









Kafka 介绍
学习目标:
- 掌握基本的消息传递模式;
- 掌握 Kafka 集群部署的方法;
- 掌握 Kafka 的基本方法。
Kafka 是一个高吞吐量的分布式发布订阅消息系统,它在实时计算系统中有着非常强大的功能。通常情况下,我们使用 Kafka构建系统或应用程序之间的数据管道,用来转换或响应实时数据,使数据能够及时的进行业务计算,得出相应结果。
一、Kafka的基础知识
为解决大数据集的传输困难,就必须搭建一个一个消息系统。消息系统将数据从一个应用程序传递到另外一个应用程序中,应用数据只关心数据,不关心在多个应用是怎么传递的。
1.1 点对点消息传递模式
点对点消息传递模式结构中,消息是通过一个虚拟通道进行传输的,生产者发送一条数据,消息将持久化到一个队列中,此时将有一个或多个消费者会消费队列中数据,但是一条消息只能被消费一次,且消费后的消息会从消息队列中删除,因此,即使有多个消费者同时消费数据,数据都可以被有序处理。

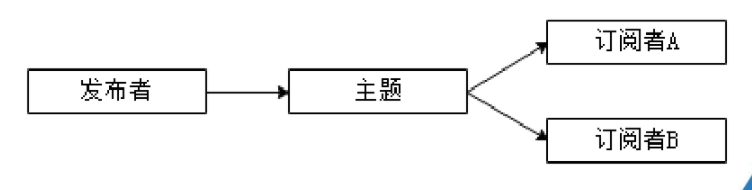
1.2 发布订阅消息传递模式
在发布订阅模式中,发布者用于发布消息,订阅者用于订阅消息, 发布订阅模式可以有多种不同的订阅者,发布者发布的消息会被持久化到一个主题中,这与点对点模式不同的是,订阅者可订阅一个或多个主题,订阅者可读取该主题中所有数据,同一条数据可被多个订阅者消费,数据被消费后也不会立即删除。
1.3 Kafka 简介
Kafka是由Apache软件基金会开发的一个开源流处理平台,它由Scala和Java语言编写,是一个基于Zookeeper系统的分布式发布订阅消息系统,该项目的设计初衷是为实时数据提供一个统一、高通量、低等待的消息传递平台。
ApacheKafka作为分布式消息系统,可以处理大量的数据,并能够将消息从一个端点传递到另外一个端点。Kafka系统在大数据领域中的应用非常普遍,它能够在离线和实时两种大数据计算架构中处理数据,这得益于Kafka的众多优点,其优点具体如下。
- (1) 解耦。Kafka具备消息系统的优点,只要生产者和消费者数据两端遵循接口约束,就可以自行扩展或修改数据处理的业务过程。
- (2) 高吞吐量、低延迟。即使在非常廉价的机器上, Kafka也能做到每秒处理几十万条消息,而它的延迟最低只有几毫秒。
- (3) 持久性。Kafka可以将消息直接持久化在普通磁盘上,且磁盘读写性能优异。
- (4) 扩展性。Kafka集群支持热扩展, Kafka集群启动运行后,用户可以直接向集群添加新的Kafka服务。
- (5) 容错性。Kafka会将数据备份到多台服务器节点中,即使Kafka集群中的某一台节点宕机,也不会影响整个系统的功能。
- (6) 支持多种客户端语言。Kafka支持Java,NET,PHP,Python等多种语言。
在大数据计算系统的开发场景中,若需要对接外部数据源时,就可以使用Kafka系统, 如读者熟悉的日志收集系统和消息系统, Kafka读取日志系统中的数据,每得到一条数据,就可以及时地处理一条数据,这就是常见的流式计算框架。
在流式计算框架中, Kafka一般用来缓存数据,它与Apache旗下的Spark、Storm等计算框架有着非常好的集成,这些计算框架可以接收Kafka中的缓存数据并进行计算,实时得出计算结果。
Kafka使用消费组 (Consumer Group) 的概念统一了点对点消息传递模式和发布订阅消息传递模式,当Kafka使用点对点模式时,它可以将待处理的工作任务平均分配给消费组中的消费者成员;当使用发布订阅模式时,它可以将消息广播给多个消费组。Kafka采用多个消费组结合多个消费者,既可以扩展消息处理的能力,也允许消息被多个消费组订阅。
二、Kafka 工作原理
2.1 Kafka核心组件介绍

| 组件名称 | 相关说明 |
|---|---|
| Topic | 特定类别消息流称为主题,数据存在主题中,主题被拆分成分区; |
| Partition | 主题的数据分割为一一个或多个分区,每个分区的数据使用多个segment文件存储,分区中的数据是有序的; |
| Offset | 每个分区消息具有的唯序列标识; |
| Replica | 副本只是一个分区的备份,它们用于防止数据丢失; |
| Producer | 生产者即数据发布者,该角色将消息发布到Kafka集群主题中; |
| Consumer | 消费者可从Broker中读取数据,可消费多个主题数据; |
| Broker | 每个Kafka服务节点都为Broker,Broker 接收消息后,将消息追加到segment文件中; |
| Leader | 负责分区的所有读写操作,每分区都有一个服务器充当Leader ; |
| Follower | 跟随领导指令,若Leader发生故障则选举一个 Follower 为新 Leader ; |
| Consumer Group | 实现一个主题消息的广播和单播的手段。 |
Kafka集群由 生产者(Producer)、消息代理服务器(Broker Server)、消费者 (Consumer) 组成的。
2.2 Kafka 工作流程分析
1. 生产者生产消息过程
生产者向Kafka集群中生产消息。Producer是消息的生产者,通常情况下,数据消息源可是服务器日志、业务数据及Web服务数据等,生产者采用推送的方式将数据消息发布到Kafka的主题中,主题本质就是一个目录,而主题是由Partition Logs (分区日志) 组成,每条消息都被追加到分区中。
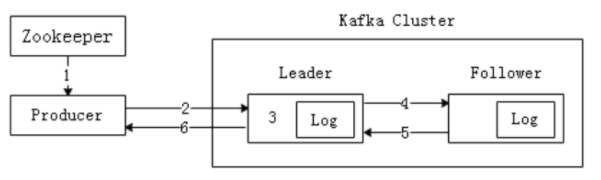
Producer 生产信息可以简单分6步,具体如下:
- Producer先读取Zookeeper的"/brokers/…/state"节点中找到该Partition的Leader 。
- Producer将消息发送给Leader。
- Leader负责将消息写入本地分区Log文件中。
- Follower从Leader中读取消息,完成备份操作。
- Follower写入本地Log文件后,会向Leader发送Ack,每次发送消息都会有一个确认反馈机制,以确保消息正常送达。
- Leader收到所有Follower发送的Ack后,向Producer发送Ack,生产消息完成。
2. 消费者消费消息过程
消费者消费类型有两种:推送模型和拉取模型;Kafka采用拉取模型, 由消费者记录消费状态,根据主题、Zookeeper集群地址和要消费消息的偏移量,每个消费者互相独立地按顺序读取每个分区的消息,消费者消费消息的流程图如下所示:

















 1976
1976











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











