/*
Navicat Premium Data Transfer
Source Server : mylife
Source Server Type : MySQL
Source Server Version : 50528
Source Host : localhost:3306
Source Schema : test
Target Server Type : MySQL
Target Server Version : 50528
File Encoding : 65001
Date: 30/07/2021 10:31:25
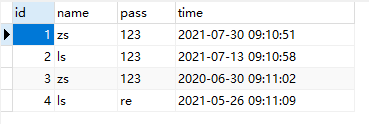
*/SET NAMES utf8mb4;SET FOREIGN_KEY_CHECKS =0;-- ------------------------------ Table structure for stu-- ----------------------------DROPTABLEIFEXISTS`stu`;CREATETABLE`stu`(`id`int(11)NOTNULLAUTO_INCREMENT,`name`varchar(255)CHARACTERSET utf8 COLLATE utf8_general_ci NULLDEFAULTNULL,`pass`varchar(255)CHARACTERSET utf8 COLLATE utf8_general_ci NULLDEFAULTNULL,`time`datetimeNULLDEFAULTNULL,PRIMARYKEY(`id`)USINGBTREE)ENGINE=InnoDBAUTO_INCREMENT=7CHARACTERSET= utf8 COLLATE= utf8_general_ci ROW_FORMAT = Compact;-- ------------------------------ Records of stu-- ----------------------------INSERTINTO`stu`VALUES(1,'zs','123','2021-07-30 09:10:51');INSERTINTO`stu`VALUES(2,'ls','123','2021-07-13 09:10:58');INSERTINTO`stu`VALUES(3,'zs','123','2020-06-30 09:11:02');INSERTINTO`stu`VALUES(4,'ls','re','2021-05-26 09:11:09');SET FOREIGN_KEY_CHECKS =1;
SQL语句
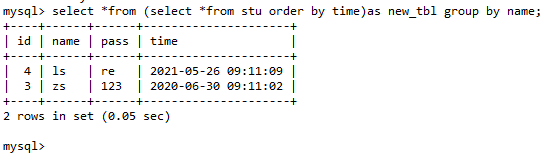
select*from(select*from stu orderbytime)as new_tbl
groupby name;







 此篇博客介绍了如何使用SQL语句从stu表中按时间顺序排列并按姓名分组,展示了数据筛选和聚合的基本操作。
此篇博客介绍了如何使用SQL语句从stu表中按时间顺序排列并按姓名分组,展示了数据筛选和聚合的基本操作。


















 1689
1689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











