









 本文介绍利用Java实现Huffman编码。先阐述哈夫曼树是带权路径最小的二叉树,构建关键是让权重大的叶子靠近根节点。接着说明哈夫曼编码借助哈夫曼树对文本编码。还给出构建哈夫曼树步骤,最后展示Java代码实现过程,包括创建类、统计字符、构建树、遍历及输出编码等。
本文介绍利用Java实现Huffman编码。先阐述哈夫曼树是带权路径最小的二叉树,构建关键是让权重大的叶子靠近根节点。接着说明哈夫曼编码借助哈夫曼树对文本编码。还给出构建哈夫曼树步骤,最后展示Java代码实现过程,包括创建类、统计字符、构建树、遍历及输出编码等。
利用java实现Huffman编码。
哈夫曼树也称最优二叉树,也是带权路径最小的二叉树。
带权路径的值,就是各个节点的权重乘上深度,然后做和.
如下图,这棵树的带权路径值 为 1*3 + 2*3 + 3*2 +3*1 = 18
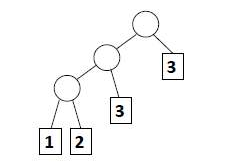
所以构建一个哈夫曼树的关键在于,让权重大的叶子更靠近根节点,权重小的叶子远离根节点。
哈夫曼编码就是借助哈夫曼树对文本进行编码操作。将一串字符串编码成 用 0 和 1 进行表示
假设有这么一串字符串: abbcccddddd
首先字符串按照字符分割,得到一个个字符,然后统计各个字符出现的次数:
a->1
b->2
c->3
d->5
把字符当作叶子,字符出现的次数当作叶子的权重,可以构建出下面这棵树:
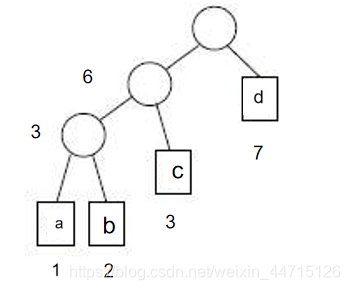
1. 首先选出出现次数最少的两个字符,当作叶子节点,根据他们的权重,计算出他们父节点的权重。
2. 再从剩下的节点中,与刚刚生成的节点比较,选出最小的一个或者两个,继续构造这棵树。
3. 重复这个过程,直到最后一个节点。
现在以abcdefg为例子:
出现字符次数相同的情景时,就按照字符进行排序。
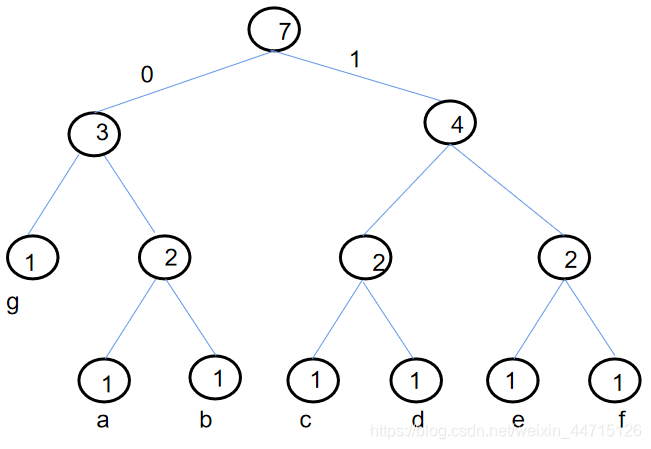
按照坐左枝为0 右枝为1 规则进行编码。
比如 a 010 g 00
所以,对abcedfg 进行编码之后,01001110010111011100
java代码实现:
1. 创建一个类,实现Comparable用来排序
class HFNode implements Comparable<HFNode> {
char character;
int frequence;
private HFNode left;
private HFNode right;
private String code;
public char getCharacter() {
return character;
}
public void setCharacter(char character) {
this.character = character;
}
public int getFrequence() {
return frequence;
}
public void setFrequence(int frequence) {
this.frequence = frequence;
}
public HFNode getLeft() {
return left;
}
public void setLeft(HFNode left) {
this.left = left;
}
public HFNode getRight() {
return right;
}
public void setRight(HFNode right) {
this.right = right;
}
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
@Override
public String toString() {
return this.character + " " + this.frequence + " ";
}
@Override
public int compareTo(HFNode o) {
if (this.frequence == o.frequence) {
return this.getCharacter() - o.getCharacter();
}
return this.frequence - o.frequence;
}
2. 分割字符串,统计每个字符出现的次数,并存放到队列中去。
Scanner in = new Scanner(System.in);
String inLine = in.next();
char[] chars = inLine.toCharArray();
Map<Character, Integer> characterMap = new HashMap<>();
for (int i = 0; i < chars.length; i++) {
int count = characterMap.containsKey(chars[i]) ? characterMap.get(chars[i]) : 0;
characterMap.put(chars[i], count + 1);
}
PriorityQueue<HFNode> pQueue = new PriorityQueue<>();
Set<Character> key = characterMap.keySet();
for (char c : key) {
HFNode hfNode = new HFNode();
hfNode.setCharacter(c);
hfNode.setFrequence(characterMap.get(c));
pQueue.add(hfNode);
}3. 构建哈夫曼树(两个叶子生成节点的字符,默认使用他的左树的字符)
每次取最小的两个节点出来,然后合并成一个新节点,再把新节点加入到队列中去。
while (pQueue.size() > 1) {
HFNode newNode = new HFNode();
HFNode leftNode = pQueue.remove();
HFNode rightNode = pQueue.remove();
newNode.setFrequence(rightNode.getFrequence() + leftNode.getFrequence());
newNode.setLeft(leftNode);
newNode.setRight(rightNode);
newNode.setCode("");
newNode.setCharacter(newNode.getLeft().getCharacter());
pQueue.add(newNode);
}
HFNode finalTree = pQueue.remove();
Queue<HFNode> queue = new ArrayDeque<>();
if (finalTree != null) {
queue.add(finalTree);
finalTree.getLeft().setCode("0");
finalTree.getRight().setCode("1");
}4. 广度优先遍历,并将节点和编码以字典的形式保存,用于后面按照输入顺序对编码进行输出
Map<Character, String> dict = new HashMap<>();
while (!queue.isEmpty()) {
HFNode node = queue.remove();
if (node.getLeft() != null)
node.getLeft().setCode(node.getCode() + "0");
if (node.getRight() != null)
node.getRight().setCode(node.getCode() + "1");
if (node.getLeft() != null) {
queue.add(node.getLeft());
}
if (node.getRight() != null) {
queue.add(node.getRight());
}
if (node.getLeft() == null && node.getRight() == null) {
dict.put(node.character, node.code);
}
}5. 按照输入顺序,将编码输出
进行大量字符串拼接时,stringBuilder性能更好。
StringBuilder string = new StringBuilder();
for (int i = 0; i < chars.length; i++) {
string.append(dict.get(chars[i]));
}
System.out.println(string);

















 905
905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









