






搜索
概念:
搜索,是在大量的数据元素中找到某个特定的数据元素而进行的工作
模型:
模型:Key模型/Key-Value模型
Java:Set /Map
一般把搜索的数据称为关键字(Key),和关键字对应的称为值(Value),所以模型会有两种:
1.纯 key 模型,即我们 Set 要解决的事情,只需要判断关键字在不在集合中即可,没有关联的 value;
2.Key-Value 模型,即我们 Map 要解决的事情,需要根据指定 Key 找到关联的 Value。
搜索的结构:
1.搜索树
2.哈希表
3.调表
搜索树
概念:
特殊的数(二叉搜索树)
纯Key模型 Key不允许重复
搜索树的中序遍历是有序的(特点)
二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树:
1.若它的左子树不为空,则左子树上所有节点的值都小于根节点的值
2.若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
3.它的左右子树也分别为二叉搜索树
![int a[]={5,3,4,1,78,2,6,0,9};](https://img-blog.csdnimg.cn/20191010181428930.png)
查找:

若根结点不为空:
如果根结点 key==查找 key,返回 true
如果根结点 key > 查找 key,在其左子树查找
如果根结点 key < 查找 key,在其右子树查找
否则 返回 false
//在搜索树中查找 key,如果找到,返回 key 所在的结点,否则返回 null
public Node search(int key) {
Node cur = root;
while (cur != null) {
if (key == cur.key) {
return cur;
} else if (key < cur.key) {
cur = cur.left;
} else {
cur = cur.right;
}
}
return null;
}
插入:
1.如果树为空树,即根 == null,直接插入
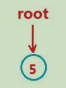
如果是空树,直接插入,然后返回 true
2.如果树不是空树,按照查找逻辑确定插入位置,插入新结点

1.按照二叉搜索树的性质,查找到插入结点的位置
root-->5 5<10 root=root->right parent=root
root-->7 7<10 root=root->right parent=root
root-->8 8<10 root=root->right parent=root
root-->9 9<10 root=root->right parent=root
2.插入新结点
public boolean insert(int key) {
if (root == null) {
root = new Node(key);
return true;
}
Node cur = root;
Node parent = null;
while (cur != null) {
if (key == cur.key) {
return false;
} else if (key < cur.key) {
parent = cur;
cur = cur.left;
} else {
parent = cur;
cur = cur.right;
}
}
Node node = new Node(key);
if (key < parent.key) {
parent.left = node;
} else {
parent.right = node;
}
return true;
}
删除:
设待删除结点为 cur,待删除结点的双亲结点为 parent
1. cur.left == null
1). cur 是 root,则 root = cur.right
2). cur 不是 root,cur 是 parent.left,则 parent.left = cur.right
3). cur 不是 root,cur 是 parent.right,则 parent.right = cur.right
2. cur.right == null
1). cur 是 root,则 root = cur.left
2). cur 不是 root,cur 是 parent.left,则 parent.left = cur.left
3). cur 不是 root,cur 是 parent.right,则 parent.right = cur.left
3. cur.left != null && cur.right != null
1). 需要使用 替换法 进行删除,即:
在它的右子树中寻找中序下的第一个结点(关键码最小),
或者 在它的左子树中寻找中序下的最后一个结点(关键码最大),[左子树中最大的/右子树中最小的]
用它的值填补到被删除节点中,再来处理该结点的删除问题
第三种情况代码:
Node goatParent = cur;
Node goat = cur.right;
while (goat.left != null) {
goatParent = goat;
goat = goat.left;
}
cur.key = goat.key;
if (goat == goatParent.left) {
goatParent.left = goat.right;
} else {
goatParent.right = goat.right;
}
性能分析:
插入和删除操作都必须先查找,查找效率代表了二叉搜索树中各个操作的性能。
对有n个结点的二叉搜索树,若每个元素查找的概率相等,则二叉搜索树平均查找长度是结点在二叉搜索树的深度的函数,即结点越深,则比较次数越多。
但对于同一个关键码集合,如果各关键码插入的次序不同,可能得到不同结构的二叉搜索树:

最优情况下,二叉搜索树为完全二叉树,其平均比较次数为: l o g 2 N log_2 N log2N
最差情况下,二叉搜索树退化为单支树,其平均比较次数为: N 2 \frac{N}{2} 2N
问题
如果退化成单支树,二叉搜索树的性能就失去了。那能否进行改进,不论按照什么次序插入关键码,都可以是二叉搜索树的性能最佳?
平衡二叉树,高度差不能超过1
和Java类集的关系
TreeMap 和 TreeSet 即 java 中利用搜索树实现的 Map 和 Set
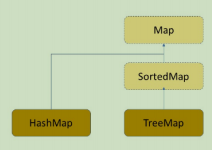
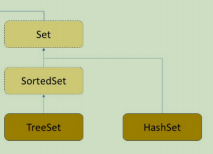
代码:> This is Code















 563
563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









