







1.最小生成树(Kruskal算法)
一个有n户人家的村庄,有m条路连接着。村里现在要修路,每条路都有一个代价,现在请你帮忙计算下,最少需要花费多少的代价,就能让这n户人家连接起来。
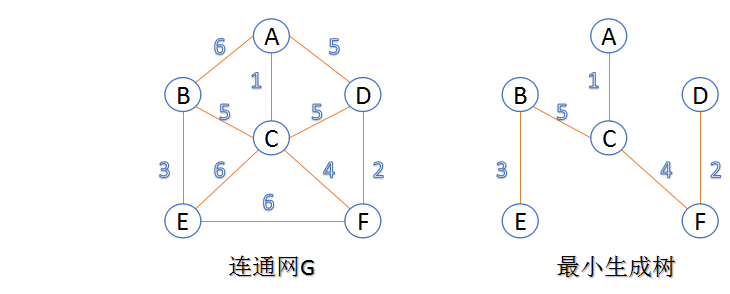
最小生成树:在连通网的所有生成树中,所有边的代价和最小的生成树,称为最小生成树。例如
解决最小生成树有两种解法:
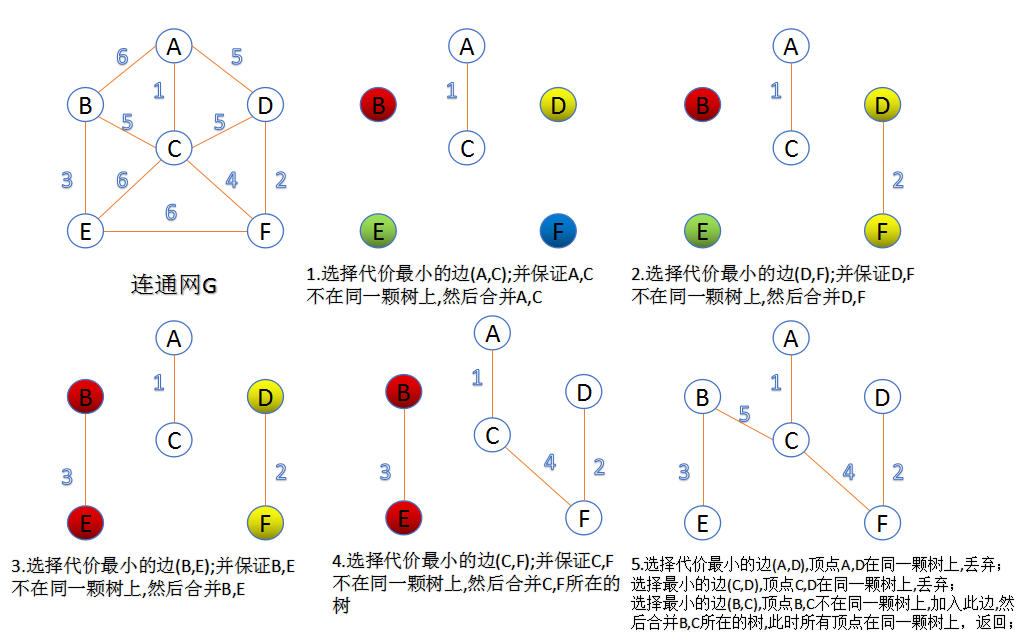
- Kruskal算法:初始最小生成树边数为0,每迭代一次就选择一条满足条件的最小代价边,加入到最小生成树的边集合里,具体可以看下图
一整个算法的流程是:
- 先对所有边进行排序,每次选取权值最小的边
- 选取到的边,需要判断是否已经在U集合中,也就是判断是否连通,这里可以使用并查的Find-Unio算法快速判断该节点是否已经在U集合中
import java.util.*;
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
* 返回最小的花费代价使得这n户人家连接起来
* @param n int n户人家的村庄
* @param m int m条路
* @param cost int二维数组 一维3个参数,表示连接1个村庄到另外1个村庄的花费的代价
* @return int
*/
public int miniSpanningTree (int n, int m, int[][] cost) {
// write code here
//进行排序,选取最小边
Arrays.sort(cost, new Comparator<int[]>() {
public int compare(int[] o1, int[] o2){
return o1[2] - o2[2];
}
});
//初始化数组 和Find-unio算法一致
int[] arr = new int[n + 1];
for(int i = 1;i < n + 1;i++){
arr[i] = i;
}
int res = 0;
for(int i = 0;i < m;i++){
//两个节点之间并没有连通
if(find(arr, cost[i][0]) != find(arr, cost[i][1])){
res += cost[i][2];
//将这两个节点设为连通
unio(arr, cost[i][0], cost[i][1]);
}
}
return res;
}
public static int find(int[] arr, int i){
int fi = i;
while(arr[fi] != fi) fi = arr[fi];
while(fi != i){
int temp = arr[i];
arr[i] = fi;
i = temp;
}
return fi;
}
public static void unio(int[] arr, int x, int y){
int fx = find(arr, x);
int fy = find(arr, y);
if(fx != fy){
arr[fx] = fy;
}
}
}
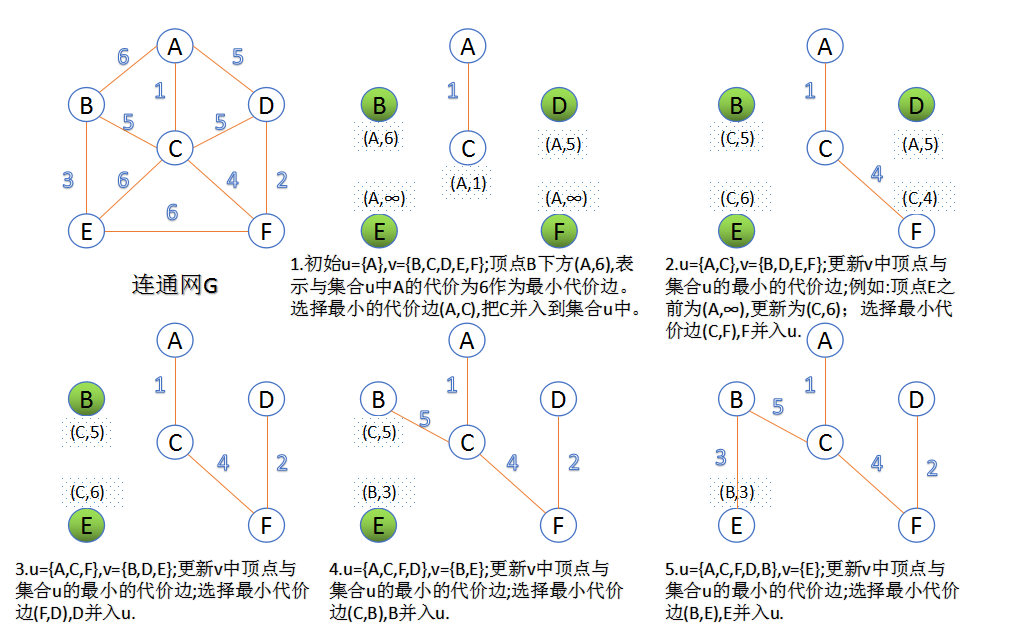
还有一种Prim算法,这里只复盘其思想
Prim算法与Kruskal算法刚好相反,Prim算法是加点法,每次迭代选取代价最小的点,加入到生成树中,算法从某一个顶点s开始,逐渐长大覆盖整个连通网的所有顶点。
2. 最短路径(Dijkdtra算法)
总体算法思想:从原点出发,找到离原点最近最近的一个顶点然后以该顶点为中心找到其他距离最近的点,本质上还是贪心思想
算法步骤:
- 定义两个数组,一个shorest数组,表示已经找到原点离i点的最点距离shorest[i],一个visited数组,表示该节点以及被访问过了
- 每次循环找到离原点最近的点,接着进行扩散,通过该最近的点再次找到最近的点
import java.util.*;
public class Main{
static int[][] weight;
static int[] shortest;
static int[] visited;
public static void main(String[] args){
final int M = 10001;
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
n++;
int m = sc.nextInt();
int s = sc.nextInt();
int t = sc.nextInt();
weight = new int[n][n];
for(int i = 1;i < n;i++){
for(int j = 1;j < n;j++){
weight[i][j] = M;
}
}
while(m-- > 0){
int x = sc.nextInt();
int y = sc.nextInt();
int z = sc.nextInt();
weight[x][y] = z;
}
shortest = new int[n];
visited = new int[n];
for(int i = 1;i < n; i++){
int min = M;
int index = 0;
for(int j = 1;j <n;j++){
if(visited[j] == 0 && weight[s][j] < min){
min = weight[s][j];
index = j;
}
}
visited[index] = 1;
shortest[index] = min;
for(int k = 1;k <n;k++){
if(visited[k] == 0 && weight[s][index] + weight[index][k] < weight[s][k]){
weight[s][k] = weight[s][index] + weight[index][k];
}
}
}
System.out.println(shortest[t] == 0 ? -1 : shortest[t]);
}
}
3. 删除链表中的重复节点
存在一个按升序排列的链表,给你这个链表的头节点 head ,请你删除链表中所有存在数字重复情况的节点,只保留原始链表中 没有重复出现 的数字。
返回同样按升序排列的结果链表。
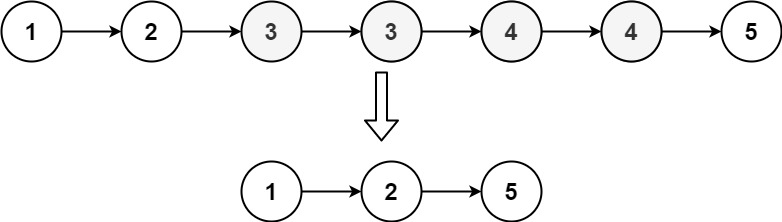
思路:这个题目是阅文集团的笔试题,时间不够了没有做出来,当时使用链表指向的做法思维很混乱,所以立即换了一种思路,使用hash表,但是需要注意的是需要使用LinkedHashMap因为插入顺序应该和链表顺序保持一致
class Solution {
public ListNode deleteDuplicates(ListNode head) {
Map<Integer, Integer> map = new LinkedHashMap<>();
ListNode temp = head;
while(temp != null){
map.put(temp.val, map.getOrDefault(temp.val, 0) + 1);
temp = temp.next;
}
List<Integer> list = new ArrayList<>();
for(int i : map.keySet()){
if(map.get(i) == 1){
list.add(i);
}
}
System.out.println(map);
ListNode res = new ListNode(0);
ListNode resTemp = res;
for(int i : list){
ListNode node = new ListNode(i);
resTemp.next = node;
resTemp = resTemp.next;
}
return res.next;
}
}
题解思路:只要将重复元素记下,然后重复比较重复删除即可
class Solution {
public ListNode deleteDuplicates(ListNode head) {
if(head == null) return null;
ListNode dumy = new ListNode(0);
dumy.next = head;
ListNode curr = dumy;
while(curr != null && curr.next != null && curr.next.next != null){
if(curr.next.val == curr.next.next.val){
int x = curr.next.val;
while(curr.next != null && curr.next.val == x){
curr.next = curr.next.next;
}
}else{
curr = curr.next;
}
}
return dumy.next;
}
}















 417
417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









