









为什么mysql的索引是最最左前缀?(基于innodb)
可以参考这个博客
创建数据表(为了演示)
DROP TABLE IF EXISTS `table`;
CREATE TABLE `table` (
`a` int(10) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键',
`b` int(11) NULL DEFAULT NULL COMMENT '字段b',
`c` int(11) NULL DEFAULT NULL COMMENT '字段c',
`d` int(11) NULL DEFAULT NULL COMMENT '字段d',
`e` int(11) NULL DEFAULT NULL COMMENT '字段e',
PRIMARY KEY (`a`) USING BTREE,
INDEX `index_1`(`b`, `c`, `d`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci ROW_FORMAT = Dynamic;
首先了解一下索引
- Hash索引:
Hash索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B+树索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,那为什么大家不都用Hash索引而还要使用B+树索引呢?
1. Hash索引仅仅能满足"=","IN"和"<=>"查询,不能使用范围查询。因为经过相应的Hash算法处理之后的Hash值的大小关系,并不能保证和Hash运算前完全一样;
2. Hash索引无法被用来避免数据的排序操作。因为Hash值的大小关系并不一定和Hash运算前的键值完全一样;
3. Hash索引不能利用部分索引键查询。对于组合索引,Hash索引在计算Hash值的时候是组合索引键合并后再一起计算Hash值,而不是单独计算Hash值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash索引也无法被利用;
4. Hash索引在任何时候都不能避免表扫描。由于不同索引键存在相同Hash值,所以即使取满足某个Hash键值的数据的记录条数,也无法从Hash索引中直接完成查询,还是要回表查询数据;
5. Hash索引遇到大量Hash值相等的情况后性能并不一定就会比B+树索引高。
- B-tree索引
大多数的MySQL引擎都支持B-Tree索引,它底层使用的是B+Tree这种数据结构来存储数据的。
最核心的特点如下:
(1)多路非二叉
(2)只有叶子节点保存数据
(3)搜索时相当于二分查找
(4)增加了相邻接点的指向指针。
- 下图是数据结构中的B+树
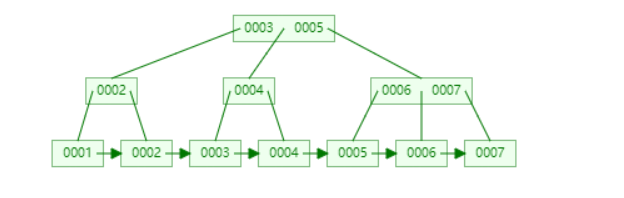
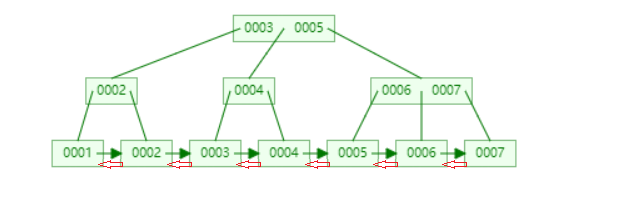
- 下图是mysql中的B+树(注意红色部分)

使用## 为什么mysql的索引是最最左前缀?(基于innodb)
创建数据表(为了演示)
DROP TABLE IF EXISTS `table`;CREATE TABLE `table` ( `a` int(10) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键', `b` int(11) NULL DEFAULT NULL COMMENT '字段b', `c` int(11) NULL DEFAULT NULL COMMENT '字段c', `d` int(11) NULL DEFAULT NULL COMMENT '字段d', `e` int(11) NULL DEFAULT NULL COMMENT '字段e', PRIMARY KEY (`a`) USING BTREE, INDEX `index_1`(`b`, `c`, `d`) USING BTREE) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci ROW_FORMAT = Dynamic;
首先了解一下索引
- Hash索引:
Hash索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B+树索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,那为什么大家不都用Hash索引而还要使用B+树索引呢?
1. Hash索引仅仅能满足"=","IN"和"<=>"查询,不能使用范围查询。因为经过相应的Hash算法处理之后的Hash值的大小关系,并不能保证和Hash运算前完全一样;
2. Hash索引无法被用来避免数据的排序操作。因为Hash值的大小关系并不一定和Hash运算前的键值完全一样;
3. Hash索引不能利用部分索引键查询。对于组合索引,Hash索引在计算Hash值的时候是组合索引键合并后再一起计算Hash值,而不是单独计算Hash值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash索引也无法被利用;
4. Hash索引在任何时候都不能避免表扫描。由于不同索引键存在相同Hash值,所以即使取满足某个Hash键值的数据的记录条数,也无法从Hash索引中直接完成查询,还是要回表查询数据;
5. Hash索引遇到大量Hash值相等的情况后性能并不一定就会比B+树索引高。
- B-tree索引
大多数的MySQL引擎都支持B-Tree索引,它底层使用的是B+Tree这种数据结构来存储数据的。最核心的特点如下:
(1)多路非二叉
(2)只有叶子节点保存数据
(3)搜索时相当于二分查找
(4)增加了相邻接点的指向指针。
- 下图是数据结构中的B+树- 下图是mysql中的B+树(注意红色部分)
上图是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
使用索引
- 使用主键索引
explain select * from `table` where a > 1;
| id | select_type | table | partition | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | table | range | PRIMARY | PRIMARY | 4 | 1 | 100.00 | Using where |
可以看出这样就可以使用id索引了,上面字段解释可以点击查看
- 使用自定义的索引(a,b,c)
explain select * from `table` where b>3 and c>3;

- 假如我们使用**explain select * from
tablewhere c>3 and d>3;**查询呢?
结果:

可以看出走的是全表扫描
那这到底是为什么呢?
这与索引的类型有关(B+树)
我们创建abc索引的时候,B+树会默认按照bcd的升序进行构造树

就像上面一样 c>3 and d>3这个条件,就等价于a=* and c>3 and d > 3,由于这条语句没有确定a的取值,所以按照B+树的寻找规则,并不能查找出数据,或者说这样查找所耗费的时间比较大,所以数据库不走索引。
不走索引的情况
- 全模糊查询跟左模糊查询
explain select * from `table` where e like '%3%';
explain select * from `table` where e like '%3';

- 右模糊可以走索引
explain select * from `table` where e like '3%';

- 只使用部分索引,但是最左的某一个缺失(假设我们有一个索引(b, c, d))
explain select * from `table` where c > 3;
explain select * from `table` where d > 3;
explain select a, b, c, d, e from `table` where d > 3;

- 走索引
explain select b, c from `table` where c > 3;
explain select b, c, d from `table` where c > 3;
explain select a, b, c, d from `table` where d = 3;
explain select a, b, c, d from `table` where d > 3;

注意这里
explain select a, b, c, d, e from table where d > 3;
跟
explain select a, b, c, d from table where d > 3;
少了一个e为什么又走索引了呢?
我们再回看一下数据库的B+树

我们看到B+树的叶子节点,因为索引有可能相同(唯一索引除外),比如
a b c d e
1 1 1 1 1
2 1 1 1 2
可以看出这里的缩影bcd是一样的,所以数据库中的叶子节点还需要一个唯一的标识,那就是主键了,所以上面我们查询的字段全部在索引里面,就不用遵循最左前缀原则了,一旦我们需要查询的字段不在索引树里面,就需要遵循最左匹配原则了














 1354
1354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









