







1、上传zookeeper-3.4.14.tar.gz并解压
tart –xvzf zookeeper-3.4.14.tar.gz
2、准备工目录:
mkdir zookeepr_dir
3、配置zookeeper:
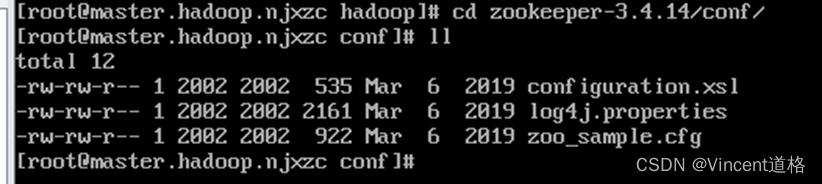
创建配置文件:
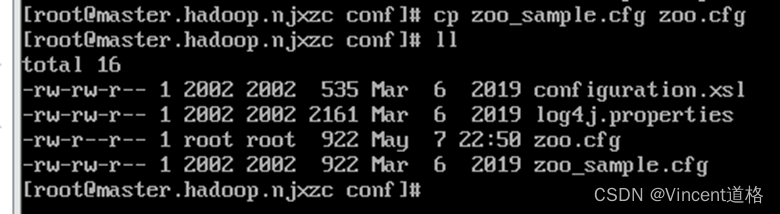
修改配置文件:
vi zoo.cfg
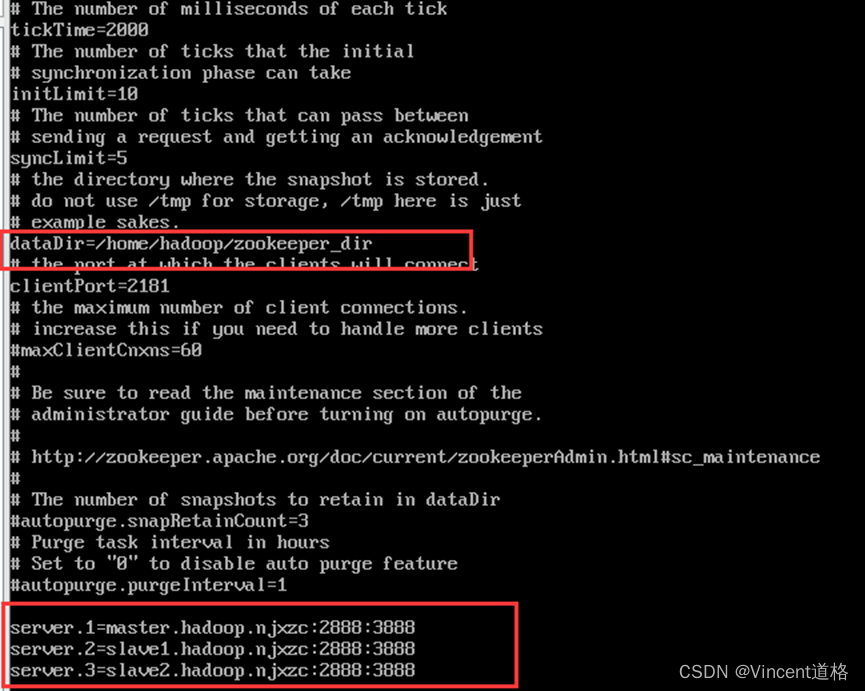
说明:
tickTime :心跳时间,单位毫秒
dataDir :存储数据信息的本地目录
initLimit:参数设定了允许所有跟随者与领导者进行连接并同步的时间
syncLimit:参数设定了允许一个跟随者与一个领导者进行同步的时间
2181:对client端提供服务
3888:选举leader使用
2888:集群内机器通讯使用(Leader监听此端口)
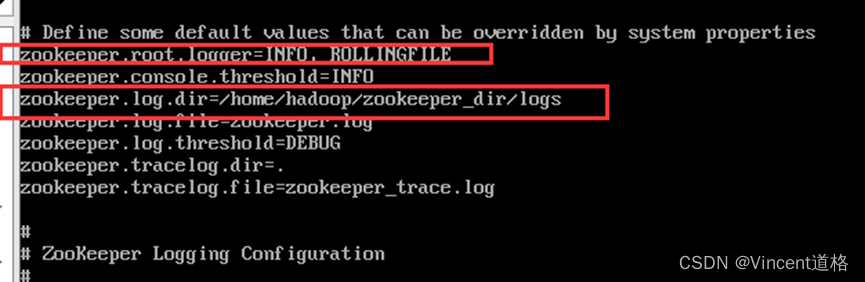
4、日志配置:
mkdir –p /home/hadoop/zookeeper_dir/logs
vi log4j.properties

cd /home/hadoop/zookeeper-2.4.14/bin
vi zkEnv.sh
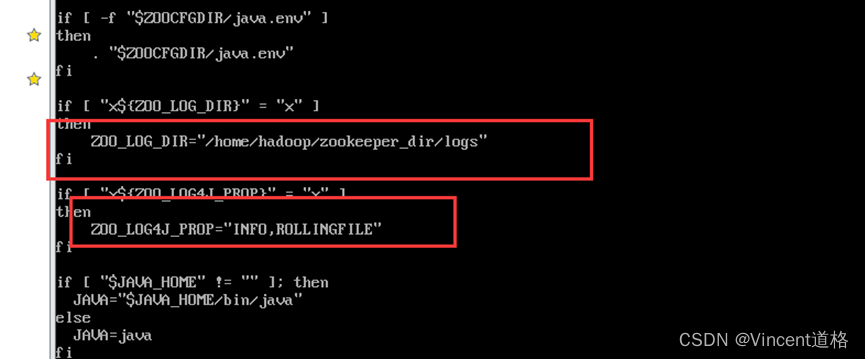
创建data文件夹
mkdir –p /home/hadoop/zookeeper_dir/data
5、分发:
zookeeper:
scp -r /home/hadoop/zookeeper-3.4.14/ root@slave1.hadoop.njxzc:/home/hadoop/
scp -r /home/hadoop/zookeeper-3.4.14/ root@slave2.hadoop.njxzc:/home/hadoop/
work_dir:
scp -r /home/hadoop/zookeeper_dir/ root@slave1.hadoop.njxzc:/home/hadoop/
scp -r /home/hadoop/zookeeper_dir/ root@slave2.hadoop.njxzc:/home/hadoop/
6、设置myid:推荐使用绝对路径
在主机master.hadoop.xzc上执行如下语句
echo “1” > /home/hadoop/zookeeper_dir/myid
在主机slave1.hadoop.xzc上执行如下语句
echo “2” > /home/hadoop/zookeeper_dir/myid
在主机slave2.hadoop.xzc上执行如下语句
echo “3” > /home/hadoop/zookeeper_dir/myid
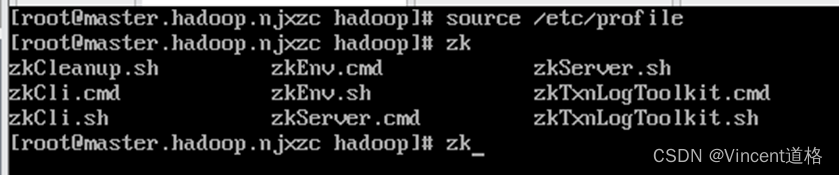
7、配置环境变量:
vi /etc/profile

source /etc/profile
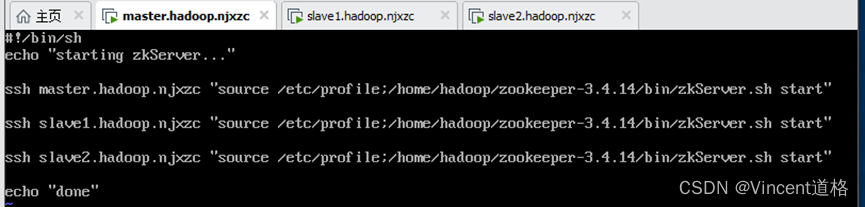
8、编写脚本,一键启动和停止zookeeper集群:
cd /home/hadoop/zookeeper-3.4.14/bin
vi start-allzk.sh
vi stop-allzk.sh
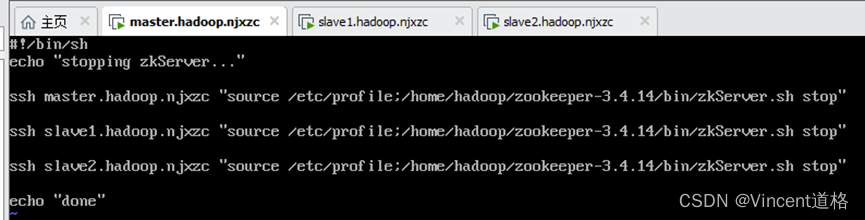
授权:
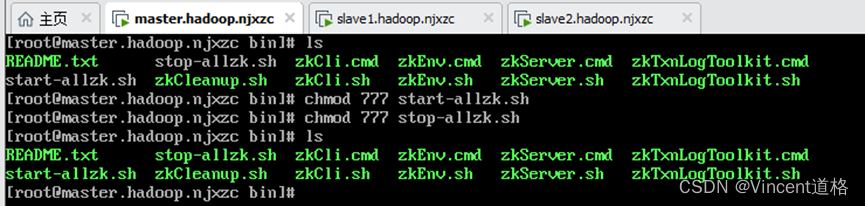
9、测试成功与否:
在master.hadoop.njxzc上执行一键启动脚本,并查看
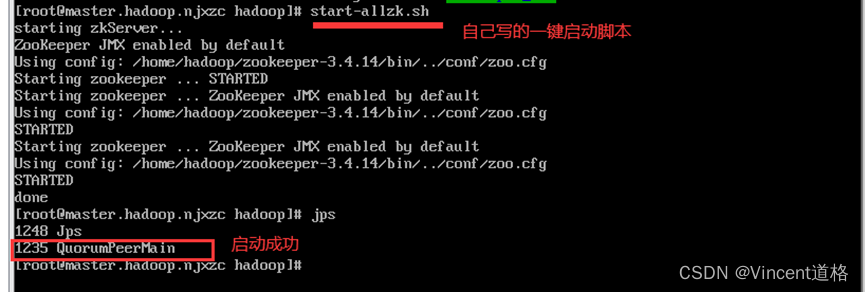
在slave1.hadoop.njxzc上查看

在slave2.hadoop.njxzc上查看

10、zookeeper的状态与操作:
查看状态信息:
zkServer.sh status



操作:
hbase,kafka……均会向zookeeper注册,并存储信息
如hbase服务器有问题,解决后,如果zookeeper中信息没有清除,hbase启动失败等问题
使用zkCli.sh操作
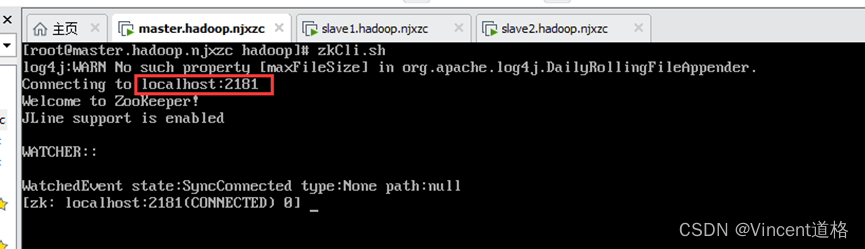
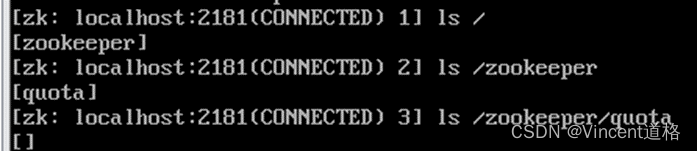
操作演示:














 1538
1538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









