Ceph节点安装
预检
我们建议安装一个 ceph-deploy 管理节点和一个三节点的Ceph 存储集群来研究 Ceph 的基本特性。这篇预检会帮你准备一个 ceph-deploy 管理节点、以及三个Ceph 节点(或虚拟机),以此构成 Ceph 存储集群。在进行下一步之前,请参见操作系统推荐以确认你安装了合适的 Linux 发行版。如果你在整个生产集群中只部署了单一 Linux 发行版的同一版本,那么在排查生产环境中遇到的问题时就会容易一点。
在下面的描述中节点代表一台机器。

| 主机名 | 角色 | 系统 | IP | 备注 |
| node1 | mon.node1 | CentOS7.5 | 192.168.1.101 | |
| node2 | osd.0 | CentOS7.5 | 192.168.1.102 | osd节点需配置数据盘
例如/dev/sdb |
| node3 | ods.1 | CentOS7.5 | 192.168.1.103 | osd节点需要配置数据盘 例如/dev/sdb |
| admin-node | ceph-deploy | CentOS7.5 | 192.168.1.104 | |
安装ceph部署工具
在节点admin-node 部署
设置yum源
设置国内阿里源(node1 node2 node3设置yum源和admin-node一致)
如果需要设置其他版本可以查看阿里云开源镜像站资源目录
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | [root@admin-node ~]#cat /etc/yum.repos.d/ceph.repo
[ceph]
name=ceph
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/x86_64/
enabled=1
gpgcheck=0
priority=1
[ceph-noarch]
name=cephnoarch
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch/
enabled=1
gpgcheck=0
priority=1
[ceph-source]
name=Ceph source packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/SRPMS
enabled=1
gpgcheck=0
priority=1
|
更新仓库安装ceph-deploy
| 1 | sudo yum update -y && sudo yum install ceph-deploy -y
|
Ceph节点安装
你的管理节点必须能够通过 SSH 无密码地访问各 Ceph 节点。如果 ceph-deploy 以某个普通用户登录,那么这个用户必须有无密码使用 sudo 的权限。
设置NTP同步(所有主机执行)
安装NTP
Ceph集群对时间一致要求很高,需要设置ntp时间同步
时间同步
| 1 | ntpdate time1.aliyun.com
|
设置在定时任务crontab执行时间同步
| 1 2 3 | crontab -e
#添加一下内容
*/5 * * * * /usr/sbin/ntpdate time1.aliyun.com
|
设置管理节点免密登录ceph节点
生成密钥对
把公钥拷贝至各ceph的node节点
使用主机名拷贝需要事先设置好主机hosts
| 1 2 3 | ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
|
关闭firewalld和senlinux
存储集群快速入门
如果你还没完成预检,请先做完。本篇快速入门用 ceph-deploy 从管理节点建立一个 Ceph 存储集群,该集群包含三个节点,以此探索 Ceph 的功能。

第一次练习时,我们创建一个 Ceph 存储集群,它有一个 Monitor 和两个 OSD 守护进程。一旦集群达到 active + clean 状态,再扩展它:增加第三个 OSD 、增加元数据服务器和两个 Ceph Monitors。为获得最佳体验,先在管理节点上创建一个目录,用于保存 ceph-deploy 生成的配置文件和密钥对。
| 1 2 | mkdir my-cluster
cd my-cluster/
|
创建集群
如果在某些地方碰到麻烦,想从头再来,可以用下列命令清除配置:
| 1 2 | ceph-deploy purgedata {ceph-node} [{ceph-node}]#清除ceph数据
ceph-deploy forgetkeys #清除key
|
用下列命令可以连 Ceph 安装包一起清除:
| 1 | ceph-deploy purge {ceph-node} [{ceph-node}]
|
如果执行了 purge ,你必须重新安装 Ceph。
在管理节点上,进入刚创建的放置配置文件的目录,用 ceph-deploy 执行如下步骤。
1,创建集群
| 1 | ceph-deploy new {initial-monitor-node(s)}
|
例如
在当前目录下用 ls 和 cat 检查 ceph-deploy 的输出,应该有一个 Ceph 配置文件、一个 monitor 密钥环和一个日志文件。
2,把 Ceph 配置文件里的默认副本数从 3 改成 2 ,这样只有两个 OSD 也可以达到 active + clean 状态。把下面这行加入 [global] 段:
| 1 | osd pool default size = 2
|
3,如果你有多个网卡,可以把 public network 写入 Ceph 配置文件的 [global] 段下。
| 1 | public network = {ip-address}/{netmask}
|
类似于192.168.1.0/24
4,安装Ceph
| 1 | ceph-deploy install {ceph-node} [{ceph-node} ...]
|
例如
| 1 | ceph-deploy install admin-node node1 node2 node3
|
ceph-deploy 将在各节点安装 Ceph 。 注:如果你执行过 ceph-deploy purge ,你必须重新执行这一步来安装 Ceph 。
执行该步骤会分别连接对应客户端安装ceph,ceph-radosgw会在对应客户端下载yum源文件
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | # cat /etc/yum.repos.d/ceph.repo
[Ceph]
name=Ceph packages for $basearch
baseurl=http://download.ceph.com/rpm-mimic/el7/$basearch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
priority=1
[Ceph-noarch]
name=Ceph noarch packages
baseurl=http://download.ceph.com/rpm-mimic/el7/noarch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
priority=1
[ceph-source]
name=Ceph source packages
baseurl=http://download.ceph.com/rpm-mimic/el7/SRPMS
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
priority=1
|
注意:使用admin节点给客户端安装ceph速度较慢,如果客户端网络好可以直接设置好yum源安装
| 1 | yum -y update && yum -y install ceph ceph-radosgw
|
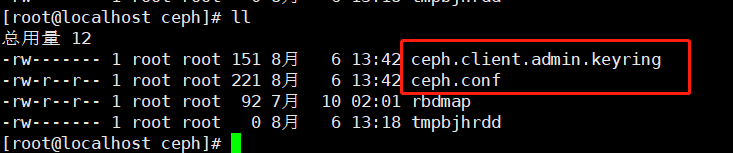
会在各个安装的节点创建目录
目录下有一个文件
| 1 2 3 | [root@localhost ceph]# cat rbdmap
# RbdDevice Parameters
#poolname/imagename id=client,keyring=/etc/ceph/ceph.client.keyring
|
安装好以后使用命令查看版本
| 1 2 | # ceph -v
ceph version 14.2.10 (b340acf629a010a74d90da5782a2c5fe0b54ac20) nautilus (stable)
|
5,配置初始 monitor(s)、并收集所有密钥:
| 1 | ceph-deploy mon create-initial
|
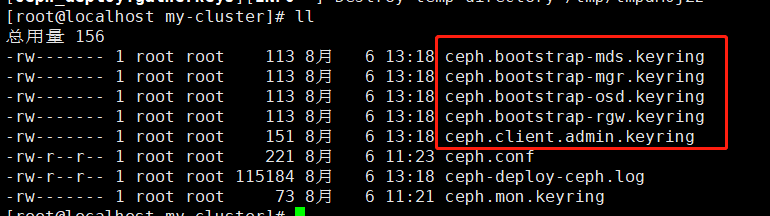
完成上述操作后,当前目录里应该会出现这些密钥环:
| 1 2 3 4 | {cluster-name}.client.admin.keyring
{cluster-name}.bootstrap-osd.keyring
{cluster-name}.bootstrap-mds.keyring
{cluster-name}.bootstrap-rgw.keyring
|
添加OSD
1,添加两个 OSD 。
| 1 | ceph-deploy osd create --data {dev} {node_name}
|
例如
| 1 2 | ceph-deploy osd create --data /dev/sdb node2
ceph-deploy osd create --data /dev/sdb node3
|
2,用 ceph-deploy 把配置文件和 admin 密钥拷贝到管理节点和 Ceph 节点,这样你每次执行 Ceph 命令行时就无需指定 monitor 和 ceph.client.admin.keyring 了。
| 1 | ceph-deploy admin {admin-node} {ceph-node}
|
例如
| 1 | ceph-deploy admin admin-node node1 node2 node3
|
会修改对应node的配置文件以及添加key
3,检查集群健康状态
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | [root@admin-node my-cluster]# ceph -s
cluster:
id: 8dc0f409-70c1-4499-94a9-466abdf4f30d
health: HEALTH_WARN
no active mgr
services:
mon: 1 daemons, quorum node1 (age 29m)
mgr: no daemons active
osd: 2 osds: 2 up (since 7m), 2 in (since 7m)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
|
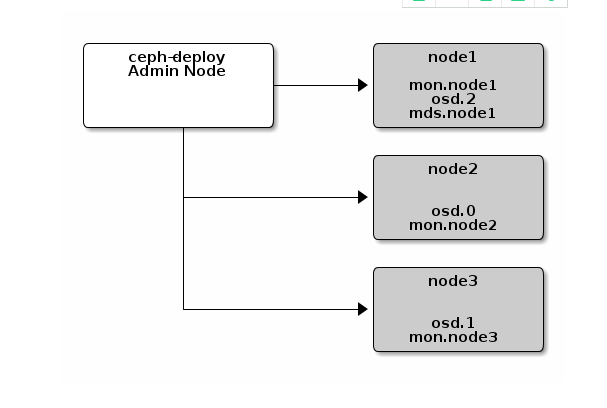
扩展集群
一个基本的集群启动并开始运行后,下一步就是扩展集群。在 node1 上添加一个 OSD 守护进程和一个元数据服务器。然后分别在 node2 和 node3 上添加 Ceph Monitor ,以形成 Monitors 的法定人数。
扩展前
扩展后
添加OSd
你运行的三个节点集群只是用于演示,把OSD添加到monitor节点就行
添加前查看

添加OSD
| 1 | ceph-deploy osd create --data /dev/sdb node1
|
添加后查看

添加元数据服务器
至少需要一个元数据服务器才能使用 CephFS ,执行下列命令创建元数据服务器:
| 1 | ceph-deploy mds create {ceph-node}
|
例如
| 1 | ceph-deploy mds create node1
|
查看
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | [root@admin-node my-cluster]# ceph -s
cluster:
id: 8dc0f409-70c1-4499-94a9-466abdf4f30d
health: HEALTH_WARN
no active mgr
services:
mon: 1 daemons, quorum node1 (age 2h)
mgr: no daemons active
mds: 1 up:standby #新建的mds服务
osd: 3 osds: 3 up (since 12m), 3 in (since 12m)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
|
| 1 | Note 当前生产环境下的 Ceph 只能运行一个元数据服务器。你可以配置多个,但现在我们还不会为多个元数据服务器的集群提供商业支持。
|
添加 RGW 例程
要使用 Ceph 的 Ceph 对象网关组件,必须部署 RGW 例程。用下列方法创建新 RGW 例程:
| 1 | ceph-deploy rgw create {gateway-node}
|
例如
| 1 | ceph-deploy rgw create node1
|
对应客户端运行ceph-radosgw@rgw.node1
RGW 例程默认会监听 7480 端口,可以更改该节点 ceph.conf 内与 RGW 相关的配置,如下:
| 1 2 | [client]
rgw frontends = civetweb port=80
|
添加 MONITORS
Ceph 存储集群需要至少一个 Monitor 才能运行。为达到高可用,典型的 Ceph 存储集群会运行多个 Monitors,这样在单个 Monitor 失败时不会影响 Ceph 存储集群的可用性。Ceph 使用 PASOX 算法,此算法要求有多半 monitors(即 1 、 2:3 、 3:4 、 3:5 、 4:6 等 )形成法定人数。
新增两个监视器到 Ceph 集群。
| 1 | ceph-deploy mon add {ceph-node}
|
例如:原有一个mon现在增加两个mon
| 1 2 | ceph-deploy mon add node2
ceph-deploy mon add node3
|
注意:需要在ceph.conf有[global]下有配置
| 1 | public network = 192.168.1.0/24
|
并且同步配置
| 1 | ceph-deploy --overwrite-conf admin admin-node node1 node2 node3
|
新增 Monitor 后,Ceph 会自动开始同步并形成法定人数。你可以用下面的命令检查法定人数状态:
| 1 | Tip 当你的 Ceph 集群运行着多个 monitor 时,各 monitor 主机上都应该配置 NTP ,而且要确保这些 monitor 位于 NTP 服务的同一级。
|
查看
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | [root@admin-node my-cluster]# ceph -s
cluster:
id: 8dc0f409-70c1-4499-94a9-466abdf4f30d
health: HEALTH_WARN
no active mgr
services:
mon: 3 daemons, quorum node1,node2,node3 (age 3m) #3个mon
mgr: no daemons active
mds: 1 up:standby
osd: 3 osds: 3 up (since 41m), 3 in (since 41m)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
|























 3920
3920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









