







规范
在BNF中,双引号中的字(“word”)代表着这些字符本身。而double_quote用来代表双引号。
在双引号外的字(有可能有下划线)代表着语法部分。
< > : 内包含的为必选项。
[ ] : 内包含的为可选项。
{ } : 内包含的为可重复0至无数次的项。
| : 表示在其左右两边任选一项,相当于"OR"的意思。
::= : 是“被定义为”的意思
“…” : 术语符号
[…] : 选项,最多出现一次
{…} : 重复项,任意次数,包括 0 次
(…) : 分组
| : 并列选项,只能选一个
斜体字: 参数,在其它地方有解释
产生式编写例
比如5+3 * (2+1)运算表达式
5为Num,3为Num,(2 + 1)为含括号的子表达式(Expr)
Num、(Expr)优先级最高,所以做叶子节点,把他们统称为Factor,即
Factor=Num | (Expr)
次高优先级的运算为乘除运算*/,表达式称为Term,基本运算元素为上一步的Factor,有
当乘除运算符个数为0时,Term = Factor
当乘除运算符个数为1时,Term = Factor * Factor | Factor / Factor,将上式Term = Factor带入得 Term = Term * Factor | Term / Factor(左递归)。
当乘除运算符个数大于1时,
Term = Factor * Factor / Factor …* Factor = (Factor * Factor / Factor…) * Factor =Term * Factor
或
Term = Factor * Factor / Factor…/ Factor = (Factor * Factor / Factor…) / Factor = Term / Factor。
于是运算符个数 >= 1时,具有相同产生式。综合得出:
Term = Term * Factor | Term / Factor | Factor
最低优先级的运算为加减运算±,表达式称为Expr,基本运算元素为上一步的Term,有
当加减运算符的个数为0时,Expr = Term
当加减运算符的个数为1时,Expr = Term + Term | Term - Term,把上式代入得,
Expr = Expr + Term | Expr - Term
当加减运算符的个数大于1时,Expr = Term + Term - Term…+ Term = (Term + Term - Term…) + Term = Expr + Term,或 Expr = Term + Term - Term…- Term = (Term + Term - Term…) - Term = Expr - Term
于是运算符个数 >= 1时,具有相同产生式。综合得出:
Expr = Expr + Term | Expr - Term | Term
<expr> ::= <expr> + <term>
| <expr> - <term>
| <term>
<term> ::= <term> * <factor>
| <term> / <factor>
| <factor>
<factor> ::= ( <expr> )
| Num
递归
产生式分成递归的和非递归的,一个产生式用自己来表示自己就会产生递归。
左递归:

产生式一直朝左侧延伸,无法结束,永远不会结束,所以叫左递归。
显然左递归无法分解出有限的叶子节点。尤其它永远无法得到第一个叶子节点。因为左侧在无限递归产生新的左叶子节点。
右递归:

右递归有第一个叶子节点,没有最后一个叶子节点。
消除左递归:
我们需要明确第一个叶子节点的重要含义:第一个节点是语法的起点,所以第一个节点很重要,如果没有第一个叶子节点,那么就永远无法判断此语法是从哪个字符开始的。所以存在左递归的文法,是无法通过程序解析的,这样的程序无法实现。
相反地,右递归有第一个叶子节点,没有最后一个叶子节点。有第一个叶子节点就可以判断语法从哪个字符开始,但是不知道语法在何时结束。
但是,在实际解析中,因为被解析的文本是有限长的,所以右递归一定会停止。除此之外,因为右递归一定有起始符号,所以在解析文本时,一旦遇到非起始符的字符串,也会停止解析。也就是说,右递归能自动保证语法的正确性,而且不会无穷递归。
综上,只有左递归需要消除。
消除以上例子的左递归:
上面我们已经推导出四则运算的产生式了,但是产生式中存在之前说的左递归。具有左递归的产生式是无法用来解析代码的,所以需要消除左递归。
如何消除左递归呢?前面说过,用非递归的部分来表示左递归的部分就可以了。如果没有非递归部分,就无法消除左递归。就相当于一条路走不通,绕个弯子走另一条路。如果没有一条路可以走,就是真的无路可走。
消除直接左递归(省略号…表示无数次重复):
现有直接左递归:A = Aa | b,
即A=A…a ,右边的A用b替换掉,等价于: A = ba…a = ba…
消除了左递归,即消除A =…a,只剩下A = ba…。
此时A的产生式为:A = bAtail,Atail是除了开始符号b剩下的部分。
那剩下的部分是什么呢?Atail = a…(右递归),即Atail = aAtail。右递归是可以处理的。
综上直接左递归消除方法是:
A = Aa | b =>消除左递归 => A = bA’, A’=aA’
由此可见,终结符是转化的桥梁。
消除间接左递归:
https://www.cnblogs.com/Alexkk/p/5977899.html
编写BNF
上面的例子遵循的原则:
优先级越高的产生式越接近终端节点;
有左递归要消除左递归。
例子:C枚举
enum EnumName
{
A, B, C
};
枚举类型的定义语法:
以一个enum开头,后面可以跟一个标识符,也可以省略不写。
接着是一个左大括号;
接着是枚举值列表,枚举值列表可以为空,不为空时,枚举值之间用逗号隔开。
枚举值可以只写出标识符名称,也可以给它赋值,如A和A=1都是正确的;
接着是一个右大括号和一个分号。
尝试写BNF:
enum_decl=‘enum’ + option_identifier + ‘{’ + value_list + ‘};’
option_identifier=identifier | ‘’
value_list=’’ | value_list + ‘,’ + indentifier | value_list + ‘,’ + indentifier + ‘=’ + Num
写到最后的value_list会发现,不管怎么写都会多出一个逗号。
因为BNF里面的控制命令太少了,想要表达出我们想要表达的规则,我们得求助于EBNF。
EBNF介绍
EBNF,E即Extended,EBNF即扩展BNF范式。
下图列举了EBNF包含的符号:
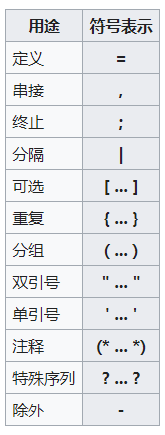
可见EBNF中包含了更多的控制命令。相对于BNF来说,它的描述能力更为强大。
用EBNF描述enum如下:
enum_decl = 'enum'[id]'{'[id'='num]{','id'='num}'}';
参考文章:https://blog.csdn.net/u012790503/article/details/112859204
https://blog.csdn.net/u012790503/article/details/114456254














 4960
4960











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









