






文章目录
数表的查找之 MySql 为什么使用 B+ 树?
讲解之前,先进行思考:
思考:从磁盘查找数据效率低,一般是什么原因?
我们知道 CPU 速度非常快,如果 CPU 直接与磁盘进行交互,由于磁盘的 IO 速度较慢的限制,因此不能直接使 CPU 与磁盘交互,而是在之间引入内存,先将磁盘中的数据加载至内存,CPU 再从内存中读取数据。

解释到这里,继续回归先前的思考题,如果从磁盘查找数据消息低,那么一定是出现在磁盘的 IO 上。
影响 IO 效率的因素主要有两大类:
- 读写数据越大,速度越慢;
- 读写次数越多,速度越慢;
对于读写的数据大,这里没什么改变的办法,有时候的需求确实是读取大量的数据,但是对于读写的次数多,这里可以进一步优化——引入索引。
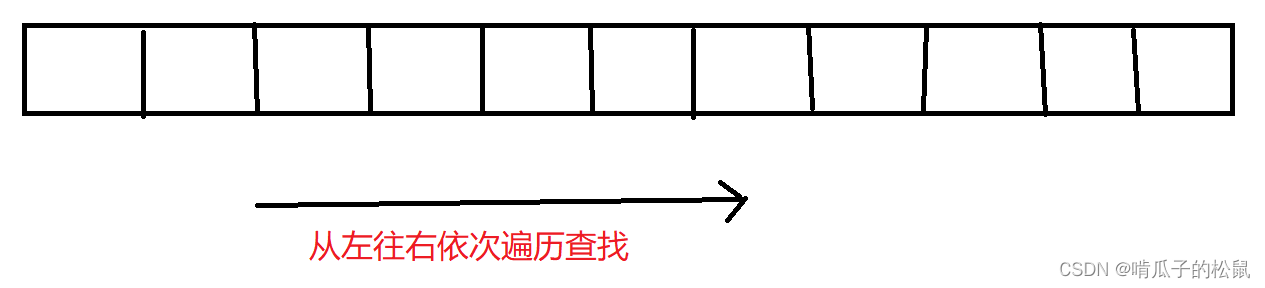
方式一:线性查找
对于线性查找,是最简单也是最原始的查找方式,它的缺点就是,查找效率非常低,对于每一次查找,都需要遍历全部数据,查询效率非常低。
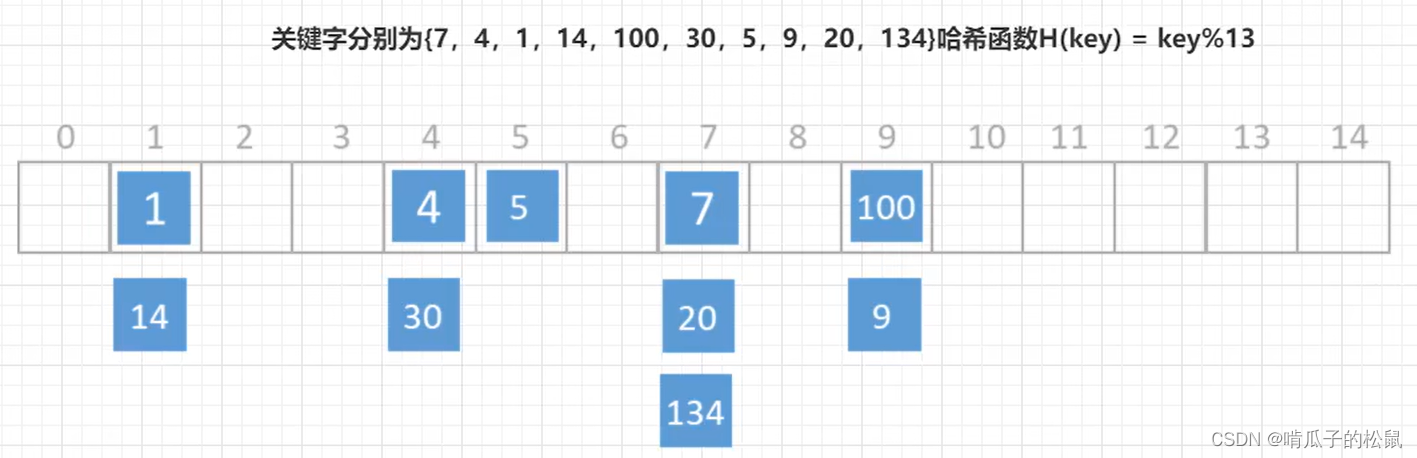
方式二:哈希查找
既然线性查找效率非常低下,那么我们引入哈希表,通过元素值的 key 去查找对应的分支链表,这样查询效率有所提升,但是,哈希查找也存在弊端,因为哈希查找存在哈希冲突,一旦出现哈希冲突,极端的情况下就会出现一条单链表,时间复杂度还是O(N);对于哈希冲突,内部有很多解决哈希冲突的算法,也不是最本质的原因,最本质的原因是哈希查找不支持范围查询,因此也不采用不采用哈希查找。
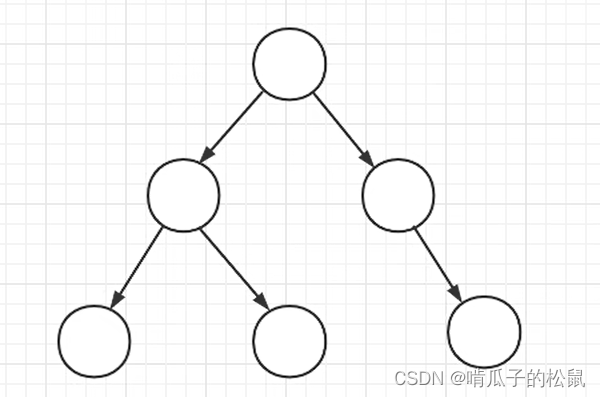
方式三:引入树查找—二叉树
对于二叉树,由于每个节点的值没有规律,查询起来还是需要一个个查找对比,还是很费劲,时间复杂度还是O(N),因此二叉树也不行。
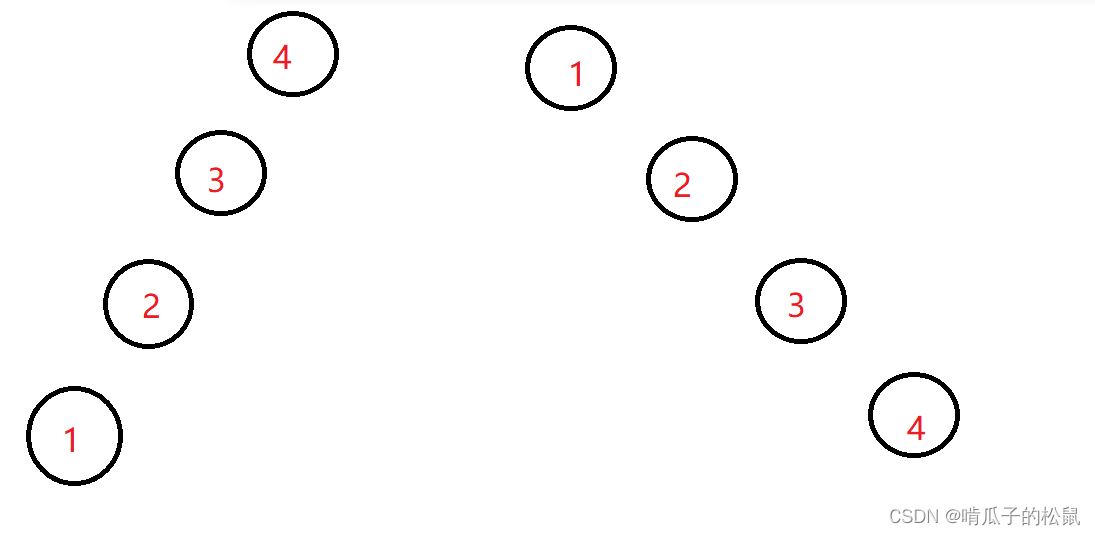
方式四:二叉树改造之二叉排序树(BST)
既然二叉树的缺点是节点之间没有规律,那么换成二叉排序树怎么样?左子树永远比根节点小,右子树永远比根节点大。咋一看好像可以,但是仔细想想还是存在特殊情况:只有左子树或只有右子树。这样的时间复杂度依旧是O(N)。
方式五:二叉排序树(BST)改造之平衡二叉树(AVL)
既然二叉排序树会存在只有左子树或右子树的极端情况,那么我们引入平衡二叉树不就解决了?让树的形态永远保持平衡。但是啊,平衡二叉树的每一次调整平衡,都需要耗时,类似于是在用插入数据时的成本,来换取查询的效率。如果插入少查询多,那么这种方法也可取,但是插入多查询少时,就不可取了。
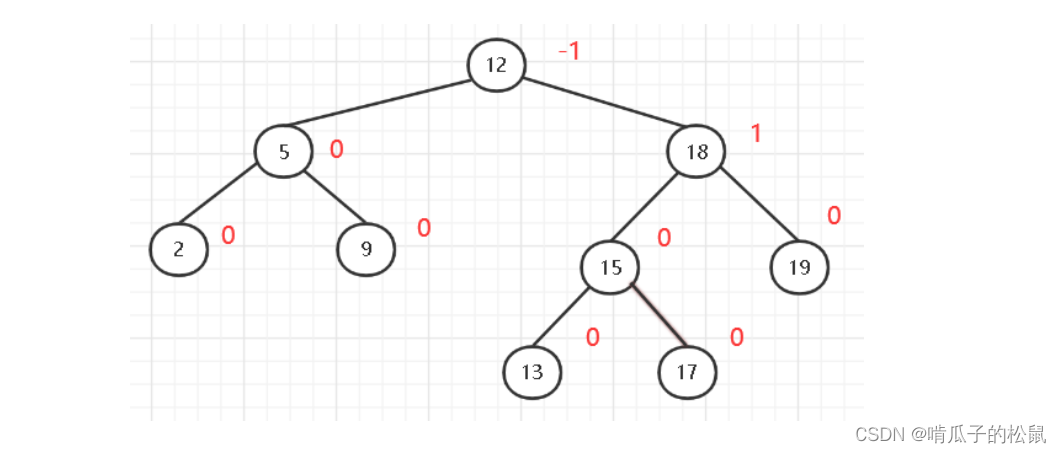
方式六:平衡二叉树(AVL)改造之红黑树
红黑树:红黑树是一颗特殊的二叉树,缺点也是高度不可控。
对于红黑树,在插入的时候虽然也需要进行红黑节点的调整,但是相对于平衡二叉树也有所好转。是不是红黑树就满足我们的需求了呢?假如我们插入了大量的数据,那么红黑树的深度也会特别深,树的深度越深,查找次数就会变多,因此效率也没有得到本质的改善。
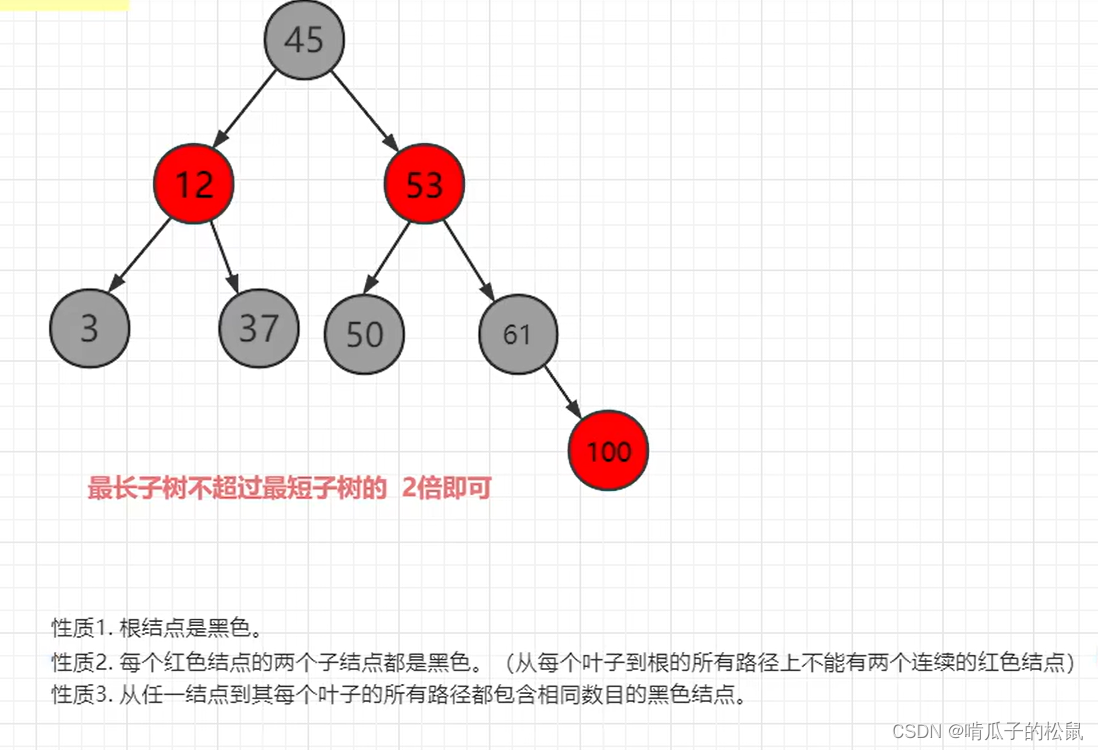
方式七:红黑树改造之降低树的深度(B 树)
B 树概念:满足下列的 m 叉树就是一颗 B 树(B-Tree)不是 B- 树:
(1)树中每个结点至多有 m 个孩子结点(即最多只有 m-1 个关键字)。
(2)每个结点的结构为:

n 表示关键字及孩子个数,p表示指向孩子结点的指针,k表示关键字。
(3)除根节点外,其他结点至少有 m/2 个孩子结点。
(4)若根节点不是叶子节点,则根节点至少有两个孩子结点。
(5)所有叶子结点都在同一层上,即 B 树是所有结点的平衡因子都等于 0 的多路查找树。
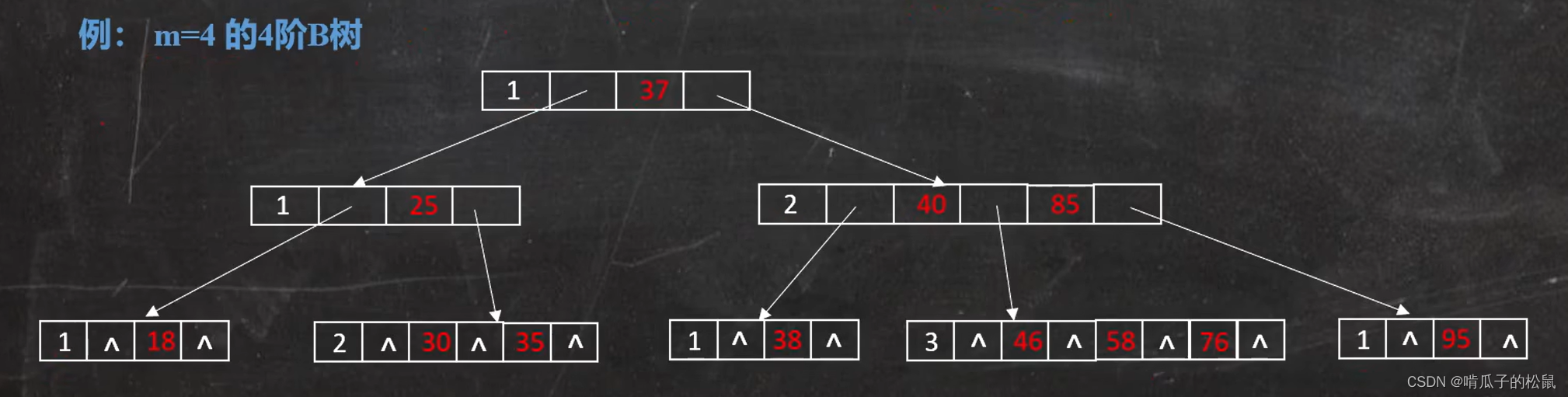
既然二叉树无法避免树的深度急剧加深,那么我们就想办法减少树的深度,因此引入多叉树如何?(引入B树,B树就是一个有序的多路查找树),树的叉数变多后,对于同一组数据,深度自然就会降低。
此处先引入一个名词:磁盘预读。
- 内存跟磁盘发生数据交互的时候,一般情况下有一个最小的逻辑单元,称之为页:datapage。
- 页一般由操作系统决定是多大,一般是 4k 或者 8k( mysql 默认是16k),在进行数据交互的时候,可以取页的整数倍来进行读取。
对于 B 树的每一个结点,都是放在一个 datapage 里面,每次查找数据时,都是先从磁盘中 IO 读取一个 datapage,然后依次往下查找,直到找到为止。假设一个结点的大小是16k(mysql 默认是16k)。
B 树笼统的说,就是一颗平衡多路的查找树(或者说是平衡多叉树),可以有效的降低树的深度,但是对范围查询很不友好,因此 mysql 索引结构没有采用 B 树。
思考并计算:B+ 树到底有多高?
在 InnoDB 存储引擎中,B+ 树索引这棵索引树上每个非叶子节点都由 key 和指针组成(key存储的是主键),一个节点的大小为16KB、一个指针的大小为 6 字节,这都是固定的。
假设主键采用 bigint 进行存储(按最大值计算)也就是 8 字节,也假设数据库表的每行数据都是 1KB,也就是一个叶子节点可以存储 16 行数据。
由于每个非叶子节点中指针的个数都比 key 多 1 个,因此对于每个节点,设 n 为 主键个数,得出计算公式:
n * 8 +(n + 1) * 6 = 16 * 1024,n ≈ 1170(个)
- 对于高度为 2 的 B+ 树,(1170 + 1) * 16 = 18736(行)
- 对于高度为 3 的 B+ 树,(1170 + 1) * (1170 + 1) * 16 = 21939856(行)
可以明显得看出,高度为 3 的 B+ 树就可以存储 2000 多万行数据行,而树的高度越低,查询的时候效率也就越高。
扩展:终结操作之 B+ 树
模拟构建 B+ 树网址:https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
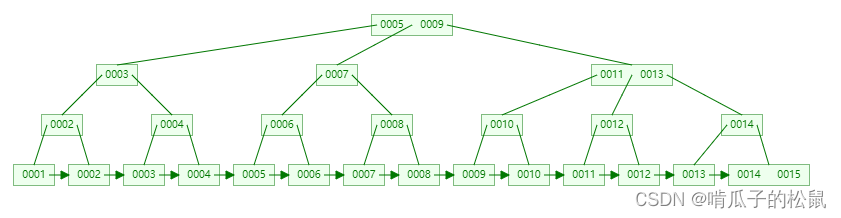
对于 B+ 树和 B 树,有以下区别:
- 非叶子节点不存储数据,只存储索引元素,这就使得非叶子节点可以存储更多的索引元素,可以有效的降低树的高度;
- 所有的数据,都存储在叶子节点上,并且在叶子节点之间形成一颗双向的循环链表,可以友好的支持范围查询;
- 相比 B 树来说,进行范围查询时 B+ 树只需要查找两个节点,进行遍历即可,而 B 树需要获取所有节点,相比之下 B+ 树效率更高,这也是采用 B+ 树最大的优点;
总结 mysql 使用 B+ 树的原因
- 数据都存储在叶子节点,因此非叶子节点就可以存储更多的索引元素,因此整颗 B+ 树会变得更矮更胖,因此查询数据的时候磁盘 IO 会更少,查询效率会提高;
- 所有数据都存储在叶子节点上,并且形成一颗双向的循环链表,这样使得范围查找、排序查找特别方便,这也是最大的优势;















 5441
5441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









