







MongoDB是一个基于分布式文件存储的数据库,由C++编写,可以为WEB应用提供可扩展、高性能、易部署的数据存储解决方案。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库中功能最丰富、最像关系数据库的。在高负载的情况下,通过添加更多的节点,可以保证服务器性能。
一、Mongo介绍
1、MongoDB体系结构
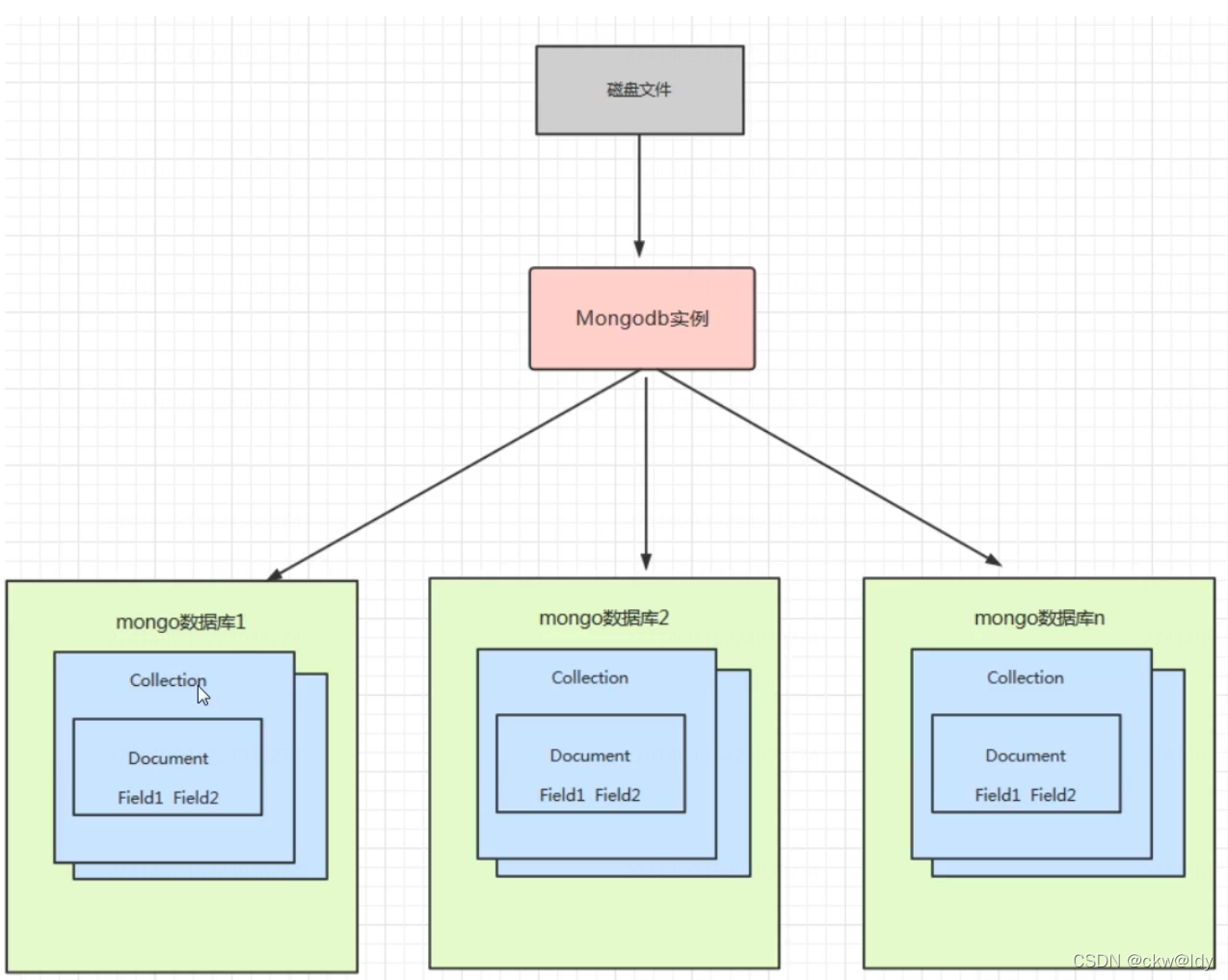
2、MongDB和RDBMS(关系型数据库)对比

3、BSON介绍
BSON是一种类json的一种二进制形式的存储格式,简称BinaryJSON,它和JSON一样,支持内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,如Date和Binary Data类型。BSON可以做为网络数据交换的一种存储形式,是一种schema-less的存储形式,它的优点是灵活性高,但它的缺点是空间利用率不是很理想。
{key:value,key2:value2}这是一个BSON的例子,其中key是字符串类型,后面的value值,它的类型一般是字符串,double,Array,ISODate等类型。
BSON有三个特点:轻量性、可遍历性、高效性
4、BSON在MongoDB中的使用
MongoDB使用了BSON这种结构来存储数据和网络数据交换。把这种格式转化成一文档这个概念(Document),这里的一个Document也可以理解成关系数据库中的一条记录(Record),只是这里的Document的变化更丰富一些,如Document可以嵌套。
MongoDB中Document中可以出现的数据类型

二、MongoDB基本操作
1、MongoDB的基本操作
查看数据库
show dbs;
切换数据库如果没有对应的数据库则创建
use数据库名;
创建集合
db.createcollection("集合名”)
查看集合
show tables;
show collections;
删除集合
db.集合名.drop();
删除数据库
db.dropDatabase();
2、CRUD操作
- 数据添加
- 插入单条数据
db.集合名.insert(文档)
文档的数据结构和USON基本一样。
所有存储在集合中的数据都是BSON格式。
BSON是一种类json的一种二进制形式的存储格式,简称BinaryJSON。 - 例如:
db.resume.insert({name:“ckw”,birthday:new ISODate(“2022-03-09”),expectSalary:15000,gender:0,city:“bj”})
没有指定_id这个字段系统会自动生成当然我们也可以指定id
(_id 类型是Objectld 类型是一个12字节BSON类型数据,有以下格式:
前4个字节表示时间戳 Objectld(“对象ld字符串”).getTimestamp)来获取接下来的3个字节是机器标识码紧接的两个字节由进程id组成(PID)最后三个字节是随机数。) - 插入多条数据
db.集合名.insert([文档,文档])
- 数据查询
-
比较条件查询
db.集合.find(条件)

-
逻辑条件查询
and 条件 MongoDB的find()方法可以传入多个键(key),每个键(key)以逗号隔开,即常规SQL的AND条件 db.集合名.find({key1:value1,key2:value2]} or条件 db.集合名.find({$or:[{key1:value1},{key2:value2}]}) not条件 db.集合名.find({key:{$not:{$操作符:value]}) -
分页查询
db.集合名.find({条件}).sort({排序字段:排序方式})).skip(跳过的行数).limit(一页显示多少数据) -
like 与 in查询
db.集合名.find({name:/模糊值/}) -- 全模糊 db.集合名.find({name:/^模糊值/}) -- 右模糊 db.resumer.find({name:{$in:[值]}}) -
数据更新(update)
$set:设置字段值 $unset:删除指定字段 $inc:对修改的值进行自增 db.集合名.update( <query>, <update>, upsert:<boolean>, multi:<boolean>, writeconcern:<document> 参数说明: query:update的查询条件,类似sql update查询内where后面的。 update:update的对象和一些更新的操作符(如$set,$inc...)等,也可以理解为sql update中set后面的upsert:可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。 multi:可选,MongoDB默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。 writeconcern:可选,用来指定mongod对写操作的回执行为比如写的行为是否需要确认。 举例: db.集合名.update({条件},{$set:{字段名:值},{multi:true}) -
数据删除
db.collection.remove( <query>, justone:<boolean>, writeconcern:<document> 参数说明: query:(可选)删除的文档的条件。 justone:(可选)如果设为true或1,则只删除一个文档,如果不设置该参数,或使用默认值false,则删除所有匹配条件的文档。 writeconcern:(可选)用来指定mongod对写操作的回执行为。
3、聚合操作
-
聚合操作介绍
聚合是MongoDB的高级查询语言,它允许我们通过转化合并由多个文档的数据来生成新的在单个文档里不存在的文档信息。一般都是将记录按条件分组之后进行一系列求最大值,最小值,平均值的简单操作,也可以对记录进行复杂数据统计,数据挖掘的操作。聚合操作的输入是集中的文档,输出可以是一个文档也可以是多个文档。 -
MongoDB聚合操作分类
- 单目的聚合操作(Single Purpose Aggregation Operation)
- 聚合管道(Aggregation Pipeline)
- MapReduce编程模型
-
单目聚合操作
单目的聚合命令常用的有:count()和distinct()db.resume.find({}).count() -
聚合管道(Aggregation Pipeline)
db.COLLECTION_NAME.aggregat(AGGREGATE_OPERATION) 如: db.resume_preview.aggregate([{$group:{_id:"$city",city_count:{$sum:1}}}])
MongoDB中聚合(aggregate)主要用于统计数(诸如统计平均值,求和等),并返回计算后的数据结果。
表达式:处理输入文档并输出。表达式只能用于计算当前聚合管道的文档,不能处理其它的文档。

MongoDB中使用db.COLLECTION_NAME.aggregate([{},…])方法来构建和使用聚合管道,每个文档通过一个由一个或者多个阶段(stage)组成的管道,经过一系列的处理,输出相应的结果。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
这里我们介绍一下聚合框架中常用的几个操作:
-
$group:将集合中的文档分组,可用于统计结果。
-
$project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
-
m a t c h : 用 于 过 滤 数 据 , 只 输 出 符 合 条 件 的 文 档 。 match:用于过滤数据,只输出符合条件的文档。 match:用于过滤数据,只输出符合条件的文档。match使用MongoDB的标准查询操作。
-
$limit:用来限制MongoDB聚合管道返回的文档数。
-
$skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
-
$sort:将输入文档排序后输出。
-
$geoNear:输出接近某一地理位置的有序文档。
db.resume.aggregate( [{$group:{_id:"$city",avgsal:{$avg:"$expectsalary"}}}, {$project:{city:"$city",salary:"$avgsal"}} ]) db.resume.aggregate( [{$group:{_id:"$city",count:{$sum:1}}}, {$match:{count:{$gt:1}}} ])
- MapReduce编程模型
Pipeline查询速度快于MapReduce,但是MapReduce的强大之处在于能够在多台Server上并行执行复杂的聚合逻辑。MongoDB不允许Pipeline的单个聚合操作占用过多的系统内存,如果一个聚合操作消耗20%以上的内存,那么MongoDB直接停止操作,并向客户端输出错误消息。
MapReduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。
>db.collection.mapReduce(
function() {emit(key,value);},//map 函数
function(key,values) {return reduceFunction},//reduce函数
{
out:collection,
query:document,
sort:document,
limit:number,
finalize:<function>,
verbose:<boolean>
}
)
使用MapReducel要实现两个函数Map函数和Reduce函数,Map函数调用emit(key,value),遍历 collection中所有的记录,将key与value 传递给Reduce 函数进行处理。
-
map:是JavaScript函数,负责将每一个输入文档转换为零或多个文档,生成键值对序列,作为reduce函数参数
-
reduce:是JavaScript函数,对map操作的输出做合并的化简的操作(将key-value变成key-values,也就是把values数组变成一个单一的值value)
-
out:统计结果存放集合
-
query:一个筛选条件,只有满足条件的文档才会调用map函数。
-
sort:和limit结合的sort排序参数(也是在发往map函数前给文档排序),可以优化分组机制
-
limit:发往map函数的文档数量的上限(要是没有limit,单独使用sort的用处不大)
-
finalize:可以对reduce输出结果再一次修改
-
verbose:是否包括结果信息中的时间信息,默认为fasle
db.resume.mapReduce( function() { emit(this. city, this. expectsalary);}, function(key, value) { return Array. avg(value)}, { query:{ expectsalary:{$gt:15000}}, out:"cityAvgsal"} } )















 5817
5817











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









