






1、初识SAS
SAS的数据库术语中,最常用的两个术语是:观测 (observation) 和变量 (variable)。 一个研究对象,如一个人,一辆车,被称为观测;而一个人的性别、年龄、身高、体重等,一辆车的颜色、价格、排量等信息,被称为变量。 因此,变量也可以理解成是观测所拥有的某些属性性质。
1.1 前言
sas语句规则
SAS 语句结束用分号;
SAS 小写、大写混用,不区分大小写;(cat和CAT在SAS中意义相同)
SAS 语句可以开始在任意行的任何一列中,并且可以在同一行上写多个语句;
一条SAS语句可以在一行或多行写,但是不能将一个单词分成两行;
SAS 语句中的字词用空格或特殊字符分隔。
单引号(')和双引号(")的区别:
主要区别在于它们对宏变量和转义字符的处理:
1)单引号宏变量会将整个字符串作为文本,不解析其中的宏变量;双引号会解析宏变量并将其值嵌入到字符串中。
2)双引号会解释转义字符,例如 \n 表示换行;单引号不会解释转义字符,它会将 \ 视为普通字符。
总结:双引号通常用于包含字符串和宏变量,而单引号用于包含纯文本字符串,
命名规则:
数据集名称、变量名称和其他项目名称:
- SAS 名称可以包含 1~ 32 个字符;
- 第一个字符必须是字母或下划线 (_);
- 后续字符必须是字母、数字或下划线。
- 不能包含空格。
- 一个 PROC 语句,其中包括单词 PROC,想要执行的过程的名称、以及包含值的 SAS 数据集的名称。(如果省略:DATA= 选项和数据集名称,该过程将使用最近在程序中创建的 SAS 数据集。)
- 补充声明 向 SAS 提供有关您要执行的操作的更多信息,例如: CLASS、VAR、TABLE 和 TITLE 语句。
- 一个 RUN 语句,其中 表示前面的一组语句已准备好执行。
语句
DATA SAS-data-set;/*开始一个 DATA 步骤 告诉 SAS开始创建 SAS data set. SAS-data-set 命名为将要被创建的data set.*/
%INCLUDE source(s) </<SOURCE2> <S2=length> <host-options>>;/*源SAS编程 语句、数据线, 或者两者都进入当前SAS编程项目.*/
RUN;/*tells SAS to begin executing the preceding group of SAS statements.*/
程序(procedures)
开始 PROC 步骤,然后 告诉 SAS 调用特定的 SAS 过程来处理 SAS 在 DATA= 选项中指定的数据集。如果省略 DATA= 选项,则该过程将处理最近创建的 SAS 程序中的数据集。
PROC procedure <DATA=SAS-data-set>;
/*begins a PROC step and tells SAS to invoke a particular SAS procedure to process the SAS data set that is specified in the DATA= option. If you omit the DATA= option, then the procedure processes the most recently created SAS data set in the program.*/
FILENAME 语句
FILENAME MyWeight ‘C:\sasuser\MyWeight\myweight.dat’;
/*将 fileref MyWeight 分配给名为 myweight.dat 的文件*/FILENAME 语句 将 FileRef 分配给外部文件。之间的关联 fileref 和外部文件仅在 SAS 期间持续存在会话,或者直到使用另一个 FILENAME 更改 fileref 语句。
LIBNAME 语句
LIBNAME Weight ‘C:\sasuser\MyWeight’;
/*此 LIBNAME 示例将 libref Weight 分配给名为 MyWeight 的 SAS 库*/LIBNAME 语句 将 libref 分配给 SAS 数据集或可访问的 DBMS 文件 就像SAS数据集一样。libref 和 SAS 库之间的关联 仅在 SAS 会话期间持续或直到您更改为止 libref 通过使用另一个 LIBNAME 语句。
在 SAS 作业中使用外部文件
FILE、INFILE
INFILE '外部文件';语句:
数据 <libref.>SAS-data-set;
告诉 SAS 开始创建 a SAS数据集。如果省略 libref,则 SAS 会创建一个临时 SAS 数据集。(SAS 附加
了 libref WORK 以进行内部处理。 如果将先前定义的 libref 作为 name,则 SAS 将数据集永久存储在
引用的库中 由 libref.SAS 程序或程序的一部分开始 以 DATA 语句结尾,以 RUN 语句结尾,另一个
DATA 语句或 PROC 语句称为 DATA 步骤。
文件名 fileref '您的输入或输出文件';
关联 fileref 替换为外部文件。在引号中将外部文件的名称括起来 标志着。
INFILE 文件引用 |“您的输入文件”;
标识外部 INPUT 语句要读取的文件。指定具有 被分配了 FILENAME 语句或适当的操作 environment 命
令,或指定外部文件的实际名称。
INPUT 变量 <$>;
使用 读取原始数据 列表输入。任意两个数据值之间必须至少出现一个空白。 $ 表示字符变量。
INPUT 变量 <$>column-range;
读取原始数据 在列中对齐。$ 表示字符变量。
INPUT 变量格式;
使用 读取原始数据 格式化的输入。信息提供特殊的阅读说明 数据。
LIBNAME libref '您的SAS数据库';
关联 libref 使用 SAS 库。将库的名称括在引号中。 SAS 通过匹配两级中的 libref 来查找永久 SAS 数
据集 SAS 数据集名称,其中包含与该 libref 关联的库 LIBNAME 语句。创建 SAS 库的规则取决于 您的
操作环境。
ATTRIB 语句
有关的信息 ATTRIB 语句如何使您能够为变量赋值, 请参见SAS DATA Step Statements: Reference 中
的 ATTRIB 语句。
DBMS 访问
"dbms=excel replace" 是一个数据步骤(Data Step)选项,用于指定将 SAS 数据集输出到 Excel 文件
时的操作。具体来说,"dbms=excel" 表示将数据输出到 Excel 文件,"replace" 表示如果文件已经存
在,则替换原有文件。
本文档解释 如何使用SAS读取原始数据和SAS数据集的文件,以及 写入 SAS 数据集。但是,SAS/ACCESS 的
SAS 文档提供了有关 使用 SAS 读取和写入存储在多种类型的 数据库管理系统 (DBMS) 文件。
格式
为 有关用于日期的格式的讨论,请参见在 SAS 系统中使用日期。
变量长度
欲了解更多信息 有关变量长度如何影响以下值的信息 您可以存储在变量中,请参阅使用数值变量和使用字
符变量。
LINESIZE= 选项
有关的信息 如何在 INPUT 语句中使用 LINESIZE= 选项来限制如何 INPUT 语句读取的每行数据的大部分
内容,请参见 SAS DATA Step Statements: Reference 中的 INPUT 语句。
MERGE、MODIFY 或 UPDATE 语句
除了 SET 语句中,可以使用 MERGE、MODIFY 或 UPDATE 语句。欲了解更多信息, 请参见合并 SAS 数据
集 更新 SAS 数据集。
SET 语句
供参考 关于 SET 语句,请参见从 SAS 数据集开始。
USER= SAS 系统选项
您可以指定 USER= SAS 系统选项,用于使用一级名称指向永久名称 SAS 文件。(如果指定 USER=WORK,
则 SAS 假定文件 使用一级名称引用的引用是指临时工作文件。为 有关详细信息,请参见《SAS 系统选项:
参考》。1.2建立一个简单的SAS数据集
1.2.1用SAS输入
1.用data语句起名字
基本格式:
data 数据集名称;数据集名称命名规则:只能由英文、数字、下划线组成,且不能以数字开头,长度不能超过32个字符。
2.用input语句输入变量
基本格式:
input 变量1 变量2...;input输入变量:的作用是读取下一个变量需要满足:要么遇到空格,要么变量的宽度读完了;&的作用是告诉SAS遇到一个空格不读取下一个变量,当遇到一个以上的空格时读取下一个变量。
3.cards语句引领数据输入
基本格式:
cards;
数据
;输入数据用cards或datalines均可。
SAS 变量可以具有 这些属性:
- 名字
- 类型
- 长度
- 信息格式
- 格式
- 标签
- 观测位置
- 索引类型
DATA= 选项和数据集名称
1.2.2建立一个永久SAS数据集
SAS资源管理器:包含逻辑库、文件快捷方式、收藏夹、计算机
逻辑库:逻辑库中名为Work的文件夹,用来存放临时数据集;建立在非Work文件夹下的数据集一般称为永久数据集。
建立永久数据集方式:
data 文件夹名称.数据集名称;/*文件夹名称即逻辑库名称*/新建逻辑库语句:
libname 逻辑库名称 "硬盘文件夹路径和名称";或者直接用data语句指定一个路径和SAS数据集名,例:
data "g:\excel\first";/*相当于在G盘中的excel文件夹中生成了一个名为first的逻辑库*/1.2.3如何从别的软件导入数据
导入数据:单击文件导入可以导入多种数据类型。步骤省略
2.数据集建立
2.1SAS变量的输入格式
input 变量1 输入格式1 变量2 输入格式2 ......;两种:字符型(character)、数值型(numeric)
2.1.1数值型变量的输入格式
w.d,w表示数值的总位数或宽度(包括小数点);d表示数值的小数部分位数。要注意的是没有小数w.d里的.也不能不写。
设定w.d格式的时候,没有小数点的整数自动把自己降为整数;例如:x指定格式4.2,22就会降为0.22。
数值型变量的实际值与原始数据保持一致,格式化只改变其显示值。
2.1.2字符型变量的输入格式
$ w.,$是必须加的,w表示字节数(1个中文占2字节),SAS默认对字符只读取8位。
注:只要加上宽度值,后面必须跟着“.”,但如果只写$符号没有宽度值就不用加“.”。
2.1.3日期型变量的输入格式
日期类型作为数值型,所有的日期型变量作为输入日期与1960年1月1日之差。日期变量的宽度最大不能超过32位。
/*日期:在可以在变量后声明日期格式*/
| 常见 输入格式 | 宽度w范围 | 举例 | 具体输入格式 |
| YYMMDDw. | 6~32 | 20200923 | YYMMDD8. |
| 2020/09/23 | YYMMDD10. | ||
| MMDDYYw. | 6~32 | 092320 | MMDDYY6. |
| 09/23/20 | MMDDYY8. | ||
| DDMMYYw. | 6~32 | 280920 | DDMMYY6. |
| 28/09/2020 | DDMMYY10. | ||
| DATEw. | 7~32 | 28JUL20 | DATE7. |
| 28JUL2020 | DATE9. | ||
| MONYY7 | 5~32 | JUL2020 | MONYY7. |
| JUL13 | MONYY5. |
2.1.4两个特殊输入符号——:和&
1.冒号(:)的作用:是读取下一个变量需要满足:要么遇到空格,要么变量的宽度读完了。
2.&的作用:是告诉SAS遇到一个空格不读取下一个变量,当遇到一个以上的空格时读取下一个变量。
data 数据集名称;/*用data给数据集取名,*/
inpute 字段名1:$12. 字段名2&:$50.;/*input输入变量,:的作用是读取下一个变量需要满足:要么遇到空格,要么变量的宽度读完了;&的作用是告诉SAS遇到一个空格不读取下一个变量,当遇到一个以上的空格时读取下一个变量*/
cards;/*cards的作用是告诉SAS下面开始输入数据*/
数据1XXX 数据1xx yy
数据2XXX 数据2xx yy
;
proc print;/*打印结果*/
run;/*运行*/2.1.5当数据由字符分隔时,而不是空白
DML:
infile datalines dlm=',';
/*默认情况下,列表输入会扫描 输入记录,查找空格以分隔每个数据值。 DLM='选项使列表输入能够识别字符',此处为 逗号,作为分隔符。*/DLM= '选项',该选项仅在 INFILE 语句中可用。
data club1;
infile datalines dlm=',';
input IdNumber Name $ Team $ StartWeight EndWeight;
datalines;
1023,David,red,189,165
1049,Amelia,yellow,145,124
1219,Alan,red,210,192
1246,Ravi,yellow,194,177
1078,Ashley,red,127,118
1221,Jim,yellow,220,.
;
proc print data=club1;
title 'Weight of Club Members';
run;DSD:
data club1;
infile datalines dsd dlm=':';
input IdNumber Name $ Team $ StartWeight EndWeight;
datalines;
1023:David:red:189:165
1049:Amelia:yellow:145:124
1219:Alan::210:192
1246:Ravi:yellow:194:177
1078:Ashley:red:127:118
1221:Jim:yellow:220:.
;
proc print data=club1;
title 'Weight of Club Members';
run;DSD是和DLM可结合用,也可单独用.
(1)如果你的数据里有变量含有引号,那么DSD告诉sas可以不用解读引号内的delimiter;
(2)如果是数字变量中有delimiter的话,可以忽略,例如1,000在读入SAS后将是1000;
(3)如果变量值中连续出现两个delimiter,DSD将视其为遗失数据。DSD默认的delimiter是逗号,如果delimiter不是逗号的话,就需要用DLM来定义这个delimiter了 。
关键字 missover 可以让 SAS 不进入下一行读取,未赋值的变量就使其成为缺失值。
格式化输入
有时 INPUT 语句需要特殊说明才能正确读取数据:
例如,SAS 可以读取特殊格式的数值数据 例如二进制、压缩十进制或日期/时间。SAS 还可以读取数字、包含逗号和货币等特殊字符的值 符号。在这些情况下,请使用格式化的输入。格式化输入 将列输入的功能与读取非标准的能力相结合 数值或字符值。以下数据显示格式化输入:
- 1,262
- $55.64
- 02一月2013
data january_sales;
input Item $ 1-16 Amount comma5.;
/*INPUT 语句 无法将变量 Amount 的值读取为有效的数值 没有 Informat.信息格式,
comma5.使 INPUT 语句能够读取此数据并将其存储为 有效的数值。*/
datalines;
trucks 1,382
vans 1,235
sedans 2,391
;
proc print data=january_sales;
title 'January Sales in Thousands';
run;
data january_sales;
input Item $10. @17 Amount comma5.;
/*@17:指示指针移动到输入缓冲区中的第 17 列,让它处于读取变量值的正确位置 量*/
datalines;
trucks 1,382
vans 1,235
sedans 2,391
;
data january_sales;
input Item $10. +6 Amount comma5.;
/*相对列指针控件 +6:指示指针 在 SAS 读取下一个数据值之前向右移动六列。*/
datalines;
trucks 1,382
vans 1,235
sedans 2,391
;列指针控件:
@n:将指针移动到 输入缓冲区中的第 n 列。
+n:向前移动指针 输入缓冲区中的 n 列。
/:将指针移动到 输入缓冲区中的下一行。
#n:将指针移动到 输入缓冲区中的第 n 行。
当 DATA 步骤读取时 来自外部文件的原始数据,当 SAS 遇到 在读入所有变量的数据之前输入行的末尾 在 input 语句中指定。读取时可能会出现此问题 可变长度记录和/或包含缺失值的记录。
2.2SAS变量的输出格式
2.2.1数值型变量的输出格式:
w.d与输入格式里面呢的w.d格式一样。
commaw.d将数值的整数部分自右向左每三位用逗号隔开,当数值位数较多时,这是比较标准的表示方式。
percentw.d将数据转化为百分比形式显示,%占3个字节。
2.2.2字符型变量的输出格式
字符型输出格式也是¥w.,w表示字节数(1个中文字符占2个字节)。
data 数据集名称;
input num cost prop;
format num 5.2 cost comma12.1 prop percent8.2;/*format设置输出变量的显示格式*/
cards;
50 10101600 0.1236
45 9580000 0.0361
;
proc print;
run;data fss;
input x$ y$2,;
format x$2.;/*只改变输出的显示,内存中变量的值并没有改变*/
x1=x+1;
y1=y+1;/*可以直接运算*/
cards;
1100 1100
;
proc print;
run;
/*上述代码执行后结果:
x:11 y:11 x1:1101 y1:12
*/2.2.3日期型变量的输出格式
| 字母 | 输出格式示例 | 显示示例 |
| s(/) | YYMMDDs8. | 13/07/28 |
| d(-) | YYMMDDd8. | 13-07-28 |
| p(.) | YYMMDDp8. | 13.07.28 |
| c(:) | YYMMDDc8. | 13:07:28 |
| b(空格) | YYMMDDb8. | 13 07 28 |
| n(无) | YYMMDDn8. | 20130728 |
注:这六个字母只能在输出格式中出现,不能在输入格式里加这六个字母。
2.3自定义输入和输出格式:
/*通过proc format过程来实现*/
proc format;
invalue <$> 格式名 变量值或范围1=输入格式91 变量值或范围2=输入格式2...;/*invalue语句定义输入格式,并起名*/
value <$> 格式名 变量值或范围1=输出格式1...;/*<>是可选项的意思 里面的内容可加可不加,如果定义的输入格式是字符格式的就需要写上$*/
picture 模板名 <数值范围>;2.3.1用informat和format自定义格式
invalue语句中,根据“输入格式”来确定是否应该加$符号,而value语句根据“变量值或范围”来确定是否需要加$符号。
原因:输入格式是真正改变变量值的,所以要按新值“输入格式”来判断是否为字符变量。而输出格式不改变变量值,所以要按原值“变量值或范围”来判断是否是字符。
举例:
invalue $ gender 1="male" 2="female";/*创建输入格式gender,当输入1和2时,自动变为male和female。由于male和female是字符变量,所以gender前加$*/
value $ grade "a"-"g"="fair" "o","u"="other";/*创建输出格式grade,当输入值介于a~g之间,输出为fair,o和u输出为other*/
invalue grade "a"-"g"=1 other=2;/*创建输入格式grade,当输入值介于a~g之间,读取为1,其他字母读取为2*/
value age low-<40=30 40-<50=40 50-high=50;
invalue lxfmt 1-4=_same_ 99=.;/*创建输入格式lxfmt,当输入值为1~4时,保持原有值不变,当输入值为99时,变为“.”*/
proc format;/*proc format定义一个过程在这个过程中可以定义自己想要的格式。*/
invalue $grade 1="freshman" 2="sophomore" 3="junior" 4="senior"
value fscore low-<60="不及格" 60-80="及格" 80-high="优秀";
data grade;
input id grade: $grade20. score;
format score fscore.;/*fomate将两个变量关联起来,让变量score按fscore.的格式输出*/
cards;
1 1 60
2 4 59
3 3 80
4 2 79
;
proc print;
run;2.3.2使用picture设置输出模板
格式:
picture 指定样式名 表达式;/*看P39代码*/2.4如何产生新变量
2.4.1利用表达式或者函数直接产生新变量:
格式:
变量名=函数表达式;变量名既可以是新变量也可以是已有变量,如果是已有变量表示新值代替旧值。
SAS中常见的运算符:
算数运算符:+、-、*、/、**(幂次方eg:2**3=8)
比较运算符:=、^=(不等于)、>、<、>=、<=、in
逻辑运算符:&或and(多个表达式同时成立)、|或or(多个表达式至少有一个成立)
注:新建变量必须卸载input和cards之间,cards之后一定要紧跟数据不可以跟其他语句;
2.4.2选择语句if-then产生新变量:
格式:
if 表达式 then 新变量= ;
else 新变量= ;2.4.3利用retain语句和累加语句产生新变量:(难、但实用)
格式:
retain 变量 <初始值>;作用:生成一个变量,指定他的初始值,并保留改变量每次计算的结果。如果没有指定初始值默认初始值为缺失值。
更简洁的方式:变量+表达式 (相当于变量=变量+表达式,同时也兼备retain语句的功能。)
2.4.4do循环语句产生新变量:
语法:
/*初始值、最终值、增加量可以是数值也可以是字符*/
do 变量=初始值 to 最终值 <by 增加量>;
SAS语句;
end;例子:
data fh;
do count=1 to 5;
input time;
output;/*注意:用do循环必须要有output语句,作用:通知SAS显示前面的数*/
end;/*do循环结束的标识,如果不写SAS会给不出结果*/
cards;
23
22
24
21
46
;
run;2.4.5指定新变量的类型与长度:
SAS主要是用length语句来指定新变量的长度与类型。
格式:
length 变量1 <$> 长度1 变量2 <$> 长度2 ...;该语句的意思是对变量指定一个长度,如果是字符型变量,还需要加上$符号。数值型变量可指定3~8,字符型变量长度可以指定1~32767。
length语句一定要在新变量产生之前就设定好,否则不起作用。
SAS有一个规则:字符型变量的长度是由第一个遇到的值的长度决定的,而且字符变量一旦产生,它的长度就无法改变。
2.5@符号在输入方式中的应用(行保持说明符):
SAS默认每行读取的数据是和变量数对应的,比如有2个变量,SAS每行就只会读取两个数,读完后无论右边还有没有数据都立刻转到第二行继续读取。
强制SAS继续往右读的方式:在input语句的最后面加上@@符号。
@@和@都是强制SAS往右读取数据
@比@@程度弱
@只在一定条件下才起作用,只有data步中有2个input语句的时候,才对第二个input语句作用,如果只有一个input语句@不起作用。
行控制符 @ 表示执行下一个操作时,指针移到下一个记录。 @@表示执行下一个操作,指针保持在当前记录。
用到两个input的情况:简化输入
例:
data score;
input gender$ id score;
cards;
M 1 86
M 2 88
M 3 78
M 4 82
F 1 45
F 2 56
F 3 33
;
proc print;
run;
data score;
input gender$ n@;
do id=1 to n;
input score@@;
output;
end;
cards;
M 4 86 88 78 82
F 3 45 56 33
;
proc print;
run;2.6SAS函数应用技巧
SAS help中可以查看所有函数
2.6.1与数值计算有关的函数
与数值计算有关的几个函数
| 函数 | 用途 |
| abs(x) | 返回x的绝对值 |
| exp(x) | 返回x的指数值 |
| log(x) | 返回x的自然对数值 |
| sqrt(x) | 返回x的平方根 |
| mod(x,y) | 返回x除以y的余数 |
| ceil(x) | 返回大于等于x的最小整数 |
| floor(x) | 返回小于等于x的最大整数 |
| round(x,舍入值) | 根据舍入值对x四舍五入 例子:round(4.8,2),意思是将4.8舍入到最接近能被2整除的数值(0、2、4、6、...)最接近4,所以返回值为4 |
| int(x) | 返回x的整数部分 |
例子:划分年龄组
data aa;
input age@@;
gage=round(age-5,10);
cards;
29 31 39 40 55
;
proc print;
run;按编号奇偶数分组
data aa;
input id@@;
if mod(id,2)=1 then group="A"; else group="B";
cards;
1 2 3 4 5 6 7 8 9 10
;
proc print;
run;2.6.2与字符有关的函数
1.计算变量的长度
length(变量)/*计算变量长度,对缺失值返回1*/
lengthn(变量)/*计算变量长度,对缺失值返回0*/2.提取变量中的字符
substrn(变量,起始位置<,提取长度>)/*变量值第一位就是1*/3.查找变量中的字符
find(变量,查找内容 <,"i"> <,起始位置>)
findc(变量,查找内容 <,"i"> <,起始位置>)/*根据指定的起始位置,查找相应的内容,如果找到,就返回找到的位置,如果找不到,就返回0 ; <,"i">:忽略查找字符的大小写*/
find和findc的区别:
find对于多个字符的查找find必须是所有字符都完全匹配才算找到。
findc对于多个字符的查找只要找到其中任意字符就算找到。
anyalpha(变量<,起始位置>)/*查找变量中任意的字母,并返回第一个字母的位置*/
anydigit(变量<,起始位置>)/*查找变量中任意的数字,并返回第一个数字的位置*/
anyalnum(变量,<,起始位置>)/*查找变量中任意的字母或数字,并返回第一个字母或数字的位置*/例子:
data computer;
input type$@@;
alpha=anyalpha(type);
digit=anydigit(type);
xh=substrn(type,alpha,digit-alpha);
bh=substrn(type,digit,length(type)-digit+1);
cards;
TP340 ks320 b3510 c560 h430
;
PROC print;
run;4.替换变量中的字符
tranwrd(变量,查找值,替换值)/*从变量中找到“查找值”,并用“替换值”替换掉*/
例子:
data lx;
input id lx$;
lx1=transwrd(lx,"显效","有效");
lx1=tranwrd(lx1,"痊愈","有效");
cards;
1 显效
2 显效
3 显效
4 痊愈
;
proc print;
run;5.去除变量中的字符
compress(变量,<欲去除的字符>,<"修饰符">)/*从变量中除去"欲去除的字符"*/常用的修饰符:a:去掉变量中的所有字母
d:去掉变量中的所有数字
s:去掉变量中的所有空格
i:忽略大小写
k:保留"欲去除的字符",去掉其他字符
例子:
data phone;
input phone:&$20.;
phone1=compress(phone,"(-) ");/*去除phone中的"("、"-"、")"\" "*/
phone2=conpress(phone,,"kd");/*保留phone中的所有数字*/
cards;
(010)56799976
010-64075841
;
proc print;
run;
6.变量的合并
cats(变量1,变量2,...)/*将几个变量合并为一个变量,删掉前后空格*/
catx("分隔符",变量1,变量2,...);/*将几个变量合并为一个变量,中间用分隔符隔开*/7.清点变量中某字符的个数(计数)
count(变量,欲清点的字符<,"i">)/*从变量中找到"欲清点字符",返回字符个数,如果没找到,返回0*/
/*指定修饰符i作用是忽略大小写*/例子:
data smile;
input pj&:$100. ;
laugh=count(pj,"哈");
cards;
哈哈哈哈
红红火火恍恍惚惚
哈哈哈哈哈哈哈哈
;
proc print;
run;
8.查找变量中的缺失值
missing(变量)/*判断变量是否为缺失值,是则返回1,不是则返回0*/2.6.3与日期和时间有关的函数
1.日期的合并与差值
mdy(月,日,年)/*将年、月、日合并为一个日期格式或变量值*/
yrdif(开始日期,结束日期,"计算依据")/*计算两个日期之间以年为单位的差值*/
datdif(开始日期,结束日期,"计算依据")/*计算两个日期以天为单位的差值*/计算依据通常指定为"actual",也就是按当年的实际天数计算。
2.日期的提取
与日期和时间提取有关的几个函数
| 函数 | 作用 |
| year(日期变量) | 返回日期变量或日期值的年 |
| month(日期变量) | 返回月份 |
| day(日期变量) | 返回几号 |
| qtr(日期变量) | 返回日期变量或日期值的季度 |
| week(日期变量) | 返回日期变量或日期值的周数(第几周) |
| weekday(日期变量) | 返回日期变量或日期值的周(周几) |
| datepart(日期时间变量) | 返回日期部分 |
| timepart(日期时间变量) | 返回时间部分 |
| hour(日期时间变量或时间变量) | 返回日期时间变量或者时间变量的小时部分 |
| today() | 返回当天的日期 |
输入输出常见的格式:
datetimew.格式(w.指定长度),主要用于ddmmmyyhh:mm:ss格式的数据,例:
26JUN09:13:00:00
ymddttmw.格式(w.指定长度),主要用于<yy>yy-mm-dd/hh:mm:ss格式的数据(日期和时间的间隔除了“/”外,还可以是"-",".",":") 。
timew.(w.指定长度),主要用于只有时间。
2.6.4与变量类型转换有关的函数
input函数主要用于将字符型转为数值型,put函数主要用于将数值型转换为字符型。
格式:
input(变量,输入格式)/*字符型转换为数值型,或将字符型转换为其他格式的字符型*/
put(变量,输出格式)/*数值型转换为字符型,或将字符型转换为其他格式的字符型*/input例子
data date;
input year1$ month1$ day1$ year2$ month2$ day2$;
date1=catx("/",year1,month1,day1);
date2=catx("/",year2,month2,day1);
d1=input(date1,yymmdd10.);/*date1并非是日期型而是字符型,不能做计算,要转为数值型设置日期格式才能做计算*/
d2=input(date2,yymmdd10.);
format d1 d2 yymmdd8.;/*todo 不懂为什么要加这段代码or删除这段代码对代码运行有没有影响*/
dif=d2-d1;
cards;
2013 05 21 2014 03 11
2023 09 22 2023 10 30
;
proc print;
run;put例子:
proc format;
invalue fage low-<40=30 40-<50=40 50-<60=50 60-high=60;
data age;
input id age fage.;
cards;
1 38
2 34
3 76
4 48
;
proc print;
run;
proc format;
value fage low-<40=30 40-<50=40 50-<60=50 60-high=60;
data age;
input id age;
ageg=put(age,fage.);
cards;
1 38
2 34
3 76
4 48
;
proc print;
run;当使用自定义格式时,如果input函数,proc format就要用invalue语句;如果用put函数,proc format就要用value语句。
put函数的输出一定是字符型的,input函数输出的值一定是字符型的。
用input函数和put函数转换已有变量的格式,一定要赋值给另外一个新变量,而不能是原有变量。
2.6.5与概率和分布有关的函数
概率分布函数:
cdf('分布',分位数,参数)/*返回指定分布累积概率分布与分位数对应的概率*/
分布:指定相应的分布。
分位数:指定相应的分位数。
参数:指定与分布对应的参数,可以是1个或多个。
cdf函数常用的几个分布及参数
| 分布名称 | cdf函数 | 作用 |
| 正态分布 | cdf('normal',x,θ,λ) | 在均数为θ、标准差为λ的前提下,小于等于x累计概率 |
| 二项分布 | cdf("binomial",m,p,n) | 在事件发生率为p的前提下,n例总数中出现小于m例事件发生数的累积概率 |
| Poisson分布 | cdf('poission',m,n) | 在已知事件发生数为n的前提下,出现事件发生数小于m例的累积i概率 |
2.6.6dif和lag函数
数据集的主要操作是基于变量之间,而不是观测之间。你可以很轻松地求出两个变量之间的差值,但无法求出两个观测之间的差值。
lag函数作用:返回指定变量的前一个(或前几个)记录;
dif函数作用:返回当前记录与前一个(或前几个)记录的差值。
这两个函数在整理动态数据、纵向数据方面几乎是必备的。
lag(变量)、lag2(变量)、lag3(变量)、..../*lag后面的数是几就代表返回前几个记录*/
dif(变量)、dif2(变量)、dif3(变量)、..../*可以理解为DIF(X)=X - LAG(X)*/可以用于计算环比一类的指标。
例子:
data dm;
input year profit;
plag=lag(profit);
pdif=dif(profit);
pratio=profit/plag;
cards;
2008 988
2009 1022
2010 1580
2011 5689
2012 6789
;
proc print;
run;
2.7小结
3.SAS数据清洗和加工
数据处理流程:数据录入-->数据清洗-->数据分析
数据清洗和加工一般包括数据合并你、比较、缺失值的查询和填补、查找重复值、生成数据子集、产生新变量等。
首先把要清洗处理的表导入到SAS中
3.1数据合并(组合SAS数据集)
组合数据集的五种方法:串联(Concatenating )、交织(Interleaving)、合并(Merging)、更新(Updating)、修改(Modifying)。定义:SAS Help Center
3.1.1串联(连接)
set语句
data 数据集;
set 数据集1(数据集选项) 数据集2(数据集选项) ...;
run;set语句的作用是将若干个数据集依次纵向连接,并存放到data语句建立的数据集中。如果det后面只有一个数据集,相当于复制的作用,也就是将set指定的数据集中的数据复制到data语句建立的数据集中。
set 数据集1(in=临时变量1) 数据集2(in=临时变量2) ...;
set 数据集1(rename=(原名1=新名1 ...)) 数据集(rename=(原名1=新名1 ...)) ...;set 数据集1(in=临时变量1)意思是针对数据集1产生一个临时变量1,当合并的记录属于数据集1时,该临时变量值为1,否则为0。所以可以利用in=选项判断合并的记录哪些属于数据集1,哪些属于数据集2。
数据集1(rename=(原名1=新名1 ...))的意思是把数据集1中的变量改一下名字。当准备合并的2个数据集变量名不同时(如数据集1中的性别用gender,数据集2中的用sex表示),就需要用该选项把名字改为相同的。
data ab1;
set sasuser.a1 sasuser.b1(rename=(ht=height wt=weight));
proc print;
run;在SAS中如果两个变量类型不同的话,是无法合并的。需要用input函数或put函数把变量类型改为一致的。
SAS中的数据集一旦建立成功,就没有办法用命令进行修改了。如果想要对已有的数据集进行更改,只能用data语句新建一个数据集,在进行相应的操作。
data sasuser.b2;
set sasuser.b2;
time1=input(time,yymmdd10.);
format time1 yymmdd10.;
drop time;
rename time1=time;
run;data语句的作用是创建新的空白数据集,而不是打开数据集。如果新建重名的数据集,新数据集会覆盖原有的数据集。
data ab2;
set sasuser.a2(in=a) sasuser.b2(in=b);
a2=a;/*把临时变量a的值赋值给变量a2*/
b2=b/*结果中不会显示a和b这两个变量,但是可以调用a,b将他们赋值给另外的新变量,以便在结果中显示*/
proc print;
run;in=选定指定的临时变量,可以调用,但是不会在结果中显示,也就是说上述代码如果只有in=a,和in=b两个选项,结果中不会显示a和b这两个变量,但是可以调用a,b将他们赋值给另外的新变量,以便在结果中显示。
使用append过程
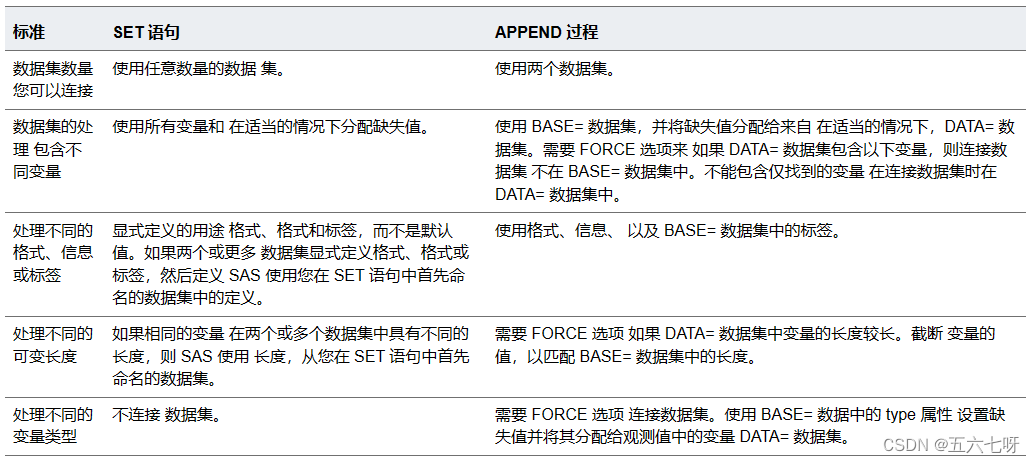
append数据集变量字段相同:将数据集 CUSTOMER_SUPPORT 追加到数据集 SALES。双数据集包含相同的变量,并且每个变量具有相同的属性。生成的数据集通过将 SALES 命名为 SALES and CUSTOMER_SUPPORT SET 语句中。
proc append base=sales data=customer_support;
run;
proc print data=sales;
title 'Employees in Sales and Customer Support Departments';
run;append数据集变量字段不相同:必须使用 FORCE 选项,当 DATA= 数据集包含变量时,带有 PROC APPEND 不在 BASE= 数据集中。如果修改程序以包括 FORCE 选项,然后它成功连接文件。
data sales;
input EmployeeID $ 1-9 Name $ 11-29 @30 HireDate date9.
Salary HomePhone $;
format HireDate date9.;
datalines;
429685482 Martin, Virginia 09aug2002 45000 493-0824
244967839 Singleton, MaryAnn 24apr2004 34000 929-2623
996740216 Leighton, Maurice 16dec2001 57000 933-6908
675443925 Freuler, Carl 15feb2010 54500 493-3993
845729308 Cage, Merce 19oct2009 64000 286-0519
;
run;
data security;
input EmployeeID $ 1-9 Name $ 11-29 Gender $ 30
@32 HireDate date9. Salary;
format HireDate date9.;
datalines;
744289612 Saparilas, Theresa F 09may2005 45000
824904032 Brosnihan, Dylan M 04jan2009 49000
242779184 Chao, Daeyong M 28sep2004 48500
544382887 Slifkin, Leah F 24jul2011 54000
933476520 Perry, Marguerite F 19apr2010 49500
;
run;
proc append base=sales data=security force;
run;
proc print data=sales;
title 'Employees in the Sales and the Security Departments';
run;append数据集变量具有不同属性时:
- 如果变量具有不同 BASE= 数据集中的属性 与 DATA= 数据集中的属性相比, 则以 BASE= 数据集中的属性为准。在以下情况下 不同的格式、信息和标签,串联成功。
- 如果变量的长度 在 BASE= 数据集中比在 DATA= 数据集中长,则 串联成功。
- 如果变量的长度 在 DATA= 数据集中比在 BASE= 数据集中长,或者如果 同一个变量是一个数据集中的字符变量和一个数字 变量,则 PROC APPEND 无法连接文件 除非指定 FORCE 选项。
使用 FORCE 选项 具有以下后果:
- 指定的长度 在 BASE= 数据集中占上风。因此,SAS 会截断 DATA= 数据集,以将它们适合到 BASE= 数据集。
- 指定的类型 在 BASE= 数据集中占上风。该过程将替换 错误的类型(DATA= 数据集中变量的所有值)替换为 缺失值。
3.1.1交错(连接)
语法
set SAS数据集1 SAS数据集2 ....;
BY 变量列表;SET 语句内容如下 多个排序的 SAS 数据集,并创建一个排序的 SAS 数据集。SAS-data-sets 是 要交错的 SAS 数据集的列表。
BY 语句是 与 SET 语句一起使用以执行 BY 组处理。变量列表包含 一个或多个变量(BY 变量)的名称,用于交错 数据集。所有数据集必须按相同的变量进行排序 在可以交错它们之前。
data research_development;
length Department Manager $ 10;
input Project $ Department $ Manager $ StaffCount;
datalines;
MP971 Designing Daugherty 10
MP971 Coding Newton 8
MP971 Testing Miller 7
SL827 Designing Ramirez 8
SL827 Coding Cho 10
SL827 Testing Baker 7
WP057 Designing Hascal 11
WP057 Coding Constant 13
WP057 Testing Slivko 10
;
run;
proc print data=research_development;
title 'Research and Development Project Staffing';
run;
data publications;
length Department Manager $ 10;
input Manager $ Department $ Project $ StaffCount;
datalines;
Cook Writing WP057 5
Deakins Writing SL827 7
Franscombe Editing MP971 4
Henry Editing WP057 3
King Production SL827 5
Krysonski Production WP057 3
Lassiter Graphics SL827 3
Miedema Editing SL827 5
Morard Writing MP971 6
Posey Production MP971 4
Spackle Graphics WP057 2
;
run;
proc sort data=publications;
by Project;
run;
proc print data=publications;
title 'Publications Project Staffing';
run;
data rnd_pubs;
set research_development publications;
by Project;
run;
proc print data=rnd_pubs;
title 'Project Participation by Research and Development';
title2 'and Publications Departments';
title3 'Sorted by Project';
run;交错时 数据集,SAS 将创建一个新数据集,如下所示:
- 在执行 SET 语句,SAS 读取每个数据集的描述符部分 您在 SET 语句中命名。然后,SAS 创建一个程序数据向量 默认情况下,它包含所有数据集中的所有变量 以及 DATA 步骤创建的任何变量。SAS 设置值 的每个变量都缺失。
- SAS着眼于第一个 BY 组,以便在 SET 语句中对每个数据集进行分组,以确定 哪个 BY 组应首先出现在新数据集中。
- SAS 复制到新的 数据集 该 BY 组中的所有观测值来自每个数据集 包含 BY 组中的观测值。SAS 从数据集复制 其显示顺序与它们在 SET 语句中的显示顺序相同。
- SAS着眼于下一个 BY 组,以确定应显示哪个 BY 组 接下来是新数据集中的下一个。
- SAS 将 程序中的每个变量都缺少数据向量。
- SAS 重复步骤 3 到 5,直到它将所有观测值复制到新数据集。
3.1.2利用merge语句进行横向合并
data 数据集;
merge 数据集1 数据集2 ...;
by 变量1 变量2 ...;
run;merge的作用是将若干个数据集依次向右连接,并且存放到一个新数据集中。
by语句相当于指定索引,按索引变量(如id号)匹配,以保证多个数据集即使在观测排序不一致的情况下也能正确连接。(取数据集的并集) (类似于数据库的join的on)
如果要求数据集的交集,可以 添加上if 数据集临时数据1 and 数据集临时数据2=1 ...;
注:在利用by语句横向合并时,如果两个数据集实现没有按id排序,一定要先分别对它们都排序才能合并。
一对一合并
语法
data 数据集1;
merge class 数据集2;
run;没有 BY 语句的 MERGE 语句,SAS 将第一个观测值合并 在 MERGE 语句中命名的所有数据集中,到第一个观测值中 在新数据集中,将所有数据集中的第二个观测值放入 新数据集中的第二个观测值,依此类推。在一对一中 合并时,新数据集中的观测值数等于 您命名的最大数据集中的观测值数 MERGE 语句。
匹配合并
加by语句
BY变量:指定变量 在 BY 语句中命名。
BY 值:指定值 的 BY 变量。
BY组:指定所有观测值的 BY 变量值相同(如果有 只有一个 BY 变量)。如果在 BY 中使用多个变量 语句,则 BY 组是具有唯一值的观测值集 这些变量的值组合。在讨论匹配合并时, BY 组通常跨越多个数据集。
3.1.3更新SAS数据集(UPDATE)
语法
UPDATE master-SAS-data-set transaction-SAS-set;
BY identifier-list;master-SAS-data-set:指定 SAS 数据 包含要更新的信息的set。
transaction-SAS-set:指定 SAS 数据 包含用于更新主数据集的信息的 set。
identifier-list:指定 用于标识相应观测值的 BY变量。
如果主数据集包含与事务数据集观测值不对应的观测值 ,则 DATA 步骤写入该观测结果到新数据集,无需修改。观测结果与 主数据集成为新观测的基础。新的观测结果可以通过事务数据集中的其他观察结果进行修改,然后再写入新数据集。
3.1.4修改SAS数据集(MODIFY)
- 替换数据集
- 替换包含事务数据集中的值的主数据集
- 追加观测值到现有SAS数据集
- 从现有 SAS 数据集删除观测值
语法
DATA SAS-data-set;
MODIFY SAS-data-set; /*数据集名字要一样*/
existing-variable = expression;
/*run前一步的默认操作不是output是replace*/
RUN;当您使用 带有 Modify 的 BY 语句,主数据和事务数据 集合可以包含具有重复 BY 变量值的观测值。 主数据集和交易数据集都不需要排序, 因为 BY 组处理使用动态 WHERE 处理来查找 主数据集中的观测值。
DATA 步骤流程 通过以下方式重复观测值:
- 如果重复的 BY 值存在于主数据集中,则 MODIFY 应用当前事务数据集到主数据集中的第一个匹配项。
- 如果重复的 BY 值存在于事务数据集中,然后应用观察结果一个在另一个之上,以便值相互覆盖。这最后一个事务中的值是主数据中的最终值 设置。
- 如果 master 和 事务数据集包含重复的 BY 值,然后 MODIFY 将每个事务应用于组中的第一个匹配项 主数据集。
处理缺失值
修改 master-SAS-data-set transaction-SAS-data-set
<UPDATEMODE=MISSINGCHECK |NOMISSINGCHECK>;
BY by-变量;MISSINGCHECK 可防止事务数据集中的缺失值替换主数据集。这是默认设置。
NOMISSINGCHECK 启用缺失事务数据集中的值替换主数据中的值通过阻止执行缺失数据检查来设置。
例子
data inventory_tool;
input PartNumber $ Description $ InStock @17
ReceivedDate date9. @27 Price;
format ReceivedDate date9.;
datalines;
K89R seal 34 27jul2010 245.00
M4J7 sander 98 20jun2011 45.88
LK43 filter 121 19may2011 10.99
MN21 brace 43 10aug2012 27.87
BC85 clamp 80 16aug2012 9.55
NCF3 valve 198 20mar2012 24.50
KJ66 cutter 6 18jun2010 19.77
UYN7 rod 211 09sep2010 11.55
JD03 switch 383 09jan2013 13.99
BV1E timer 26 03aug2013 34.50
;
run;
data add_inventory;
input PartNumber $ Description $ NewStock @16 NewPrice;
datalines;
K89R seal 6 247.50
AA11 hammer 55 32.26
BB22 wrench 21 17.35
KJ66 cutter 10 24.50
CC33 socket 7 22.19
BV1E timer 30 36.50
;
run;
data inventory_tool;
modify inventory_tool add_inventory;
by PartNumber;
/*_iorc_自动变量:用于在 DATA 步骤程序中进行错误检查。*/
select (_iorc_);
/* 观测存在于主数据集 */
when (%sysrc(_sok)) do;
InStock=InStock+NewStock;
ReceivedDate=today();
Price=NewPrice;
replace;
end;
/* 观测不存在于主数据集 */
when (%sysrc(_dsenmr)) do;
InStock=NewStock;
ReceivedDate=today();
Price=NewPrice;
output;
_error_=0;
end;
otherwise do;
put 'An unexpected I/O error has occurred.'/
'Check you data and your program.';
_error_=0;
stop;
end;
end;
run;
proc print data=inventory_tool;
title 'Tool Warehouse Inventory';
run;检查程序错误
_IORC_用自动变量:用于在 DATA 步骤程序中进行错误检查。(一个名为_iorc_的自动变量被系统创建。 _IORC_自动变量包含系统每次运行modify语句时返回的I/O操作码。 以匹配访问为例,如果更新数据集BY变量值在主数据集中不存在,自动变量_IORC_返回一个非零值。)
助记符:
_DSENMR:指定主数据集中不存在事务数据集观测(仅与 MODIFY 和 BY 语句一起使用)。如果具有不同 BY 值的连续观测在主数据集中未找到匹配项,则它们都返回 _DSENMR。。
_DSEMTR:指定主数据集中不存在具有给定 BY 值的多个事务数据集观测(仅与 MODIFY 和 BY 语句一起使用)。如果具有相同 BY 值的连续观测值在主数据集中未找到匹配项,则第一个观测值返回 _DSENMR,后续观测值返回 _DSEMTR。
_DSENOM:指定未找到匹配的观察结果。
_SOK:指定的观测位于主数据集位置中,并表明 MODIFY 语句 已成功执行。
DATA 过程步骤处理重复观测值方式:
- 如果主数据集中存在重复的 BY 值,则 MODIFY 将当前事务第一次出现应用于主数据集中的。
- 如果交易数据集中存在重复的 BY 值,则观测结果将一个一个地应用到另一个之上,以便这些值相互覆盖。最后事务中的值是主数据集中的最终值。
- 如果主数据集和事务数据集都包含重复的 BY 值,则 MODIFY 将每个事务应用于在主数据集中第一个出现的。
3.2数据对比
proc compare <base=数据集 compare=数据集> <nosummary> <transpose>;
by变量1 变量2 ...;
id变量1 变量2 ...;
run;nosummary的作用是不显示一些概括性的结果;
transpose的作用是按记录显示不一致的结果,如果不指定该选项,默认的是按变量显示不一致的结果。
by语句和merge合并中的by语句作用相同,指定索引变量。如果两个数据集的记录不同,通过by语句可以避免错位比较的情况。
id语句通常指定索引变量,如id号,id可以让你很方便的根据该变量找到相应的观测。如果不指定默认结果只显示第几行。
3.3数据清洗--查找和删除重复值
3.3.1查找和删除重复值
proc sort <data=数据集> <out=数据集> <nouniquekey> <nodupkey>;
by <descending> 变量1 <descending> 变量2 ...;
run;proc sort语句调用排序过程。
选项data=数据集指定对哪个数据集进行排序。
选项out=数据集的意思是把排序后的数据输出到指定数据集中,此时原数据仍然保留。如果不加该选项,排序后的数据集将覆盖原有的数据集。
nouniquekey选项的作用是输出重复值。
nodupkey选项作用是删除重复值,也就是输出唯一值。
by语句是指定排序的变量,可以指定多个。
选项descending表示按降序排序,如果不加该选项,默认升序。
proc sort data=ab1;
by id;
proc sort data=ab2;
by id;
run;
data ab;
merge ab1 ab2;
by id;
proc print;
run;重复值需要自己指定 在by语句中,指定几个就代表几个都重复了这条数据就算重复。
proc sort data=sasuser.xb nodupkey out=norep;/*输出唯一值并把值保存到数据集norep中*/
by name gender;
proc print data=norep;
run;3.3.2扩展内容:first.变量和last.变量
sor过程自动产生的两个变量:first.变量和last.变量;这两个变量分别表示某变量某个值的第一个和最后一个观测。
data patients;
input id gender age time yymmdd10. sbp;
format time yymmdd10.;
cards;
1 1 51 2010/01/12 150
1 1 51 2010/02/12 147
1 1 51 2010/03/14 142
2 2 59 2010/01/09 163
2 2 59 2010/02/10 162
2 2 59 2010/03/17 160
2 2 59 2010/04/16 151
;
proc sort;
by id time;
run;
data patients;
set patients;
by id;
retain firstsbp;
if first.id then firstsbp=sbp;/*对每一个人的第一次观测,将sbp值赋给firstsbp*/
difsbp=sbp-firstsbp;
proc print;
run;first.XX不是指第一个XX值,而是XX为某个值时,它对应的多个观测中的第一个观测;同样last.XX不是指最后一个XX值,而是XX为某个值时,它对应的多个观测中的最后一个观测。
3.4数据清洗--查找缺失值
3.4.1补充内容:数组
对多个变量执行完全相同的操作,可以考虑用数组批量执行这些操作,提高效率。
array 数组名[下标] <$> <数组元素> <(元素初始值)>;
array:是定义数组的标志;
数组名:取名规则与SAS数据集命名规则一致;
下标:是指定数组中包含元素的个数,这里的元素一般就是变量;(下标从一开始)
数组元素:主要是列出数组中包含的1个或多个变量,这些变量可以是数据集中已有的变量,也可以是新变量。如果是字符型变量需要在前面加上$;
元素初始值:指定新变量的值,不指定默认新变量的值为缺失值。
注意事项:
数组名不能与数据集中已有变量重名,也不要与已有函数同名。
一个数组中下标的写法既可以用[],也可以用{}或()。
数据的下标也可以是个范围,如array x[11:15] y11 y12 y13 y14 y15;。
数组的下标可以不写,用"*"代替。如array x[*] a b c;,SAS会自动根据变量个数来判断下标值为3.
数组中的数组元素可以不写,如array y[3];等同于array y[3] y1 y2 y3;。
元素初始值一定要用()括起来,各个值之间可以用逗号或空格隔开。
data missing;
set sasuser.xb;
array cha[1] name;
if missing(cha[1]) then output;
array num[10] gender age height weight time y1-y5;
do i=1 to 10;
if missing(num[i]) then output;
end;
proc print;
run;3.4.2自动变量
_numeric_表示数据集中的所有数值型变量。
_character_表示数据集中的所有字符型变量。
_all_表示数据集中的所有变量。
3.4.3查找缺失值的万能程序
data missing;
set sasuser.feeder;
array cha[*] _character_;/*利用*号不指定cha数组中的字符型变量个数*/
do i=1 to dim(cha);/*指定循环次数为数组char中的元素数*/
if missing(cha[i]) then output;
end;
array num[*] _numeric_;
do i=1 to dim(num);
if missing(num[i]) then output;
end;
proc print;
run;3.5数据清洗-查找异常值
data 新数据集;/*建立新数据集*/
set 已有数据集;/*利用set语句将已有数据集复制进来*/
if|where 条件语句;/*根据if或where语句把异常值过滤掉,仅复制符合条件的记录*/
proc print;
run;3.5.1if和where的区别
1if和where都可以使用的场景
在利用set语句有条件的复制数据集时,set后紧跟条件语句,此时if和where都可以。例:
data outliney5;
set sasuser.xb;
if (y5 not in(1,2,3,4,5,.));
proc print;
run;
data outliney5;
set sasuser.xb;
if (y5 not in(1,2,3,4,5,.));
proc print;
run;2.只能用if的部分场合
1)使用SAS自动变量时,只能用if,不能用where。
2)如果指定的条件变量是新产生的变量,只能用if,不能用where。
3、只能用where的部分场合
1)当使用某些特殊运算符时。
2)当做数据集选项使用时。
3.5.2 查找异常值万能程序
%let data=sasuser.xb;
%let id=id;
%macro outline(var=,low=,high=);
data outline;
set &data.(keep=&id. &var.);
length variable $20. reason $20.;
variable="&var.";
value=&var.;
if &var.<&low. and not missing(&var.) then do;
reason="过低";
output;
end;
else if &var.>&high. and not missing(&var.) then do;
reason="过高";
output;
end;
drop &var.;
proc append base=outliner1 data=outline;
run;
%mend outline;
%outline(var=height,low=150,high=200);
%outline(var=weight,low=150,high=200);
%outline(var=y1,low=1,high=5);
%outline(var=y2,low=1,high=5);
%outline(var=y3,low=1,high=5);
%outline(var=height,low=1,high=5);
proc print data=outliner1;
run;
3.6缺失值填补
3.6.1 缺失数据的填补
proc mi过程实现缺失值填补
mi是mutiple imputation(多重填补)的缩写。
proc mi <out=数据集> <round=> <minimun=> <maxmum=>;
mcmc;
var 变量1 变量2 ......;
run;round=选项的作用是指定填补值的小数位数。(例:变量y的值只能是整数,就可以设定round=1)
mcmc语句采用马尔科夫链蒙特卡罗(Markov chain Monte Carlo, MCMC)模拟方法来产生的一个抽样分布,作为缺失值的填补技术。
var语句指定哪些变量需要填补。
3.6.2 缺失数据的更新
data 新数据集;
update 旧数据集 新数据集;
by 索引变量;
run;3.6.3 常见语句及数据集选项(翻书吧...)
常见的SAS内嵌过程步:
- PROC SORT:对数据集进行排序。
- PROC FREQ:生成频数统计表。
proc freq data = example1 参数1;
tables 变量 / 参数2;
可选1:weight count;
run;- PROC MEANS:生成变量的描述性统计信息。
- PROC TABULATE:生成交叉分类表。
-
维度 table 语句可以在报告中指定三个维度:页、行、列。如果只指定一个维度,则默认 是列维度;如果指定两个,则是行和列。 缺失数据 默认下不考虑缺失数据,在 proc 语句后面增加 missing 选项可以改变这种默认: PROC TABULATE MISSING;proc tabulate; class 变量名1 变量名2 ....; table 页变量1 页变量2 ... , 行变量1 行变量2 ..., 列变量1 列变量2 ...; /*变量之间加*代表,使用星号(*)可以将两个或多个变量组合成一个交叉变量。这个交叉变量将会在表格中作为一个整体来处理。星号的作用相当于在SQL中使用的join操作。*/ run;
-
- PROC TRANSPOSE:将数据从长格式转换为宽格式,或者从宽格式转换为长格式。
- PROC SUMMARY:生成变量的汇总统计信息。
- PROC PRINT:打印数据集的内容。
- PROC REPORT:生成自定义格式的报告。
-
PROC REPORT NOWINDOWS; /*类似于proc print 的 var 语句,告诉SAS哪些变量该包括并以何种顺序,如果遗 漏语句 column,SAS默认在数据集中包括所有变量*/ COLUMN variable-list;
-
- PROC SQL:进行结构化查询语言(SQL)操作。
- PROC GLM:进行一般线性模型分析。
- PROC LOGISTIC:进行逻辑回归分析。
- PROC REG:进行线性回归分析。
- PROC ANOVA:进行方差分析。
- PROC CORR:计算变量之间的相关系数。
- PROC UNIVARIATE:生成变量的单变量分析结果。
- PROC GENMOD:进行广义线性模型分析。
- PROC GAM:进行广义可加模型分析。
- PROC PHREG:进行生存分析。
- PROC MIXED:进行混合效应模型分析。
- PROC NLMIXED:进行非线性混合效应模型分析。
这些是一些常见的SAS内嵌过程步,用于数据处理、统计分析、报告生成等各种任务。SAS提供了丰富的过程步来满足不同的分析需求。
ODS(Output Delivery System)是一种输出管理系统,它用于控制和管理SAS程序生成的输出结果。通过使用其他ODS语句,可以将SAS程序的输出发送到其他设备或文件中,如HTML、PDF、Excel等。例如,可以使用ods html file='path_to_file.html';将SAS程序的输出发送到一个HTML文件中。这样,SAS程序的输出将会保存在指定的HTML文件中,而不是显示在SAS程序的输出窗口中。
常用函数记录:
ifn(条件表达式,正确时输出的数值型赋值,错误时输出的数值型赋值,缺失时输出的数值型赋值)
ifc(条件表达式,正确时输出的字符型赋值,错误时输出的字符型赋值,缺失时输出的字符型赋值)















 690
690











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









