







TF-IDF介绍
TF-IDF是NLP中一种常用的统计方法,用以评估一个字词对于一个文件集或一个语料库中的其中一份文件的重要程度,通常用于提取文本的特征,即关键词。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
在NLP中,TF-IDF的计算公式如下: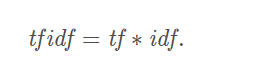
其中,tf是词频(Term Frequency),idf为逆向文件频率(Inverse Document Frequency)。
- tf为词频,即一个词语在文档中的出现频率,假设一个词语在整个文档中出现了i次,而整个文档有N个词语,则tf的值为i/N.
- idf为逆向文件频率,假设整个文档有n篇文章,而一个词语在k篇文章中出现,则idf值为
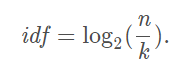
- 当然,不同地方的idf值计算公式会有稍微的不同。比如有些地方会在分母的k上加1,防止分母为0,还有些地方会让分子,分母都加上1,这是smoothing技巧。在本文中,还是采用最原始的idf值计算公式,因为这与gensim里面的计算公式一致。
文本介绍及预处理
我们将采用以下三个示例文本:
text1 = """
Football is a family of team sports that involve, to varying degrees, kicking a ball to score a goal.
Unqualified, the word football is understood to refer to whichever form of football is the most popular
in the regional context in which the word appears. Sports commonly called football in certain places
include association football (known as soccer in some countries); gridiron football (specifically American
football or Canadian football); Australian rules football; rugby football (either rugby league or rugby union);
and Gaelic football. These different variations of football are known as football codes.
"""
text2 = """
Basketball is a team sport in which two teams of five players, opposing one another on a rectangular court,
compete with the primary objective of shooting a basketball (approximately 9.4 inches (24 cm) in diameter)
through the defender's hoop (a basket 18 inches (46 cm) in diameter mounted 10 feet (3.048 m) high to a backboard
at each end of the court) while preventing the opposing team from shooting through their own hoop. A field goal is
worth two points, unless made from behind the three-point line, when it is worth three. After a foul, timed play stops
and the player fouled or designated to shoot a technical foul is given one or more one-point free throws. The team with
the most points at the end of the game wins, but if regulation play expires with the score tied, an additional period
of play (overtime) is mandated.
"""
text3 = """
Volleyball, game played by two teams, usually of six players on a side, in which the players use their hands to bat a
ball back and forth over a high net, trying to make the ball touch the court within the opponents’ playing area before
it can be returned. To prevent this a player on the opposing team bats the ball up and toward a teammate before it touches
the court surface—that teammate may then volley it back across the net or bat it to a third teammate who volleys it across
the net. A team is allowed only three touches of the ball before it must be returned over the net.
"""
这三篇文章分别是关于足球,篮球,排球的介绍,它们组成一篇文档。
接下来是文本的预处理部分。
首先是对文本去掉换行符,然后是分句,分词,再去掉其中的标点,完整的Python代码如下,输入的参数为文章text:
import nltk
import string
# 文本预处理
# 函数:text文件分句、分词,并去掉标点
def get_token(text):
text = text.replace('\n', '')
sents = nltk.sent_tokenize(text) # 分句
print(len(sents))
tokens = []
for sent in sents:
for word in nltk.word_tokenize(sent): # 分词
if word not in string.punctuation: # 去掉标点
tokens.append(word)
return tokens
print(get_token(text1))运行结果:
4
['Football', 'is', 'a', 'family', 'of', 'team', 'sports', 'that', 'involve', 'to', 'varying', 'degrees', 'kicking', 'a', 'ball', 'to', 'score', 'a', 'goal', 'Unqualified', 'the', 'word', 'football', 'is', 'understood', 'to', 'refer', 'to', 'whichever', 'form', 'of', 'football', 'is', 'the', 'most', 'popular', 'in', 'the', 'regional', 'context', 'in', 'which', 'the', 'word', 'appears', 'Sports', 'commonly', 'called', 'football', 'in', 'certain', 'places', 'include', 'association', 'football', 'known', 'as', 'soccer', 'in', 'some', 'countries', 'gridiron', 'football', 'specifically', 'American', 'football', 'or', 'Canadian', 'football', 'Australian', 'rules', 'football', 'rugby', 'football', 'either', 'rugby', 'league', 'or', 'rugby', 'union', 'and', 'Gaelic', 'football', 'These', 'different', 'variations', 'of', 'football', 'are', 'known', 'as', 'football', 'codes']接着,去掉文章中的停用词(stopwords),然后统计每个单词的出现次数,完整的Python代码如下,输入的参数为文章text:
from nltk.corpus import stopwords # 停用词
from collections import Counter
# 对原始的text文件去掉停用词
# 生成count字典,即每个单词的出现次数
def make_count(text):
tokens = get_token(text)
filtered = [w for w in tokens if w not in stopwords.words('english')] # 去掉停用词
count = Counter(filtered)
return count
print(make_count(text1))
以text1为例,生成的count字典如下:
Counter({'football': 12, 'rugby': 3, 'word': 2, 'known': 2, 'Football': 1, 'family': 1, 'team': 1, 'sports': 1, 'involve': 1, 'varying': 1, 'degrees': 1, 'kicking': 1, 'ball': 1, 'score': 1, 'goal': 1, 'Unqualified': 1, 'understood': 1, 'refer': 1, 'whichever': 1, 'form': 1, 'popular': 1, 'regional': 1, 'context': 1, 'appears': 1, 'Sports': 1, 'commonly': 1, 'called': 1, 'certain': 1, 'places': 1, 'include': 1, 'association': 1, 'soccer': 1, 'countries': 1, 'gridiron': 1, 'specifically': 1, 'American': 1, 'Canadian': 1, 'Australian': 1, 'rules': 1, 'either': 1, 'league': 1, 'union': 1, 'Gaelic': 1, 'These': 1, 'different': 1, 'variations': 1, 'codes': 1})
Gensim中的TF-IDF
对文本进行预处理后,对于以上三个示例文本,我们都会得到一个count字典,里面是每个文本中单词的出现次数。下面,我们将用gensim中的已实现的TF-IDF模型,来输出每篇文章中TF-IDF排名前三的单词及它们的tfidf值,完整的代码如下:
from nltk.corpus import stopwords
from gensim import corpora, models, matutils
# training by gensim tfidf model
def get_words(text):
tokens = get_token(text)
filtered = [w for w in tokens if w not in stopwords.words('english')]
return filtered
# get text
count1, count2, count3 = get_words(text1), get_words(text2), get_words(text3)
count_list = [count1, count2, count3]
# training by tfidf model in gensim
dictionary = corpora.Dictionary(count_list)
new_dict = {v: k for k, v in dictionary.token2id.items()}
corpus2 = [dictionary.doc2bow(count) for count in count_list]
tfidf2 = models.TfidfModel(corpus2)
corpus_tfidf = tfidf2[corpus2]
# output
print('\nTraining by gensim tfidf model......\n')
for i, doc in enumerate(corpus_tfidf):
print('Top words in document %d' % (i + 1))
sorted_words = sorted(doc, key=lambda x: x[1], reverse=True) # type=list
for num, score in sorted_words[:3]:
print('\tWord: %s, Tfidf: %s' % (new_dict[num], round(score, 5)))
运行结果:
Training by gensim tfidf model......
Top words in document 1
Word: football, Tfidf: 0.84766
Word: rugby, Tfidf: 0.21192
Word: known, Tfidf: 0.14128
Top words in document 2
Word: play, Tfidf: 0.29872
Word: cm, Tfidf: 0.19915
Word: diameter, Tfidf: 0.19915
Top words in document 3
Word: net, Tfidf: 0.45775
Word: teammate, Tfidf: 0.34331
Word: across, Tfidf: 0.22888输出的结果还是比较符合我们的预期的,比如关于足球的文章中提取了football, rugby关键词,关于篮球的文章中提取了plat, cm关键词,关于排球的文章中提取了net, teammate关键词。
自己动手实践TF-IDF模型
有了以上我们对TF-IDF模型的理解,其实我们自己也可以动手实践一把,这是学习算法的最佳方式!
以下是笔者实践TF-IDF的代码(接文本预处理代码):
import math
# 计算tf
def tf(word, count):
return count[word] / sum(count.values())
# 计算count_list有多少个文件包含word
def n_containing(word, count_list):
return sum(1 for count in count_list if word in count)
# 计算idf
def idf(word, count_list):
return math.log2(len(count_list) / n_containing(word, count_list)) # 对数以2为底
# 计算tf-idf
def tfidf(word, count, count_lsit):
return tf(word, count) * idf(word, count_list)
# tf-idf测试
# TF-IDF测试
count1, count2, count3 = make_count(text1), make_count(text2), make_count(text3)
countlist = [count1, count2, count3]
print("Training by original algorithm......\n")
for i, count in enumerate(countlist):
print("Top words in document %d" % (i + 1))
scores = {word: tfidf(word, count, countlist) for word in count}
sorted_words = sorted(scores.items(), key=lambda x: x[1], reverse=True) # type=list
# sorted_words = matutils.unitvec(sorted_words)
for word, score in sorted_words[:3]:
print("\tWord: %s, TF-IDF: %s" % (word, round(score, 5)))
运行结果:
Training by original algorithm......
Top words in document 1
Word: football, TF-IDF: 0.30677
Word: rugby, TF-IDF: 0.07669
Word: word, TF-IDF: 0.05113
Top words in document 2
Word: play, TF-IDF: 0.05283
Word: one, TF-IDF: 0.03522
Word: shooting, TF-IDF: 0.03522
Top words in document 3
Word: net, TF-IDF: 0.10226
Word: teammate, TF-IDF: 0.07669
Word: bat, TF-IDF: 0.05113可以看到,笔者自己动手实践的TF-IDF模型提取的关键词与gensim一致,至于篮球中为什么后两个单词不一致,是因为这些单词的tfidf一样,随机选择的结果不同而已。但是有一个问题,那就是计算得到的tfidf值不一样,这是什么原因呢?
究其原因,也就是说,gensim对得到的tf-idf向量做了规范化(normalize),将其转化为单位向量。因此,我们需要在刚才的代码中加入规范化这一步,代码如下:
import numpy as np
# 对向量做规范化, normalize
def unitvec(sorted_words):
lst = [item[1] for item in sorted_words]
L2Norm = math.sqrt(sum(np.array(lst) * np.array(lst)))
unit_vector = [(item[0], item[1] / L2Norm) for item in sorted_words]
return unit_vector
# tf-idf测试
# TF-IDF测试
count1, count2, count3 = make_count(text1), make_count(text2), make_count(text3)
countlist = [count1, count2, count3]
print("Training by original algorithm......\n")
for i, count in enumerate(countlist):
print("Top words in document %d" % (i + 1))
scores = {word: tfidf(word, count, countlist) for word in count}
sorted_words = sorted(scores.items(), key=lambda x: x[1], reverse=True) # type=list
sorted_words = unitvec(sorted_words)
for word, score in sorted_words[:3]:
print("\tWord: %s, TF-IDF: %s" % (word, round(score, 5)))
运行结果:
Training by original algorithm......
Top words in document 1
Word: football, TF-IDF: 0.84766
Word: rugby, TF-IDF: 0.21192
Word: word, TF-IDF: 0.14128
Top words in document 2
Word: play, TF-IDF: 0.29872
Word: one, TF-IDF: 0.19915
Word: shooting, TF-IDF: 0.19915
Top words in document 3
Word: net, TF-IDF: 0.45775
Word: teammate, TF-IDF: 0.34331
Word: bat, TF-IDF: 0.22888现在的输出结果与gensim得到的结果一致!
全部代码:
import nltk
import string
import math
import numpy as np
from nltk.corpus import stopwords # 停用词
from collections import Counter
from gensim import corpora, models, matutils
text1 = """
Football is a family of team sports that involve, to varying degrees, kicking a ball to score a goal.
Unqualified, the word football is understood to refer to whichever form of football is the most popular
in the regional context in which the word appears. Sports commonly called football in certain places
include association football (known as soccer in some countries); gridiron football (specifically American
football or Canadian football); Australian rules football; rugby football (either rugby league or rugby union);
and Gaelic football. These different variations of football are known as football codes.
"""
text2 = """
Basketball is a team sport in which two teams of five players, opposing one another on a rectangular court,
compete with the primary objective of shooting a basketball (approximately 9.4 inches (24 cm) in diameter)
through the defender's hoop (a basket 18 inches (46 cm) in diameter mounted 10 feet (3.048 m) high to a backboard
at each end of the court) while preventing the opposing team from shooting through their own hoop. A field goal is
worth two points, unless made from behind the three-point line, when it is worth three. After a foul, timed play stops
and the player fouled or designated to shoot a technical foul is given one or more one-point free throws. The team with
the most points at the end of the game wins, but if regulation play expires with the score tied, an additional period
of play (overtime) is mandated.
"""
text3 = """
Volleyball, game played by two teams, usually of six players on a side, in which the players use their hands to bat a
ball back and forth over a high net, trying to make the ball touch the court within the opponents’ playing area before
it can be returned. To prevent this a player on the opposing team bats the ball up and toward a teammate before it touches
the court surface—that teammate may then volley it back across the net or bat it to a third teammate who volleys it across
the net. A team is allowed only three touches of the ball before it must be returned over the net.
"""
# 文本预处理
# 函数:text文件分句、分词,并去掉标点
def get_token(text):
text = text.replace('\n', '')
sents = nltk.sent_tokenize(text) # 分句
print(len(sents))
tokens = []
for sent in sents:
for word in nltk.word_tokenize(sent): # 分词
if word not in string.punctuation: # 去掉标点
tokens.append(word)
return tokens
print(get_token(text1))
# 对原始的text文件去掉停用词
# 生成count字典,即每个单词的出现次数
def make_count(text):
tokens = get_token(text)
filtered = [w for w in tokens if w not in stopwords.words('english')] # 去掉停用词
count = Counter(filtered)
return count
print(make_count(text1))
# training by gensim tfidf model
def get_words(text):
tokens = get_token(text)
filtered = [w for w in tokens if w not in stopwords.words('english')]
return filtered
# get text
count1, count2, count3 = get_words(text1), get_words(text2), get_words(text3)
count_list = [count1, count2, count3]
# training by tfidf model in gensim
dictionary = corpora.Dictionary(count_list)
new_dict = {v: k for k, v in dictionary.token2id.items()}
corpus2 = [dictionary.doc2bow(count) for count in count_list]
tfidf2 = models.TfidfModel(corpus2)
corpus_tfidf = tfidf2[corpus2]
# output
print('\nTraining by gensim tfidf model......\n')
for i, doc in enumerate(corpus_tfidf):
print('Top words in document %d' % (i + 1))
sorted_words = sorted(doc, key=lambda x: x[1], reverse=True) # type=list
for num, score in sorted_words[:3]:
print('\tWord: %s, Tfidf: %s' % (new_dict[num], round(score, 5)))
# 计算tf
def tf(word, count):
return count[word] / sum(count.values())
# 计算count_list有多少个文件包含word
def n_containing(word, count_list):
return sum(1 for count in count_list if word in count)
# 计算idf
def idf(word, count_list):
return math.log2(len(count_list) / n_containing(word, count_list)) # 对数以2为底
# 计算tf-idf
def tfidf(word, count, count_lsit):
return tf(word, count) * idf(word, count_list)
# 对向量做规范化, normalize
def unitvec(sorted_words):
lst = [item[1] for item in sorted_words]
L2Norm = math.sqrt(sum(np.array(lst) * np.array(lst)))
unit_vector = [(item[0], item[1] / L2Norm) for item in sorted_words]
return unit_vector
# tf-idf测试
# TF-IDF测试
count1, count2, count3 = make_count(text1), make_count(text2), make_count(text3)
countlist = [count1, count2, count3]
print("Training by original algorithm......\n")
for i, count in enumerate(countlist):
print("Top words in document %d" % (i + 1))
scores = {word: tfidf(word, count, countlist) for word in count}
sorted_words = sorted(scores.items(), key=lambda x: x[1], reverse=True) # type=list
sorted_words = unitvec(sorted_words)
for word, score in sorted_words[:3]:
print("\tWord: %s, TF-IDF: %s" % (word, round(score, 5)))
运行结果:
4
['Football', 'is', 'a', 'family', 'of', 'team', 'sports', 'that', 'involve', 'to', 'varying', 'degrees', 'kicking', 'a', 'ball', 'to', 'score', 'a', 'goal', 'Unqualified', 'the', 'word', 'football', 'is', 'understood', 'to', 'refer', 'to', 'whichever', 'form', 'of', 'football', 'is', 'the', 'most', 'popular', 'in', 'the', 'regional', 'context', 'in', 'which', 'the', 'word', 'appears', 'Sports', 'commonly', 'called', 'football', 'in', 'certain', 'places', 'include', 'association', 'football', 'known', 'as', 'soccer', 'in', 'some', 'countries', 'gridiron', 'football', 'specifically', 'American', 'football', 'or', 'Canadian', 'football', 'Australian', 'rules', 'football', 'rugby', 'football', 'either', 'rugby', 'league', 'or', 'rugby', 'union', 'and', 'Gaelic', 'football', 'These', 'different', 'variations', 'of', 'football', 'are', 'known', 'as', 'football', 'codes']
4
Counter({'football': 12, 'rugby': 3, 'word': 2, 'known': 2, 'Football': 1, 'family': 1, 'team': 1, 'sports': 1, 'involve': 1, 'varying': 1, 'degrees': 1, 'kicking': 1, 'ball': 1, 'score': 1, 'goal': 1, 'Unqualified': 1, 'understood': 1, 'refer': 1, 'whichever': 1, 'form': 1, 'popular': 1, 'regional': 1, 'context': 1, 'appears': 1, 'Sports': 1, 'commonly': 1, 'called': 1, 'certain': 1, 'places': 1, 'include': 1, 'association': 1, 'soccer': 1, 'countries': 1, 'gridiron': 1, 'specifically': 1, 'American': 1, 'Canadian': 1, 'Australian': 1, 'rules': 1, 'either': 1, 'league': 1, 'union': 1, 'Gaelic': 1, 'These': 1, 'different': 1, 'variations': 1, 'codes': 1})
4
4
3
Training by gensim tfidf model......
Top words in document 1
Word: football, Tfidf: 0.84766
Word: rugby, Tfidf: 0.21192
Word: known, Tfidf: 0.14128
Top words in document 2
Word: play, Tfidf: 0.29872
Word: cm, Tfidf: 0.19915
Word: diameter, Tfidf: 0.19915
Top words in document 3
Word: net, Tfidf: 0.45775
Word: teammate, Tfidf: 0.34331
Word: across, Tfidf: 0.22888
4
4
3
Training by original algorithm......
Top words in document 1
Word: football, TF-IDF: 0.84766
Word: rugby, TF-IDF: 0.21192
Word: word, TF-IDF: 0.14128
Top words in document 2
Word: play, TF-IDF: 0.29872
Word: one, TF-IDF: 0.19915
Word: shooting, TF-IDF: 0.19915
Top words in document 3
Word: net, TF-IDF: 0.45775
Word: teammate, TF-IDF: 0.34331
Word: bat, TF-IDF: 0.22888


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









