







演示程序截图
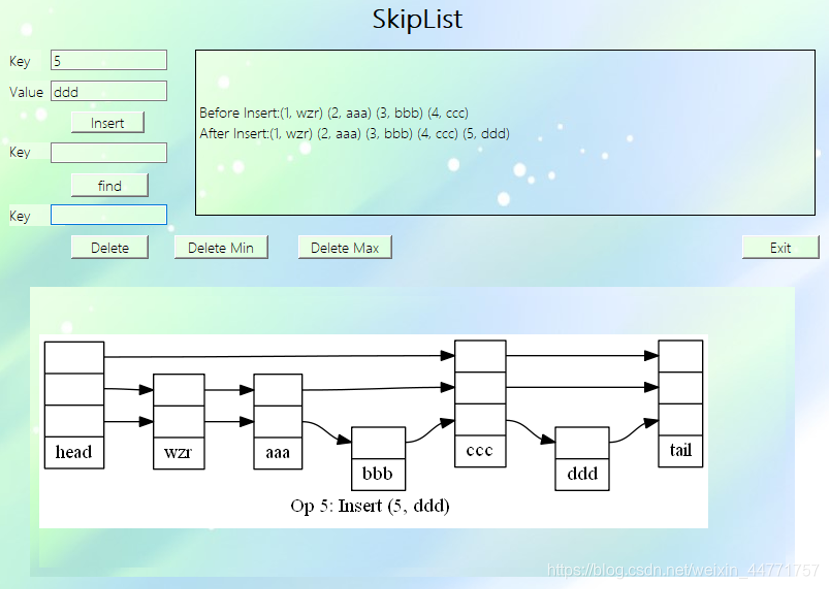
实现功能
- 跳表初始化
- 跳表的查找操作
- 跳表的插入操作
- 跳表的删除操作(指定关键字的元素、关键字最小的元素、关键字最大的元素)
- 跳表可视化
程序结构设计
- 初始化模块:void Initialization(int n);
- 查找模块:void find(const K&);
- 插入模块:void insert(const pair<const K, E>&);
- 删除模块:
- 指定关键字的元素:void erase(const K&);
- 关键字最小的元素:void eraseMin();
- 关键字最大的元素:void eraseMax();
- 可视化模块:void visualition(string ¬es,int operation);
设计思路
- 初始化模块:void Initialization(int n);
输入n代表初始化跳表时所插入的节点个数,然后调用insert函数执行插入操作。 - 查找模块:void find(const K&);
首先判断关键字是否大于尾节点的关键字若大于则无匹配的数对,否则以头节点为起始节点,从最高级链表开始查找,若节点关键字小于要查找的关键字则节点右移,直到0级链表,最后检查节点的关键字是否匹配,若匹配则查找成功,否则查找失败。 - 插入模块:void insert(const pair<const K, E>&);
首先判断插入数对的关键字是否大于尾节点的关键字若大于则无法插入,否则要进行搜索来定位插入位置并把每一级链表搜索时所遇到的最后一个节点指针存储进last数组,若关键字相同则更新节点数据,不同则先确定新节点所在的级链表,然后在所定位的插入位置插入新节点,最后更新跳表的节点个数。 - 删除模块:
- 指定关键字的元素:void erase(const K&);
首先判断关键字是否大于尾节点的关键字若大于则无匹配的数对,否则要查找是否存在匹配数对,若无匹配数对则删除失败退出,有匹配数对则删除该节点并更新链表级,最后释放节点空间并更新跳表的节点个数。 - 关键字最小的元素:void eraseMin();
首先判断跳表是否为空,为空则退出,否则删除头节点之后的第一个节点,删除结束后要更新链表级,最后释放节点空间并更新跳表的节点个数。 - 关键字最大的元素:void eraseMax();
首先判断跳表是否为空,为空则退出,否则要通过搜索跳表来定位删除节点的位置,然后删除节点并更新链表级,最后释放节点空间并更新跳表的节点个数。
- 指定关键字的元素:void erase(const K&);
- 可视化模块:void visualition(string ¬es,int operation);
该模块使用了Graphviz开源工具包,通过C++程序将各节点的信息以及连接情况写入dot文件,然后通过命令行进行编译并输出图片。
分析与探讨
-
各基本操作的时间复杂性分析
如果只粗略地估算一下的话,由于跳表的级数上限 m a x L e v e l = ⌈ l o g 1 / p N ⌉ − 1 maxLevel=\lceil log_{1/p}N\rceil-1 maxLevel=⌈log1/pN⌉−1,(其中 p p p 为 i − 1 i-1 i−1 级链表的数对个数与 i i i级链表的数对个数之比,这本次实验中 p p p 取 0.5 0.5 0.5 )且按关键字查询操作是从最高级链表开始查找,直到第 0 0 0 级链表且每层遍历的元素个数为常数级别,故查找操作的时间复杂度为 O ( l o g n ) O(logn) O(logn),而插入和删除操作中更新级数的操作时间复杂度也为 O ( l o g n ) O(logn) O(logn),所以跳表的各基本操作的时间复杂度均为 O ( l o g n ) O(logn) O(logn)。下面再梳理一下参考论文(Skip Lists: A Probabilistic Alternative to Balanced Trees) 中给出的较为严谨的推导过程:- 首先求出每个节点的平均级数:由于节点的级数是依据概率随机分配的,所以一个节点的平均级数为 ( 1 − p ) ∑ k = 1 k p k − 1 = 1 / ( 1 − p ) (1-p)\sum_{k=1}kp^{k-1}=1/(1-p) (1−p)∑k=1kpk−1=1/(1−p)
- 计算平均查找长度:论文中将查找过程进行逆向计算,假设从一个级数为 i i i 的节点出发,需要向左上移动 k k k级,用 C ( k ) C(k) C(k)表示向上移动 k k k级所需走过的平均路径长度则 C ( k ) = 1 / p + C ( k − 1 ) C(k)=1/p+C(k-1) C(k)=1/p+C(k−1),计算化简得 C ( k ) = k / p C(k)=k/p C(k)=k/p,所以查找过程中,总共需要移动的级数为跳表的 总 级 数 − 1 总级数-1 总级数−1。因为总层数的均值为 l o g 1 / p n log_{1/p}n log1/pn,最高级的平均结点数为 1 / p 1/p 1/p 所以平均查找长度为 ( l o g 1 / p n − 1 ) / p (log_{1/p}n-1)/p (log1/pn−1)/p,故平均时间复杂度为 O ( l o g n ) O(logn) O(logn)。
-
跳表空间复杂性分析
一般情况下, i i i 级链表有 n / 2 i n/2^i n/2i 个数对即存储 n / 2 i n/2^i n/2i 个指针空间,所以跳表的平均空间需求为 n ∑ i = 1 n 1 / 2 i = 2 n n\sum_{i=1}^{n}1/2^i=2n n∑i=1n1/2i=2n -
跳表维护动态数据集合的效率问题
利用随机数产生规模分别为1000、5000、10000、50000、100000的测试数据,由于各操作的平均时间较短,故采用QueryPerformanceFrequency(),QueryPerformanceCounter()函数以较高的精度来记录操作的时间,实验结果如下:
查找
| n | 1000 | 5000 | 10000 | 50000 | 100000 |
|---|---|---|---|---|---|
| t/(ms) | 0.000304494 | 0.000513333 | 0.000413000 | 0.000555000 | 0.000691000 |
插入
| n | 1000 | 5000 | 10000 | 50000 | 100000 |
|---|---|---|---|---|---|
| t/(ms) | 0.000587234 | 0.000688710 | 0.000788500 | 0.000909800 | 0.001060800 |
删除
| n | 1000 | 5000 | 10000 | 50000 | 100000 |
|---|---|---|---|---|---|
| t/(ms) | 0.000375000 | 0.000484783 | 0.000475000 | 0.000552530 | 0.000612831 |
为了对比跳表查找效率与普通线性结构,又记录了普通一维数组的操作时间,实验结果如下:
查找
| n | 1000 | 5000 | 10000 | 50000 | 100000 |
|---|---|---|---|---|---|
| t/(ms) | 0.001255000 | 0.005395000 | 0.008828000 | 0.032137000 | 0.075318000 |
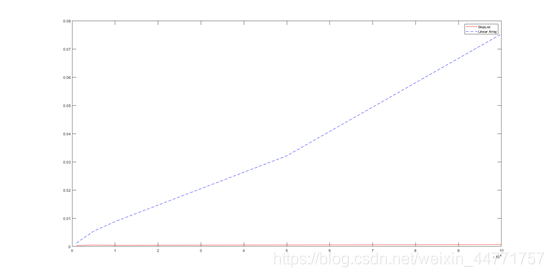
由上图的对比可以看出,在数据规模较大的情况下,跳表的查找效率远远优于普通的线性查找,跳表优异的查找效率以及构造的简易性使得它广泛应用于实际生产中的数据检索领域。当然,跳表的查询效率还可以再优化,优化方案是为每个节点添加一个指向前继节点的指针进行双向搜索,虽然搜索效率加快了,但同时也提高了空间复杂度以及维护跳表结构的难度,在实际生活中单向跳表已可满足大部分的应用需求。
代码实现
核心代码如下
template <class K, class E>
struct skipNode
{
typedef pair<const K, E> pairType;
pairType element; //节点元素
int NodeSize; //级数 (后续作图使用)
int id; //编号(后续作图使用)
skipNode<K,E> **next; //指针数组
//构造函数
skipNode(const pairType& thePair, int size)
:element(thePair),NodeSize(size){next = new skipNode<K,E>* [size];}
};
//跳表类
template<class K, class E>
class skipList
{
public:
//构造函数
skipList(K, int maxPairs = 10000, float prob = 0.5);
//析构函数
~skipList();
//判断跳表是否为空
bool empty() const {return dSize == 0;}
//跳表节点个数
int size() const {return dSize;}
//跳表初始化
void Initialization(int n);
//关键字查询
string find(const K&);
//按关键字删除
void erase(const K&);
//删除关键字最小的元素
void eraseMin();
//删除关键字最大的元素
void eraseMax();
//插入节点
void insert(const pair<const K, E>&);
//输出跳表第0级
void output(ostream& out) const;
//跳表可视化
void visualition(string ¬es,int operation);
void OutputToString(string &s);
protected:
float cutOff; //用来确定层数
int level() const; //分配级数
int levels; //当前最大级数
int dSize; //字典的数对个数
int maxLevel; //允许的最大级数
K tailKey; //最大关键字
skipNode<K,E>* search(const K&) const; //搜索并把每一级链表搜索时所遇到的最后一个节点指针存储起来
skipNode<K,E>* headerNode; //头节点指针
skipNode<K,E>* tailNode; //尾节点指针
skipNode<K,E>** last; //存储每一级搜索过程中遇到的最后一个指针
};
//构造函数:
//largeKey:大于字典的任何数对的关键字,存储在尾节点
//maxPairs:字典数对个数的最大值
//prob:i-1级链表数对同时也是i级链表数对的概率
template<class K, class E>
skipList<K,E>::skipList(K largeKey, int maxPairs, float prob)
{
//数据成员初始化
cutOff = prob * RAND_MAX;
maxLevel = (int) ceil(logf((float) maxPairs) / logf(1/prob)) - 1;
levels = 0;
dSize = 0;
tailKey = largeKey;
//生成头节点、尾节点、last数组
pair<K,E> tailPair;
tailPair.first = tailKey;
headerNode = new skipNode<K,E> (tailPair, maxLevel + 1);
tailNode = new skipNode<K,E> (tailPair, 0);
last = new skipNode<K,E> *[maxLevel+1];
//初始链表为空,任意级链表中的头节点都指向尾节点
for (int i = 0; i <= maxLevel; i++)
headerNode->next[i] = tailNode;
}
//析构函数
template<class K, class E>
skipList<K,E>::~skipList()
{
skipNode<K,E> *nextNode;
//释放所有跳表节点的空间
while (headerNode != tailNode)
{
nextNode = headerNode->next[0];
delete headerNode;
headerNode = nextNode;
}
delete tailNode;
//释放last数组的空间
delete [] last;
}
//int转string
void AppendInt(string &s,int &a){
char buf[10];
itoa(a,buf,10);
s+=buf;
}
//跳表可视化
//notes:所执行的操作
//operation: 操作次序
template <class K, class E>
void skipList<K,E>::visualition(string ¬es,int operation)
{
freopen("graph.dot","w",stdout);
//重定向输出流到dot文件
//dot语言作图
cout<<"digraph G{"<<endl;
//图像标题
cout<<"label=\"";
cout<<notes;
cout<<"\";"<<endl;
//图像分布
cout<<"rankdir=LR;"<<endl;
//节点形状
cout<<"node [shape=record,width=.1,height=.1];"<<endl;
//声明头节点与尾节点
string s="[label=\"";
for(int i=levels;i>=0;i--){
s+="<";
AppendInt(s,i);
s+=">";
s+="|";
}
string head,tail;
head=s+"head\"]";
tail=s+"tail\"]";
cout<<"0"<<head<<";"<<endl;
cout<<dSize+1<<tail<<";"<<endl;
//声明其余节点
skipNode<K,E>* beforeNode = headerNode->next[0];
int no=1;
headerNode->id=0;
//对每个节点进行标号
while(beforeNode!=tailNode){
beforeNode->id=no;
no++;
beforeNode=beforeNode->next[0];
}
tailNode->id=no;
beforeNode = headerNode->next[0];
//声明除头节点、尾节点外的节点
while(beforeNode!=tailNode){
int l=beforeNode->NodeSize;
l--;
int NodeID=beforeNode->id;
string node="";
AppendInt(node,NodeID);
string s="[label=\"";
for(int i=l;i>=0;i--){
s+="<";
AppendInt(s,i);
s+=">";
s+="|";
}
s+=beforeNode->element.second;
s+="\"]";
node+=s;
cout<<node<<endl;
beforeNode=beforeNode->next[0];
}
//连接各级节点
for(int i=levels;i>=0;i--){
beforeNode=headerNode;
while(beforeNode!=tailNode){
int NodeID1=beforeNode->id;
string link="";
AppendInt(link,NodeID1);
link+=":";
AppendInt(link,i);
link+="->";
beforeNode=beforeNode->next[i];
int NodeID2=beforeNode->id;
AppendInt(link,NodeID2);
link+=":";
AppendInt(link,i);
cout<<link<<endl;
}
}
cout<<"}"<<endl;
//命令行输出图片
s = "";
s += "dot -Tpng ";
s += "graph.dot";
s += " -o ";
AppendInt(s,operation);
s+=".png";
const char* cmd = s.data();
system(cmd);
}
//按关键字查询
template<class K, class E>
string skipList<K,E>::find(const K& theKey)
{
string p;
//关键字大于尾节点的关键字则无匹配数对,退出
if (theKey > tailKey){
p="Error";
return p;
}
//从最高级链表开始查找,从左边尽可能逼近要查找的节点,直到0级链表
skipNode<K,E>* beforeNode = headerNode;
for (int i = levels; i >= 0; i--)
while (beforeNode->next[i]->element.first < theKey)
beforeNode = beforeNode->next[i];
//检查节点的关键字是否为theKey
if (beforeNode->next[0]->element.first == theKey){
p=beforeNode->next[0]->element.second;
return p;
}
//无匹配数对
p="Error";
return p;
}
//级的分配方法
template<class K, class E>
int skipList<K,E>::level() const
{
//返回一个表示链表级的随机数,这个数不大于maxLevel
int lev = 0;
while (rand() <= cutOff)
lev++;
return (lev <= maxLevel) ? lev : maxLevel;
}
//搜索并把每一级链表搜索时所遇到的最后一个节点指针存储起来
template<class K, class E>
skipNode<K,E>* skipList<K,E>::search(const K& theKey) const
{
//beforeNode是关键字为theKey的节点之前最右边的节点
skipNode<K,E>* beforeNode = headerNode;
for (int i = levels; i >= 0; i--)
{
while (beforeNode->next[i]->element.first < theKey)
beforeNode = beforeNode->next[i];
last[i] = beforeNode; //最后一级链表i的节点
}
return beforeNode->next[0];
}
//跳表插入
template<class K, class E>
void skipList<K,E>::insert(const pair<const K, E>& thePair)
{
//关键字太大
if (thePair.first > tailKey)
{
ostringstream s;
s << "Key = " << thePair.first << " Must be < " << tailKey;
exit(0);
}
//搜索节点位置
skipNode<K,E>* theNode = search(thePair.first);
//查看关键字为theKey的数对是否已经存在
if (theNode->element.first == thePair.first)
{
theNode->element.second = thePair.second;
return;
}
//确定新节点所在的级链表
int theLevel = level();
//使theLevel<=levels+1
if (theLevel > levels)
{
theLevel = ++levels;
last[theLevel] = headerNode;
}
//在节点theNode之后插入新节点
skipNode<K,E>* newNode = new skipNode<K,E>(thePair, theLevel + 1);
for (int i = 0; i <= theLevel; i++)
{
//插入i级链表
newNode->next[i] = last[i]->next[i];
last[i]->next[i] = newNode;
}
//更新跳表节点个数
dSize++;
return;
}
//跳表初始化
template<class K, class E>
void skipList<K,E>::Initialization(int n)
{
pair<int, string> p;
while(n--){
cin>>p.first>>p.second;
insert(p);
}
}
//按关键字删除节点
template<class K, class E>
void skipList<K,E>::erase(const K& theKey)
{
//关键字太大无匹配
if (theKey > tailKey){
cout<<-1<<endl;
return;
}
//查找是否有匹配的数对
skipNode<K,E>* theNode = search(theKey);
//无匹配则退出
if (theNode->element.first != theKey){
cout<<-1<<endl;
return;
}
cout<<theNode->element.first<<" "<<theNode->element.second<<endl;
//从跳表中删除节点
for (int i = 0; i <= levels &&last[i]->next[i] == theNode; i++)
last[i]->next[i] = theNode->next[i];
//更新链表级
while (levels > 0 && headerNode->next[levels] == tailNode)
levels--;
//释放节点空间
delete theNode;
//更新跳表节点个数
dSize--;
}
//删除最小关键字节点
template<class K, class E>
void skipList<K,E>::eraseMin()
{
//跳表为空,退出
if(headerNode->next[0]==tailNode){
return;
}
//删除节点
skipNode<K,E>* theNode=headerNode->next[0];
cout<<theNode->element.first<<" "<<theNode->element.second<<endl;
for (int i = 0; i <= levels&&headerNode->next[i]==theNode;i++)
headerNode->next[i] = theNode->next[i];
//更新链表级
while (levels > 0 && headerNode->next[levels] == tailNode)
levels--;
//释放节点空间
delete theNode;
//更新跳表节点个数
dSize--;
}
//删除最大关键字节点
template<class K, class E>
void skipList<K,E>::eraseMax()
{
//跳表为空,退出
if(headerNode->next[0]==tailNode){
return;
}
//定位删除节点的位置
skipNode<K,E>* beforeNode=headerNode;
for (int i = levels; i >= 0; i--)
{
if(beforeNode->next[i]==tailNode)
continue;
while (beforeNode->next[i]->next[i]!=tailNode)
beforeNode = beforeNode->next[i];
last[i] = beforeNode;
}
skipNode<K,E>* theNode=beforeNode->next[0];
cout<<theNode->element.first<<" "<<theNode->element.second<<endl;
//删除节点
for (int i = 0; i <= levels &&
last[i]->next[i] == theNode; i++)
last[i]->next[i] = theNode->next[i];
//更新链表级
while (levels > 0 && headerNode->next[levels] == tailNode)
levels--;
//释放节点空间
delete theNode;
//更新跳表节点个数
dSize--;
}
//输出第0级跳表
template<class K, class E>
void skipList<K,E>::output(ostream& out) const
{
for (skipNode<K,E>* currentNode = headerNode->next[0];
currentNode != tailNode;
currentNode = currentNode->next[0])
out << currentNode->element.first << " "
<< currentNode->element.second << " ";
}
//重载输出流运算符<<
template <class K, class E>
ostream& operator<<(ostream& out, const skipList<K,E>& x)
{x.output(out); return out;}
template <class K,class E>
void skipList<K,E>::OutputToString(string &s){
s="";
for (skipNode<K,E>* currentNode = headerNode->next[0];
currentNode != tailNode;
currentNode = currentNode->next[0]){
s+="(";
int nn=currentNode->element.first;
AppendInt(s,nn);
s+=",";
s+=currentNode->element.second;
s+=")";
}
s+="\n";
}

















 2797
2797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









