







1._集合概述
Java集合类存放在java.util包中,是一个用来存放对象的容器。
1. 1._数组和集合的区别
-
相同点
都是容器,可以存储多个数据
-
不同点
- 数组的长度是不可变的,集合的长度是可变的(自动扩容)
- 数组可以存基本数据类型和引用数据类型
- 集合只能存引用数据类型,如果要存基本数据类型,需要存对应的包装类
1.2._集合体系结构
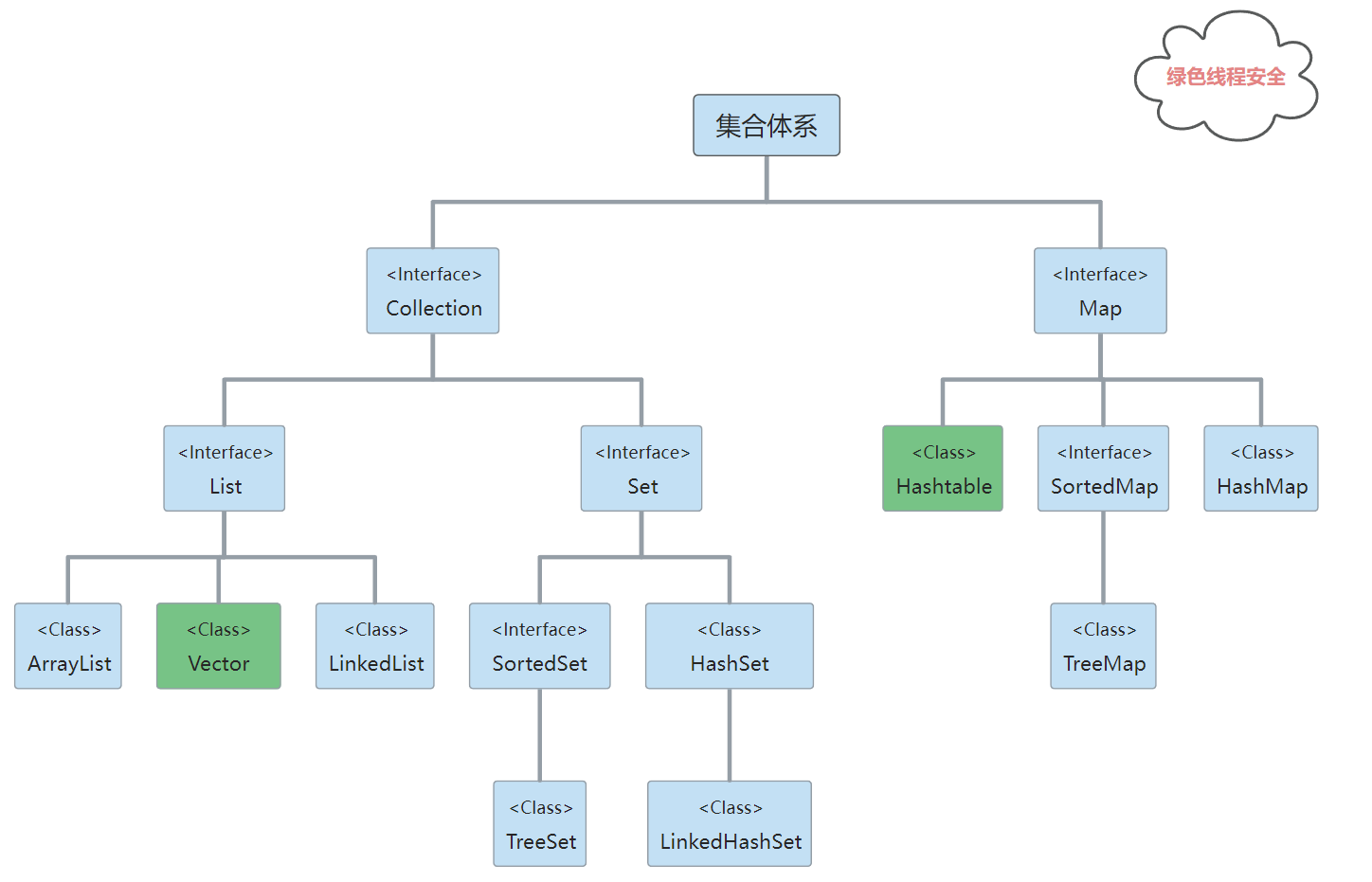
1.3._集合体系特点
Collection 接口的接口 对象的集合(单列集合)
List 底层为数组结构,有序的可重复集合,元素可以重复因为每个元素有自己的角标(索引),可以在任意位置增加删除元素,用 Iterator 实现单向遍历,也可用ListIterator 实现双向遍历。
- ArrayList:底层的数据结构是数组结构,特点是:查询很快,增 删 稍微慢点,线程不同步 。
- LinkedList:底层使用的是双向链表数据结构,特点是:增 删很快,查询慢。
- Vector:底层是数组数据结构,线程同步, 被 ArrayList 代替了,现在用的只有他的枚举。淘汰,用不到了
Set:底层是红黑树,无序的不包含重复元素的集合(用对象的 equals() 方法来区分元素是否重复),set 中最多包含一个 null 元素,只能用 Iterator 实现单项遍历,线程不同步 。
- HashSet:底层是哈希表数据结构。HashSet 的实现是依赖于 HashMap 的,HashSet 的值都是存储在 HashMap 中的。在 HashSet 的构造法中会初始化一个 HashMap 对象,HashSet 不允许值重复。因此,HashSet 的值是作为 HashMap 的 key 存储在 HashMap 中的,当存储的值已经存在时返回 false。根据 hashCode 和 equals 方法来确定元素的唯一性
- TreeSet:底层的数据结构是红黑二叉树(是一个自平衡的二叉树),可以对 Set 集合中的元素进行排序(自然循序),也可以自己写个类实现 Comparable 或者 Comparator 接口,定义自己的比较器,将其作为参数传递给 TreeSet 的构造函数。
Map:JDK1.7及之前:数组+链表,JDK1.8:数组+链表+红黑树。这个集合是存储键值对的(双列集合), 而且要确保键的唯一性
-
HashTable:底层是哈希表(散列值)数据结构,不可以存入 null 键和 null 值,该集合线程是同步的,效率比较低。出现于 JDK1.0 。
-
HashMap:底层是哈希表数据结构,可以存入 null 键和 null 值,线程不同步,效率较高,代替了 HashTable,出现于 JDK 1.2 。
-
TreeMap:底层是二叉树数据结构,不可以存入 null 键但是可以存入null 值,线程不同步,具体顺序可以由指定的Comparator来决定,或者根据键的自然顺序来判断。
TreeMap 可以保证顺序,HashMap 不保证顺序,即为无序的,Map 中可以将 Key 和 Value 单独抽取出来,其中 KeySet()方法可以将所有的 keys 抽取成一个 Set,而 Values()方法可以将 map 中所有的 values 抽取成一个集合。
2._Collection 集合概述和使用
-
Collection集合概述
- 是单列集合的顶层接口,它表示一组对象,这些对象也称为Collection的元素
- JDK 不提供此接口的任何直接实现.它提供更具体的子接口(如Set和List)实现
-
Collection集合常用方法
方法名 说明 boolean add(E e) 添加元素 boolean remove(Object o) 从集合中移除指定的元素 boolean removeIf(Object o) 根据条件进行移除 void clear() 清空集合中的元素 boolean contains(Object o) 判断集合中是否存在指定的元素 boolean isEmpty() 判断集合是否为空 int size() 集合的长度,也就是集合中元素的个数
2.1._List集合的概述和特点
- List集合的概述
- 有序集合,这里的有序指的是存取顺序,因为该集合体系有索引
- 用户可以精确控制列表中每个元素的插入位置,用户可以通过整数索引访问元素,并搜索列表中的元素
- 与Set集合不同,列表通常允许重复的元素
- List集合的特点
- 存取有序
- 可以重复
- 有索引
- List集合的常用方法
| 方法名 | 描述 |
|---|---|
| void add(int index,E element) | 在此集合中的指定位置插入指定的元素 |
| E remove(int index) | 删除指定索引处的元素,返回被删除的元素 |
| E set(int index,E element) | 修改指定索引处的元素,返回被修改的元素 |
| E get(int index) | 返回指定索引处的元素 |
LinkedList集合的特有功能
-
特有方法
方法名 说明 public void addFirst(E e) 在该列表开头插入指定的元素 public void addLast(E e) 将指定的元素追加到此列表的末尾 public E getFirst() 返回此列表中的第一个元素 public E getLast() 返回此列表中的最后一个元素 public E removeFirst() 从此列表中删除并返回第一个元素 public E removeLast() 从此列表中删除并返回最后一个元素
2.2._Set集合概述和特点
- 不可以存储重复元素
- 没有索引,不能使用普通for循环遍历
2.1.1_TreeSet集合
- 不可以存储重复元素
- 没有索引
- 可以将 元素按照规则进行排序,如下两种方式
- TreeSet():根据其元素的自然排序进行排序
- TreeSet(Comparator comparator) :根据指定的比较器进行排序
2.1.2_HashSet集合
- 底层数据结构是哈希表
- 存取无序
- 不可以存储重复元素
- 没有索引,不能使用普通for循环遍历
概念
-
HashSet底层数据结构采用哈希表实现,元素无序且唯一,线程不安全,效率高,可以存储null元素
-
元素的唯一性是靠所存储元素类型是否重写hashCode()和equals()方法来保证的,如果没有重写这两个方法,则无法保证元素的唯一性。
-
具体实现唯一性的比较过程:
-
存储元素首先会使用hash()算法函数生成一个int类型hashCode散列值,然后已经的所存储的元素的hashCode值比较,如果hashCode不相等,则所存储的两个对象一定不相等,此时存储当前的新的hashCode值处的元素对象;
-
如果hashCode相等,存储元素的对象还是不一定相等,此时会调用equals()方法判断两个对象的内容是否相等,如果内容相等,那么就是同一个对象
-
HashSet集合存储自定义类型元素,要想实现元素的唯一,要求必须重写hashCode方法和equals方法
哈希值
-
哈希值简介
是JDK根据对象的地址或者字符串或者数字算出来的int类型的数值
-
如何获取哈希值
Object类中的public int hashCode():返回对象的哈希码值
-
哈希值的特点
- 同一个对象多次调用hashCode()方法返回的哈希值是相同的
- 默认情况下,不同对象的哈希值是不同的。而重写hashCode()方法,可以实现让不同对象的哈希值相同
哈希表结构
-
JDK1.8以前
- 数组 + 链表
-
JDK1.8以后
-
节点个数少于等于8个
数组 + 链表
-
节点个数多于8个
数组 + 红黑树
-
Map集合概述和使用
-
Map集合的集合概述
- 双列集合的根接口,一个键对应一个值
- 键不可以重复,值可以重复
-
方法介绍
方法名 说明 V put(K key,V value) 添加元素 V remove(Object key) 根据键删除键值对元素 void clear() 移除所有的键值对元素 boolean containsKey(Object key) 判断集合是否包含指定的键 boolean containsValue(Object value) 判断集合是否包含指定的值 boolean isEmpty() 判断集合是否为空 int size() 集合的长度,也就是集合中键值对的个数 V get(Object key) 根据键获取值 Set< K > keySet() 获取所有键的集合 Collection< V > values() 获取所有值的集合 Set<Map.Entry<K,V>> entrySet() 获取所有键值对对象的集合 -
常用代码
public class MapDemo02 { public static void main(String[] args) { //创建集合对象 Map<String,String> map = new HashMap<String,String>(); //V put(K key,V value):添加元素 map.put("张无忌","赵敏"); map.put("郭靖","黄蓉"); map.put("杨过","小龙女"); //V remove(Object key):根据键删除键值对元素 // System.out.println(map.remove("郭靖")); // System.out.println(map.remove("郭襄")); //void clear():移除所有的键值对元素 // map.clear(); //boolean containsKey(Object key):判断集合是否包含指定的键 // System.out.println(map.containsKey("郭靖")); // System.out.println(map.containsKey("郭襄")); //boolean isEmpty():判断集合是否为空 // System.out.println(map.isEmpty()); //int size():集合的长度,也就是集合中键值对的个数 System.out.println(map.size()); //输出集合对象 System.out.println(map); } }
Map遍历的五种方式
public class Test {
public static void main(String[] args) {
//方法一:在for循环中遍历value
Map<String, String> map = new HashMap();
map.put("张无忌", "赵敏");
map.put("郭靖", "黄蓉");
map.put("杨过", "小龙女");
for (Object value : map.values()) {
System.out.println("第一种:" + value);
}
System.out.println("========================");
//方法二::通过key遍历
for (String key : map.keySet()) {
System.out.println("第二种:" + map.get(key));
}
System.out.println("========================");
//方法三::通过entrySet实现遍历 推荐
Set<Map.Entry<String, String>> entrySet = map.entrySet();
for (Map.Entry entry : entrySet) {
System.out.println("第三种:" + entry.getKey() + " :" + entry.getValue());
}
System.out.println("========================");
//方法四::通过Iterator迭代器实现遍历
Iterator<Map.Entry<String, String>> entryIterator = map.entrySet().iterator();
while (entryIterator.hasNext()) {
Map.Entry<String, String> entry = entryIterator.next();
System.out.println("第四种:" + entry.getKey() + " :" + entry.getValue());
}
System.out.println("========================");
// 方法五 :通过lambda表达式进行遍历
map.forEach((key, value) -> {
System.out.println("第五种:" + key + " :" + value);
});
}
}
HashMap集合概述和特点
- HashMap底层是哈希表结构的
- 依赖hashCode方法和equals方法保证键的唯一
- 如果键要存储的是自定义对象,需要重写hashCode和equals方法
TreeMap集合概述和特点
- TreeMap底层是红黑树结构
- 依赖自然排序或者比较器排序,对键进行排序
- 如果键存储的是自定义对象,需要实现Comparable接口或者在创建TreeMap对象时候给出比较器排序规则
TreeMap集合应用案例-集合排序
-
案例需求
- 创建一个TreeMap集合,键是学生对象(Student),值是籍贯(String),学生属性姓名和年龄,按照年龄进行排序并遍历
- 要求按照学生的年龄进行排序,如果年龄相同则按照姓名进行排序
-
代码实现
学生类
public class Student implements Comparable<Student>{ private String name; private int age; public Student() { } public Student(String name, int age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", age=" + age + '}'; } @Override public int compareTo(Student o) { //按照年龄进行排序 int result = o.getAge() - this.getAge(); //次要条件,按照姓名排序。 result = result == 0 ? o.getName().compareTo(this.getName()) : result; return result; } }测试类
public class Test1 { public static void main(String[] args) { // 创建TreeMap集合对象 TreeMap<Student, String> tm = new TreeMap<>(); // 创建学生对象 Student s1 = new Student("xiaohei", 23); Student s2 = new Student("dapang", 22); Student s3 = new Student("xiaomei", 22); // 将学生对象添加到TreeMap集合中 tm.put(s1, "江苏"); tm.put(s2, "北京"); tm.put(s3, "天津"); // 遍历TreeMap集合,打印每个学生的信息 Set<Map.Entry<Student, String>> entries = tm.entrySet(); for (Map.Entry<Student, String> entry : entries) { System.out.println(entry.getKey() + "---" + entry.getValue()); } } }
Stream概述
说白了,我理解的就是链式编程,就和jquery一样,具体概念的话,[Java 8 Stream | 菜鸟教程 (runoob.com)](https://www.runoob.com/java/java8-streams.html)
Stream(流)是一个来自数据源的元素队列并支持聚合操作
- 元素是特定类型的对象,形成一个队列。 Java中的Stream并不会存储元素,而是按需计算。
- 数据源 流的来源。 可以是集合,数组,I/O channel, 产生器generator 等。
- 聚合操作 类似SQL语句一样的操作, 比如filter, map, reduce, find, match, sorted等。
和以前的Collection操作不同, Stream操作还有两个基础的特征:
- Pipelining: 中间操作都会返回流对象本身。 这样多个操作可以串联成一个管道, 如同流式风格(fluent style)。 这样做可以对操作进行优化, 比如延迟执行(laziness)和短路( short-circuiting)。
- 内部迭代: 以前对集合遍历都是通过Iterator或者For-Each的方式, 显式的在集合外部进行迭代, 这叫做外部迭代。 Stream提供了内部迭代的方式, 通过访问者模式(Visitor)实现。
Stream流的三类方法
- 获取Stream流
- 创建一条流水线,并把数据放到流水线上准备进行操作
- 中间方法
- 流水线上的操作
- 一次操作完毕之后,还可以继续进行其他操作
- 终结方法
- 一个Stream流只能有一个终结方法
- 是流水线上的最后一个操作
生成Stream流的方式
-
Collection体系集合 =》 使用默认方法stream()生成流,
default Stream< E > stream()- list.stream();
- set.stream();
-
Map体系集合 =》 把Map转成Set集合,间接的生成流
- map.keySet().stream();
- map.values().stream();
- map.entrySet().stream();
-
数组 =》 通过Arrays中的静态方法stream生成流
- Arrays.stream(strArray);
-
同种数据类型的多个数据 =》 通过Stream接口的静态方法of(T… values)生成流
-
代码演示
public static void main(String[] args) { //Collection体系的集合可以使用默认方法stream()生成流 List<String> list = new ArrayList<String>(); list.add("demo"); Stream<String> listStream = list.stream(); listStream.forEach(System.out::println); System.out.println("==============="); Set<String> set = new HashSet<String>(); set.add("setdemo"); Stream<String> setStream = set.stream(); set.forEach(System.out::println); System.out.println("==============="); //Map体系的集合间接的生成流 Map<String,Integer> map = new HashMap<String, Integer>(); map.put("map",1); map.put("map2",2); Stream<String> keyStream = map.keySet().stream(); Stream<Integer> valueStream = map.values().stream(); Stream<Map.Entry<String, Integer>> entryStream = map.entrySet().stream(); keyStream.forEach(System.out::println); // map2 map valueStream.forEach(System.out::println); // 2 1 entryStream.forEach(System.out::println); // map2=2 map=1 System.out.println("==============="); //数组可以通过Arrays中的静态方法stream生成流 String[] strArray = {"hello","world","java"}; Stream<String> strArrayStream = Arrays.stream(strArray); strArrayStream.forEach(System.out::println); // hello world java // 通过Stream接口的静态方法of(T... values)生成流 Stream<String> strArrayStream1 = Stream.of(strArray); strArrayStream1.forEach(System.out::println); // hello world java Stream<String> strArrayStream2 = Stream.of("hello","world","java"); strArrayStream2.forEach(System.out::println); // hello world java System.out.println("==============="); }
Stream流中间操作方法
-
概念
中间操作的意思是,执行完此方法之后,Stream流依然可以继续执行其他操作
-
常见方法
方法名 说明 Stream< T > filter(Predicate predicate) 用于对流中的数据进行过滤 Stream< T > limit(long maxSize) 返回此流中的元素组成的流,截取前指定参数个数的数据 Stream< T > skip(long n) 跳过指定参数个数的数据,返回由该流的剩余元素组成的流 static < T > Stream< T > concat(Stream a, Stream b) 合并a和b两个流为一个流 Stream< T > distinct() 返回由该流的不同元素(根据Object.equals(Object) )组成的流 -
filter代码演示
public class StreamDemo01 { public static void main(String[] args) { //创建一个集合,存储多个字符串元素 ArrayList<String> list = new ArrayList<String>(); list.add("林青霞"); list.add("张曼玉"); list.add("王祖贤"); list.add("柳岩"); list.add("张敏"); list.add("张无忌"); //需求1:把list集合中以张开头的元素在控制台输出 list.stream().filter(s -> s.startsWith("张")).forEach(System.out::println); System.out.println("--------"); //需求2:把list集合中长度为3的元素在控制台输出 list.stream().filter(s -> s.length() == 3).forEach(System.out::println); System.out.println("--------"); //需求3:把list集合中以张开头的,长度为3的元素在控制台输出 list.stream().filter(s -> s.startsWith("张")).filter(s -> s.length() == 3).forEach(System.out::println); } } -
limit&skip代码演示
public class StreamDemo02 { public static void main(String[] args) { //创建一个集合,存储多个字符串元素 ArrayList<String> list = new ArrayList<String>(); list.add("林青霞"); list.add("张曼玉"); list.add("王祖贤"); list.add("柳岩"); list.add("张敏"); list.add("张无忌"); //需求1:取前3个数据在控制台输出 list.stream().limit(3).forEach(System.out::println); System.out.println("--------"); //需求2:跳过3个元素,把剩下的元素在控制台输出 list.stream().skip(3).forEach(System.out::println); System.out.println("--------"); //需求3:跳过2个元素,把剩下的元素中前2个在控制台输出 list.stream().skip(2).limit(2).forEach(System.out::println); } } -
concat&distinct代码演示
public class StreamDemo03 { public static void main(String[] args) { //创建一个集合,存储多个字符串元素 ArrayList<String> list = new ArrayList<String>(); list.add("林青霞"); list.add("张曼玉"); list.add("王祖贤"); list.add("柳岩"); list.add("张敏"); list.add("张无忌"); //需求1:取前4个数据组成一个流 Stream<String> s1 = list.stream().limit(4); //需求2:跳过2个数据组成一个流 Stream<String> s2 = list.stream().skip(2); //需求3:合并需求1和需求2得到的流,并把结果在控制台输出 // Stream.concat(s1,s2).forEach(System.out::println); //需求4:合并需求1和需求2得到的流,并把结果在控制台输出,要求字符串元素不能重复 Stream.concat(s1,s2).distinct().forEach(System.out::println); } }
Stream流终结操作方法
-
概念
终结操作的意思是,执行完此方法之后,Stream流将不能再执行其他操作
-
常见方法
方法名 说明 void forEach(Consumer action) 对此流的每个元素执行操作 long count() 返回此流中的元素数 -
代码演示
public class StreamDemo { public static void main(String[] args) { //创建一个集合,存储多个字符串元素 ArrayList<String> list = new ArrayList<String>(); list.add("林青霞"); list.add("张曼玉"); list.add("王祖贤"); list.add("柳岩"); list.add("张敏"); list.add("张无忌"); //需求1:把集合中的元素在控制台输出 // list.stream().forEach(System.out::println); //需求2:统计集合中有几个以张开头的元素,并把统计结果在控制台输出 long count = list.stream().filter(s -> s.startsWith("张")).count(); System.out.println(count); } }
Stream流的收集操作
-
概念
对数据使用Stream流的方式操作完毕后,可以把流中的数据收集到集合中
-
常用方法
方法名 说明 R collect(Collector collector) 把结果收集到集合中 -
工具类Collectors提供了具体的收集方式
方法名 说明 public static < T > Collector toList() 把元素收集到List集合中 public static < T > Collector toSet() 把元素收集到Set集合中 public static Collector toMap(Function keyMapper,Function valueMapper) 把元素收集到Map集合中 -
代码演示
public class CollectDemo { public static void main(String[] args) { //创建List集合对象 List<String> list = new ArrayList<String>(); list.add("林青霞"); list.add("张曼玉"); list.add("王祖贤"); list.add("柳岩"); /* //需求1:得到名字为3个字的流 Stream<String> listStream = list.stream().filter(s -> s.length() == 3); //需求2:把使用Stream流操作完毕的数据收集到List集合中并遍历 List<String> names = listStream.collect(Collectors.toList()); for(String name : names) { System.out.println(name); } */ //创建Set集合对象 Set<Integer> set = new HashSet<Integer>(); set.add(10); set.add(20); set.add(30); set.add(33); set.add(35); /* //需求3:得到年龄大于25的流 Stream<Integer> setStream = set.stream().filter(age -> age > 25); //需求4:把使用Stream流操作完毕的数据收集到Set集合中并遍历 Set<Integer> ages = setStream.collect(Collectors.toSet()); for(Integer age : ages) { System.out.println(age); } */ //定义一个字符串数组,每一个字符串数据由姓名数据和年龄数据组合而成 String[] strArray = {"林青霞,30", "张曼玉,35", "王祖贤,33", "柳岩,25"}; //需求5:得到字符串中年龄数据大于28的流 Stream<String> arrayStream = Stream.of(strArray).filter(s -> Integer.parseInt(s.split(",")[1]) > 28); //需求6:把使用Stream流操作完毕的数据收集到Map集合中并遍历,字符串中的姓名作键,年龄作值 Map<String, Integer> map = arrayStream.collect(Collectors.toMap(s -> s.split(",")[0], s -> Integer.parseInt(s.split(",")[1]))); Set<String> keySet = map.keySet(); for (String key : keySet) { Integer value = map.get(key); System.out.println(key + "," + value); } } }
Stream流综合练习
-
案例需求
现在有两个ArrayList集合,分别存储6名男演员名称和6名女演员名称,要求完成如下的操作
- 男演员只要名字为3个字的前三人
- 女演员只要姓林的,并且不要第一个
- 把过滤后的男演员姓名和女演员姓名合并到一起
- 把上一步操作后的元素作为构造方法的参数创建演员对象,遍历数据
演员类Actor已经提供,里面有一个成员变量,一个带参构造方法,以及成员变量对应的get/set方法
-
代码实现
演员类
public class Actor { private String name; public Actor(String name) { this.name = name; } public String getName() { return name; } public void setName(String name) { this.name = name; } }测试类
public class StreamTest { public static void main(String[] args) { //创建集合 ArrayList<String> manList = new ArrayList<String>(); manList.add("周润发"); manList.add("成龙"); manList.add("刘德华"); manList.add("吴京"); manList.add("周星驰"); manList.add("李连杰"); ArrayList<String> womanList = new ArrayList<String>(); womanList.add("林心如"); womanList.add("张曼玉"); womanList.add("林青霞"); womanList.add("柳岩"); womanList.add("林志玲"); womanList.add("王祖贤"); /* //男演员只要名字为3个字的前三人 Stream<String> manStream = manList.stream().filter(s -> s.length() == 3).limit(3); //女演员只要姓林的,并且不要第一个 Stream<String> womanStream = womanList.stream().filter(s -> s.startsWith("林")).skip(1); //把过滤后的男演员姓名和女演员姓名合并到一起 Stream<String> stream = Stream.concat(manStream, womanStream); //把上一步操作后的元素作为构造方法的参数创建演员对象,遍历数据 // stream.map(Actor::new).forEach(System.out::println); stream.map(Actor::new).forEach(p -> System.out.println(p.getName())); */ Stream.concat(manList.stream().filter(s -> s.length() == 3).limit(3), womanList.stream().filter(s -> s.startsWith("林")).skip(1)).map(Actor::new). forEach(p -> System.out.println(p.getName())); } }


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









