






学习目标:
-
室内定位可视化界面(上一篇室内定位讲解了算法)
-
室内定位模型的加载以及使用
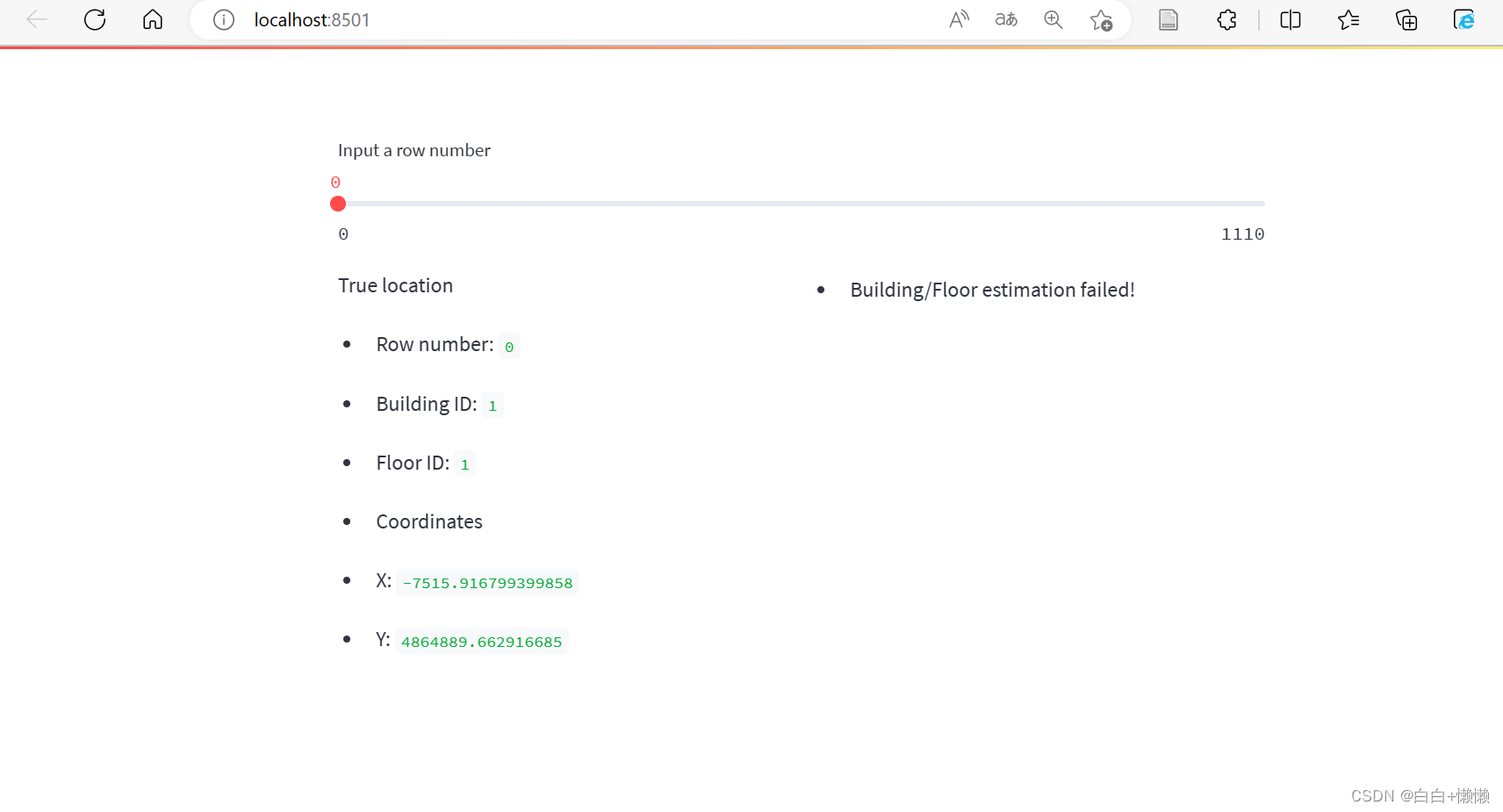
最终的可视化界面如下图所示:
测试数据预处理:
- 首先定义后面使用的变量、常量
path_train = 'G:/PycharmProjects/Apostgraduate/indoor_localization/data/trainingData2.csv' # '-110' for the lack of AP.
path_validation = 'G:/PycharmProjects/Apostgraduate/indoor_localization/data/validationData2.csv' # ditto
path_model = 'G:/PycharmProjects/Apostgraduate/indoor_localization/my_model_1/sae_model.hdf5'
N = 8
scaling = 0.2
training_ratio = 0.9
- 读取训练和测试数据帧,通独热编码形成一致的标签
train_df = pd.read_csv(path_train, header=0) # pass header=0 to be able to replace existing names
test_df = pd.read_csv(path_validation, header=0)
# print(train_df)
# print(test_df)
train_AP_features = scale(np.asarray(train_df.iloc[:,0:520]).astype(float), axis=1) # convert integer to float and scale jointly (axis=1)
train_df['REFPOINT'] = train_df.apply(lambda row: str(int(row['SPACEID'])) + str(int(row['RELATIVEPOSITION'])), axis=1) # add a new column
blds = np.unique(train_df[['BUILDINGID']])
flrs = np.unique(train_df[['FLOOR']])
- 将参考点映射到每个建筑物楼层的高度,并计算每个建筑物/楼层的平均坐标
x_avg = {}
y_avg = {}
for bld in blds:
for flr in flrs:
# map reference points to sequential IDs per building-floor before building labels(在建筑物标签之前,将参考点映射到每个建筑物楼层的顺序ID)
cond = (train_df['BUILDINGID']==bld) & (train_df['FLOOR']==flr)
_, idx = np.unique(train_df.loc[cond, 'REFPOINT'], return_inverse=True) # refer to numpy.unique manual
train_df.loc[cond, 'REFPOINT'] = idx
# calculate the average coordinates of each building/floor(计算每个建筑物/楼层的平均坐标)
x_avg[str(bld) + '-' + str(flr)] = np.mean(train_df.loc[cond, 'LONGITUDE'])
y_avg[str(bld) + '-' + str(flr)] = np.mean(train_df.loc[cond, 'LATITUDE'])
- 该数据属于多分类,为该多分类构建标签
len_train = len(train_df)
blds_all = np.asarray(pd.get_dummies(pd.concat([train_df['BUILDINGID'], test_df['BUILDINGID']]))) # for consistency in one-hot encoding for both dataframes
flrs_all = np.asarray(pd.get_dummies(pd.concat([train_df['FLOOR'], test_df['FLOOR']]))) # ditto
blds = blds_all[:len_train]
flrs = flrs_all[:len_train]
rfps = np.asarray(pd.get_dummies(train_df['REFPOINT']))
train_labels = np.concatenate((blds, flrs, rfps), axis=1)
位置预测:
- 加载模型(上一篇训练好的SAE编码器)
model = load_model(path_model)
- 将给定的验证集转换为测试集
test_AP_features = scale(np.asarray(test_df.iloc[:,0:520]).astype(float), axis=1) # convert integer to float and scale jointly (axis=1)
x_test_utm = np.asarray(test_df['LONGITUDE'])
y_test_utm = np.asarray(test_df['LATITUDE'])
blds = blds_all[len_train:]
flrs = flrs_all[len_train:]
n_rows = test_df.shape[0]
row_number = st.slider('Input a row number', min_value=0, max_value=n_rows-1)
# row_number = st.number_input('Input a row number', min_value=0, max_value=n_rows-1)
test_row = test_df.iloc[[row_number]]
test_rss = test_AP_features[[row_number]]
preds = model(test_rss, training=False)[0].numpy()
- 正确估计建筑物和楼层时计算定位误差
x = 0.0
x_weighted = 0.0
y = 0.0
y_weighted = 0.0
pos_err = -1.0 # initial value as an indicator of no processing
pos_err_weighted = -1.0 # ditto
if test_row['BUILDINGID'].values[0] == np.argmax(preds[:3]) and test_row['FLOOR'].values[0] == np.argmax(preds[3:8]):
x_test_utm = x_test_utm[row_number]
y_test_utm = y_test_utm[row_number]
blds = blds[row_number]
flrs = flrs[row_number]
rfps = preds[8:118]
idxs = np.argpartition(rfps, -N)[-N:] # (unsorted) indexes of up to N nearest neighbors
threshold = scaling*np.amax(rfps)
xs = []
ys = []
ws = []
for i in idxs:
rfp = np.zeros(110)
rfp[i] = 1
rows = np.where((train_labels == np.concatenate((blds, flrs, rfp))).all(axis=1))[0]
if rows.size > 0:
if rfps[i] >= threshold:
xs.append(train_df.loc[train_df.index[rows[0]], 'LONGITUDE'])
ys.append(train_df.loc[train_df.index[rows[0]], 'LATITUDE'])
ws.append(rfps[i])
if len(xs) > 0:
x = np.mean(xs)
y = np.mean(ys)
pos_err = math.sqrt((x-x_test_utm)**2 + (y-y_test_utm)**2)
x_weighted = np.average(xs, weights=ws)
y_weighted = np.average(ys, weights=ws)
pos_err_weighted = math.sqrt((x_weighted-x_test_utm)**2 + (y_weighted-y_test_utm)**2)
else:
key = str(np.argmax(blds)) + '-' + str(np.argmax(flrs))
x = x_weighted = x_avg[key]
y = y_weighted = y_avg[key]
pos_err = pos_err_weighted = math.sqrt((x-x_test_utm)**2 + (y-y_test_utm)**2)
### display input and output
col1, col2 = st.columns(2)
到此为止,室内定位从数据处理到最终的可视化工作全部完成!















 746
746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









