






摘自:https://www.zhihu.com/question/20993864/answer/958223021
统计学中认识的第一对概念就是总体与样本,这里我想特别澄清一点的是把样本想象成固定的会限制我们的思考。总体和样本的关系是一对多的,理论上一个总体我们可以抽取无数个样本量相同但本质上不同的样本。比如我们想检验北京大学男生的平均身高是否为1.8m(H0:总体均数为1.8m),那么北京大学所有男生的身高数据就是我们这个案例的总体。之后我们从总体中随机抽取100名男生测量身高,这100名男生的身高就是一个样本。当然,我还可以获得很多其他的样本,特别注意,这里的样本不是一个一个学生,而是一个由100个学生组成的集体。
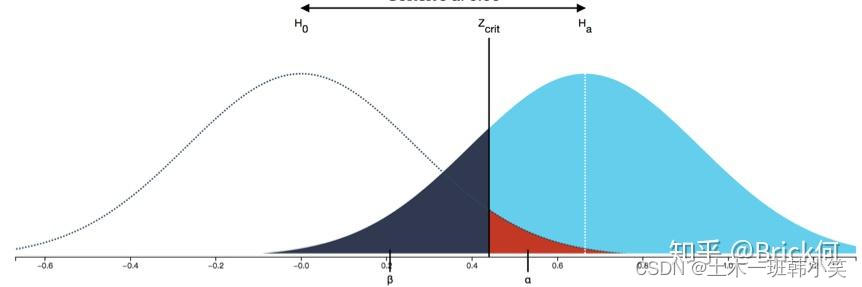
在统计学上,我们通常会把样本称为样本点,如果你结合样本均数来理解就会很清楚为什么要加一个“点”字。首先,每一个样本都会计算出一个样本均数,每一个样本均数其实都是X轴上的一个点,有的样本均数离总体均数近,而有的离总体均数远。当我们抽中的样本计算出来的样本均数离总体均数远的时候,即两者差异较大时,我们就会倾向拒绝两者相等的假设。所以,即便实际上H0假设正确,数轴上依然会有一些点与总体均数的距离较远,当这些点对应的样本被我们抽中时,我们就会做出拒绝H0的决定,从而我们就会犯错了,这便是第一类错误的发生逻辑。
那第二类错误怎么理解呢?要犯第二类错误,那么意味着H0(总体平均身高为1.8m)是假的,实际上可能是1.85m。这其中会出现一个比较绕的点是,由于H0和事实不一致,所以H0所代表的总体和实际研究的总体也不一样。在本例中,一个是均数为1.8的总体(上图中的虚线总体);另一个是均数为1.85的总体(上图中蓝色部分的总体)。我们用假设检验进行判断时用的是第一个总体,即依据第一个总体的均数来计算检验统计量并判断是否要拒绝原假设,因为我们假设所获得的这个样本是来自于第一个总体的。但我们计算犯错概率时,用的是第二个实际总体,即我们这个样本并不是来自第一个总体,而是来自第二个实际的总体,在这个实际的总体中,会有多少样本点导致在前一步计算检验统计量时不拒绝H0。这一点理清之后,你可能就会豁然开朗。
类似刚才的思路,我们有可能在实际均数为1.85的总体中抽出一些样本(上图黑色阴影部分所代表),而通过这些样本计算的样本均数与1.8差异不大,从而让我们不拒绝H0(因为这些样本不处于拒绝域,即红色阴影所代表的部分),进而导致第二类错误的发生。而计算错误发生概率大小,就是在实际1.85的总体中那些与1.8距离较近的样本点所组成的集合所占的比例(上图黑色阴影部分面积在实际总体所占的比例),正是这些集合的存在会让我们不拒绝H0而犯错。通过上述说明,对照图你可能就能理解,为什么我们会说减少第一类错误的发生概率就会增加第二类错误的概率,因为,第一类错误的概率是我们根据检验水准人为设定的,当我们把检验水准从0.05提高到0.01时,我们减少了图中红色阴影的面积,但增大了图中黑色阴影的面积,该面积即为第二类错误发生概率。另一个常见的问题是为什么只有增加样本量才能同时减少这两类错误的犯错概率,简单理解,就是由于样本量的增加会降低标准误的大小(标准误=S/根号N,样本本量N越大,标准误越小,反映在图形中就是两个总体(假设总体和实际总体)变得更“细瘦”,所以重合的部分越少,由此代表犯错概率的图形的面积也会变小。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









