






似然和概率
在统计学中,似然函数(likelihood function,通常简写为likelihood,似然)是一个非常重要的内容,在非正式场合似然和概率(Probability)几乎是一对同义词,但是在统计学中似然和概率却是两个不同的概念。
- 概率是在特定环境下某件事情发生的可能性,也就是结果没有产生之前依据环境所对应的参数来预测某件事情发生的可能性。 比如抛硬币,抛之前我们不知道最后是哪一面朝上,但是根据硬币的性质我们可以推测任何一面朝上的可能性均为50%,这个概率只有在抛硬币之前才是有意义的,抛完硬币后的结果便是确定的。
- 而似然刚好相反,是在确定的结果下去推测产生这个结果的可能环境(参数)。 还是抛硬币的例子,假设我们随机抛掷一枚硬币1,000次,结果500次人头朝上,500次数字朝上(实际情况一般不会这么理想,这里只是举个例子),我们很容易判断这是一枚标准的硬币,两面朝上的概率均为50%,这个过程就是我们运用出现的结果来判断这个事情本身的性质(参数),也就是似然。
通俗一点来说,似然是什么
给定一堆数据,假如我们知道它是从某一种分布中随机取出来的,可是我们并不知道这个分布具体的参数,即“模型已定,参数未知”。例如,我们知道这个分布是正态分布,但是不知道均值和方差;或者是二项分布,但是不知道均值。这时候的问题便是似然了。
#似然的数学表达
结果和参数相互对应的时候,似然和概率在数值上是相等的,如果用θ 表示环境对应的参数,表示结果,那么概率可以表示为:
P
(
X
∣
θ
)
P(X|\theta)
P(X∣θ)


似然和概率的区别
简单来讲,似然与概率分别是针对不同内容的估计和近似。概率(密度)表达给定θ \thetaθ下样本随机向量X = x 的可能性,而似然表达了给定样本X = x 下参数θ = θ 1 (相对于另外的参数取值为θ2)为真实值的可能性.
换言之, 似然函数的形式是L ( θ ∣ x ) ,其中"|"代表的是条件概率或者条件分布,因此似然函数是在"已知"样本随机变量X = x 的情况下,估计参数空间中的参数θ \thetaθ的值. 因此似然函数是关于参数θ \thetaθ的函数,即给定样本随机变量x后,估计能够使X的取值成为x 的参数θ 的可能性; 而概率密度函数的定义形式是f ( x ∣ θ ) , 即概率密度函数是在"已知θ的情况下,去估计样本随机变量x 出现的可能性.
注意上面有一句中需要理清几个概念:
估计能够使X的取值成为x的参数θ的可能性
- 统计学中, 样本随机变量的出现是基于某个分布的.例如f ( x ∣ θ ) f(x|\theta)f(x∣θ)代表x服从f ff分布,而f ff的分布是由参数θ \thetaθ决定的.
- 通常在概率统计学中X 代表的是随机变量,而小写形式x xx通常代表其具体取值. 假定X XX服从二项分布(也可以是任何其他分布), 则可以写成X ∼ B ( n , p ) X \sim B(n,p)X∼B(n,p), 而该二项分布情况下, 6次试验下x的取值可以是"010011".
- 而上面第一条中, 其实包含了一个前提假设,就是我们已知X XX服从二项分布, 这种假设的数学含义是什么呢? 对, 就是决定该分布的参数为θ \thetaθ, 即参数θ \thetaθ刻画了随机变量X \textbf{X}X在概率空间中服从什么分布. 更具体一点,假如X服从二项分布,那么其由θ决定的形式为f(x;n;k∣θ)=P(X=k)=(kn)pk (1−p)n−k. 其中p可以代表二项分布中"1"出现的概率,即θ的取值, 比如可以取值为"1/2". 而在似然估计中θ是怎么得到的呢? 还是以上面x的取值"010011"为例, 可以发现6次试验中,"1"出现了三次,那么这种情况下p取值为"1/2"是可能性最大的,即最接近θ的真实分布.
似然和概率的联系
似然函数可以看做是同一个函数形式下的不同视角.
以函数ab 为例. 该函数包含了两个变量,a和b. 如果b已知为2, 那么函数就是变量a的二次函数,即f(a)=a2 ;如果a已知为2,那么该函数就是变量b的幂函数, 即f(b) = 2b.
同理,θ和x也是两个不同的变量,如果x的分布是由已知的θ刻画的, 要求估计X的实际取值, 那么p ( x ∣ θ ) 就是x的概率密度函数; 如果已知随机变量x的取值, 而要估计使X取到已知x的参数分布,就是似然函数的目的.
有一个硬币,它有θ的概率会正面向上,有1 − θ的概率反面向上。θ是存在的,但是你不知道它是多少。
为了获得θ的值,你做了一个实验:将硬币抛10次,得到了一个正反序列:x = H H T T H T H H H H无论θ的值是多少,这个序列的概率值为θ⋅θ⋅(1−θ)⋅(1−θ)⋅θ⋅(1−θ)⋅θ⋅θ⋅θ⋅θ=θ7(1−θ)3 . 比如,如果θ值为0,则得到这个序列的概率值为0。如果θ值为1/2,概率值为1/1024。但是,我们应该得到一个更大的概率值,所以我们尝试了所有θ可取的值,画出了下图:
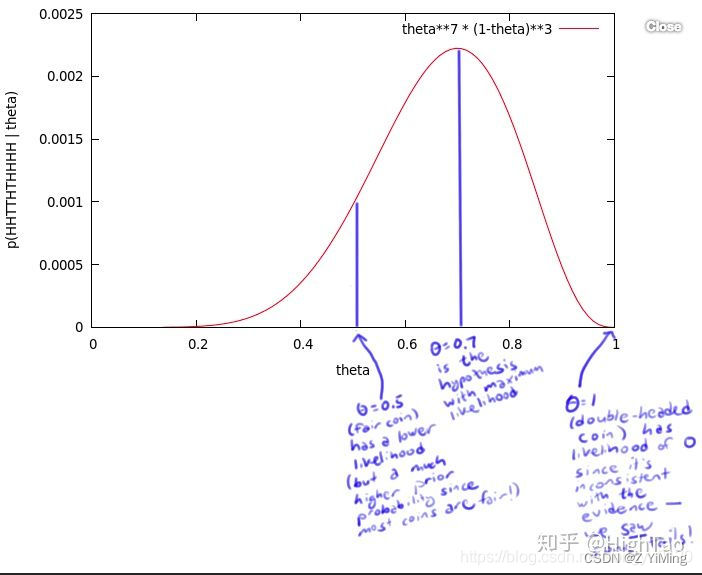
这个曲线就是θ的似然函数,通过了解在某一假设下,已知数据发生的可能性,来评价哪一个假设更接近θ的真实值。
如图所示,最有可能的假设是在θ=0.7的时候取到。但是,你无须得出最终的结论θ=0.7。事实上,根据贝叶斯法则,0.7是一个不太可能的取值(如果你知道几乎所有的硬币都是均质的,那么这个实验并没有提供足够的证据来说服你,它是均质的)。但是,0.7却是最大似然估计的取值。因为这里仅仅试验了一次,得到的样本太少,所以最终求出的最大似然值偏差较大,如果经过多次试验,扩充样本空间,
则最终求得的最大似然估计将接近真实值0.5。














 1271
1271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









