







准备工作:
1.下载 DOSBOx 0.74
2.在对用位置的文件
C:\Users\Administrator\AppData\Local\DOSBox\dosbox-0.74.conf
最后下面加入代码
mount d d:/masm
d:
masm t1.asm;
link t1.obj;
注:
mount 后面的盘符可以自定 ,e,g都可。 d:/masm是你的源文件,编译后的分块和链接文件,exe可执行文件生成的地方。
t1.asm; t1是你自己定的一个asm源文件的名称
t1.obj; 与上同
1.为什么内存地址是从0开始的?
答案:因为物理上的限制,电路中只能表示了0或者1,所以最小的只能从0开始
2.什么叫寻址能力?
答案:地址线的数量决定了你能传多少位的0或者1,决定了你能找到的多少地址,例如10根地址线,那么范围就是0-1023
3.三种线的作用?
地址线:决定了 CPU 的寻址能力
数据线:决定了 CPU 和其他部件进行数据传送时,一次性能够传送多少字节的能力
控制线:决定了 CPU 对其他部件进行控制的能力
4.为什么产生的exe可执行文件在电脑上执行时总是显示说,不能运行,不兼容等多方面的原因。
答案:masm5 汇编产生的是16位DOS环境下的可执行程序,所以在你64位或者32位的电脑上是不可以运行的。
检测:
(1)一个CPU的寻址能力为8kb,那么他的地址总线宽度为 8192
(2)1kb的存储器有 1024 个储存单元,编号为0-1023
(3)在存储器中,数据和程序(指令)以 二进制 形式存放
1.内存条:主内存
2.内存地址是不是内存条的地址?
答案:不是,内存条是计算机的一个部件,debug里面的内容是显卡,即显存的地址,显卡是插在主板上的硬件。
3.什么是RAM内存?
答案:允许读取和写入,断电后,内存中的指令和数据就丢失了
4.什么是ROM内存?
答案:只允许读取,断电后,指令和数据还存在,一般用在计算机启动上面。
5.键盘和鼠标同样也有芯片,也能存储指令和数据
6.CPU通过 主板上的电路 读取到所有的数据。CPU就像人的大脑,主板是人体的骨骼,主板上的电路就像附加在骨骼上的神经
7.CPU也给鼠标、键盘、麦克风、音箱编号了的, 60H 是键盘的编号,称为 端口号。
8.GPU:图形处理芯片,对于图形的要求越来越高了,专门进行图形处理,有专门的编程语言。
寄存器
1.AX,BX,CX,DX四个通用寄存器,存放数据的,数据寄存器。
2Byte=16bit 表示范围0-65535(10进制)
他们可以各自分割为两个八位寄存器
在使用mov时,要保证数据与寄存器之间位数一致性
AX=AH+AL AX的高八位寄存器 AH寄存器 ,低八位寄存器 AL寄存器
BX=BH+BL
CX=CH+CL
DX=DH+DL
为什么要有八位寄存器?
答案:
(1)为了兼容以前编写的寄存器,稍加修改就可以运行在8086CPU上
(2)内存的最小单元 字节 8bit
cpu从内存中读取一个字节 8位数据–>8位寄存器中
数据线呢? 16根数据线
8086CPU一次可以处理两种尺寸的数据
字节型数据 byte 8bit 8位寄存器中
字型数据 2byte=16bit 16位寄存器中 2个字节
一个字节是这个字型数据的高位字节(AH,BH,CH,DH)
另一个字节是这个字型数据的低位字节(AL,BL,CL,DL)
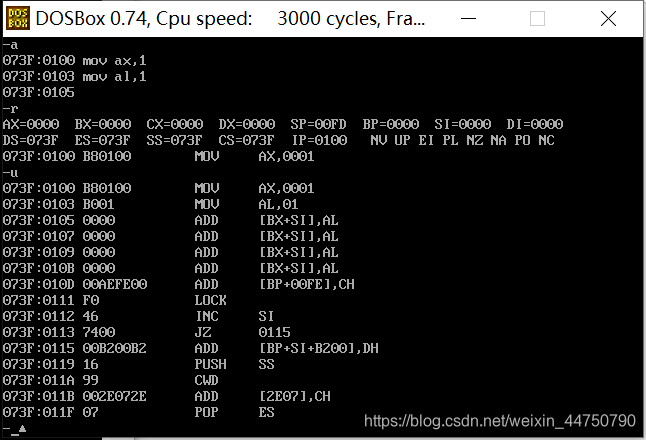
数据与寄存器之间要保证一致性,8位寄存器给8位寄存器,16位寄存器给16位寄存器,不能说八位给16位,也不能16位给8位。
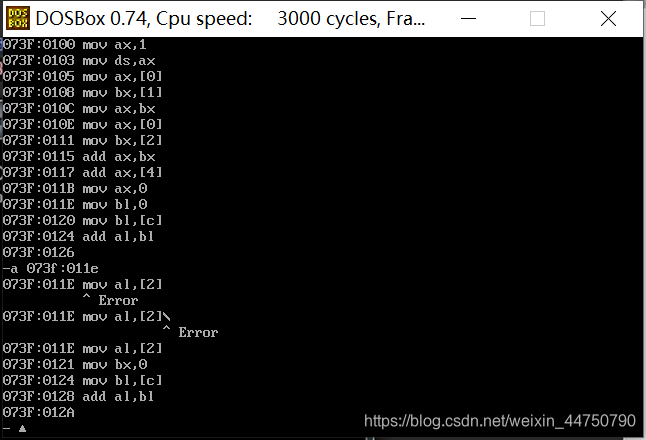
由下图可知,位数不同的寄存器互相赋值时会报错。
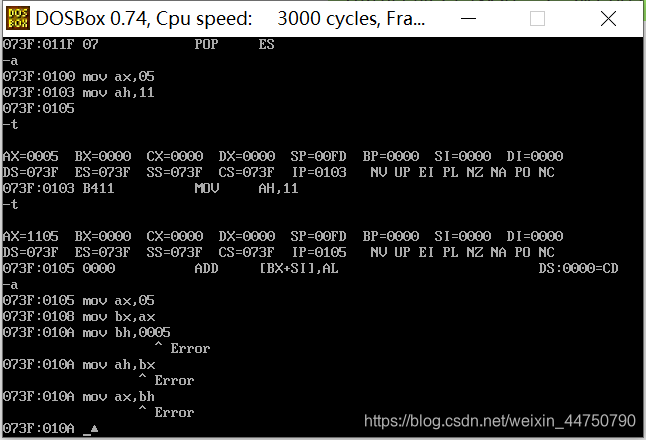
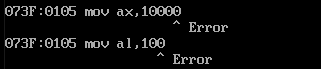
八位寄存器进行八位运算,只会保存八位数据。先把93赋值给ax,然后再将al加上85,本来结果是等于118的,但是结果只是18。表明了两个寄存器是互相独立的,就算溢出了,也不会跑到ah的低位去。
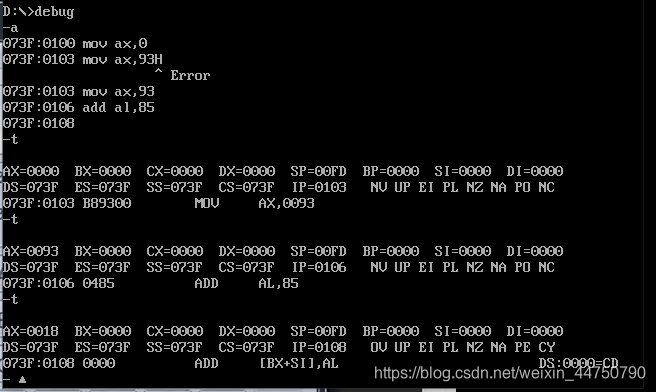
下面这种情况,利用十六位寄存器来进行运算的,就不会溢出

地址线的数量决定了CPU的寻址能力
冒号左边的是段地址(存放在段地址寄存器中)
冒号右边的是偏移地址(存放在偏移地址寄存器中)
段地址:偏移地址
段地址寄存器:DS、ES、SS、CS
偏移地址寄存器:SP、BP、SI、DI、IP、BX(地址信息也可以当做一种数据),都是16位寄存器
8086CPU的设计者给了20个地址线,表示范围
00000000000000000000-11111111111111111111
但是地址寄存器却只有16位,所以设计者给了一个地址加法器
地址加法器 地址的计算方式:
段地址x16(10进制的,16进制是10H)+偏移地址=物理地址
段地址x16=基础地址
基础地址+偏移地址=物理地址
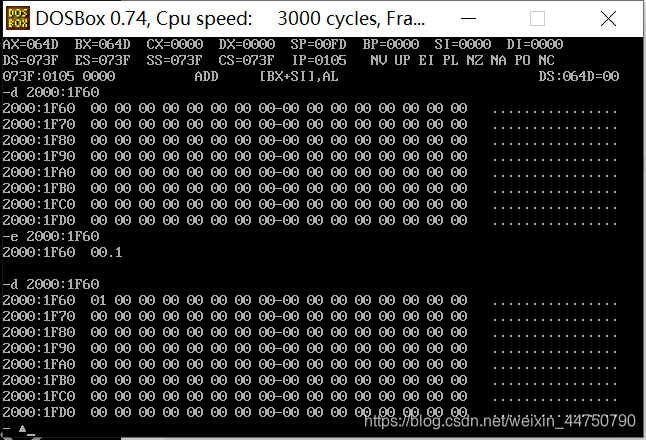
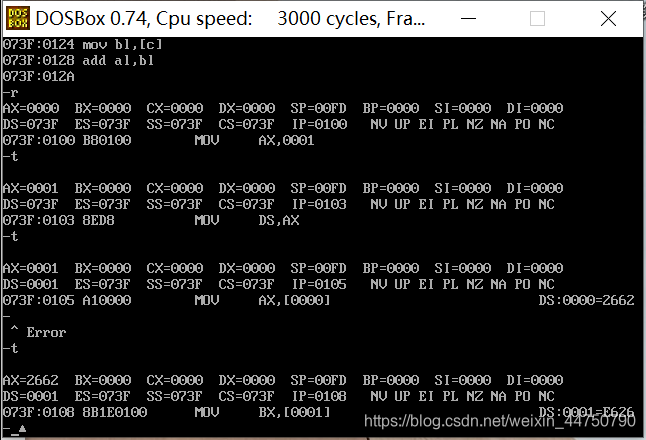
由下面的实验就可以看到
段地址 2000
偏移地址 1F60
-d 2000:1F60进入到这个地址中并查看改地址的值
-e 2000:1F60进去到这个地址中并修改地址中的值
-d 2000:1F60 再次进入到这个地址中查看地址中的值
-d 2100: 0F60 进入到地址中查看该地址的值
经过3、4可以发现,段地址*16(10进制)+偏移地址(0-FFFF)= 物理地址【验证成功】

1.段地址为 0001H,仅仅通过变化偏移地址寻址,CPU的寻址范围为 10H 到 1000FH
2.有一个数据存在内存20000H单元中,现在给 段地址为 SA,若想用偏移地址找到此单元,则SA应该满足的条件是 1001H 到 2000H(段地址0000-FFFF)
这个地方特别注意不要算成1000H
CPU如何区分指令和数据的呢?
u指令 将某个内存地址开始的字节全部当做指令
d指令 将某个内存地址开始的字节全部当做数据
8086CPU中, 在任意时刻, CPU将CS(段地寄存器),IP(偏移地址寄存器) 中所指向的内容全部当做指令来执行。
在内存中,指令和数据是没有任何区别的,都是二进制的,CPU只有在工作的时候,才将有的信息当做指令,有的信息当做数据,CPU是根据什么将内存中的信息当做指令的话,那就是CPU在工作中将CS,IP所指向的内存单元中的内容当做指令。
指令和数据在内存中是没有任何区别的,CPU只有在工作的时候,才会把CS段地址寄存器和IP偏移地址寄存器 组合而成的地址从中读取内容并当做指令来处理。
指令是有长度的,一条指令可由多个字节组成。
指令的执行过程:
1.CPU从CS:IP所指向的内存单元中读取指令,存放到指令缓存器中
2.IP=IP+所读指令的长度,从而指向下一条指令
3.执行指令缓存器中的内容,回到步骤1
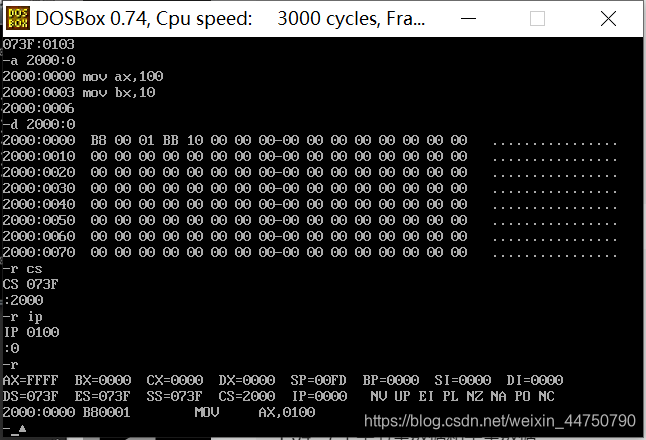
实验:了解ip寄存器和指令长度之间的关系
先把
mov ax,1000
mov bx,1000
mov dl,10
放进去指令集
此时,CPU将CS(段地址寄存器)*10H+IP(偏移地址寄存器) 中取出作为指令
此时的
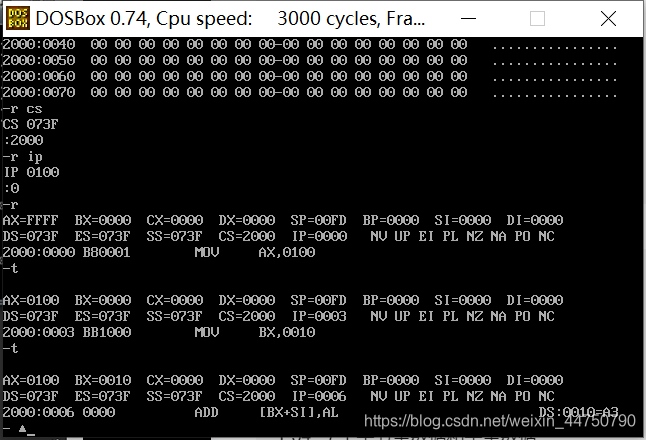
073F:0100 B80010 就是指令,此时,ip=0100,然后,-t,单行执行指令,此时ip=ip+3(3就是原来指令的长度即B80010的长度,3个字节)。
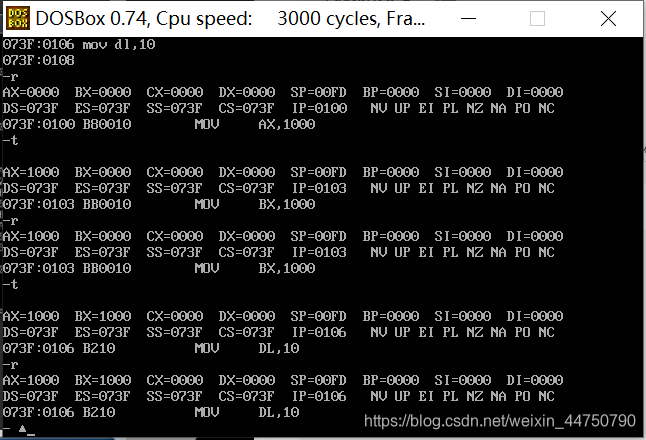
然后再执行一次 ,此时ip地址的长度=ip+3(3是第二条取出地址的长度即BB0010的长度,3个字节)。
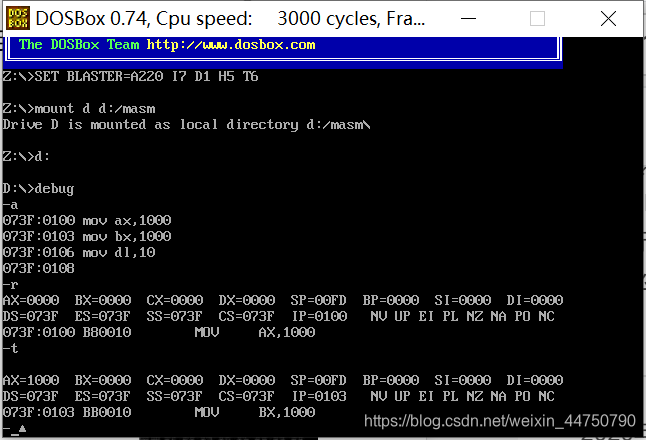
然后,此时,下一条指令是 B210(长度为2个字节),
此时ip=ip+2(刚刚好为108)
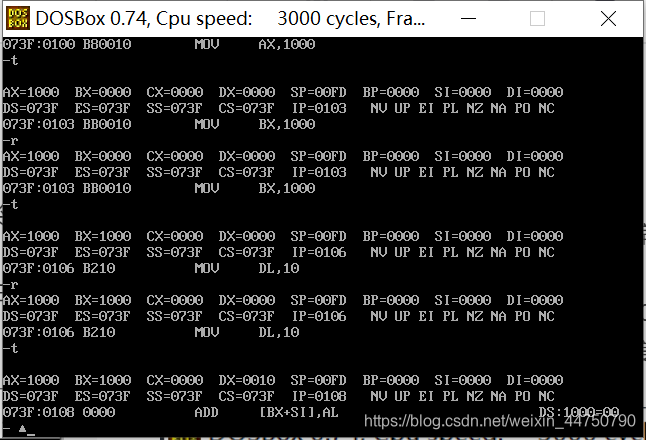
新的汇编指令
JMP 跳转指令
jmp 2000:0000
jmp 寄存器
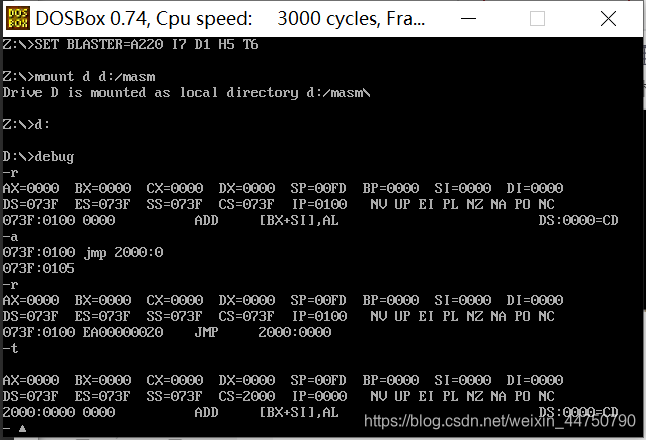
此时,-r查看073F:0000这个地址中的情况,发现cs=073f,ip=01000,
然后,我们使用-a修改指令为 jmp 2000:0
此时,-r,可以看到,cs=2000,ip=0000.(就是前面的段地址和偏移地址)
问题:为什么指令取出后要放到指令寄存器中,然后ip+=指令长度,然后再执行呢?
为了实现 call 指令
下面几条指令执行后,CPU修改了几次ip,都是在什么时候,最后的ip值为多少?
mov ax,bx -->存放到指令缓存器中,ip修改一次,此时ip指向第二条指令(mov ax,bx),执行步骤3 ax=bx
sub ax,bx---->存放到指令缓存器中,ip再修改一次,指向(jmp ax),执行 ax=ax-bx=0
jmp ax —>存放到指令缓存器中,ip修改一次,ip指向下一条指令,然后执行,此时ip=0(ip等于ax寄存器中的值,ax=0,那么ip也就等于0),ip的值在最后的执行也还修改了一次。
答案:ip修改了4次,最后ip的值为0
debug调试工具的总结使用:
r命令:
功能1:查看cpu中所有寄存器中的内容,将cs和ip所指向的机器码翻译成指令
功能2:修改寄存器中的内容
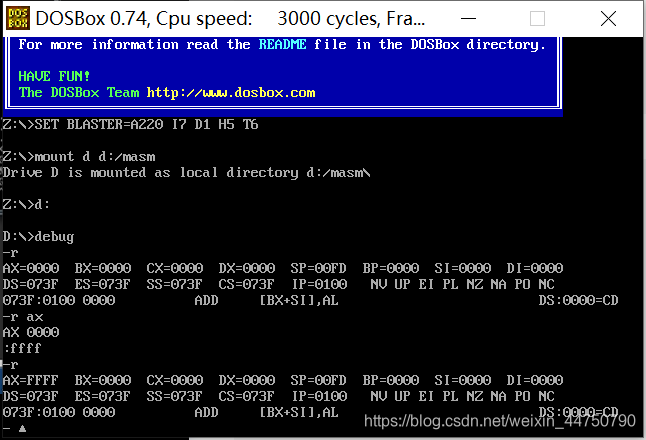
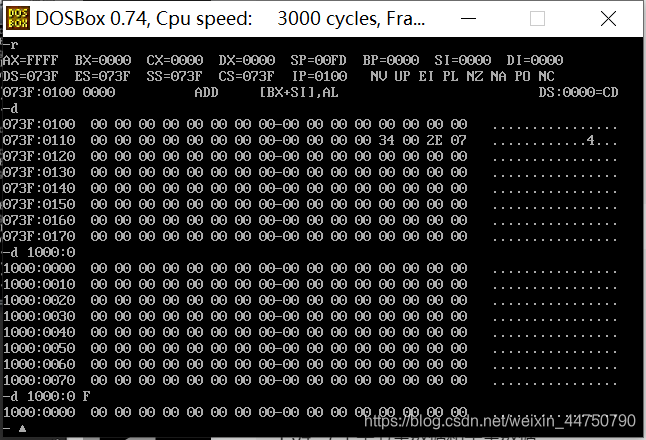
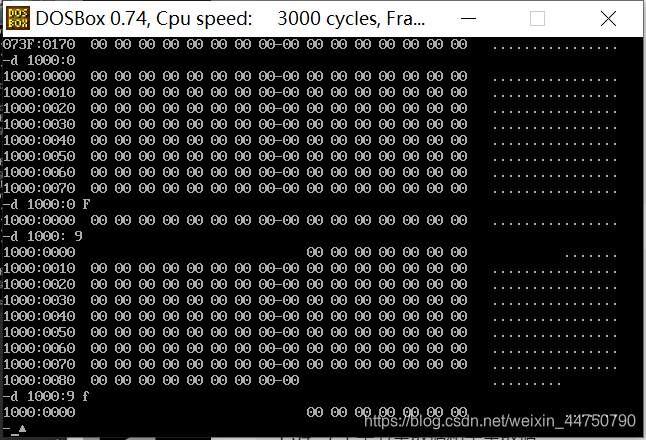
d命令:
功能1:查看内存地址(左边)、内存地址中的内容(中间)、ASCII码(右边)
功能2:查看对应地址开始后面的128个字节
功能3:查看对应地址开始后面指定的字节数
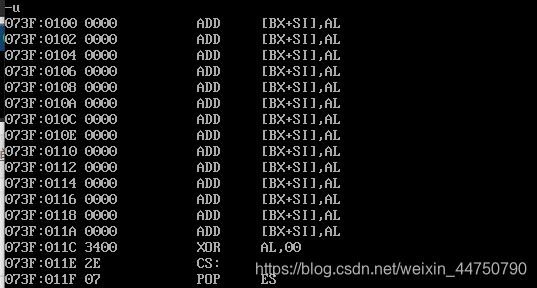
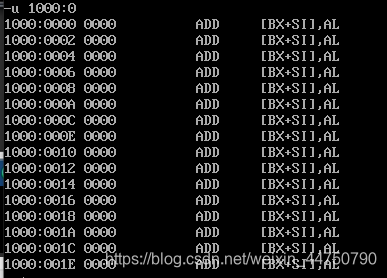
u命令:
功能1:从这个地址开始,将机器码翻译为汇编指令,给一个阅读方便。
功能2:从指定地址开始,将机器码翻译为汇编指令
功能3:从指定地址开始,将特定数目的机器码翻译为汇编指令
a命令:
功能1:向当前位置写入一条汇编指令
功能2:向指定位置写入一条汇编指令

此时只是写入了机器码,但是cs和ip还是没有改变
所以使用r命令改一下
t命令
功能1:单步执行指令
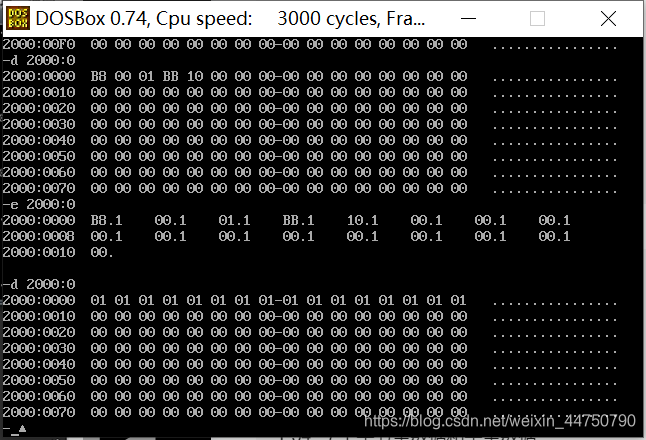
e命令:
功能1:修改对应地址中的内容
例如:一开始,2000:0中的全部内容都是0,然后到后来,我们全部都修改成1.
功能2:改变对应地址开始的ASCII码
后面双引号里面输入的是你要的字符,这个就是能够快捷修改对应地址的ACSII码
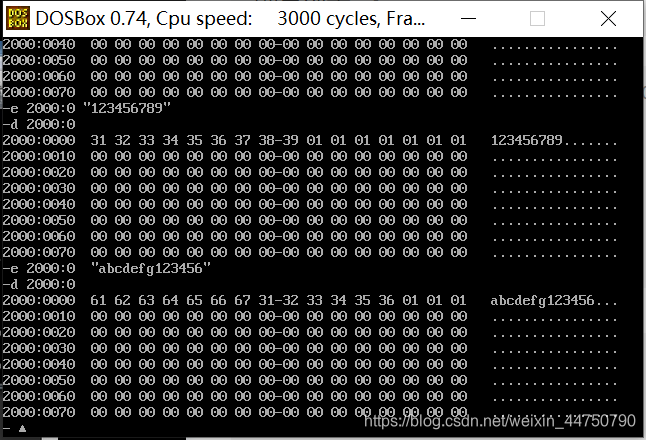
利用指令 d FFF0:0000 FF(可以看到内存地址的生产日期)
寄存器可以分为三类:
1.数据寄存器
2.地址寄存器(段地址寄存器 偏移地址寄存器)
3.标志位寄存器
数据寄存器
BX可以用来当做偏移地址寄存器,CX也可以有其他作用
AX,BX,CX,DX通用寄存器
16位寄存器,可以各自分割为两个8位寄存器,互相独立的八位寄存器
实验:下面的例子,在使用ax时,因为是16位寄存器,汇编指令就被编译为0001(十六位寄存器);在使用al时,汇编指令就是01(八位寄存器)。
翻译工作为了保证数据与寄存器之间的位数一致性 通过寄存器的位数来判断编译指令中的数据的位数
下面这个就是寄存器的位数和所要保存的数据位数不一致的情况,就会报错。
运算的时候,有可能会超过寄存器的最大表示值,最高位被存放到其他地方去了。
寄存器之间是互相独立的。
地址寄存器
段地址寄存器:偏移地址寄存器
ds sp
es bp
ss si
cs di
ip
bx
组合规则:
段地址*16(10进制)+偏移地址=物理地址
8086CPU有20根地址线,但是寄存器只有16位,如果只用16位寄存器来表示地址的话,那么会造成地址线的浪费,所以就有上面的组合规则的出现。
CPU是如何区分指令和数据的呢?
指令和数据在内存中的存储形式都是机器码,毫无区别
关键:CS IP这两个寄存器
在任意时刻,CPU将段地址寄存器CS 和 偏移地址寄存器IP 所组合出来的地址从中读取的内容全部当做指令来执行。
指令是有长度的,指令长度与IP地址相关
可以修改 CS IP 这2个寄存器的指令
转移指令:
jmp 2000:0(具体地址)
jmp 寄存器格式
call xxxx 指令执行的过程—>改变了的IP保存了起来,实行跳转。
指令执行的过程
1.CPU从CS:IP 所指向的内存单元中读取指令,存放到指令缓存器中
2.IP=IP+所读指令的长度,从而指向下一条指令。
3.执行指令缓存器中的内容,回到步骤1.
内存的访问过程:
问题:call指令 将 IP保存到了哪里去了?(保存在内存的哪个位置) 利用 ret 可以拿回
数据长度 字节型数据 字型数据
一个字型数据 存放在内存当中 可以由2个连续的地址的内存单元组成
高地址 内存单元存放 字型数据的 高位字节
地地址 内存单元存放 字型数据的 低位字节
mov ax,1000H
mov ds,ax
物理地址 内容
10000H 23H
10001H 11H
10002H 22H
10003H 66H
ds:[0]=1123H
ds:[2]=6622H
ds:[1]=2211H
mov ax,ds:[0]
mov bx,ds:[2]
mov cx,ds:[1]
mov bx,ds:[1]
add cx,ds:[2]

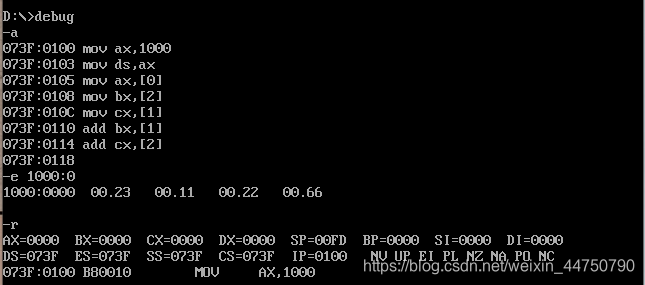
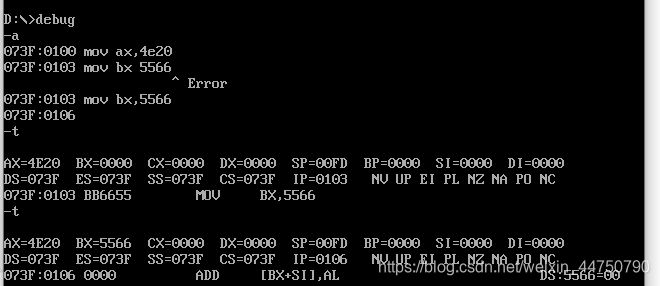
把指令输入到文件里面,然后改变地址 1000:0 的值
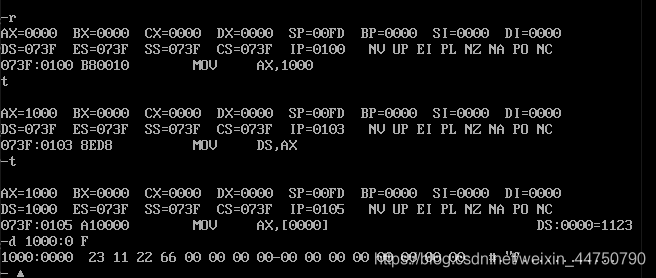
改变了ds的值之后,我们查看下对应指令的数据,前面四个就是23 11 22 66,是我们输入的数据
执行第一条指令,AX=1123,

下面依次执行每一条指令
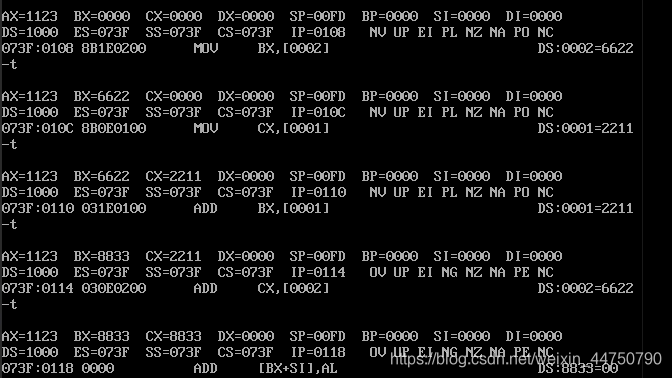
数据段
编程时候一种数据安排,编程的时候要特别注意是字型数据还是字节型数据。
字节型数据 字型数据 在内存中的存放
字型数据 在内存中存储时,需要两个连续得的内存单元存放。
高字节 存放在 高地址 中
低字节 存放在 低地址 中
注意:数据和指令在内存中是没有任何区别的
常用指令的格式:
| mov 寄存器,数据 | mov ax,8 |
|---|---|
| mov 寄存器,寄存器 | mov ax,bx |
| mov 寄存器,内存单元 | mov ax,ds:[0] |
| mov 内存单元,寄存器 | mov ds:[0],寄存器 |
| mov 段寄存器,寄存器 | mov ds,ax |
| add 寄存器,数据 | add ax,8 |
|---|---|
| add 寄存器,寄存器 | add ax,bx |
| add 寄存器,内存单元 | add ax,[0] |
| add 内存单元,寄存器 | add [0],ax |
| sub 寄存器,数据 | sub ax,9 |
|---|---|
| sub 寄存器,内存单元 | sub ax,bx |
| sub 寄存器,内存单元 | sub ax,[0] |
| sub 内存单元,寄存器 | sub [0],ax |
指令从哪里来:cs:ip
数据从哪里来:ds
通过使用汇编语言 修改寄存器中的内容,去控制CPU,控制整个计算机
核心就一句话:
高字节 存放在 高地址 中
低字节 存放在 低地址 中

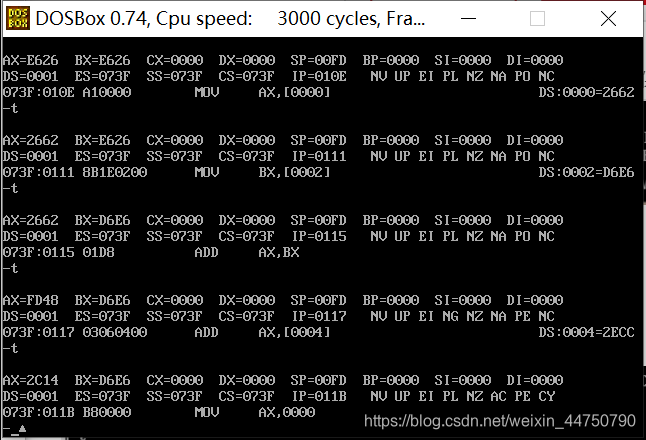
比如第一个指令,AX=2262H
对比上面,我们知道,[0]=62,[1]=26
所以,AX的高位AH存放[1]的值就是26,AX的低位AL存放[0]的值就是62.
高字节存高地址,低字节存地地址
AX的值在经过执行修改后变为了2262.
BX变为E626,实验结果证明是经得起实际考验的。

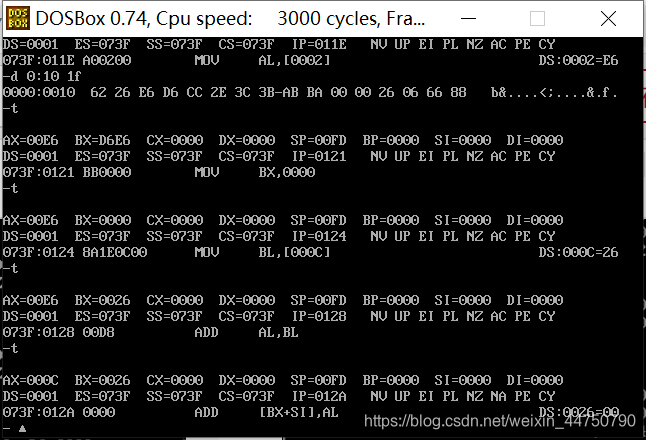
这个是执行ADD AX,[0004]的结果,这时结果为2C14(事实上,还有一个最高位1被存放在其他地方了)
注意此时AX=0C,此时结果是会溢出的。但是它的最高位被存放在另外的寄存器。指令是 ADD al,bl.(两个低位存储器,按照正常来讲,它相加的和保存在al中,而ah的小的那个位置却没有保存他们和的进位,这个也表明寄存器是互相独立的)。
实践是检验整理的唯一标准
栈:一段连续的内存单元,也是一段连续的内存地址
汇编指令:
入栈 push 修改栈顶标记
出栈 pop 修改栈顶标记
只能对16位寄存器进行操作,只 操作字型数据
栈顶标记是内存地址(段地址+偏移地址)
在8080CPU中 任意时刻,将 段地址寄存器ss 和 偏移地址寄存器sp 所组合出来的内存地址当做栈顶标记。
push ax 修改sp寄存器中的数值,sp=sp-2,将 ax 中字型数据存入到 ss:sp所组合出来的内存地址中
pop bx 将 ss :sp 所组合出来的内存地址中的字型数据存放到bx中,然后修改栈顶标记 sp=sp+2, 成为新的栈顶标记
实验:
mov ax,2233
push ax
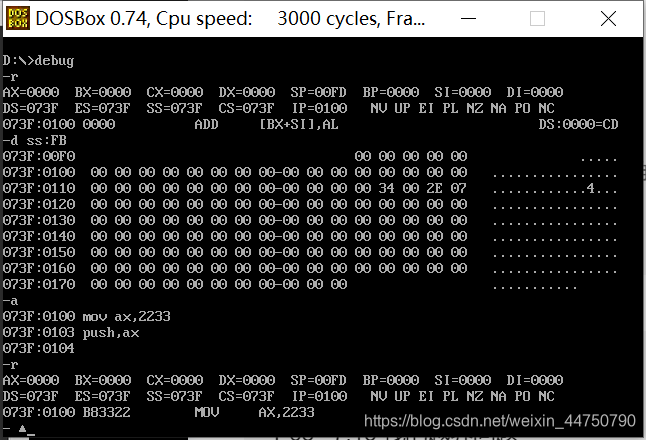
一开始,先利用-d指令查看 ss:fb(即栈的值)
注意观察执行push指令前后,SP的值由 00FD 变为 00FB。
再查看一下 ss:fb,发现变成了 33 22(高地址存高字节,低地址存低字节)
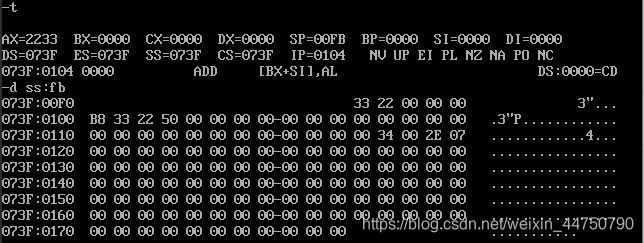
在8080CPU中,cpu在任意时刻,都会将段地址寄存器ss 和 偏移地址寄存器sp 所组合出来的内存地址当做栈顶标记。然后,我们可以改变寄存器的内容------>我们可以决定栈顶标记在哪里------>可以决定栈在哪里----->可以决定栈的大小。
通过设置ss,sp所组合出来的栈顶标记,一般是16的倍数。
栈会越界:就是存放的数据超出了栈的范围,这是非常危险的。
我们可能在栈中存放了指令或者数据,但是我们使用栈超出了范围,会发生一些奇奇怪怪的问题。
8086CPU在任意时刻都会将 段地址寄存器ss 和偏移地址寄存器 sp 所组合出来的内存地址 当做栈顶标记!
所以,汇编语言我们是没有什么判断溢出的操作的。
汇编语言栈的极限大小:
sp寄存器的变化范围 0-FFFFH 32768个字型数据
ss=2000H sp=0
设置了一个可以存放32768个字型的栈,如果越界了,就是会覆盖了原来栈中的内容。
栈的作用:
1.临时性保存数据;
2.用栈进行数据交换;
3.栈是一种非常重要的思想。
汇编语言编程中的注意事项:
每执行一条 t 指令,cpu就会将寄存器保存到栈中,栈是临时性保存数据
call ip保存到栈,为了让ret 指令可以从栈中拿回来。
我们可以在一段内存中存放数据 数据段 存放了我们自己定义的数据
我们可以在一段内存中存放指令 指令段(代码段) 存放了我们自己定义的指令
我们可以将一段内存定义成栈空间 因为我们处理数据的时候需要临时性的存放 栈段
对于数据段来讲,段地址寄存器ds [0] [1]。。。。mov add sub 指令去访问 这些内存单元,那么cpu就会将我们定义的数据段中的内容当做数据来访问
对于代码段来讲,我们可以通过 cs ip这两个寄存器,去指向我们定义的代码段,这样cpu就将执行我们定义的代码段中的指令
对于栈段来讲,我们可以通过ss:sp这两个寄存器去决定栈顶标记在哪里,这样cpu在执行栈的操作时,比如 push pop 就会将我们定义的栈段 当作 栈空间使用,进行临时性的数据存放或者取出
不管我们如何安排,cpu将内存中某段内容当做指令,是因为 cs:ip 指向那里,cpu将某段内存当作栈空间,是因为 ss:sp 指向那里
我们一定要清楚,我们应该如何安排内存,以及如何让cpu按照我们的安排去行事
数据从哪里来?
指令从哪里来?
临时性的数据 存放到哪里?
取决于我们对cpu中的 地址寄存器的设置,cs,ip,ss,sp,ds 寄存器
内存段的安全:数据段 代码段 栈段
随意地向某一段内存空间中写入内容是非常危险的,我们如果随意使用mov指令,可能会不小心修改了系统存放在内存中的重要数据或者指令导致程序的崩溃甚至系统的崩溃。
解决:
1.向安全的内存空间去写入内容0:200-0:2FFH
2.使用操作系统分配给你的空间
在操作系统的环境下,合法地通过操作系统取得的内存空间都是安全的,操作系统不会让 一个程序所使用用的内存空间 和 其他程序 以及 系统自己的内存空间 产生冲突
如何在系统中运行软件 exe文件,我们将一个汇编语言源文件,通过 编译 和 链接 之后可以得到一个 exe 文件。
代码段 数据段 栈段都是写在 源文件中的
执行exe文件就是操作系统给我们程序分配内存的过程
编译和链接
编译 masm asm----> obj
链接 link obj -----> exe
将代码拆分开开来,防止一些代码有错误而需要修改后需要整个文件重新编译,因而先将他们每一部分先细分之后,然后编译出来后再链接起来。
exe 可执行文件
系统要执行exe文件时,需要给他分配一段内存。
系统是怎么知道要分配多大的内存给这个程序呢?(因为exe文件中除了整个程序的代码,还包括了一些信息,例如描述信息)
描述信息:系统就是根据这些信息,对寄存器进行相关的设置,例如 栈的大小,程序入口等。
源代码文件(asm):
汇编语言
汇编指令 被编译成 010101机器指令 机器码 由CPU执行
伪指令 由编译器执行的
符号体系 由编译器执行的(mov 指令 之类的)
一开始有个assume,假设指令,是设置的依据,将数据和指令的编译与特定的寄存器联系起来
data segment 告诉了编译器 data段从这里开始
data ends 告诉了编译器 data段从这里结束
段的名字可以随意取,一般去对应的英语单词(方便阅读)
系统在加载程序的时候,系统给程序分配内存,经过程序返回的功能,把内存和寄存器都还给系统,永远占用了内存,内存是有限的,直到最终系统没有内存可用。
程序的跟踪 debug+程序名
cx = 程序的长度
p 执行 int 指令
q 退出
psp区 从ds:0 开始的256个字节
我们程序的名字
系统加载程序到内存中
它是用来 系统和程序之间 进行的通信
assume cs:code
code segment
mov ax,2000H
mov ss,ax
mov sp,0
add sp,10H
pop ax
pop bx
push ax
push bx
pop ax
pop bx
mov ax,4C00H
int 21H
code ends
end
快速编译:将一个asm编译为exe文件。
调试:debug,-t 指令。利用u指令可以查看文件中写的汇编指令
规则: 翻译软件的规则
1.如果是字母数据的话,一个数据最开头不能是字母,要在前面加一个0,不然会报错.任何字母型数据前面都要加个0
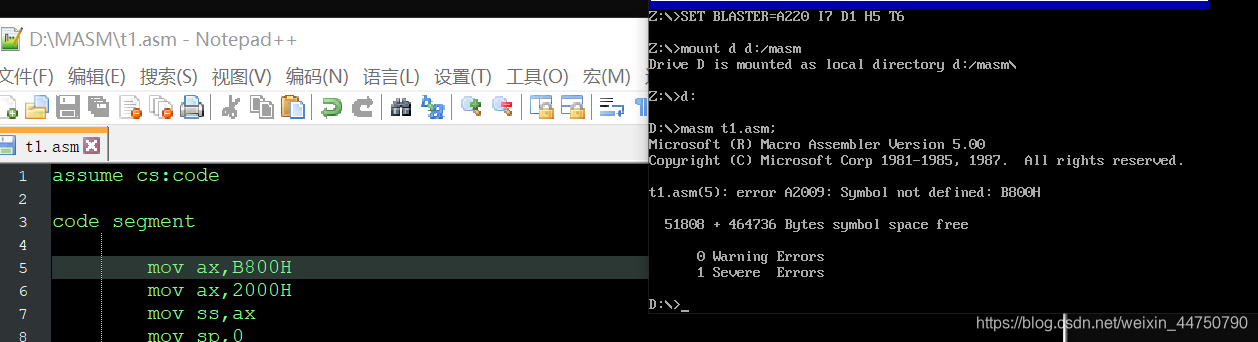

2.注意十六进制和十进制
 3.注释
3.注释
在编译指令后 加个分号 ; 在分号之后,所有的东西都会被当做注释。注释很重要。
自增指令
inc bx ;将bx里面的值加1
与 add bx,1有何区别?
为了节约内存。
从实验结果看来,作用的结果确实是一致的,但是他们第一个指令是
073F:0100 83C301 (3个字节)
第二个指令是
073F:0103 43 (1个字节)

这里把它放进去编译软件后,再利用 -u -a -t -d 指令去观察变化的情况。
assume cs:code
code segment
mov ax,2000H
mov ds,ax
mov bx,1000H
mov dl,0BEH
mov ds:[bx],dl
mov ax,ds:[bx]
inc bx
inc bx
mov ds:[bx],ax ;把ax寄存器中的值放进去前面的地址中
inc bx
inc bx
mov ds:[bx],ax
inc bx
mov ds:[bx],al
inc bx
mov ds:[bx],al
mov ax,4C00H
int 21H
code ends
end
需求:我们需要不断执行某几条指令,就是,某几条指令可能需要重复执行。
JMP指令
使用jmp指令去修改 cpu 中寄存器的值
我们给 mov ds:[bx],dl 设置了一个setNumber的编号,然后,mov ds:[bx],dl 的地址是
073F:000C,此时,观察 jmp后面的setNumber的值也被翻译为 000C.
这样不用去揣测它的地址第一个起始指令的地址,就使得编程变得很灵活。
assume cs:code
code segment
mov ax,2000H
mov ds,ax
mov bx,1000H
mov,dl,0
setNumber: mov ds:[bx],dl
inc dl
inc bx
jmp setNumber ;setNumber是你可以自己设定的,叫做标号,标识(会被翻译为内存地址)
mov ax,4C00H
int 21H
code ends
end

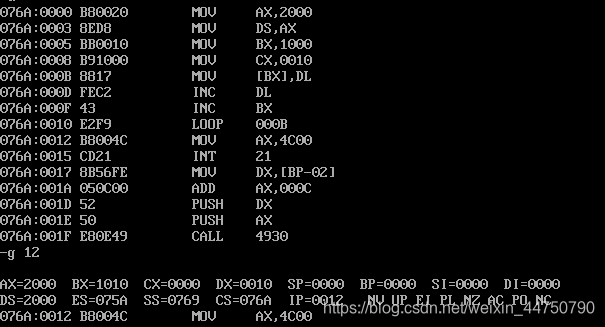
loop指令
**执行一次循环体中的内容后,会把cx中的值减1,然后去跟0比较。**跟高级语言的for循环有点相似。
assume cs:code
code segment
mov ax,2000H
mov ds,ax
mov bx,1000H
mov cx,16 ;保存跳转次数,即增加了一个限制条件
setNumber: mov ds:[bx],dl
inc dl
inc bx
loop setNumber ;setNumber是你可以自己设定的,叫做标号,标识(会被翻译为内存地址)
mov ax,4C00H
int 21H
code ends
end
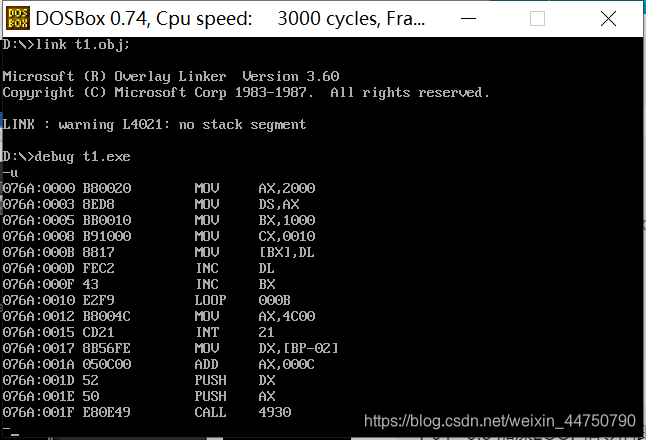
方法1:执行到loop指令的时候,可以直接用p指令,就可以把循环次数都用完。
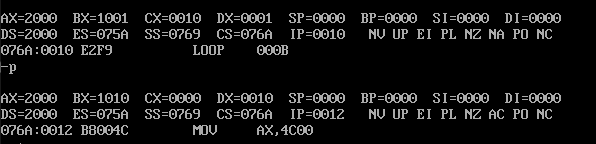
方法2:观察loop指令的下一条指令的位置是12,利用 -g 12,直接到了指令的下一条,它也就会自动执行了。
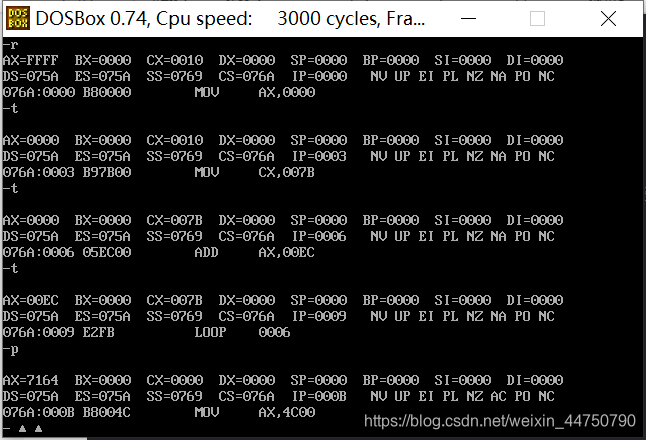
编程练习1:
计算 123*236的结果
assume cs:code
code segment
mov ax,0
mov cx,123;决定了loop指令的循环次数
addNumber: add ax,236
loop addNumber
mov ax,4C00H
int 21H
code ends
end
编程练习2:
用编程求 FFFF:0 到 FFFF:F字节型数据的和 结果存放在dx中。
assume cs:code
;阅读性 初始化 数据从哪里来 数据放到哪里去
code segment
mov ax,0FFFH
mov ds,ax ;先设置起始段地址寄存器的值
mov bx,0 ;设置偏移地址寄存器的值
mov dx,0;初始化,因为最终要存放在dx中
mov cx,16 ;设置循环次数F次即16次
mov ax,0 ;ah=0,al=读取的数据
addNumber: mov al,ds:[bx]
add dx,ax ;最终的结果要保存在dx中
inc bx
loop addNumber
code ends
end
编程练习3:
将内存 FFFF:0 - FFFF:F 内存单元中的数据复制到
0:200 - 0:20F中
代码1:利用一个栈将寄存器的地址存储起来
.386 ;告诉汇编程序按照 386 CPU指令系统进行汇编
assume cs:code
;阅读性 初始化 数据从哪里来 数据放到哪里去
;cpu 将 cs:ip 所指向的信息当做指令
;cpu 将 ss:sp 所指向的地址当做栈顶
;问题:如何将内存 FFFF:0 - FFFF:F 内存单元中的数据复制到 0:200 - 0:20F中?
code segment
start: mov ax,0FFFFH
mov ds,ax
mov bx,0 ;偏移地址
mov cx,16;要循环16次
setNumber: push ds
mov dl,ds:[bx]
mov ax,20H
mov ds,ax
mov ds:[bx],dl
inc bx
pop ds
loop setNumber
mov AH,4CH;程序结束后返回到dos命令状态,如果没有这指令则无法返回dos
int 21H
code ends
end start
代码2:利用两条修改指令不断修改段地址寄存器就可以了,可以不使用栈,因为第一种代码里边我们没有设置栈的大小,这是非常危险的。
assume cs:code
;阅读性 初始化 数据从哪里来 数据放到哪里去
;cpu 将 cs:ip 所指向的信息当做指令
;cpu 将 ss:sp 所指向的地址当做栈顶
;问题:如何将内存 FFFF:0 - FFFF:F 内存单元中的数据复制到 0:200 - 0:20F中?
code segment
start: mov bx,0 ;偏移地址
mov cx,16;要循环16次
setNumber: mov ax,0FFFFH
mov ds,ax
mov dl,ds:[bx]
mov ax,20H
mov ds,ax
mov ds:[bx],dl
inc bx
loop setNumber
mov AH,4CH;程序结束后返回到dos命令状态,如果没有这指令则无法返回dos
int 21H
code ends
end start
es寄存器器,和数据相关
ds代表 数据从哪里来 es 寄存器 代表数据到哪里去(可以自己安排,反过来也可以)
代码2中我们一直在不断修改段地址寄存器的地址,由 FFFF 修改为 200,又把 200 修改为 FFFF。这样其实是非常浪费内存的。
代码3:利用另外一个寄存器es,就再也不用一直去反复修改段地址寄存器的地址了。
assume cs:code
;阅读性 初始化 数据从哪里来 数据放到哪里去
;cpu 将 cs:ip 所指向的信息当做指令
;cpu 将 ss:sp 所指向的地址当做栈顶
;问题:如何将内存 FFFF:0 - FFFF:F 内存单元中的数据复制到 0:200 - 0:20F中?
code segment
start: mov bx,0 ;偏移地址
mov cx,16;要循环16次
mov ax,0FFFFH
mov ds,ax ;数据从哪里来
mov ax,20H
mov es,ax ;数据到哪里去
setNumber:
mov dl,ds:[bx]
mov es:[bx],dl
inc bx
loop setNumber
mov AH,4CH;程序结束后返回到dos命令状态,如果没有这指令则无法返回dos
int 21H
code ends
end start
代码四:这里是复制字节,而我们利用的寄存器都是字型数据,改进了这一点。比第三种方法效率提高了一倍。
code segment
start:
mov ax,0FFFFH
mov ds,ax ;数据从哪里来
mov ax,20H
mov es,ax ;数据到哪里去
mov bx,0 ;偏移地址
mov cx,8;要循环8次
setNumber:
mov dx,ds:[bx]
mov ex:[bx],dl
add bx,2
loop setNumber
mov AH,4CH;程序结束后返回到dos命令状态,如果没有这指令则无法返回dos
int 21H
code ends
end start
第5种:比第四种更快,连寄存器都节省下来了
code segment
start:
mov ax,0FFFFH
mov ds,ax ;数据从哪里来
mov ax,20H
mov es,ax ;数据到哪里去
mov bx,0 ;偏移地址
mov cx,8;要循环8次
setNumber:
push ds:[bx]
pop es:[bx]
add bx,2
loop setNumber
mov AH,4CH;程序结束后返回到dos命令状态,如果没有这指令则无法返回dos
int 21H
code ends
end start
结果:
以上五种代码都是可以的,同样也能完成以前相同的工作,具体的代码可以一步一步改进。

总结:很多代码你首先就要实现它的功能,然后再慢慢利用所学的知识去改进它,要去思考,才能会变得很强。
编程实验:向内存0:200-0:23F依次传送数据 0-63(3FH)字节型数据
代码1:
code segment
start:
mov ax,20H ;设置数据到哪里去
mov es,ax
mov cx,64 ;设置loop指令的循环次数
mov bx,0 ;
mov dl,0
setNumber: mov es:[bx],dl
inc bx
inc dl
loop setNumber
mov AX,4CH;程序结束后返回到dos命令状态,如果没有这指令则无法返回dos
int 21H
code ends
end start
代码2:要就包括下面的两行指令,只能使用九号指令(真正操作指令只能有7行),经过观察,可以发现我们有这么dl这两行是可以省略掉的。
code segment
start:
mov ax,20H ;设置数据到哪里去
mov es,ax
mov cx,64 ;设置loop指令的循环次数
mov bx,0 ;
setNumber: mov es:[bx],bx
inc bl
loop setNumber
mov AX,4CH;程序结束后返回到dos命令状态,如果没有这指令则无法返回dos
int 21H
code ends
end start
实验:代码迁移
问题:将mov ax,4CH之前的指令内容复制到 0:200 处
assume cs:code
;阅读性 初始化 数据从哪里来 数据放到哪里去
;cpu 将 cs:ip 所指向的信息当做指令
;cpu 将 ss:sp 所指向的地址当做栈顶
;问题:将mov ax,4CH之前的指令内容复制到 0:200 处
code segment
start:
mov ax,____ ;数据从哪里来
mov ds,ax
mov ax,0020H ;数据到哪里去
mov es,ax
mov bx,0
mov cs,____ ;要复制多少个字节
setNumber:
mov al,ds:[bx] ;每次复制一个字节
mov es:[bx],al
inc bx
loop setNumber
mov AX,4CH;程序结束后返回到dos命令状态,如果没有这指令则无法返回dos
int 21H
code ends
end start
思路:
1.数据应该从哪里来呢?
这里的代码,不久从cs来的吗,所以,第一个空填cs
注意:cpu 将 cs:ip 所指向的信息当做指令
2.根据下面每次是复制al,说明每次只是复制一个字节,我们就必须要知道,这个程序变异之后,到底有多少个字节。所以第二个空先填1(试探,然后找出正确结果)
看了一下,要求复制的最后一个指令的位置上是17(16进制的,也就是23(10进制的))。
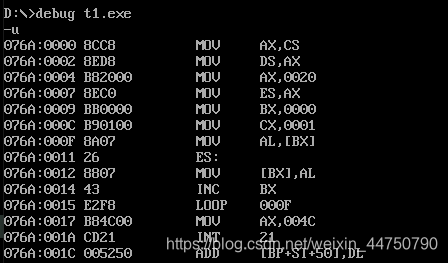
于是填上23.实验结果(虽然是笨办法,但是管用)。
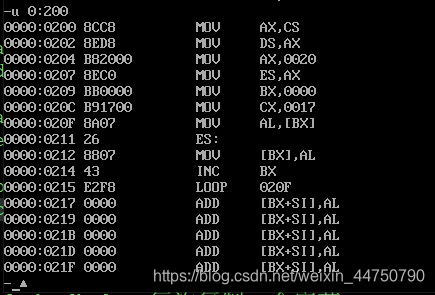
jmp 是无限次数的跳转
loop 是有限次数的跳转















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









