







Webscrapping (Day 7)
Preparation: selenium, requests, lxml
实战大项目:模拟登录丁香园,并抓取论坛页面所有的人员基本信息与回复帖子内容。
丁香园论坛:晕厥待查——请教各位同仁 - 心血管专业讨论版 -丁香园论坛 。
因为没有国内手机号无法注册丁香园,改为一亩三分地。
Attention!!! 一定找代理IP,不会的同学可以查看我之前的帖子。https://blog.csdn.net/weixin_44706550/article/details/88230384
- 爬取一亩三分地的一篇帖子
- 首先设置登录命令,填入登陆信息并登陆
登陆后的页面是这样婶的,
- 尝试搜索内容,但因为积分不够,无法实现搜索。
- 不气馁,开始收集网页信息,回复人和回复信息。

结果输出
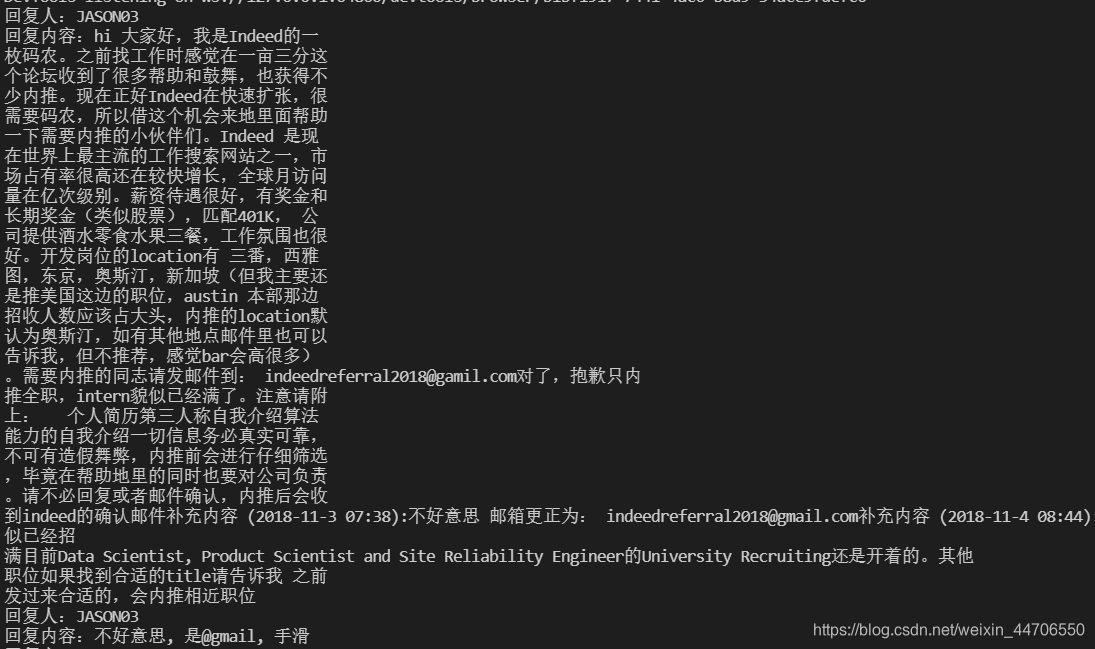
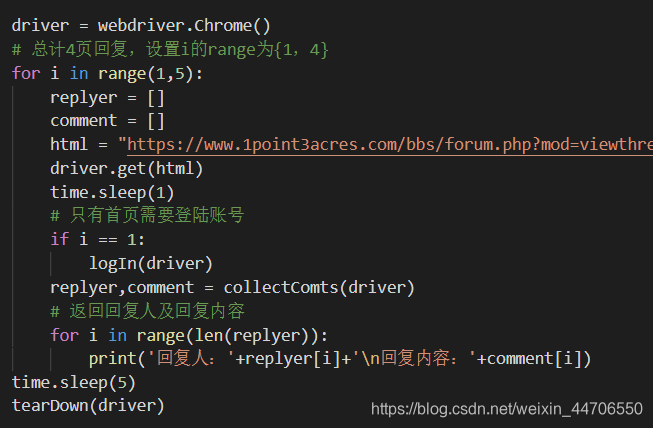
- 因为总共是4页回复,用一个小循环改变网址,就可以得到所有的回复人和回复信息。
- 总结
从登陆论坛,爬取回复人和回复信息,看到网页可以自动运行,结果正常输出,内心还是小有激动,7天不长,但真心学到了些爬虫知识,感谢Datawhale 爬虫群。














 2964
2964











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









