






 本文详细介绍了二分类模型中的关键评估指标,如混淆矩阵、准确性、精确度、召回率、F1分数、ROC曲线、AUC值、KS统计和Lift提升度。此外,还探讨了PSI稳定性指标在评估模型适用性的重要性。这些指标帮助我们全面了解和优化模型性能。
本文详细介绍了二分类模型中的关键评估指标,如混淆矩阵、准确性、精确度、召回率、F1分数、ROC曲线、AUC值、KS统计和Lift提升度。此外,还探讨了PSI稳定性指标在评估模型适用性的重要性。这些指标帮助我们全面了解和优化模型性能。
分类模型评估指标,下面是二分类的示例(多分类时,把其中一类列为正样本,其他归为负样本进行统计即可)
一、混淆矩阵
| 预测值 | ||
|---|---|---|
| 真实值 | 1 | 0 |
| 1 | TP | FN(type Ⅱ error) |
| 0 | FP(type Ⅰ error) | TN |
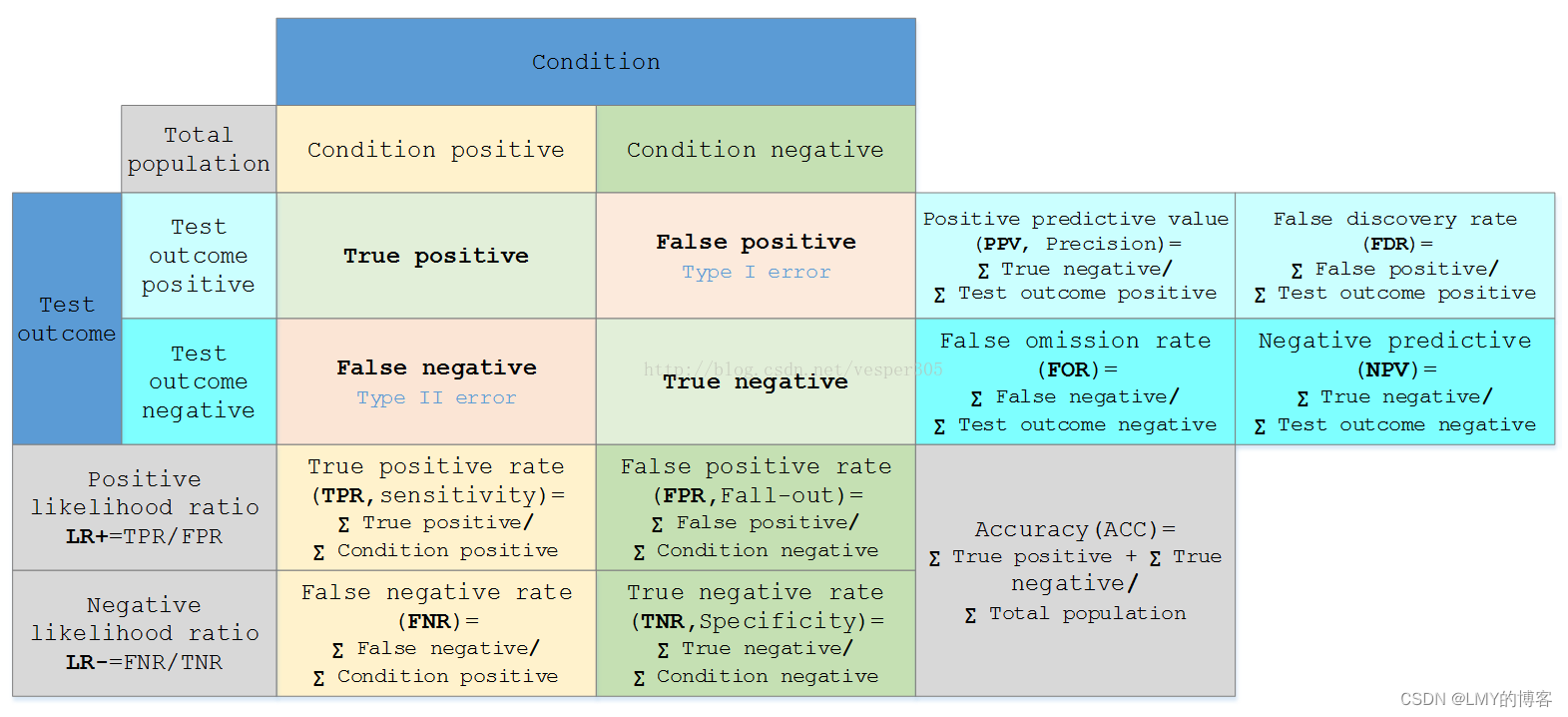
TP = True Postive = 真阳性;
FP = False Positive = 假阳性;
FN = False Negative = 假阴性;
TN = True Negative = 真阴性
二、accuracy、precision、recall
accuracy(准确性,ACC,) = (TP+TN)/(TP+FP+FN+TN)
precision(精确度,PPV, positive predictive value ,阳性预测值) = TP/(TP+FP)= 真阳性/预测为正的样本
recall(召回率,TPR,True Positive Rate,或者敏感度,sensitivity,真阳率) = TP/(TP+FN)=真阳性/真实为正的样本
false positive rate(假阳率,FPR) = FP/(TN+FP)=真实为负预测为正的样本数/真实为负的样本
True Negative Rate(真阴率,TNR,特异度,specificity)= TN/(TN + FP)=真阴性的样本数/真实为负的样本
False negtive rate(假阴率,FNR)= FN/(FP+FN)=假阴性/真实为正的样本
False discovery rate(FDR,假阳发现率)= FP/(TP+FP)=假阳性/预测为正的样本
False omission rate(FOR,假阴发现率)= FN/(FN+TN)=假阴性/预测为负的样本
Negative predictive(NPV,阴性预测值) = TN/(FN+TN)=真阴性/预测为负的样本
三、F1、roc、auc、ks
1、F1
F1-值(F1-score)= 2TP / (2TP+FP+FN);
2、roc
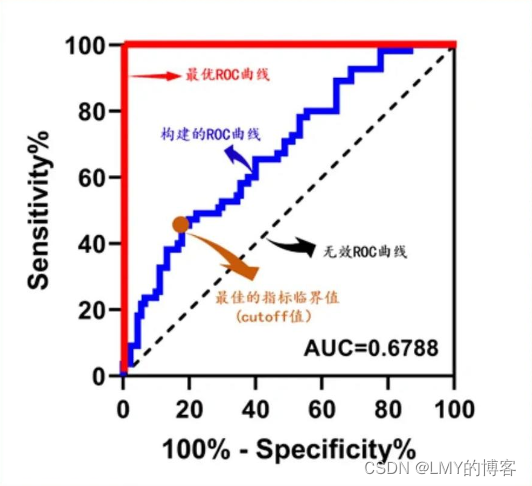
含义和计算逻辑:ROC曲线是基于混淆矩阵得出的。一个二分类模型的阈值可能设定为高或低,每种阈值的设定会得出不同的 FPR 和 TPR ,将同一模型每个阈值的 (FPR, TPR) 坐标都画在 ROC 空间里,就成为特定模型的ROC曲线。x轴:FPR(假阳率)或1-TNR(真阴率);y轴:TPR(召回率);按照probability阈值由小到大划分计算TPR、FPR矩阵,即为roc。ROC值一般在0.5-1.0之间。值越大表示模型判断准确性越高,即越接近1越好。ROC=0.5表示模型的预测能力与随机结果没有差别。
应用场景:ROC曲线不固定阈值,允许中间状态的存在,利于使用者结合专业知识,权衡漏诊与误诊的影响,选择一个更加的阈值作为诊断参考值。
3、auc
含义和计算逻辑:roc曲线下的面积,由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。AUC越接近1.0,检测方法真实性越高;等于0.5时,则真实性最低,无应用价值。AUC的含义通俗理解:随机给定一个正样本和一个负样本,用一个分类器进行分类和预测,该正样本的得分比该负样本的得分要大的概率。
应用场景:衡量模型预测的质量,而不考虑选择什么分类阈值。
AUC = 1,是完美分类器
AUC = [0.85, 0.95], 效果很好
AUC = [0.7, 0.85], 效果一般
AUC = [0.5, 0.7],效果较低,但用于预测股票已经很不错了
AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测
4、ks
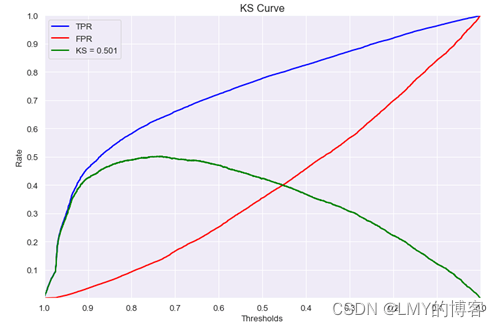
含义和计算逻辑:KS(Kolmogorov-Smirnov):KS用于模型风险区分能力进行评估,用以评估模型对好、坏客户的判别区分能力,指标衡量的是好坏样本累计分部之间的差值。好坏样本累计差异越大,KS指标越大,那么模型的风险区分能力越强,KS值范围在0%-100%。
KS 曲线是两条线,其横轴是 “阈值”(区间序号,按概率排序的等份),纵轴是 TPR(上面那条)与 FPR(下面那条)的值,值范围[0,1] 。两条曲线之间之间相距最远的地方对应的阈值,就是最能划分模型的阈值。
KS 取的是TPR和FPR差值的最大值,能够找到一个最优的阈值。KS=max(TPR−FPR)
应用场景:表示模型将正负样本区分开的能力,一般应用于金融风控领域。
KS: <20% : 差
KS: 20%-40% : 一般
KS: 41%-50% : 好
KS: 51%-75% : 非常好
KS: >75% : 过高,需要谨慎的验证模型
5、Lift提升度
含义和计算逻辑:Lift提升度(指数)衡量的是评分模型对坏样本的预测能力与不利用模型随机选择相比,模型的预测能力“变好”了多少倍,变好的倍数就是Lift,Lift越大,模型的效果越好,LIFT大于1说明模型表现优于随机。
lift = precision / 正样本占比 = ppv / [p/(p+N)]
6、PSI
含义和计算逻辑:由于模型是以特定时间段的建模样本开发的,此模型是否适用于开发样本之外的样本(时间段不同或客群不同),必须经过稳定性测试才能得知。稳定度指标(population stability index ,PSI)可衡量测试样本和建模样本评分的分布差异。PSI表示的就是按分数分档后,针对不同客群样本,或者不同时间的样本,population分布是否有变化,就是看各个分数区间内样本占总样本的占比是否有显著变化。
PSI = ∑(actual−except)ln(except/actual )
应用场景:评估模型整体的稳定性,也可以评估特征的稳定性,一般PSI小于0.25意味着变化在可接受范围内。
PSI<0.1:样本分布有微小变化
0.1⩽PSI<0.2:样本分布有变化
PSI>0.2:样本分布有显著变化


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









