root/miniconda3/envs/myconda/lib/python3.7/site-packages/numba/cuda/compiler.py", line 569, in __init__
self.cooperative = 'cudaCGGetIntrinsicHandle' in lib.get_asm_str()
File "/root/miniconda3/envs/myconda/lib/python3.7/site-packages/numba/cuda/codegen.py", line 103, in get_asm_str
return self._join_ptxes(self._get_ptxes(cc=cc))
File "/root/miniconda3/envs/myconda/lib/python3.7/site-packages/numba/cuda/codegen.py", line 107, in _get_ptxes
ctx = devices.get_context()
File "/root/miniconda3/envs/myconda/lib/python3.7/site-packages/numba/cuda/cudadrv/devices.py", line 212, in get_context
return _runtime.get_or_create_context(devnum)
File "/root/miniconda3/envs/myconda/lib/python3.7/site-packages/numba/cuda/cudadrv/devices.py", line 138, in get_or_create_context
return self._get_or_create_context_uncached(devnum)
File "/root/miniconda3/envs/myconda/lib/python3.7/site-packages/numba/cuda/cudadrv/devices.py", line 151, in _get_or_create_context_uncached
with driver.get_active_context() as ac:
File "/root/miniconda3/envs/myconda/lib/python3.7/site-packages/numba/cuda/cudadrv/driver.py", line 401, in __enter__
driver.cuCtxGetCurrent(byref(hctx))
File "/root/miniconda3/envs/myconda/lib/python3.7/site-packages/numba/cuda/cudadrv/driver.py", line 278, in __getattr__
self.ensure_initialized()
File "/root/miniconda3/envs/myconda/lib/python3.7/site-packages/numba/cuda/cudadrv/driver.py", line 241, in ensure_initialized
raise CudaSupportError(f"Error at driver init: {description}")
numba.cuda.cudadrv.error.CudaSupportError: Error at driver init: Call to cuInit results in UNKNOWN_CUDA_ERROR (-1)解决方法:看网上说是处理数据需要将cuda10.0降级为cuda9.0, 于是按照下面链接搞cuda9.0(千万记得要先降低gcc版本)在Ubuntu 18.04中配置GPU环境:安装CUDA 9.0等_白马负金羁-CSDN博客_ubuntu18.04安装cuda9.0
结果又报错了:non_max_supreeesion.nms
/root/miniconda3/envs/myconda/lib/python3.7/site-packages/skimage/io/manage_plugins.py:23: UserWarning: Your installed pillow version is < 7.1.0. Several security issues (CVE-2020-11538, CVE-2020-10379, CVE-2020-10994, CVE-2020-10177) have been fixed in pillow 7.1.0 or higher. We recommend to upgrade this library.
from .collection import imread_collection_wrapper
nvcc -std=c++11 -c -o ../cc/nms/nms_kernel.cu.o ../cc/nms/nms_kernel.cu.cc -I/usr/local/cuda/include -x cu -Xcompiler -fPIC -arch=sm_37 --expt-relaxed-constexpr
gcc: error trying to exec 'cc1plus': execvp: No such file or directory
concurrent.futures.process._RemoteTraceback:
"""
Traceback (most recent call last):
File "/mnt/second.pytorch/second/core/non_max_suppression/nms_cpu.py", line 10, in <module>
from second.core.non_max_suppression.nms import (
ModuleNotFoundError: No module named 'second.core.non_max_suppression.nms'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/root/miniconda3/envs/myconda/lib/python3.7/concurrent/futures/process.py", line 239, in _process_worker
r = call_item.fn(*call_item.args, **call_item.kwargs)
File "/root/miniconda3/envs/myconda/lib/python3.7/concurrent/futures/process.py", line 198, in _process_chunk
return [fn(*args) for args in chunk]
File "/root/miniconda3/envs/myconda/lib/python3.7/concurrent/futures/process.py", line 198, in <listcomp>
return [fn(*args) for args in chunk]
File "/mnt/second.pytorch/second/utils/buildtools/command.py", line 255, in compile_func
raise RuntimeError("compile failed with retcode", ret.returncode)
RuntimeError: ('compile failed with retcode', 1)
"""
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "create_data.py", line 9, in <module>
from second.core import box_np_ops
File "/mnt/second.pytorch/second/core/box_np_ops.py", line 7, in <module>
from second.core.non_max_suppression.nms_gpu import rotate_iou_gpu_eval
File "/mnt/second.pytorch/second/core/non_max_suppression/__init__.py", line 1, in <module>
from second.core.non_max_suppression.nms_cpu import nms_jit, soft_nms_jit
File "/mnt/second.pytorch/second/core/non_max_suppression/nms_cpu.py", line 18, in <module>
cuda=True)
File "/mnt/second.pytorch/second/utils/buildtools/pybind11_build.py", line 113, in load_pb11
cmds, cwd, num_workers=num_workers, compiler=compiler)
File "/mnt/second.pytorch/second/utils/buildtools/command.py", line 277, in compile_libraries
if any([r.returncode != 0 for r in rets]):
File "/mnt/second.pytorch/second/utils/buildtools/command.py", line 277, in <listcomp>
if any([r.returncode != 0 for r in rets]):
File "/root/miniconda3/envs/myconda/lib/python3.7/concurrent/futures/process.py", line 483, in _chain_from_iterable_of_lists
for element in iterable:
File "/root/miniconda3/envs/myconda/lib/python3.7/concurrent/futures/_base.py", line 598, in result_iterator
yield fs.pop().result()
File "/root/miniconda3/envs/myconda/lib/python3.7/concurrent/futures/_base.py", line 428, in result
return self.__get_result()
File "/root/miniconda3/envs/myconda/lib/python3.7/concurrent/futures/_base.py", line 384, in __get_result
raise self._exception
RuntimeError: ('compile failed with retcode', 1)感觉上面那些博客的方法都实在是搞不定,所以打算用OpenMMLab的mmdetection3d(这个是整合模型库)跑跑看,按照以下链接:MMdetection3d环境搭建、使用MMdetection3d做3D目标检测训练自己的数据集、测试、可视化,以及常见的错误_星空-CSDN博客_mmdetection3d首先是要搞个docker, 用云服务器跑跑试试。

该云服务器的/etc/apt/sources.list配置:
# See http://help.ubuntu.com/community/UpgradeNotes for how to upgrade to
# newer versions of the distribution.
deb http://mirrors.ustc.edu.cn/ubuntu/ bionic main restricted
# deb-src http://mirrors.ustc.edu.cn/ubuntu/ bionic main restricted
## Major bug fix updates produced after the final release of the
## distribution.
deb http://mirrors.ustc.edu.cn/ubuntu/ bionic-updates main restricted
# deb-src http://mirrors.ustc.edu.cn/ubuntu/ bionic-updates main restricted
## N.B. software from this repository is ENTIRELY UNSUPPORTED by the Ubuntu
## team. Also, please note that software in universe WILL NOT receive any
## review or updates from the Ubuntu security team.
deb http://mirrors.ustc.edu.cn/ubuntu/ bionic universe
# deb-src http://mirrors.ustc.edu.cn/ubuntu/ bionic universe
deb http://mirrors.ustc.edu.cn/ubuntu/ bionic-updates universe
# deb-src http://mirrors.ustc.edu.cn/ubuntu/ bionic-updates universe
## N.B. software from this repository is ENTIRELY UNSUPPORTED by the Ubuntu
## team, and may not be under a free licence. Please satisfy yourself as to
## your rights to use the software. Also, please note that software in
## multiverse WILL NOT receive any review or updates from the Ubuntu
## security team.
deb http://mirrors.ustc.edu.cn/ubuntu/ bionic multiverse
# deb-src http://mirrors.ustc.edu.cn/ubuntu/ bionic multiverse
deb http://mirrors.ustc.edu.cn/ubuntu/ bionic-updates multiverse
# deb-src http://mirrors.ustc.edu.cn/ubuntu/ bionic-updates multiverse
可以安装docker,但是无法启动。下面链接为docker安装
Ubuntu 16.04安装docker详细步骤_jinking01的专栏-CSDN博客_ubuntu 安装docker
搞了一段时间docker以后发现,docker在云服务器上很难搞定。原因应该就是下面这个链接的意思:在Linux的Windows子系统上(WSL)使用Docker(Ubuntu) - Leon_Chaunce - 博客园
综上,决定用实验室的2080ti机子,虽然机子的环境已经残破不堪,但是docker容器只要能部署上,其他应该都能跑。
2. 实验室2080ti机子(成功🤣)
首先因为机子本身就是linux系统,所以docker是成功部署了,不过有个报错是pillow版本不适应,先按照下文跑了再说。
MMdetection3d环境搭建、使用MMdetection3d做3D目标检测训练自己的数据集、测试、可视化,以及常见的错误_星空-CSDN博客_mmdetection3d
2.1 测试demo
按照上文链接,成功跑通了测试demo, 不过可视化有点麻烦,所以等后面再可视化。
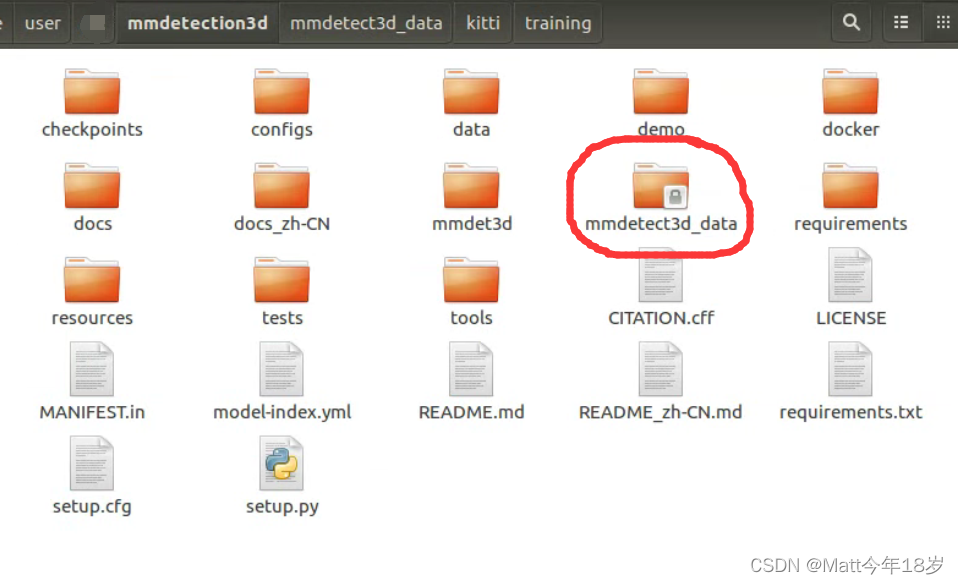
docker部署完了应该就会有mmdetection3d镜像,随后根据上面链接的指令生成容器映射到本地,也就是下面圈出来的mmdetec3d_data。
然后将下好的权重同步放到docker容器里的文件夹中,运行命令即可生成下图中的文件。
python demo/pcd_demo.py demo/data/kitti/kitti_000008.bin configs/second/hv_second_secfpn_6x8_80e_kitti-3d-car.py data/predtrain_models/hv_second_secfpn_6x8_80e_kitti-3d-car_20200620_230238-393f000c.pth --out-dir data/output_result/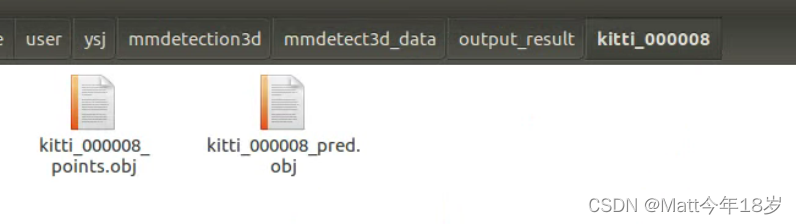
可视化的内容等后面再补......
2.2 训练过程
2.2.1 数据预处理
目标是先把docker容器中的数据集摆成这样。

因为我不知道该怎么将docker容器与宿主机的kitti建立软连接,所以直接将kitti数据集copy到了容器中。
# 在宿主机上先cd到kitti文件夹下,目录应该是ImageSets, object
docker cp ImageSets 容器id:/mmdetection3d/data/kitti/ImageSets
# 然后cd到object目录下,object里面有training和testing两个文件夹
docker cp training 容器id:/mmdetection3d/data/kitti/training
docker cp testing 容器id:/mmdetection3d/data/kitti/testing
然后按照下方博客进行数据集预处理MMdetection3d框架的环境搭建与使用(二)-- 使用篇_旺仔小姐的博客-CSDN博客_mmdetection3d
正常的话,数据集预处理就是下面这样。
(mmlab) shl@zhihui-mint:~/shl_res/mmlab/mmdetection3d$ python tools/create_data.py kitti --root-path ./data/kitti --out-dir ./data/kitti --extra-tag kitti
Generate info. this may take several minutes.
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 3712/3712, 18.2 task/s, elapsed: 205s, ETA: 0s
Kitti info train file is saved to data/kitti/kitti_infos_train.pkl
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 3769/3769, 18.4 task/s, elapsed: 205s, ETA: 0s
Kitti info val file is saved to data/kitti/kitti_infos_val.pkl
Kitti info trainval file is saved to data/kitti/kitti_infos_trainval.pkl
Kitti info test file is saved to data/kitti/kitti_infos_test.pkl
create reduced point cloud for training set
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 3712/3712, 18.7 task/s, elapsed: 199s, ETA: 0s
create reduced point cloud for validation set
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 3769/3769, 18.8 task/s, elapsed: 200s, ETA: 0s
create reduced point cloud for testing set
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 7518/7518, 18.5 task/s, elapsed: 406s, ETA: 0s
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 3712/3712, 38.2 task/s, elapsed: 97s, ETA: 0s
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 3769/3769, 40.3 task/s, elapsed: 93s, ETA: 0s
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 7481/7481, 39.5 task/s, elapsed: 189s, ETA: 0s
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 7518/7518, 42.4 task/s, elapsed: 177s, ETA: 0s
Create GT Database of KittiDataset
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 3712/3712, 17.3 task/s, elapsed: 215s, ETA: 0s
load 2207 Pedestrian database infos
load 14357 Car database infos
load 734 Cyclist database infos
load 1297 Van database infos
load 488 Truck database infos
load 224 Tram database infos
load 337 Misc database infos
load 56 Person_sitting database infos
(mmlab) shl@zhihui-mint:~/shl_res/mmlab/mmdetection3d$
最后生成pkl文件
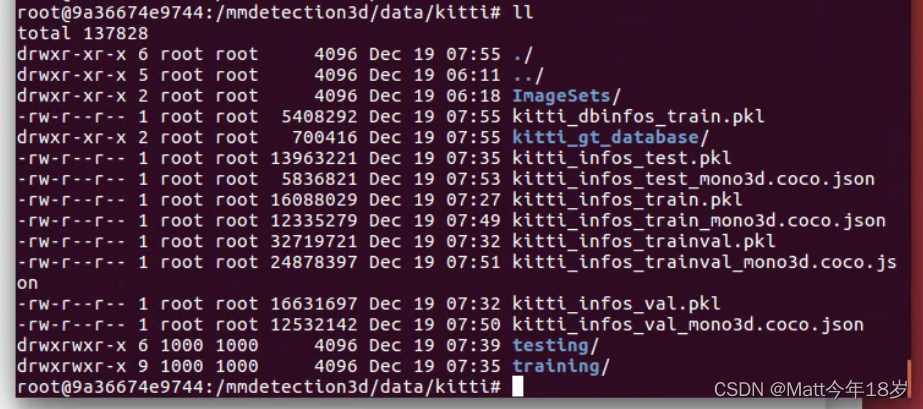
2.2.2 开始训练
python tools/train.py configs/pointpillars/hv_pointpillars_secfpn_6x8_160e_kitti-3d-3class.py
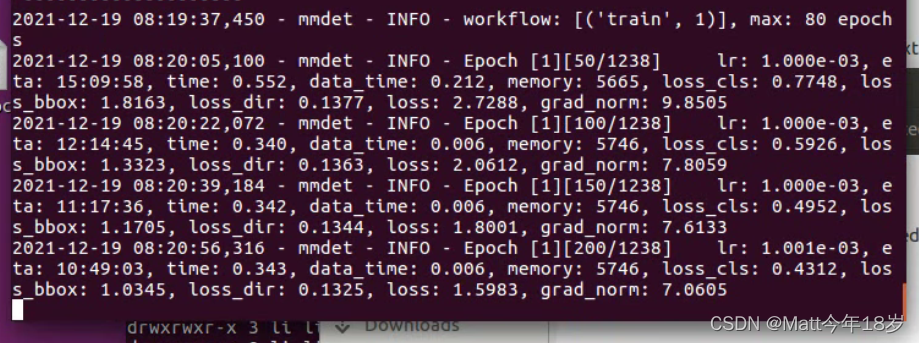
nvidia-smi显卡使用情况如下:2080ti完全可以跑通。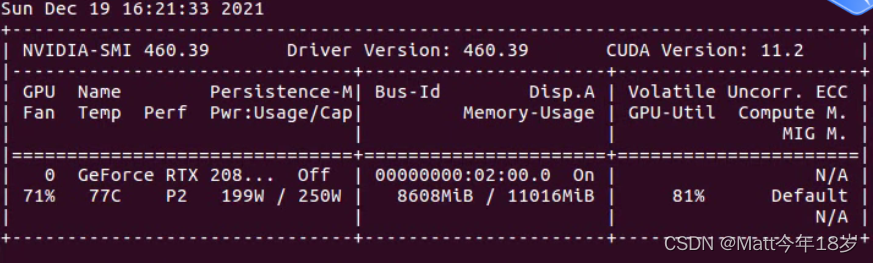
训练时间有点长,这里就直接用预训练的模型跑,结果如下:
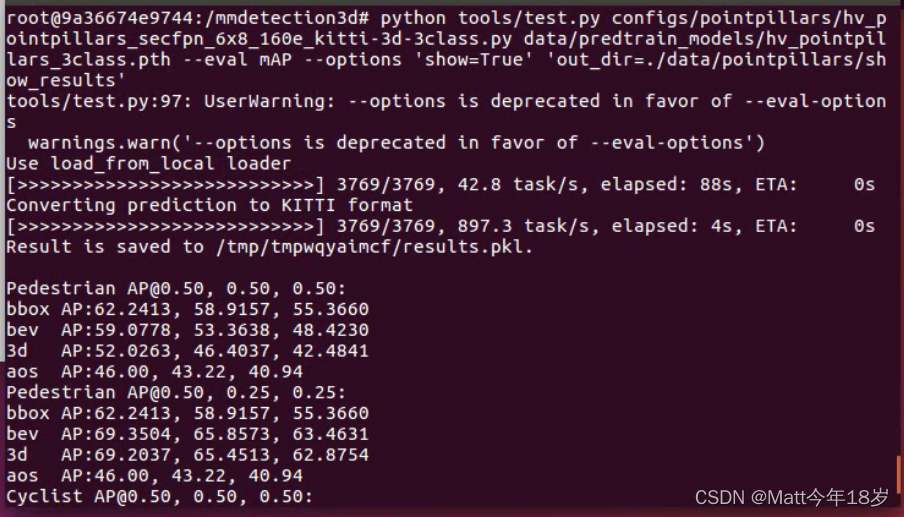
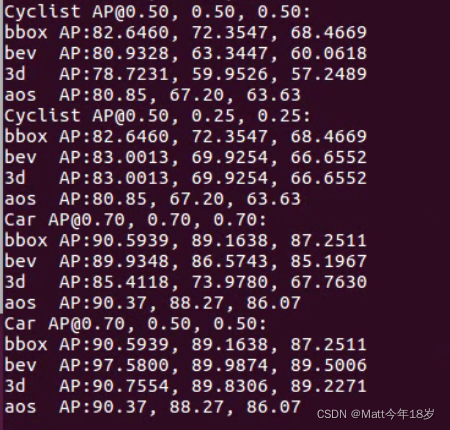
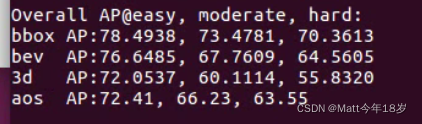
美中不足是最后的open3d可视化出点问题,搞不出来:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









