










1.概述
提升(boosting)是一个机器学习技术,可以用于分类以及回归问题,可以在每一步中产生一个弱预测模型,并且将每个弱预测模型通过加权累加到总模型中。如果每一步的弱预测模型生成都是依据损失函数的梯度方向,则称之为梯度提升(gradient boosting)。
而梯度提升算法则会首现给定一个目标损失函数,它的定义域是所有可行的弱函数集合(也被称为基函数),提升算法通过迭代地选择一个负梯度方向上的基函数来逐渐逼近局部最小值。
提升算法的理论意义在于:如果一个问题存在弱分类器,则可通过提升的方法来得到一个强分类器。
2.提升算法
2.1 推导
给定输入向量x和输出向量y组成的若干训练样本(x1,y1),(x2,y2),(x3,y3)…(xn,yn),目标是找到近似函数F(x),使得损失函数L(y,F(x))的值最小。
常用的损失函数:
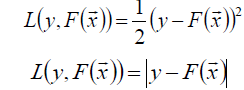
假定一个最优函数:
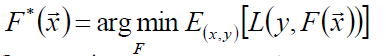
假设F(x)是一族基函数f(x)的加权和:
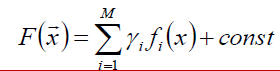
使用梯度提升算法寻找最优解F(x),使得损失函数在训练集上的期望最小。
首先,给定一个常函数F0(x):
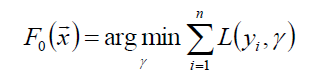
以贪心的思路拓展得到Fm(x):
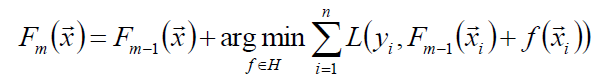 贪心法在每次选择最优基函数f时仍然苦难,因此使用梯度下降的方法近似计算,将样本带入基函数得到f(x1),f(x2)…f(xn),从而变为了:
贪心法在每次选择最优基函数f时仍然苦难,因此使用梯度下降的方法近似计算,将样本带入基函数得到f(x1),f(x2)…f(xn),从而变为了:
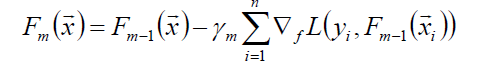 其中的γ为梯度下降的步长,可用线性搜索计算最优步长:
其中的γ为梯度下降的步长,可用线性搜索计算最优步长:
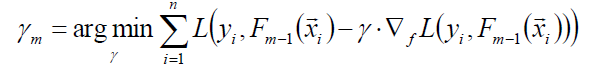 接下来更新模型:
接下来更新模型:
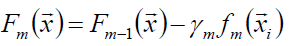
2.2 提升算法步骤

2.3 梯度提升决策树(GBDT)
梯度提升的典型基函数是决策树(CART)。
 其中bjm是样本x在区域Rjm的预测值。
其中bjm是样本x在区域Rjm的预测值。
使用线性搜索计算学习率,最小化损失函数:
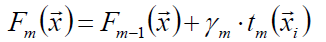
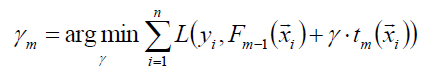 接下来进一步,对树的每个区域分别计算步长,从而系数bjm被合并到步长中,从而:
接下来进一步,对树的每个区域分别计算步长,从而系数bjm被合并到步长中,从而:
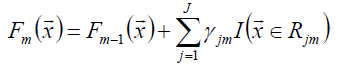
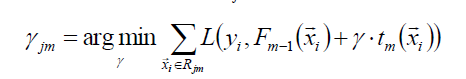 函数估计本来被认为是在函数空间而非参数空间的数值优化问题,而阶段性的加性扩展和梯度下降手段将函数估计转化为参数估计。
函数估计本来被认为是在函数空间而非参数空间的数值优化问题,而阶段性的加性扩展和梯度下降手段将函数估计转化为参数估计。
损失函数是最小平方误差、绝对值误差等,则为回归问题;而当误差函数换成多类别Logistic似然函数,则成为分类问题。
3.XGBoost
3.1 XGBoost概述
相对于传统的GBDT,XGBoost用到了二阶信息,从而在训练集上可以更快地收敛。XGBoost在一定程度上有着过拟合的特性;XGBoost的实现中用到了并行/多核计算,因此训练速度快。
3.2 XGBoost推导
目标函数:
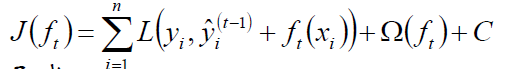 根绝Taylor展开:
根绝Taylor展开:
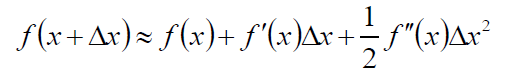 可以令:
可以令:
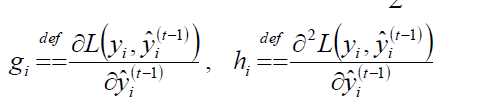 可得:
可得:
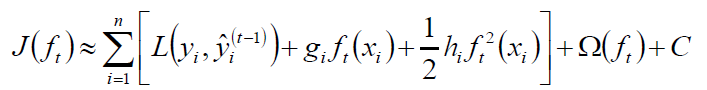 目标函数的计算:
目标函数的计算:
 继续化简可得:
继续化简可得:
 接下来枚举可行的分割点,选择增益最大的划分,继续同样的操作,直到满足某阈值或者得到纯结点。
接下来枚举可行的分割点,选择增益最大的划分,继续同样的操作,直到满足某阈值或者得到纯结点。
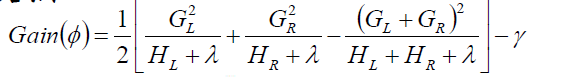
4.AdaBoost
4.1 概述
AdaBoost算法是模型为加法模型、损失函数为指数函数、学习算法为前向分步算法时的二类学习方法。
AdaBoost的训练误差是以指数速率下降的。
AdaBoost算法不需要事先知道下界γ,具有自适应性,它能自适应弱分类器的训练误差率。
4.2 AdaBoost步骤
得到训练集:
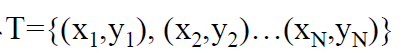
初始化权值分布:
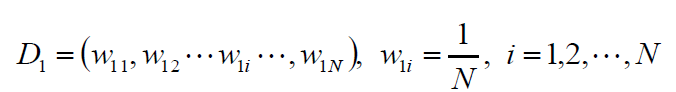 使用具有权值分布Dm的训练数据集学习,得到基本分类器:
使用具有权值分布Dm的训练数据集学习,得到基本分类器:
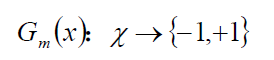
计算Gm(x)在训练数据集上的分类错误率:
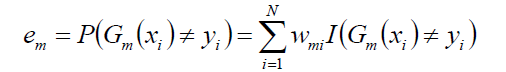 然后计算Gm(x)的系数:
然后计算Gm(x)的系数:
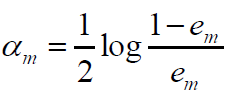
接下来更新数据集的权值分布:
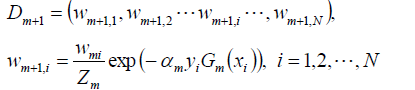
其中的Zm是规范化因子(作用是使Dm+1成为一个概率分布):
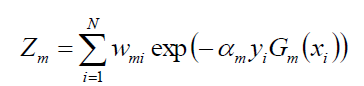
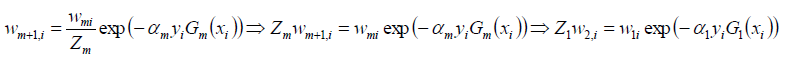 接下来构建基本分类器的线性组合:
接下来构建基本分类器的线性组合:
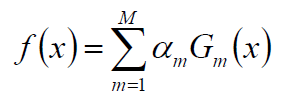
得到最终的分类器:
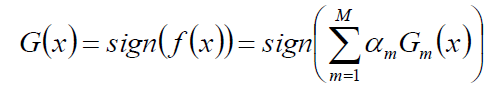
5.代码
import xgboost as xgb
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
import csv
def show_accuracy(a, b, tip):
acc = a.ravel() == b.ravel()
acc_rate = 100 * float(acc.sum()) / a.size
return acc_rate
def load_data(file_name, is_train):
data = pd.read_csv(file_name) # 数据文件路径
# 性别
data['Sex'] = data['Sex'].map({'female': 0, 'male': 1}).astype(int)
# 补齐船票价格缺失值
if len(data.Fare[data.Fare.isnull()]) > 0:
fare = np.zeros(3)
for f in range(0, 3):
fare[f] = data[data.Pclass == f + 1]['Fare'].dropna().median()
for f in range(0, 3):
data.loc[(data.Fare.isnull()) & (data.Pclass == f + 1), 'Fare'] = fare[f]
if is_train:
# 年龄:使用随机森林预测年龄缺失值
print ('随机森林预测缺失年龄:--start--')
data_for_age = data[['Age', 'Survived', 'Fare', 'Parch', 'SibSp', 'Pclass']]
age_exist = data_for_age.loc[(data.Age.notnull())] # 年龄不缺失的数据
age_null = data_for_age.loc[(data.Age.isnull())]
print (age_exist)
x = age_exist.values[:, 1:]
y = age_exist.values[:, 0]
rfr = RandomForestRegressor(n_estimators=1000)
rfr.fit(x, y)
age_hat = rfr.predict(age_null.values[:, 1:])
# print age_hat
data.loc[(data.Age.isnull()), 'Age'] = age_hat
print ('随机森林预测缺失年龄:--over--')
else:
print ('随机森林预测缺失年龄2:--start--')
data_for_age = data[['Age', 'Fare', 'Parch', 'SibSp', 'Pclass']]
age_exist = data_for_age.loc[(data.Age.notnull())] # 年龄不缺失的数据
age_null = data_for_age.loc[(data.Age.isnull())]
# print age_exist
x = age_exist.values[:, 1:]
y = age_exist.values[:, 0]
rfr = RandomForestRegressor(n_estimators=1000)
rfr.fit(x, y)
age_hat = rfr.predict(age_null.values[:, 1:])
# print (age_hat)
data.loc[(data.Age.isnull()), 'Age'] = age_hat
print ('随机森林预测缺失年龄2:--over--')
# 起始城市
data.loc[(data.Embarked.isnull()), 'Embarked'] = 'S' # 保留缺失出发城市
embarked_data = pd.get_dummies(data.Embarked)
embarked_data = embarked_data.rename(columns=lambda x: 'Embarked_' + str(x))
data = pd.concat([data, embarked_data], axis=1)
print (data.describe())
data.to_csv('New_Data.csv')
x = data[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked_C', 'Embarked_Q', 'Embarked_S']]
y = None
if 'Survived' in data:
y = data['Survived']
x = np.array(x)
y = np.array(y)
x = np.tile(x, (5, 1))
y = np.tile(y, (5, ))
if is_train:
return x, y
return x, data['PassengerId']
def write_result(c, c_type):
file_name = '12.Titanic.test.csv'
x, passenger_id = load_data(file_name, False)
if type == 3:
x = xgb.DMatrix(x)
y = c.predict(x)
y[y > 0.5] = 1
y[~(y > 0.5)] = 0
predictions_file = open("Prediction_%d.csv" % c_type, "wb")
open_file_object = csv.writer(predictions_file)
open_file_object.writerow(["PassengerId", "Survived"])
open_file_object.writerows(zip(passenger_id, y))
predictions_file.close()
if __name__ == "__main__":
x, y = load_data('12.Titanic.train.csv', True)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.5, random_state=1)
lr = LogisticRegression(penalty='l2',max_iter=3000)
lr.fit(x_train, y_train)
y_hat = lr.predict(x_test)
lr_rate = show_accuracy(y_hat, y_test, 'Logistic回归 ')
# write_result(lr, 1)
rfc = RandomForestClassifier(n_estimators=100)
rfc.fit(x_train, y_train)
y_hat = rfc.predict(x_test)
rfc_rate = show_accuracy(y_hat, y_test, '随机森林 ')
# write_result(rfc, 2)
# XGBoost
data_train = xgb.DMatrix(x_train, label=y_train)
data_test = xgb.DMatrix(x_test, label=y_test)
watch_list = [(data_test, 'eval'), (data_train, 'train')]
param = {'max_depth': 3, 'eta': 0.1, 'silent': 1, 'objective': 'binary:logistic'}
# 'subsample': 1, 'alpha': 0, 'lambda': 0, 'min_child_weight': 1}
bst = xgb.train(param, data_train, num_boost_round=100, evals=watch_list)
y_hat = bst.predict(data_test)
# write_result(bst, 3)
y_hat[y_hat > 0.5] = 1
y_hat[~(y_hat > 0.5)] = 0
xgb_rate = show_accuracy(y_hat, y_test, 'XGBoost ')
print ('Logistic回归:%.3f%%' % lr_rate)
print ('随机森林:%.3f%%' % rfc_rate)
print ('XGBoost:%.3f%%' % xgb_rate)















 1331
1331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









