







来源:
https://kongsh.blog.csdn.net/article/details/117900022
https://copyfuture.com/blogs-details/202205231447237893
《精通Python自动化编程》
目录
- 简介
- Windows安装和配置
- SETNX命令的使用
- SET实现
- 命令基本实现
- 数据结构
- Python操作Redis
简介
Redis是Key-Value存储系统,基于内存,亦可持久化的日志型Key-Value数据库,并提供多种语言的API。
特点
- 支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用;
- 支持多种数据类型,不仅仅是简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储;
- 支持数据的备份,即master-slave模式的数据备份。
Redis被称为数据结构服务器,它的数据结构有字符串、散列、列表、集合、有序集合、位图、流等类型。
优势
- 性能极高:读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型:支持二进制安全的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子性:Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
- 丰富的特性:Redis还支持 publish/subscribe, 通知,,key 过期等等特性。
应用
- 缓存(数据查询、短连接、新闻内容、商品内容等等)(使用最多的场景)
- 分布式集群架构中的session分离;
- 聊天室的在线好友列表;
- 任务队列;(秒杀、抢购、12306等等)
- 应用排行榜;
- 网站访问统计
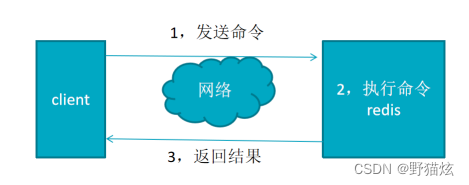
Redis基本通讯模型
执行过程:发送指令-〉执行命令-〉返回结果
执行命令:单线程执行,所有命令进入队列,按顺序执行
单线程快原因:纯内存访问, 单线程避免线程切换和竞争产生资源消耗,RESP协议简单
问题:如果某个命令执行慢,会造成其它命令的阻塞
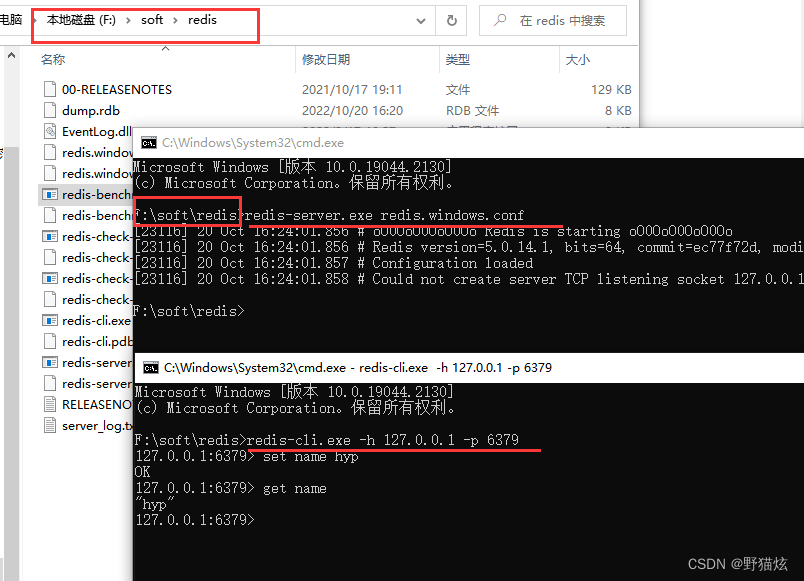
Windows安装和配置
https://github.com/tporadowski/redis/releases
可安装可视化工具RedisDesktopManager
redis-server.exe redis.windows.conf
redis-cli.exe -h 127.0.0.1 -p 6379
使用redis常用的两种加锁的机制:
- SETNX命令
- SET命令
SETNX命令的使用
SETNX 是『SET if Not eXists』(如果不存在,则 SET)的简写。
SETNX key value
将 key 的值设为 value ,当且仅当 key 不存在。
若给定的 key 已经存在,则 SETNX 不做任何动作。
SETNX test 'try'
get test
SETNX test 'tryAgain'
get test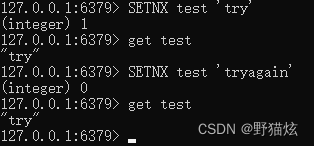
第一次给test赋值,返回表示成功;第二次再次尝试给test赋值,返回0,表示失败,并未再次操作,因为值已经存在。
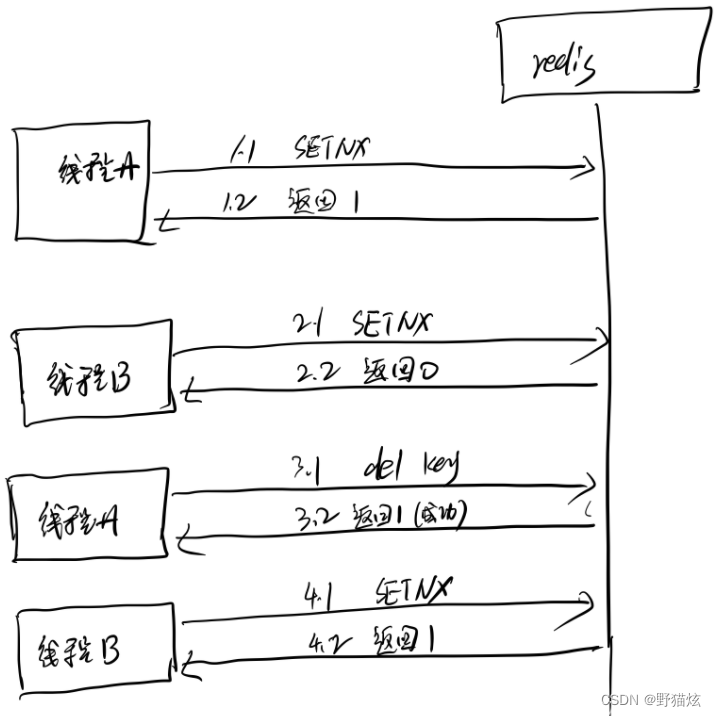
比如有两个线程A和B,两个线程操作相同的key.
SET实现
一般说分布式锁NX命令其实是表达set 的一种命令,如下:
SET key value [EX seconds] [PX milliseconds] [NX|XX]
生存时间(TTL,以秒为单位)
Redis 2.6.12 版本开始:(等同SETNX 、 SETEX 和 PSETEX)
EX second :设置键的过期时间为 second 秒。 SET key value EX second 效果等同于 SETEX key second value 。
PX millisecond :设置键的过期时间为 millisecond 毫秒。 SET key value PX millisecond 效果等同于 PSETEX key millisecond value 。
NX :只在键不存在时,才对键进行设置操作。 SET key value NX 效果等同于 SETNX key value 。
XX :只在键已经存在时,才对键进行设置操作。
set get 可以对已经存在的值重新赋值
127.0.0.1:6379> set test1 value
OK
(0.60s)
127.0.0.1:6379> get test1
"value"
127.0.0.1:6379> set test1 new-value
OK
127.0.0.1:6379> get test1
"new-value"
可以设置过期时间 ex ttl
127.0.0.1:6379> set test1-expire-time 'hello' ex 10000
OK
127.0.0.1:6379> get test1-expire-time
"hello"
127.0.0.1:6379> ttl test1-expire-time
(integer) 9987
127.0.0.1:6379> ttl test1-expire-time
(integer) 9981
127.0.0.1:6379> ttl test1-expire-time
(integer) 9976
NX 已经存在的值不能再次赋值
127.0.0.1:6379> set not-test1-key 'hello' NX
OK
127.0.0.1:6379> get not-test1-key
"hello"
127.0.0.1:6379> set not-test1-key 'hello1' NX
(nil)
127.0.0.1:6379> get not-test1-key
"hello"
XX:不存在的key不能赋值,只能修改已经存在的key的value
127.0.0.1:6379> EXISTS exists-key
(integer) 0
127.0.0.1:6379> set exists-key 'value' XX
(nil)
127.0.0.1:6379> set exists-key 'value'
OK
127.0.0.1:6379> set exists-key 'value-new' XX
OK
127.0.0.1:6379> get exists-key
"value-new"分布式锁
1)命令基本实现
命令 SET resource-name anystring NX EX max-lock-time 是一种在 Redis 中实现锁的简单方法
给lock设置了过期时间为60000毫秒(也可以用ex 6000,单位就变成了秒),当用NX再次赋值,则返回nil,不能重入操作
时间过期后再次get,返回nil,表明key 为 lock的锁已经释放
127.0.0.1:6379> set lock true NX px 60000
OK
127.0.0.1:6379> set lock true NX px 6000
(nil)
127.0.0.1:6379> get lock
"true"
127.0.0.1:6379> ttl lock
(integer) 44
127.0.0.1:6379> get lock
"true"如果setnx 返回ok 说明拿到了锁;如果setnx 返回 nil,说明拿锁失败,被其他线程占用。
换成客户端服务器则是如下:
客户端执行以上的命令:
如果服务器返回 OK ,那么这个客户端获得锁。
如果服务器返回 NIL ,那么客户端获取锁失败,可以在稍后再重试。
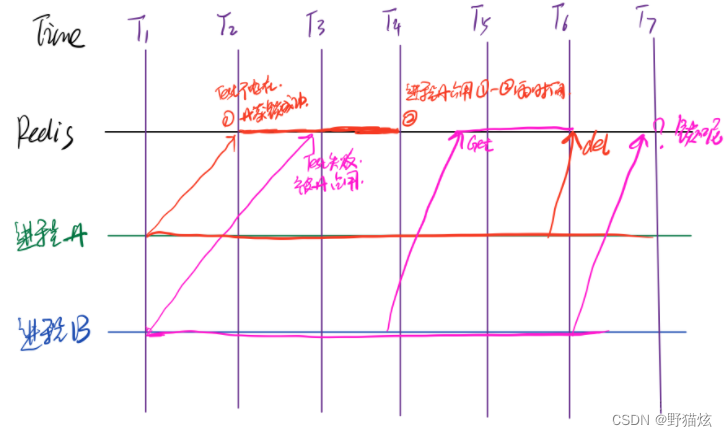
如果进程A又不讲道理,操作锁内资源超过笔者设置的超时时间,那么就会导致其他进程拿到锁,等进程A回来了,回手就是把其他进程的锁删了。可以加一层判定,当自己的进程结束或者过期,若value不是自己的值,则不进行删除操作流程。
数据结构
1.字符串(String)
字符串类型:实际上可以是字符串(包括XML JSON),还有数字(整型,浮点型),二进制(图片、音频、视频),最大不能超过512MB
设值命令:set
- 语法:set key value [expiration EX seconds|PX milliseconds] [NX|XX]
- 示例:
set age 23 ex 10 //10秒后过期 px 10000 毫秒过期
setnx name test //键name不存在时,返回1设置成功;存在的话失败0
set对已经存在的键再次设置时相当于修改操作
set age 33 xx //键存在时,返回OK表示成功,不存在返回nil
取值命令:get
- 语法:get key
如果key存在则返回value, 不存在返回nil
批量设值:mset
- 语法:mset key value [key value ...]
批量获取:
- 语法:mget key [key ...]
同时获取多个键值,没有的话返回nil
注意:若没有mget命令,则要执行n次get命令
计数:incr、decr、incrby、decrby、incrbyfloat
key必须为整数,否则会报错;key不存在的话会创建,而且从0开始自增/减1返回
操作非整数类型会报错
key不存在,会创建并且默认值为0
- 示例:
decr age //整数age减1
incrby age 10 //整数age+10
decrby age 2//整数age -2
incrbyfloat score 89.98 //浮点型score+89.98
追加:append
- 语法:append key value
- 示例:set content hello; append content world //追加后成helloworld
获取字符串长度:strlen
- 语法:strlen key
- 示例:
set hello 中国
strlen hello//结果6,每个中文占3个字节
截取字符串:getrange
- 语法:getrange key start end
start从0开始,最后一个用-1表示即可,获取的是闭区间,也就是[start, end]
2.哈希(Hash)
哈希hash是一个string类型的键值对映射表,用于存储对象,类似于python的字典
设值:hset
- 语法:hset key field value
成功返回键值对的个数
- 示例:hset user:1 name xiao age 18
取值:hget
- 语法:hget key field
- 示例:hget user:1 name
批量设值:hmset
- 语法:hmset key field value [field value ...] 成功返回OK
- 示例:hmset user:2 name kongsh age 23 addr beijing
批量取值:hmget
- 语法:hmget key field [field ...]
- 示例:hmget user:2 name age addr //返回三行
删值:hdel
- 语法:hdel key field [field ...]
执行成功返回删除的个数,执行失败返回0
- 示例:
hmset user:2 name kongsh age 23 addr beijing
hmget user:2 name age addr
hdel user:2 addr
计算个数:hlen
- 语法:hlen key
成功返回键值对的个数,失败返回0
- 示例:
hlen user:2 //返回2,user:1有两个属性值
hlen user:1
判断field是否存在:hexists
- 语法:hexists key field
若存在返回1,不存在返回0
- 示例
hexists user:2 addr
hexists user:2 name
获取所有field: hkeys
- 语法:hkeys key
key存在返回其所有的field,不存在返回空
- 示例:
hkeys user:2
hkeys user:1
获取所有的value:hvals
- 语法:hvals key
- 示例
hvals user:1
hvals user:2
获取所有的键值对:hgetall
- 语法:hgetall key
- 示例:hgetall user:2
整数加值操作:hincryby
- 语法:hincrby key field increment
- 示例:hincrby user:2 age 1
浮点数数加值操作:hincrybyfloat
- 语法:hincrbyfloat key field increment
- 示例:hincrbyfloat user:2 age 1.5
3.列表(list)
用来存储多个有序的字符串,一个列表最多可存2的32次方减1个元素,因为有序,可以通过索引下标获取元素或某个范围内元素列表,列表元素可以重复。
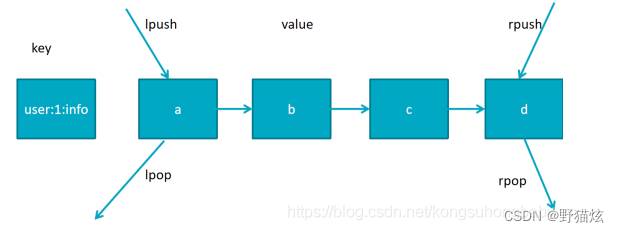
添加命令:lpush、rpush
从左侧添加或者从右侧添加,执行成功后返回列表中元素的总个数
- 语法:lpush key value [value ...]/rpush key value [value ...]
- 示例:
lpush list 1 2 3 //从右向左插入1 2 3, 返回值3
lrange list 0 -1 //从左到右获取列表所有元素
rpush list a b c //从左向右插入a b c, 返回值6
lrange list 0 -1 //从左到右获取列表所有元素
插入命令:linsert
- 语法:linsert key BEFORE|AFTER pivot value
- 示例:
linsert list before a 0 //在a之前插入0
linsert list after c d //在c之后插入d
查找命令:lrange
- 语法:lrange key start stop
索引下标特点:从左到右为0到N-1
返回指定位置元素:lindex
- 语法:lindex key index
- 示例:
lindex list -1
lindex list -3
lindex list 3
获取列表长度:llen
- 语法:llen key
返回指定列表的长度,列表不存在时,返回长度为0
删除列表中的元素:lpop、rpop
- 语法:lpop key、rpop key
- 示例:
lpop list //从左侧删除
rpop list //从右侧删除
4.集合(set)
用户标签,社交,查询有共同兴趣爱好的人,智能推荐。保存多元素,与列表不一样的是集合不允许有重复元素,且集合是无序。一个集合最多可存2的32次方减1个元素,除了支持增删改查,还支持集合交集、并集、差集;
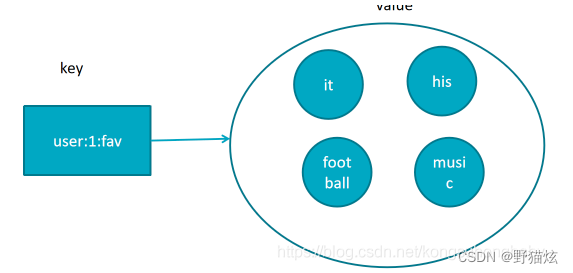
判断键值是否存在:exists
- 语法:exists key [key ...]
判断key代表的集合是否存在,不存在返回0,存在返回1
- 示例:
exists user //检查user键值是否存在,此时返回0
sadd user a b c //向user插入3个元素,返回3
exists user //检查user键值是否存在,此时返回1
添加元素:sadd
- 语法:sadd key member [member ...]
- 示例:
sadd user a b c //向user插入3个元素,返回3
sadd user a b //若再加入相同的元素,则重复无效,返回0
sadd user a b d //只插入d, 返回1
获取集合中所有元素:smembers
- 语法:smembers key
获取集合中所有的元素,返回结果无序
- 示例:
smembers user //获取user的所有元素,
删除集合中元素:srem
- 语法:srem key member [member ...]
执行成功后,返回删除的元素个数,失败返回0
- 示例:
srem user d //返回1,删除d元素
获取集合中元素个数:scard
- 语法:scard key
获取集合中元素的个数,集合不存在返回0
- 示例:
scard user //返回3
交集:sinter
- 语法:sinter key [key ...]
计算交集时,集合的前后顺序没有影响
- 示例:
sinter user user2
差集:sdiff
- 语法:sdiff key [key ...]
返回所有给定 key 与第一个 key 的差集,两个key交换顺序返回的结果有可能不一样
- 示例:
sdiff user user2 //获取user中存在而user2中不存在的元素,返回的是a
sdiff user2 user //获取user2中存在而user中不存在的元素,返回的是d
并集:sunion
- 语法:sunion key [key ...]
返回给定集合的并集
sunion user user2 user3 //获取3个集合的并集
5.有序集合(zset)
常用于排行榜,如视频网站需要对用户上传视频做排行榜,或点赞数,与集合类似,也不能有重复元素。
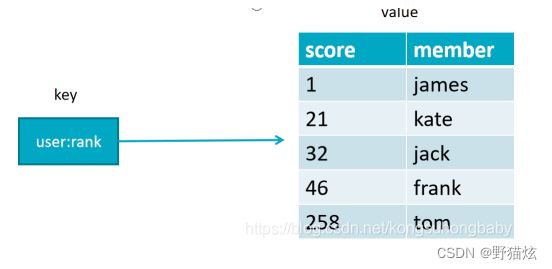
添加元素:zadd
- 语法:zadd key [NX|XX] [CH] [INCR] score member [score member ...]
执行成功,返回操作成功的条数,执行失败返回0
key:键
NX:只有key不存在的时候,zadd才会起作用(只添加不更新)
XX:只有key存在的时候,zadd才会起作用(只更新不添加)
member:有序集合中的成员(相当于集合中的元素)
score:分数
CH:返回zadd修改成员的个数,不写CH时修改member时默认返回0
INCR:当member不存在的时候没什么作用,当member存在时会将score加上member原来的分数
[score member]:一次设置多个score与member。
- 示例:
zadd usr:zan 1 xiao //xiao的点赞数1, 返回操作成功的条数1
zadd usr:zan 15 kongsh 2 lily 3 ksh //返回3
zadd test:1 nx 1 a //键test:1必须不存在,主要用于添加
zadd test:1 xx incr 100 a /键test:1必须存在,主用于修改,此时为101
zadd test:1 xx ch incr -10 a//返回操作结果91,101-10=91
获取元素:zrange
- 语法:zrange key start stop [WITHSCORES]
- 示例:
zrange test:1 0 -1 withscores //查看点赞(分数)与成员名
获取元素:zcard
- 语法:zcard key
- 示例:
zcard test:1 //计算成员个数, 返回3
获取指定元素索引:zrank
- 语法:zrank key member
返回有序集合中指定成员的索引,元素不存在返回nil
- 示例
zcard test:1
zcard test:1 a
zcard test:1 b
zcard test:1 dddddd
获取成员排名:zrevrank
- 语法:zrevrank key member
如果成员是有序集 key 的成员,返回成员的排名,名次从0开始。 如果成员不是有序集 key 的成员,返回 nil
- 示例
zrevrank test:1 0 -1 withscores
zrevrank test:1 c
zrevrank test:1 dddddd
获取成员分值:zscore
- 语法:zscore key member
返回有序集合中成员的分值
- 示例
zscore test:1 a
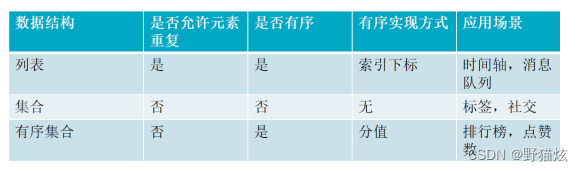
有序集合与集合及队列区别
6.Redis全局命令
查看所有键:keys *
键总数 :dbsize
如果存在大量键,线上禁止使用此指令
检查键是否存在:exists key
存在返回1,不存在返回0
删除键:del key
del hello school, 返回删除键个数,删除不存在键返回0
键过期:expire key seconds
set name test
expire name 10,表示10秒过期
查看剩余的过期时间:ttl key
键的数据结构类型:type key
返回键的类型,键不存在返回none
选择数据库:select
用于切换到指定的数据库,数据库索引号 index 用数字值指定,以 0 作为起始索引值。Redis默认建立了16个数据库,/usr/local/redis/etc/redis.conf:
客户端与Redis建立连接后会默认选择0号数据库,可以使用select命令进行切换。
清空当前数据库中的数据:flushdb
清空所有数据库中的数据:flushall
清空一个Redis实例中所有数据库中的数据
redis 127.0.0.1:6379> FLUSHALL
该命令可以清空实例下的所有数据库数据。关系型数据库多个库常用于存储不同应用程序的数据 ,且没有方式可以同时清空实例下的所有库数据。所以对于Redis来说这些db更像是一种命名空间,且不适宜存储不同应用程序的数据。比如可以使用0号数据库存储某个应用生产环境中的数据,使用1号数据库存储测试环境中的数据,但不适宜使用0号数据库存储A应用的数据而使用1号数据库B应用的数据,不同的应用应该使用不同的Redis实例存储数据。
由于Redis不支持自定义数据库的名字,所以每个数据库都以编号命名。Redis也不支持为每个数据库设置不同的访问密码,所以一个客户端要么可以访问全部数据库,要么全部数据库都没有权限访问。
以上是基于单体Redis的情况。而在集群的情况下不支持使用select命令来切换db,因为Redis集群模式下只有一个db0
Python操作Redis
Redis服务器设有多个db,它可视为关系型数据库的数据表,主要读取和存储数据信息。
安装redis模块,该模块用于实现Python与Redis服务器的连接与通信,并提供Redis的数据操作等函数方法。
pip install redis
Python操作Redis数据库,先使两者实现通信连接,redis模块提供了两种连接方式:
- 直接连接Redis数据库
- 创建Redis连接池,用于管理所有连接,避免每次建立、释放连接的开销
import redis
# 连接方式一
# 直接连接Redis数据库
# 通过实例化Redis类,在初始化的过程中传入Redis数据库的连接信息
# 参数decode_responses是对Redis数据库返回的数据进行编码,若设为True,则数据以字符串的形式返回,否则以二进制格式返回
r = redis.Redis(host='localhost', port=6379, decode_responses=True)
# 写入字符串类型的数据
r.set('name', 'Python')
# 获取name的数据
print('获取数据方法一:', r['name'])
print('获取数据方法二:', r.get('name'))
# 连接方式二
# 创建Redis连接池,用于管理所有连接,避免每次建立、释放连接的开销
pool = redis.ConnectionPool(host='localhost',port=6379,decode_responses=True)
r = redis.Redis(connection_pool=pool)
# 写入字符串类型的数据
r.set('name', 'Django')
# 获取name的数据
print('获取数据方法一:', r['name'])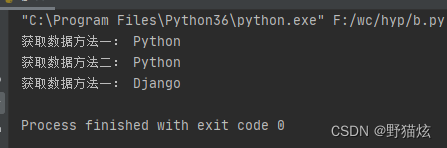
在并发量较高的情况下,第二种方式通过创建连接池,预先创建多个Redis连接,当进行数据操作时,直接从连接池中获取某个连接进行操作,操作完成后,程序不会释放连接,而是让其返回连接池,用于后续操作,这样避免连续创建和释放,从而提高了性能。
新增数据
每个函数或方法的第一个参数name都代表数据名称,第二或第三个参数代表数据内容
import redis
r = redis.Redis(host='localhost', port=6379, decode_responses=True)
# 写入字符串类型的数据
r.set(name='string', value='Python')
# 获取字符串的数据
print('获取字符串的数据:', r['string'])
print('获取字符串的数据:', r.get('string'))
# 写入散列类型的数据
r.hset(name='hash', key='name', value='Tom')
r.hset(name='hash', key='age', value=10)
r.hset(name='hash', key='address', value='UK')
# 获取散列的数据
print('获取散列的数据:', r.hget(name='hash', key='name'))
# 写入列表类型的数据
# 将元素写入列表的左边
r.lpush('list', 'Mr Li', 'Miss Lu')
# 将元素写入列表的右边
r.rpush('list', 'Miss Wang', 'Mir Zhang')
# 获取列表的数据
# lpop()从最左边获取元素,数据获取后在数据库中移除
print('获取列表的数据:', r.lpop('list'))
# rpop()从最右边获取元素,数据获取后在数据库中移除
print('获取列表的数据:', r.rpop('list'))
# 写入集合类型的数据
r.sadd('set', 'UK', 'CN', 'US', 'JP')
# 获取集合的数据
print('获取集合的数据:', r.smembers('set'))
# 写入有序集合类型的数据,每个数据设有权重,权重以整数表示
r.zadd(name='sord_set', mapping={'GZ': 1, 'BJ': 2, 'SZ': 3, 'SH': 4})
# 获取有序集合的数据
print('获取有序集合的数据:', r.zrange('sord_set', 0, -1))
# 写入位图类型的数据
# 将bytes的数据设为字符串数据
r.set(name='bytes', value='Python')
print('二进制数据的第二位数为:', r.getbit(name='bytes', offset=1))
# setbit()将字符串数据转为二进制数据,然后将第二位数改为0
r.setbit(name='bytes', offset=1, value=0)
# 写入流类型的数据
id = r.xadd(name='stream', fields={'name': 'Tom'})
# 获取流数据的id
print('获取流数据的id:', id)
id = r.xadd(name='stream', fields={'msg': 'Hello Python'})
# 获取流数据的id
print('获取流数据的id:', id)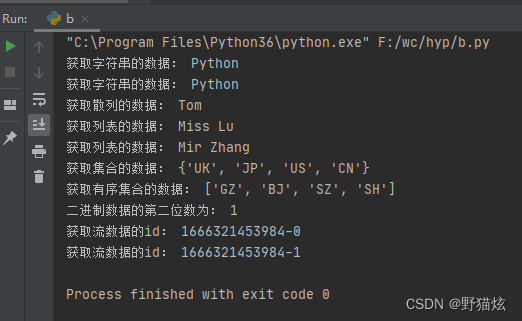
更新数据
Redis仅支持部分数据类型执行更新操作,如字符串、散列、列表和位图。字符串、散列和位图类型的数据,更新数据与新增数据可以使用同一个函数或方法,如果当前数据不存在数据库,就执行新增操作,如果已存在数据库中,就执行更新操作;而列表类型的数据可以使用linsert()和lset()方法实现数据更新操作。而集合、有序集合和流是无法更新数据的,只能清空原有的数据,再执行新增操作。
import redis
r = redis.Redis(host='localhost', port=6379, decode_responses=True)
# 更新字符串类型的数据
r.set(name='string', value='Python')
# 如果数据已存在,就进行修改处理
r.set(name='string', value='Django')
# 获取字符串的数据
print('获取字符串的数据:', r['string'])
# append()是在数据的末端添加数据
r.append('string', '_web')
print('获取字符串的数据:', r.get('string'))
# 更新散列类型的数据
r.hset(name='hash', key='name', value='Tom')
# 如果数据已存在,就进行修改处理
r.hset(name='hash', key='name', value='Tim')
# 获取散列的数据
print('获取散列的数据:', r.hget(name='hash', key='name'))
# 更新列表类型的数据
# 将元素放在列表的左边
r.lpush('list', 'Mr Li', 'Miss Lu')
# 在元素Mr Li前面添加Lucy,参数before代表在前面还是后面
r.linsert('list', 'before', 'Mr Li', 'Lucy')
# 查看整个列表的数据
print('查看整个列表的数据:', r.lrange('list', 0, -1))
# 将列表第一个元素改为Mary
r.lset(name='list', index=0, value='Mary')
# 查看整个列表的数据
print('查看整个列表的数据:', r.lrange('list', 0, -1))
# 更新集合类型的数据
r.sadd('set', 'UK', 'CN', 'US', 'JP')
# 不提供更新操作,只能清空集合再新增数据
r.srem('set', *r.smembers('set'))
r.sadd('set', *('UK', 'CN', 'US'))
# 获取集合的数据
print('获取集合的数据:', r.smembers('set'))
# 更新有序集合类型的数据
r.zadd(name='sord_set', mapping={'GZ': 1, 'BJ': 2, 'SZ': 3, 'SH': 4})
# 不提供更新操作,只能清空有序集合再新增数据
r.zrem('sord_set', *r.zrange('sord_set', 0, -1))
r.zadd(name='sord_set', mapping={'GZ': 1, 'BJ': 2})
# 获取有序集合的数据
print('获取有序集合的数据:', r.zrange('sord_set', 0, -1))
# 更新位图类型的数据
# 将bytes的数据设为字符串数据
r.set(name='bytes', value='Python')
print('二进制数据的第二位数为:', r.getbit(name='bytes', offset=1))
# setbit()将字符串数据转为二进制数据,然后将第二位数改为0
r.setbit(name='bytes', offset=1, value=0)
# 更新流类型的数据
# 不提供修改功能,只能清空数据再新增数据
# xrange()的参数max='+'和min='-'是获取所有数据
alls = r.xrange(name='stream', max='+', min='-')
# 获取流数据的id
ids = [i[0] for i in alls]
# 删除数据
if ids:
r.xdel('stream', *ids)
# 新增数据
id = r.xadd(name='stream', fields={'msg': 'Hello Python'})
# 获取流数据的id
print('获取流数据的id:', id)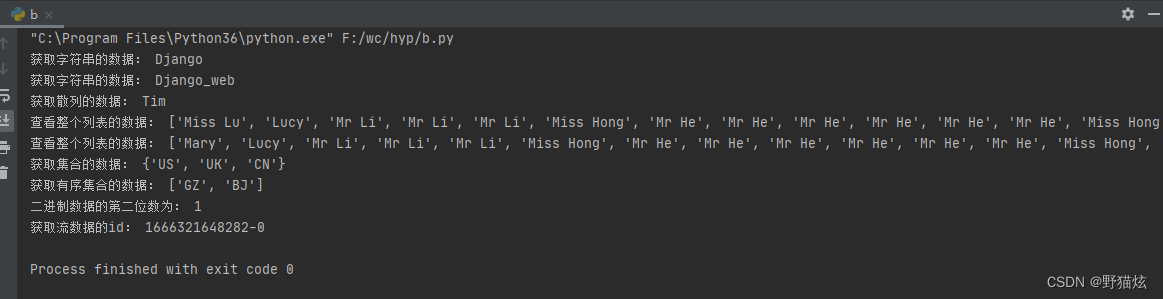 删除数据
删除数据
import redis
r = redis.Redis(host='localhost', port=6379, decode_responses=True)
# 删除字符串类型的数据
# 删除整个string
r.delete('string')
# 删除散列类型的数据
# 删除某个键值对
r.hdel('hash', *('name', ))
# 删除全部键值对
# hgetall()获取全部键值对,以字典格式返回
keys = r.hgetall(name='hash').keys()
# 将hash的所有键值对删除
r.hdel('hash', *keys)
# 删除整个hash
r.delete('hash')
# 删除列表类型的数据
# 删除某个数据
# 参数count的值等于0,移除列表中所有指定数据
# 参数count的值大于0,从列表的左端开始向右进行检查,并移除最先发现的count个指定数据
# 参数count的值小于0,从列表的右端开始向左进行检查,并移除最先发现的abs(count)个指定数据
r.lrem(name='list', count=0, value='Mary')
# 删除整个list
r.delete('list')
# 删除集合类型的数据
# 删除某个数据
r.srem('set', *('US',))
# 删除全部数据
# smembers()获取所有数据
all = r.smembers('set')
r.srem('set', *all)
# 删除整个set
r.delete('set')
# 删除有序集合类型的数据
# 删除某个数据
r.zrem('sord_set', *('BJ',))
# 删除全部数据
# zrange()获取有序集合的所有数据
all = r.zrange('sord_set', 0, -1)
r.zrem('sord_set', *all)
# 删除整个sord_set
r.delete('sord_set')
# 删除位图类型的数据
# 删除整个bytes
r.delete('bytes')
# 删除流类型的数据
# xrange()的参数max='+'和min='-'是获取所有数据
alls = r.xrange(name='stream', max='+', min='-')
# 获取所有数据的id
ids = [i[0] for i in alls]
# 删除全部数据,如果删除某个数据,那么只需设置ids的列表数据即可
if ids:
r.xdel('stream', *ids)
# 删除整个stream
r.delete('stream')查询数据
import redis
r = redis.Redis(host='localhost', port=6379, decode_responses=True)
# 查询字符串类型的数据
print('查询字符串类型的数据:', r.get('string'))
print('查询字符串类型的数据:', r['string'])
# 查询散列类型的数据
# 查询某个键值对
v = r.hget(name='hash', key='name')
print('查询某个键值对:', v)
# 查询全部键值对
# hgetall()获取全部键值对,以字典格式返回
v = r.hgetall(name='hash')
print('查询全部键值对:', v)
# 查询列表类型的数据
# 获取列表最左端的元素,并移除
l = r.lpop('list')
print('获取列表最左端的元素,并移除:', l)
# 获取列表最右端的元素,并移除
l = r.rpop('list')
print('获取列表最右端的元素,并移除:', l)
# 查询列表的长度
l = r.llen('list')
print('查询列表的长度:', l)
# 查询指定索引的数据
l = r.lindex(name='list', index=0)
print('查询指定索引的数据:', l)
# 查询索引范围的数据
# 若参数start=0且end=-1,则查询全部数据
l = r.lrange(name='list', start=0, end=-1)
print('查询索引范围的数据:', l)
# 查询集合类型的数据
# 随机查询数据
# 参数number代表查询数据的个数
s = r.srandmember(name='set', number=2)
print('随机查询数据:', s)
# 查询数据是否存在
s = r.sismember(name='set', value='UK')
print('查询数据是否存在:', s)
# 查询数据的数量
s = r.scard(name='set')
print('查询数据的数量:', s)
# 查询所有数据
s = r.smembers('set')
print('查询所有数据:', s)
# 查询有序集合类型的数据
# 查询数据的数量
s = r.zcard('sord_set')
print('查询数据的数量:', s)
# 查询全部数据
# zrange()获取有序集合的所有数据
# 参数start和end代表数据在有序集合中的索引
# 若参数start=0且end=-1,则查询全部数据
s = r.zrange(name='sord_set', start=0, end=-1)
print('查询全部数据:', s)
# 查询数据的权重
s = r.zscore(name='sord_set', value='GZ')
print('查询数据的权重:', s)
# 查询数据的排名
s = r.zrange(name='sord_set', start=0, end=-1)
print('查询数据的排名:', s)
# 查询位图类型的数据
# 查询二级制的某个位数的数值
b = r.getbit(name='bytes', offset=1)
print('查询二级制的某个位数的数值:', b)
# 查询被设置的二进制位数量
b = r.bitcount(key='bytes', start=0, end=-1)
print('查询被设置的二进制位数量:', b)
# 查询第一个指定的二进制位值的位置
b = r.bitpos(key='bytes', bit=1, start=0, end=-1)
print('查询第一个指定的二进制位值的位置:', b)
# 查询流类型的数据
# 查询所有数据
# xrange()的参数max='+'和min='-'是获取所有数据
x = r.xrange(name='stream', max='+', min='-')
print('查询所有数据:', x)
# 查询数据的数量
x = r.xlen(name='stream')
print('查询数据的数量:', x)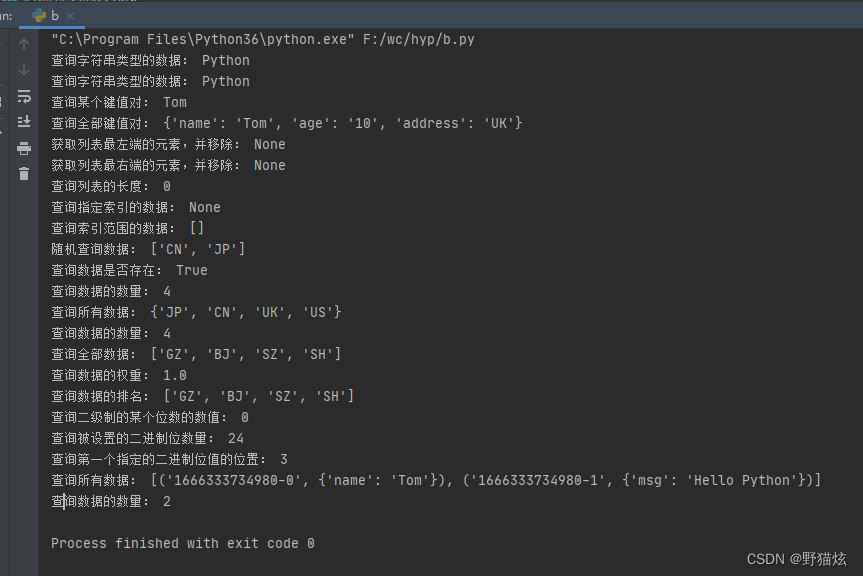















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









