






思维导图


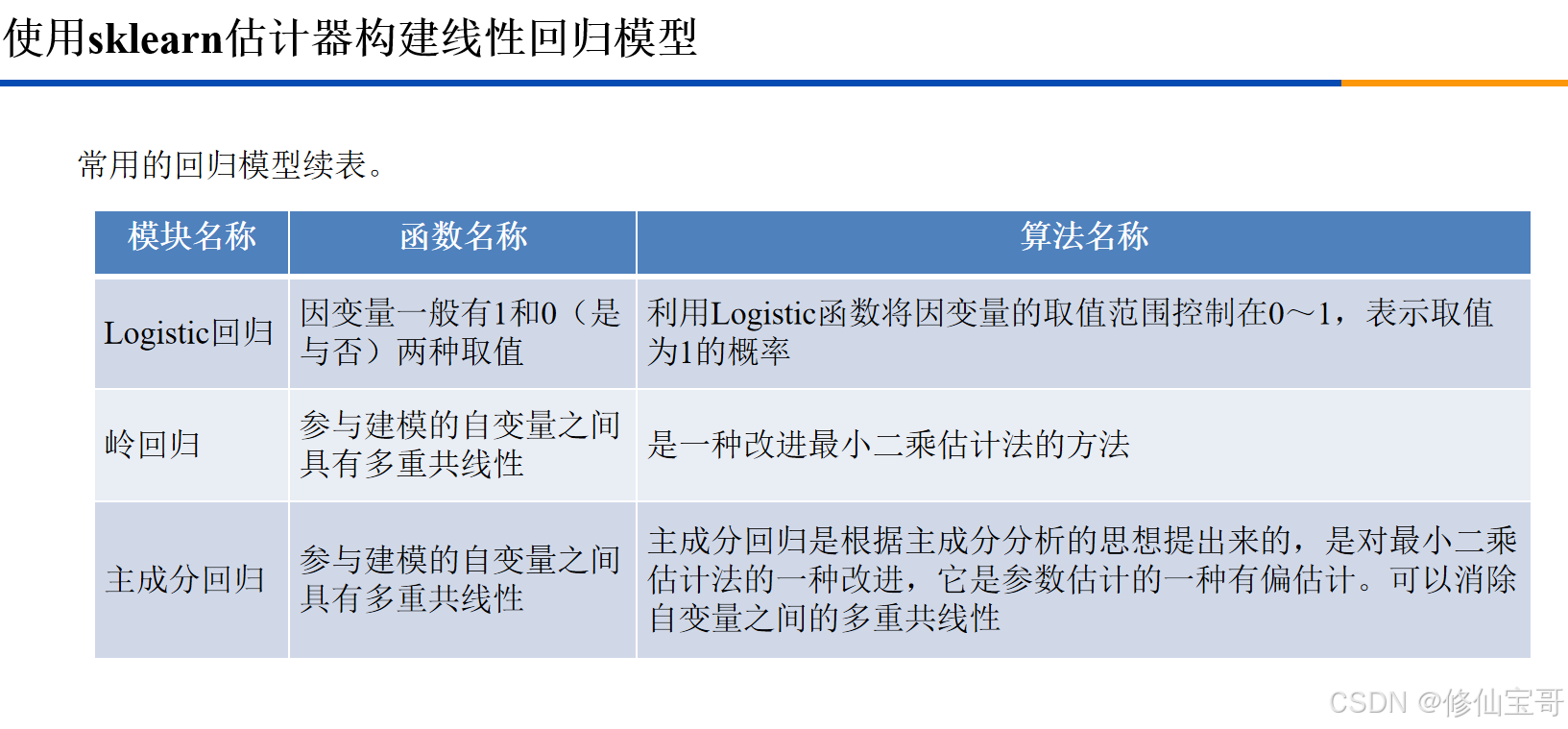
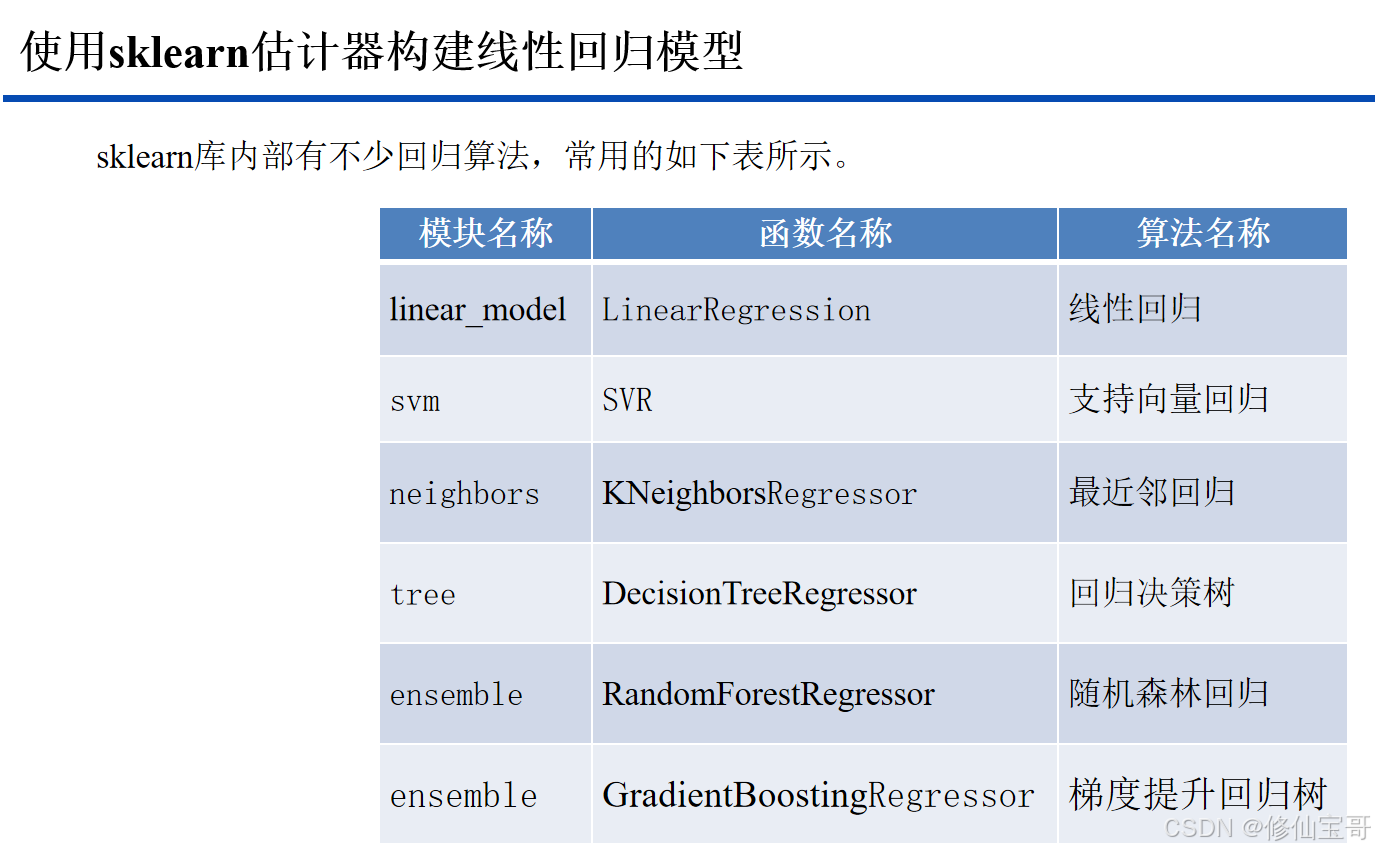
一、数据准备
1. 读取数据集
# 代码6-15
import pandas as pd
# 读取数据集
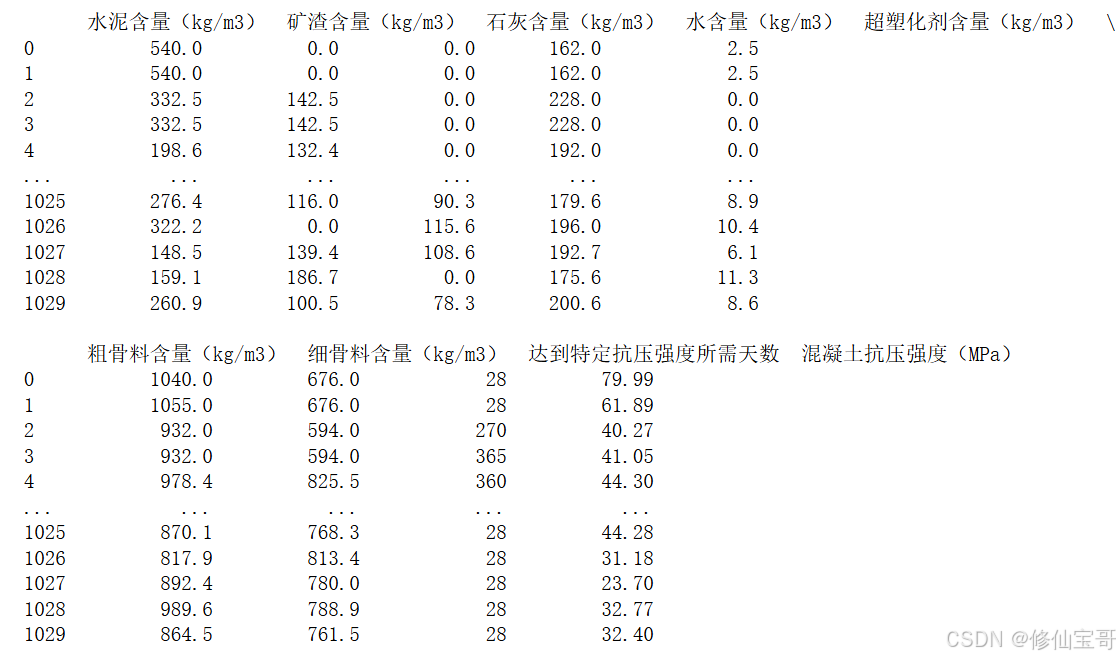
concrete = pd.read_csv('./concrete.csv', encoding='gbk')
print(concrete)
结果
代码解析:
- 此部分代码使用了
pandas库中的read_csv方法来读取CSV文件。read_csv方法的参数'../data/concrete.csv'指定了文件的路径,encoding='gbk'指定了文件的编码格式为GBK。
2. 拆分数据和标签
# 拆分数据和标签
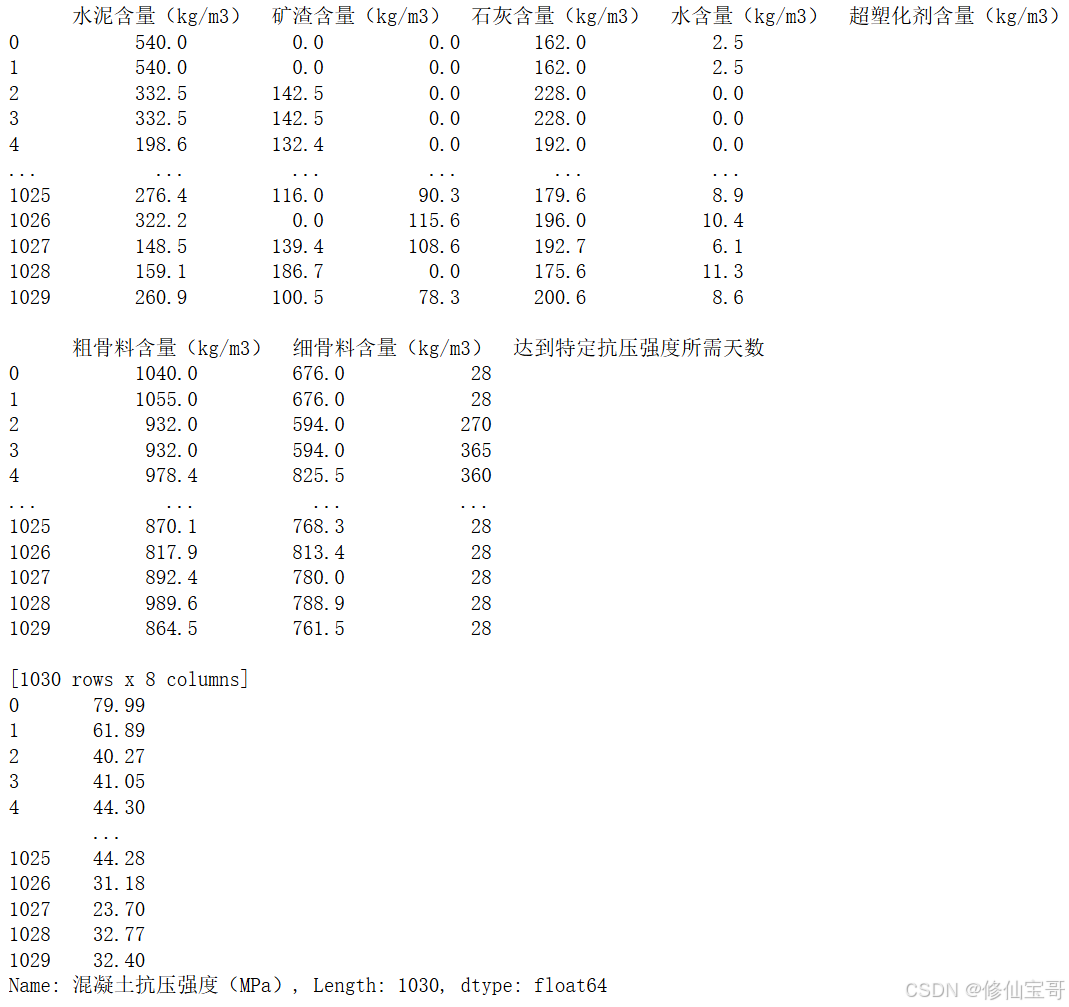
concrete_data = concrete.iloc[:, :-1]
concrete_target = concrete.iloc[:, -1]
print(concrete_data)
print(concrete_target)
结果
代码解析:
iloc是pandas中用于按位置索引选取数据的方法。concrete.iloc[:, :-1]表示选取除最后一列之外的所有列作为特征数据,concrete.iloc[:, -1]表示选取最后一列作为目标标签。
3. 划分训练集和测试集
# 划分训练集和测试集
from sklearn.model_selection import train_test_split
concrete_data_train, concrete_data_test, \
concrete_target_train, concrete_target_test = \
train_test_split(concrete_data, concrete_target,
test_size=0.2, random_state=20)
代码解析:
- 从
sklearn.model_selection模块中导入train_test_split方法,用于将数据集划分为训练集和测试集。 train_test_split方法的参数:concrete_data和concrete_target分别是特征数据和目标标签。test_size=0.2表示将20%的数据划分为测试集。random_state=20是随机种子,用于保证每次划分的结果一致。
二、模型训练
from sklearn.linear_model import LinearRegression
concrete_linear = LinearRegression().fit(concrete_data_train,
concrete_target_train)
代码解析:
- 从
sklearn.linear_model模块中导入LinearRegression类,用于创建线性回归模型。 LinearRegression().fit(concrete_data_train, concrete_target_train)使用训练集数据对线性回归模型进行训练。
三、模型预测
# 预测测试集结果
y_pred = concrete_linear.predict(concrete_data_test)
print('预测前20个结果为:','\n', y_pred[: 20])
结果

代码解析:
concrete_linear.predict(concrete_data_test)使用训练好的线性回归模型对测试集数据进行预测,返回预测结果存储在y_pred中。print语句用于打印预测结果的前20个值。
四、结果可视化
# 代码6-16
import matplotlib.pyplot as plt
from matplotlib import rcParams
rcParams['font.sans-serif'] = 'SimHei'
fig = plt.figure(figsize=(12, 6)) # 设定空白画布,并制定大小
plt.plot(range(concrete_target_test.shape[0]),
list(concrete_target_test), color='blue')
plt.plot(range(concrete_target_test.shape[0]),
y_pred, color='red', linewidth=1.5, linestyle='-.')
plt.legend(['真实值', '预测值'])
plt.savefig('./回归结果.jpg', dpi=1080)
plt.show() # 显示图片
结果
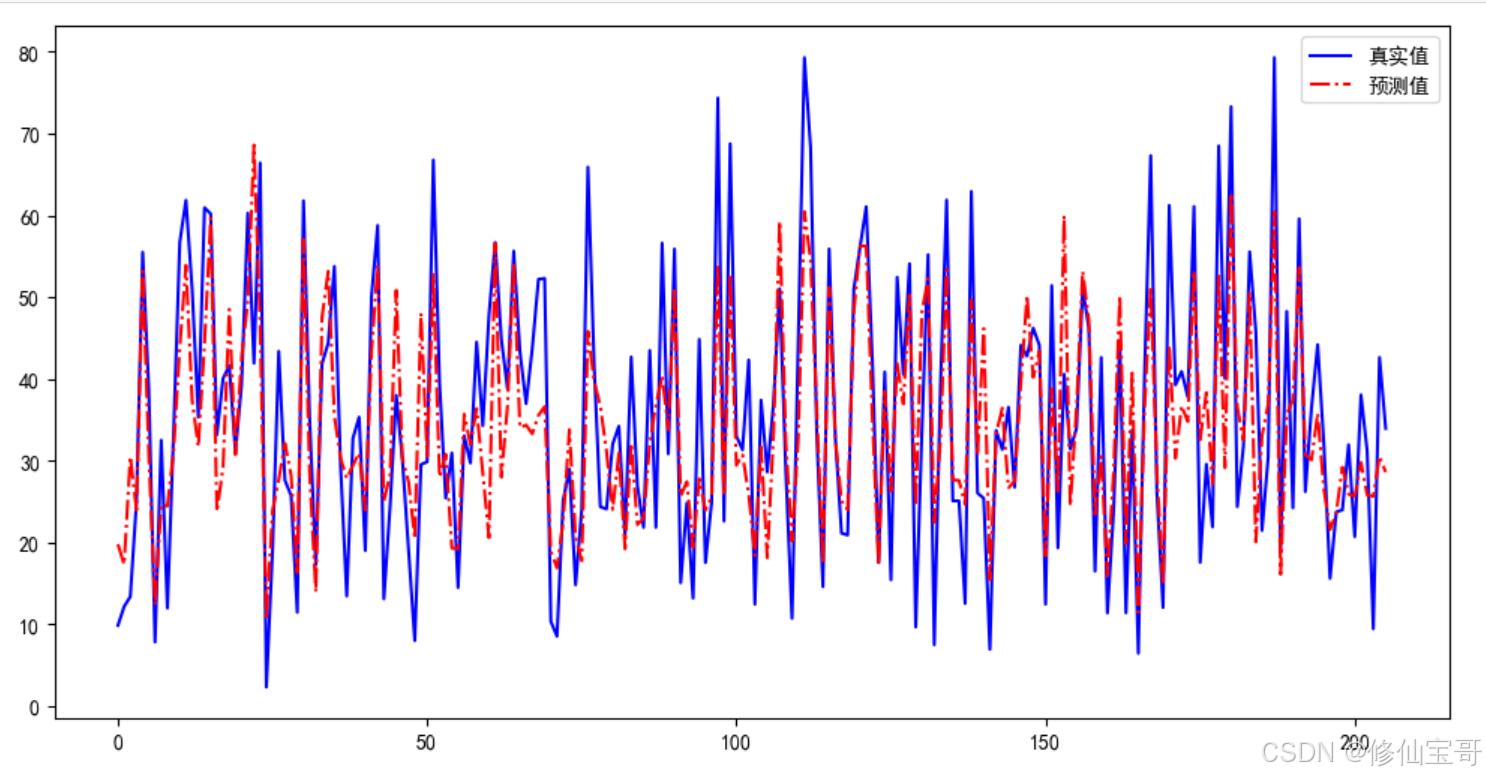
代码解析:
- 导入
matplotlib.pyplot库用于绘图,rcParams['font.sans-serif'] = 'SimHei'设置字体为黑体,以支持中文显示。 plt.figure(figsize=(12, 6))创建一个大小为12x6的空白画布。plt.plot方法用于绘制曲线,第一个plt.plot绘制真实值曲线,第二个plt.plot绘制预测值曲线。plt.legend方法用于添加图例。plt.savefig方法将绘制的图片保存到指定路径,dpi=1080指定图片的分辨率。plt.show方法显示绘制的图片。
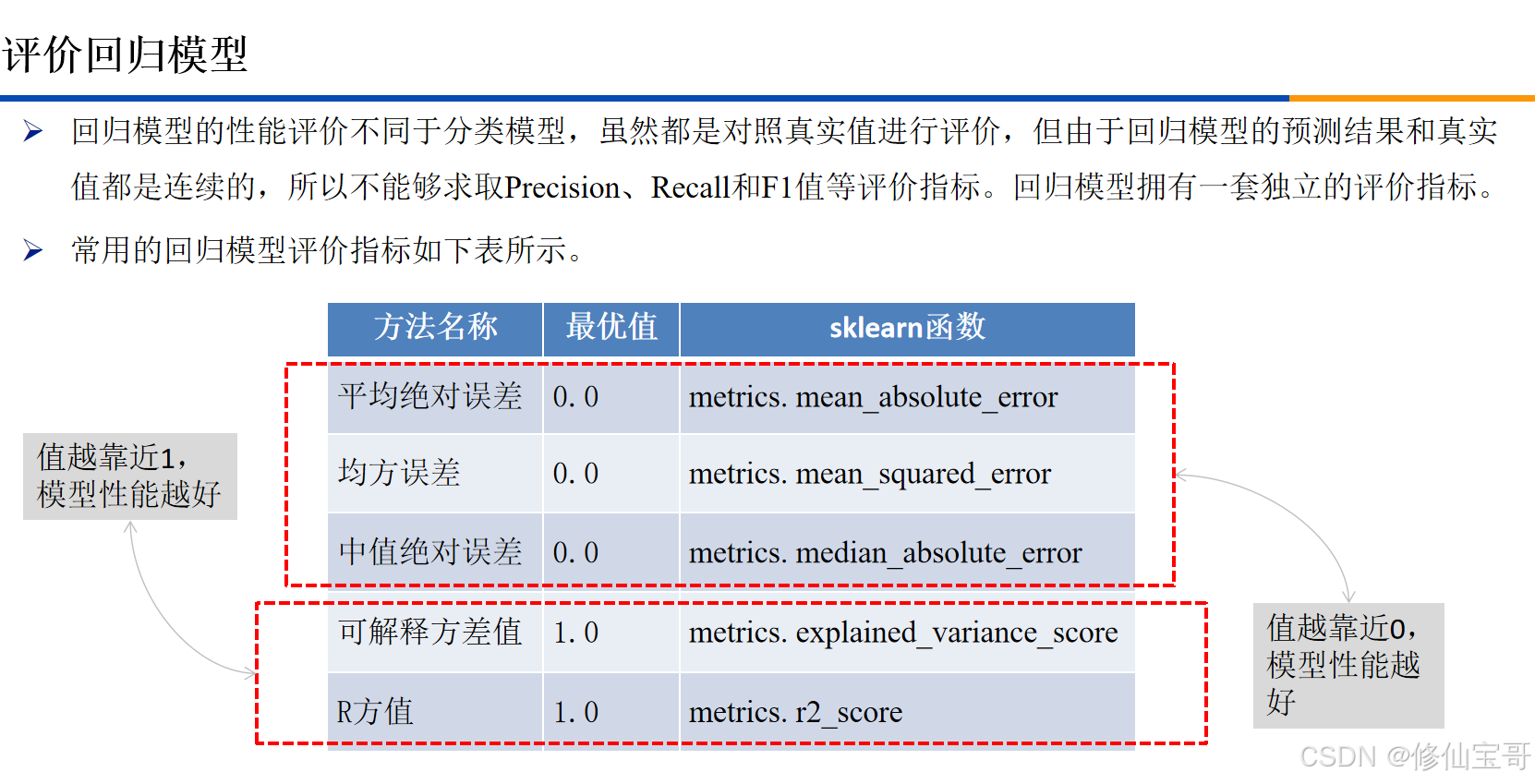
五、模型评估
# 代码6-17
from sklearn.metrics import explained_variance_score,\
mean_absolute_error, mean_squared_error,\
median_absolute_error, r2_score
print('diabetes数据线性回归模型的平均绝对误差为:',
mean_absolute_error(concrete_target_test, y_pred))
print('diabetes数据线性回归模型的均方误差为:',
mean_squared_error(concrete_target_test, y_pred))
print('diabetes数据线性回归模型的中值绝对误差为:',
median_absolute_error(concrete_target_test, y_pred))
print('diabetes数据线性回归模型的可解释方差值为:',
explained_variance_score(concrete_target_test, y_pred))
print('diabetes数据线性回归模型的R方值为:',
r2_score(concrete_target_test, y_pred))
结果

代码解析:
- 从
sklearn.metrics模块中导入多种评估指标的计算方法。 - 分别使用这些方法计算线性回归模型的平均绝对误差、均方误差、中值绝对误差、可解释方差值和R方值,并打印输出。
总结
通过本次学习,读者能够掌握以下知识与技能:
- 使用
pandas库读取CSV文件,并进行数据和标签的拆分。 - 使用
sklearn库的train_test_split方法划分训练集和测试集。 - 使用
sklearn库的LinearRegression类构建线性回归模型并进行训练和预测。 - 使用
matplotlib库对模型的预测结果进行可视化。 - 使用
sklearn库的多种评估指标对线性回归模型进行评估。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









