






一、认识influxDB
1.1 InfluxDB 的使用场景
InfluxDB 是一种时序数据库,时序数据库全程时间序列数据库(Time Series Database,TSDB,用于存储大量基于时间的数据,时序数据(Time Series Data)指的是一系列基于时间的数据,例如 CPU 利用率,北京的房价变化趋势,某一地区的温度变化等。
比如。我们可以写一个程序将服务器上 CPU 的使用情况每隔 10 秒钟向 InfluxDB 中写 入一条数据。接着,我们写一个查询语句,查询过去 30 秒 CPU 的平均使用情况,然后让这个查询语句也每隔 10 秒钟执行一次。最终,我们配置一条报警规则,如果查询语句的执行结果>xxx,就立刻触发报警。
1.2 为什么不用关系型数据库
1.2.1 写入性能
关系型数据库也是支持时间戳的,也能够基于时间戳进行查询。但是,从我们的使用场景出发,需要注意数据库的写入性能。通常,关系型数据库会采用 B+树数据结构,在数据写入时,有可能会触发叶裂变,从而产生了对磁盘的随机读写,降低写入速度。 当前市面上的时序数据库通常都是采用 LSM Tree 的变种,顺序写磁盘来增强数据的写入能力。
1.2.2 数据价值
时序数据库一般用于指标监控场景。这个场景的数据有一个非常明显的特点就是冷热差别明显。通常,指标监控只会使用近期一段时间的数据,比如我只查询某个设备最近 10 分钟的记录,10 分钟前的数据我就不再用了。那么这 10 分钟前的数据,对我们来说就是冷数据,应该被压缩放到磁盘里去来节省空间。而热数据因为经常要用,数据库就应该让它留在内存里,等待查询。而市面上的时序数据库大都有类似的设计。
1.2.3 时间不可倒流,数据只写不改
时序数据是描述一个实体在不同时间所处的不同状态。
就像是我们打开任务管理器,查看 CPU 的使用情况。我发现 CPU 占用率太高了,于是杀死了一个进程,但 10 秒前的数据不会因为我关闭进程再发生改变了。
这是时序数据的一大特点。与之相应,时序数据库基本上是插入操作较多,而且还没有什么更新需求。
1.2.4 了解字段含义
在 InfluxDB 中,我们可以粗略的将要存入的一条数据看作一个虚拟的 key 和其对应的 value(field value),格式如下:
cpu_usage,host=server01,region=us-west value=0.64 1434055562000000000
虚拟的 key 包括以下几个部分: database, retention policy, measurement, tag sets, field name, timestamp。 database 和 retention policy 在上面的数据中并没有体现,通常在插入数据时候指定响应字段。
- database: 数据库名,在 InfluxDB 中可以创建多个数据库,不同数据库中的数据文件是隔离存放的,存放在磁盘上的不同目录。
- retention policy: 存储策略,用于设置数据保留的时间,每个数据库刚开始会自动创建一个默认的存储策略 autogen,数据保留时间为永久,之后用户可以自己设置,例如保留最近2小时的数据。插入和查询数据时如果不指定存储策略,则使用默认存储策略,且默认存储策略可以修改。InfluxDB 会定期清除过期的数据。
- measurement: 测量指标名,例如 cpu_usage 表示 cpu 的使用率。
- tag sets: tags 在 InfluxDB 中会按照字典序排序,不管是 tagk 还是 tagv,只要不一致就分别属于两个 key,例如 host=server01,region=us-west 和 host=server02,region=us-west 就是两个不同的 tag set。
- field name: 例如上面数据中的 value 就是 fieldName,InfluxDB 中支持一条数据中插入多个 fieldName,这其实是一个语法上的优化,在实际的底层存储中,是当作多条数据来存储。
- timestamp: 每一条数据都需要指定一个时间戳,在 TSM 存储引擎中会特殊对待,以为了优化后续的查询操作。
Series
series 相当于是 InfluxDB 中一些数据的集合,在同一个 database 中,retention policy、measurement、tag sets 完全相同的数据同属于一个 series,同一个 series 的数据在物理上会按照时间顺序排列存储在一起。
series 的 key 为 measurement + 所有 tags 的序列化字符串,这个 key 在之后会经常用到。
代码中的结构如下:
type Series struct {
mu sync.RWMutex
Key string // series key
Tags map[string]string // tags
id uint64 // id
measurement *Measurement // measurement
}
Point
InfluxDB 中单条插入语句的数据结构,series + timestamp 可以用于区别一个 point,也就是说一个 point 可以有多个 field name 和 field value。
注意:如果提交具有相同measurement,tag set和timestamp,但具有不同field set的行协议,则field set将变为旧field set与新field set的合并,并且如果有任何冲突以新field set为准
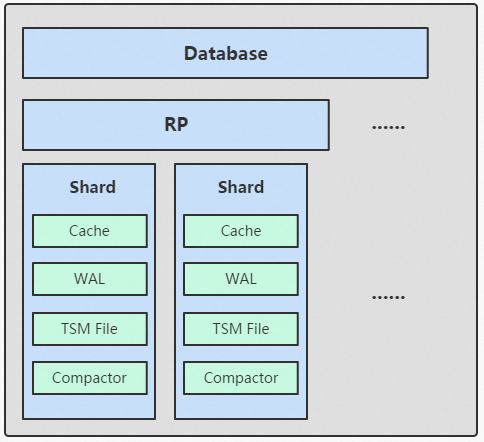
Shard
shard 在 InfluxDB 中是一个比较重要的概念,它和 retention policy 相关联。每一个存储策略下会存在许多 shard,每一个 shard 存储一个指定时间段内的数据,并且不重复,例如 7点-8点 的数据落入 shard0 中,8点-9点的数据则落入 shard1 中。每一个 shard 都对应一个底层的 tsm 存储引擎,有独立的 cache、wal、tsm file。
创建数据库时会自动创建一个默认存储策略,永久保存数据,对应的在此存储策略下的 shard 所保存的数据的时间段为 7 天,计算的函数如下:
func shardGroupDuration(d time.Duration) time.Duration {
if d >= 180*24*time.Hour || d == 0 { // 6 months or 0
return 7 * 24 * time.Hour
} else if d >= 2*24*time.Hour { // 2 days
return 1 * 24 * time.Hour
}
return 1 * time.Hour
}
1.2.5 TSM 存储引擎
TSM 存储引擎主要由几个部分组成: cache、wal、tsm file、compactor。
目录与文件结构
InfluxDB 的数据存储主要有三个目录。
默认情况下是 meta, wal 以及 data 三个目录。
meta 用于存储数据库的一些元数据,meta 目录下有一个 meta.db 文件。
wal 目录存放预写日志文件,以 .wal 结尾。data 目录存放实际存储的数据文件,以 .tsm 结尾。这两个目录下的结构是相似的,其基本结构如下:
wal 目录结构
# wal 目录结构
-- wal
-- mydb
-- autogen
-- 1
-- _00001.wal
-- 2
-- _00035.wal
-- 2hours
-- 1
-- _00001.wal
# data 目录结构
-- data
-- mydb
-- autogen
-- 1
-- 000000001-000000003.tsm
-- 2
-- 000000001-000000001.tsm
-- 2hours
-- 1
-- 000000002-000000002.tsm
其中 mydb 是数据库名称,autogen 和 2hours 是存储策略名称,再下一层目录中的以数字命名的目录是 shard 的 ID 值,比如 autogen 存储策略下有两个 shard,ID 分别为 1 和 2,shard 存储了某一个时间段范围内的数据。再下一级的目录则为具体的文件,分别是 .wal 和 .tsm 结尾的文件。
1.3 1.X 的 TICK 技术栈与 2.X 的进一步融合
根据上文的介绍,我们首先可以知道时序数据一般用在监控场景。大体上,数据的应
用可以分为 4 步走。
(1)数据采集
(2)存储
(3)查询(包括聚合操作)
(4)报警
这样一看,只给一个数据库其实只能完成数据的存储和查询功能,上游的采集和下游的报警都需要自己来实现。因此 InfluxData 在 InfluxDB1.X 的时候推出了 TICK 生态来推出start 全套的解决方案。
TICK4 个字母分别对应 4 个组件。
⚫ T : Telegraf - 数据采集组件,收集&发送数据到 InfluxDB。
⚫ I : InfluxDB - 存储数据&发送数据到 Chronograf。
⚫ C : Chronograf - 总的用户界面,起到总的管理功能。
⚫ K : Kapacitor - 后台处理报警信息。
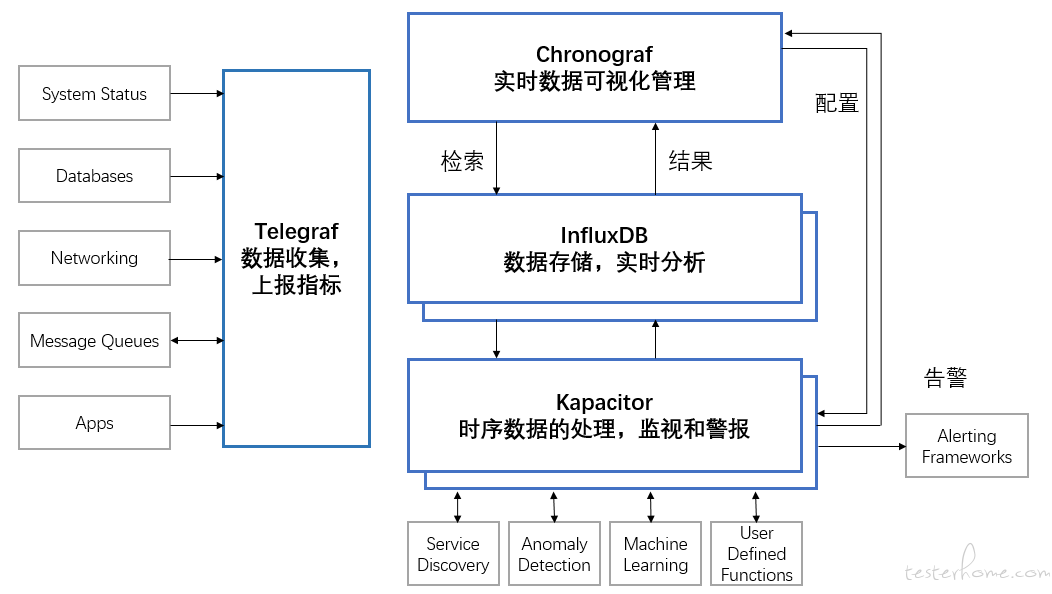
到了 2.x,TICK 进一步融合,ICK 的功能全部融入了 InfluxDB,仅需安装 InfluxDB 就能得到一个管理页面,而且附带了定时任务和报警功能。
1.4 安装
https://jasper-zhang1.gitbooks.io/influxdb/content/Introduction/installation.html
linux环境下安装
下载:
wget https://dl.influxdata.com/influxdb/releases/influxdb2-2.6.1-linux-amd64.tar.gz
解压:
tar xvzf path/to/influxdb2-2.6.1-linux-amd64.tar.gz
启动:
./influxd
window下如果出现:Could not load template file no-server-data or one of its included components
关闭本地代理
web浏览器输入ip:8086直接访问:
二、Web UI
2.1数据源相关
2.1.1 Load Data 加载数据
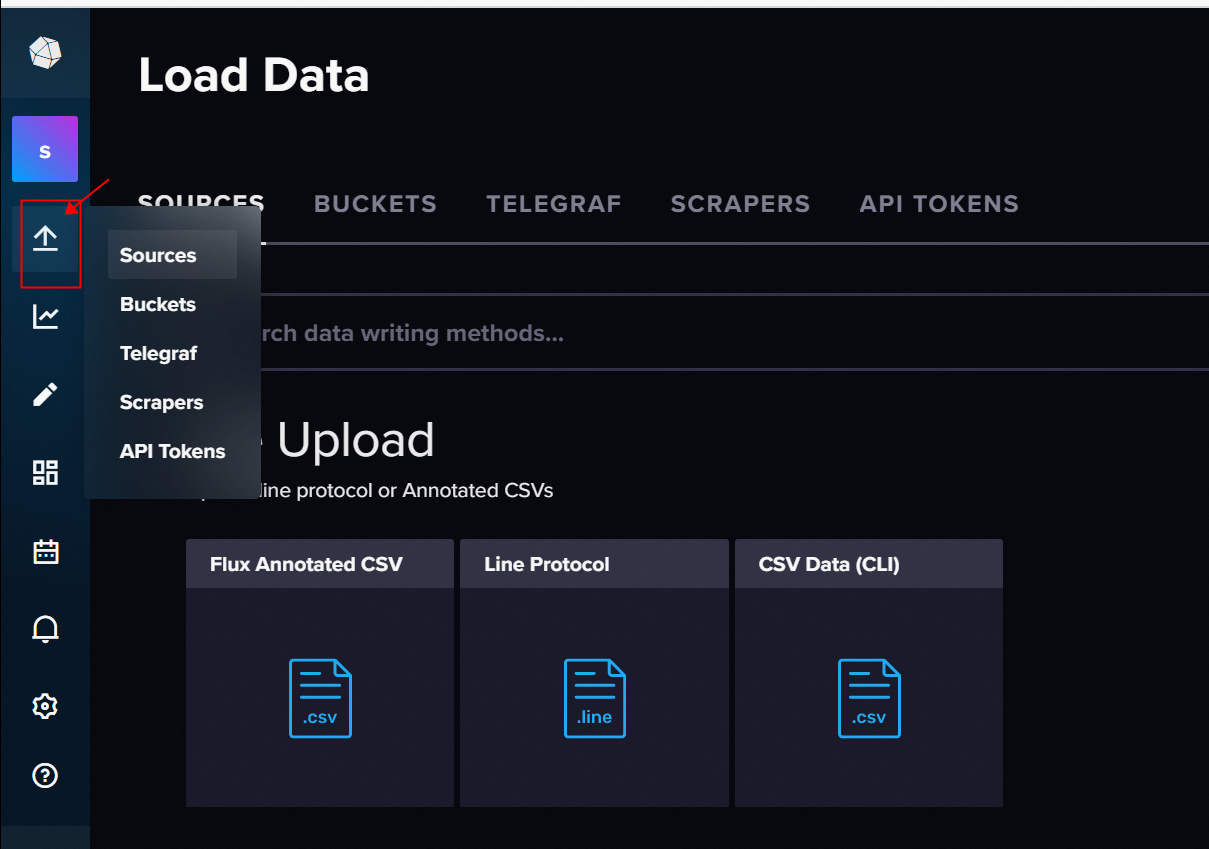
1、File Upload
在 Web UI 上,你可以用文件的方式上传数据,前提是文件中的数据符合 InfluxDB 支
持的类型,包括 CSV、带 Flux 注释的 CSV 和 InfluxDB 行协议。
2、写入 InfluxDB 的代码模板
InfluxDB 提供了各种编程语言的连接库,你甚至可以在前端嵌入向 InfluxDB 写入数据
的代码,因为 InfluxDB 向外提供了一套功能完整的 REST API。
3、配置 Telegraf 的输入插件
Telegraf 是一个插件化的数据采集组件,在这里你可以找一下没有对应你的目标数据源
的插件,点击它的 logo。可以看到这个插件配置的写法,但是关于这方面的内容,还是建
议参考 Telegraf 的官方文档,那个更细更全一些。
2.1.2 管理桶
创建、设置有效期、设置label
2.1.3添加数据

2.1.4 influxDB行协议
InfluxDB 行协议是 InfluxDB 数据库独创的一种数据格式,它由纯文本构成,只要数据 符合这种格式,就能使用 InfluxDB 的 HTTP API 将数据写入数据库。
在 InfluxDB 行协议中,一条数据和另一条数据之间使用换行符分隔, 所以一行就是一条数据。另外,在时序数据库领域,一行数据一行数据由下面 4 种元素构成。
(1)measurement(测量名称)
(2)Tag Set(标签集)
(3)Field Set(字段集)
(4)Timestamp(时间戳)

1、measurement(测量名称)
必需
可以理解为mysql中的table,大小写敏感,不可以用下划线打头
2、Tag Set(标签集)
标签应该用在一些值的范围有限(可枚举)的,不太会变动的属性上。比如传感器的类型和 id 等等。在 InfluxDB 中一个 Tag 相当于一个索引。给数据点加上 Tag 有利于将来对数据进行检索。但是如果索引太多了,就会减慢数据的插入速度。
可选
键值关系使用=表示
多个键值对之间使用英文逗号 , 分隔
标签的键和值都区分大小写
标签的键不能以下划线 _ 开头
键的数据类型:字符串
值的数据类型:字符串
3、Field Set(字段集)
必需
一个数据点上所有的字段键值对,键是字段名,值是数据点的值。
一个数据点至少要有一个字段。
字段集的键是大小写敏感的。
键的数据类型:字符串
值的数据类型:浮点数 | 整数 | 无符号整数 | 字符串 | 布尔值
4、Timestamp(时间戳)
可选
数据点的 Unix 时间戳,每个数据点都可以制定自己的时间戳。
如果时间戳没有指定。那么 InfluxDB 就使用当前系统的时间戳。
数据类型:Unix timestamp
如果你的数据里的时间戳不是以纳秒为单位的,那么需要在数据写入时指定时间戳的
精度。
5、空格
行协议中的空格决定了 InfluxDB 如何解释数据点,第一个未转义的空格将测量值&Tag Set(标签集)与 Field Set(字段集)分开。第二个未转义空格将 Field Set(字段级)和时间戳分开。

6、数据类型和格式
1)Float 浮点型:默认类型,64位
2)Integer 整数:64位,需要在数字末尾追加 i
3)UInteger 无符号整数:64位,需要在数字末尾追加 u
4)String 字符串:长度不超过64kb
5)Boolean 布尔值:true:t,T,true,True,TRUE;false:f,F,false,False,FALSE
6)Unix Timestamp(Unix 时间戳):默认纳秒
7、注释
以井号#开头的一行被当做注释
2.1.5 Telegraf
Telegraf 是 InfluxDB 生态中的一个数据采集组件,它可以将各种时序数据自动采集到
InfluxDB。现在,Telegraf 不仅仅是 InfluxDB 的数据采集组件了,很多时序数据库都支持与 Telegraf 进行协作,不少类似的时序数据收集组件选择在 Telegraf 的基础上二次开发。
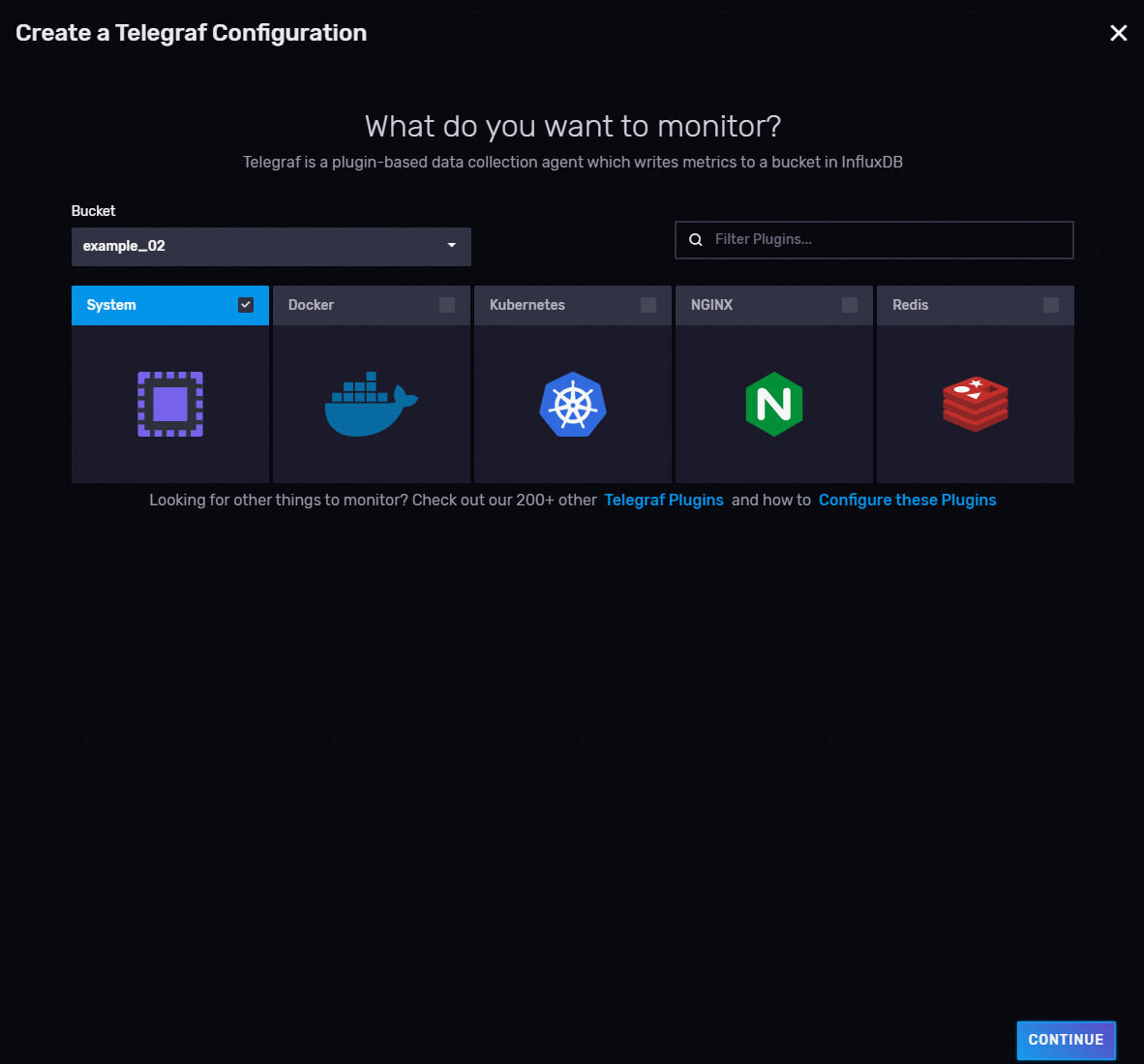
1、新建telegraf配置,指定bucket和模板
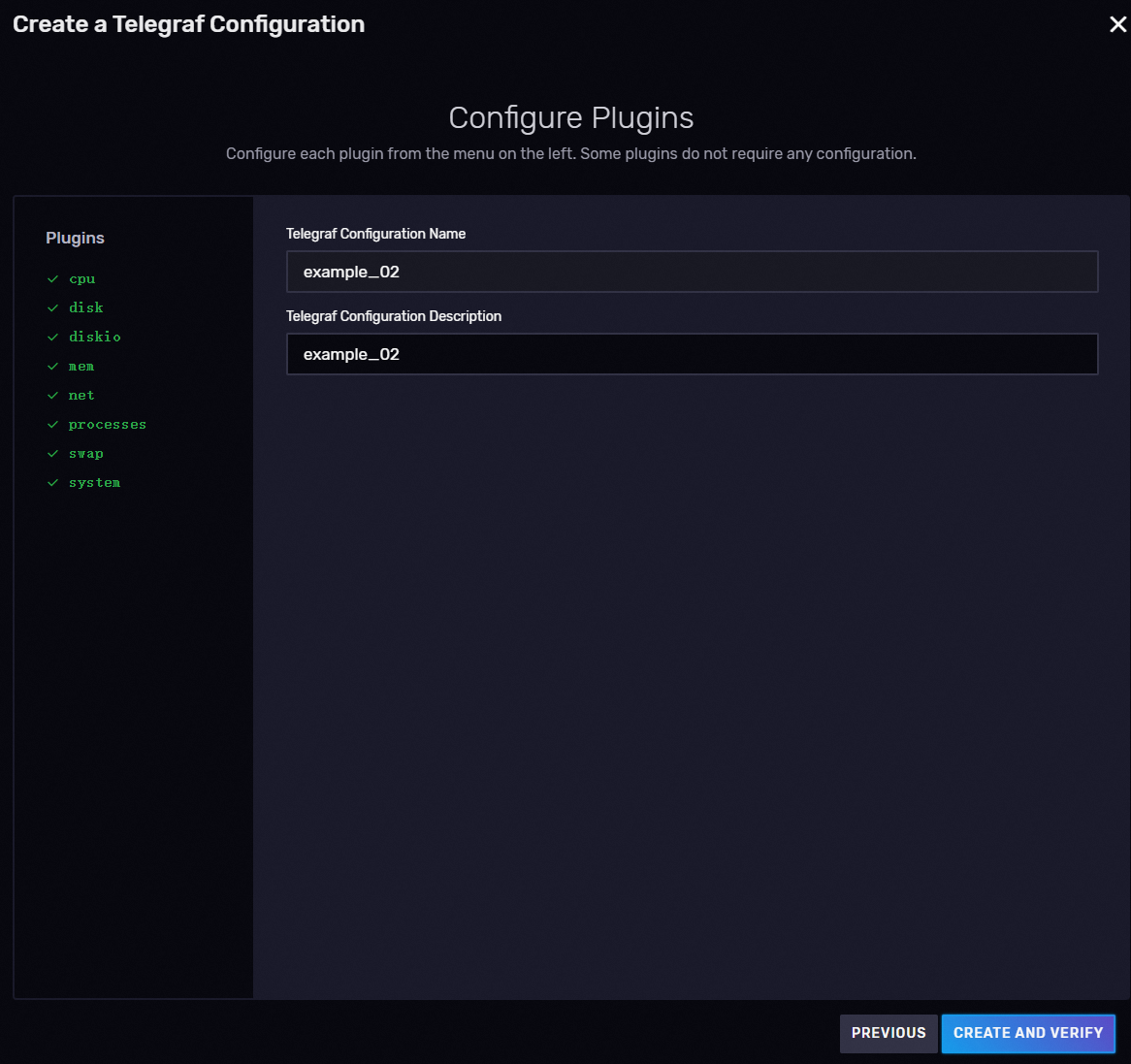
2、指定名称描述
3、设置环境变量token
下面是启动命令
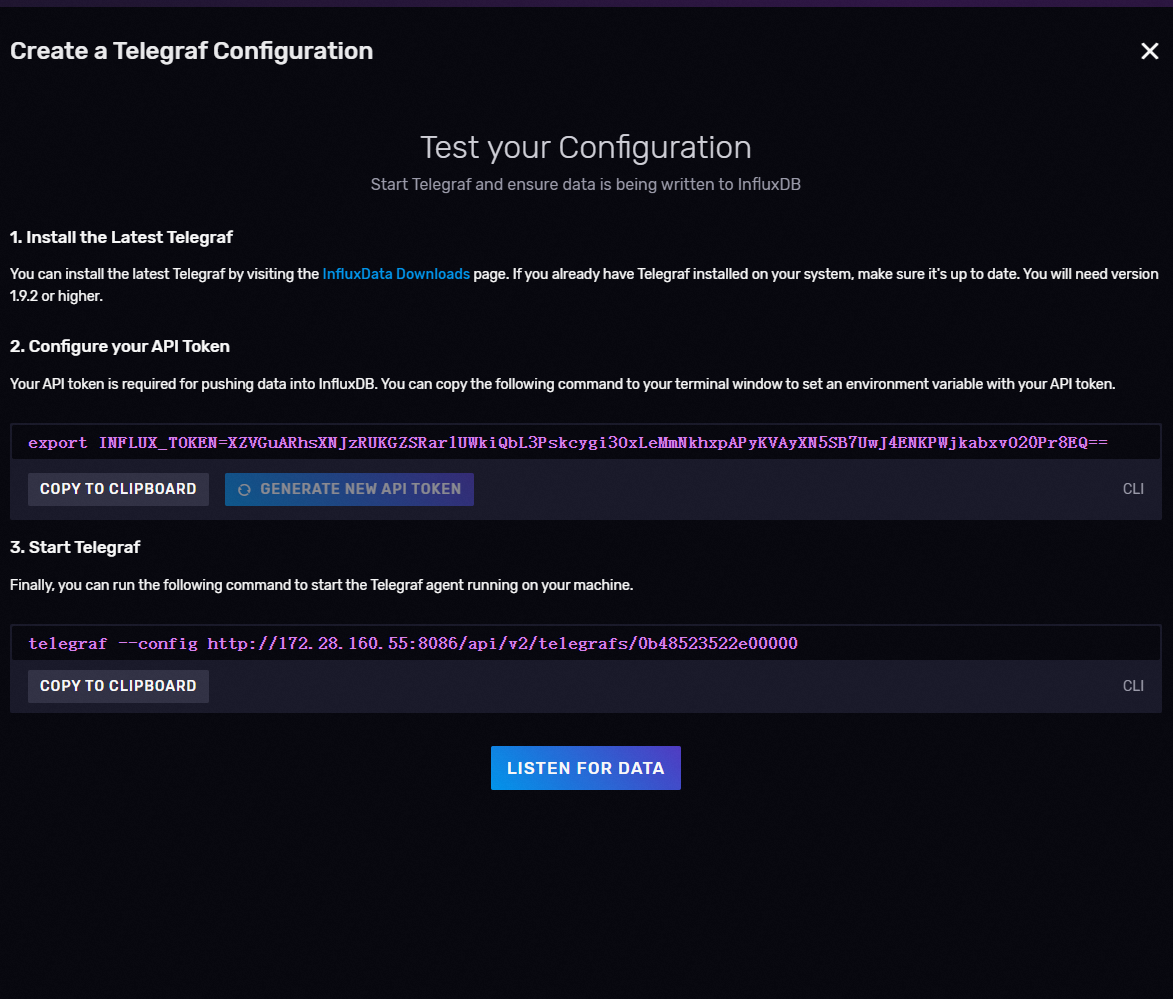
4、下载安装Telegraf
wget https://dl.influxdata.com/telegraf/releases/telegraf-
1.23.4_linux_amd64.tar.gz
tar -zxvf telegraf-1.23.4_linux_amd64.tar.gz
设置token,然后启动
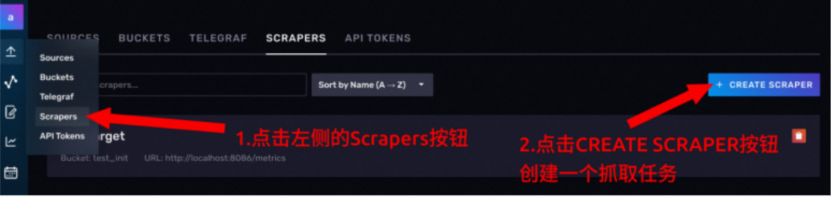
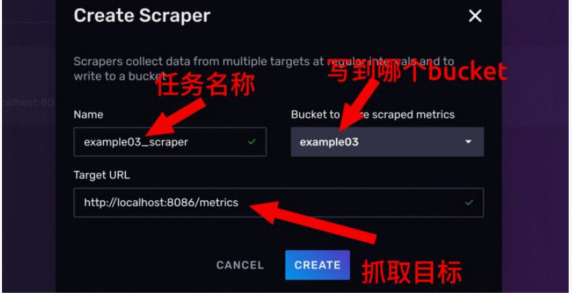
2.1.6 scrapers 管理抓取任务
抓取任务就是你给定一个 URL,InfluxDB 每隔一段时间去访问这个链接,把访问到的数据入库。
目标 URL 暴露出来的数据格式必须得是Prometheus 数据格式:

InfluxDB 自身暴露的监控接口
http://localhost:8086/metrics 来查看 InfluxDB 暴露出来的性能数据。这里面
有,InfluxDB 的 GC 情况
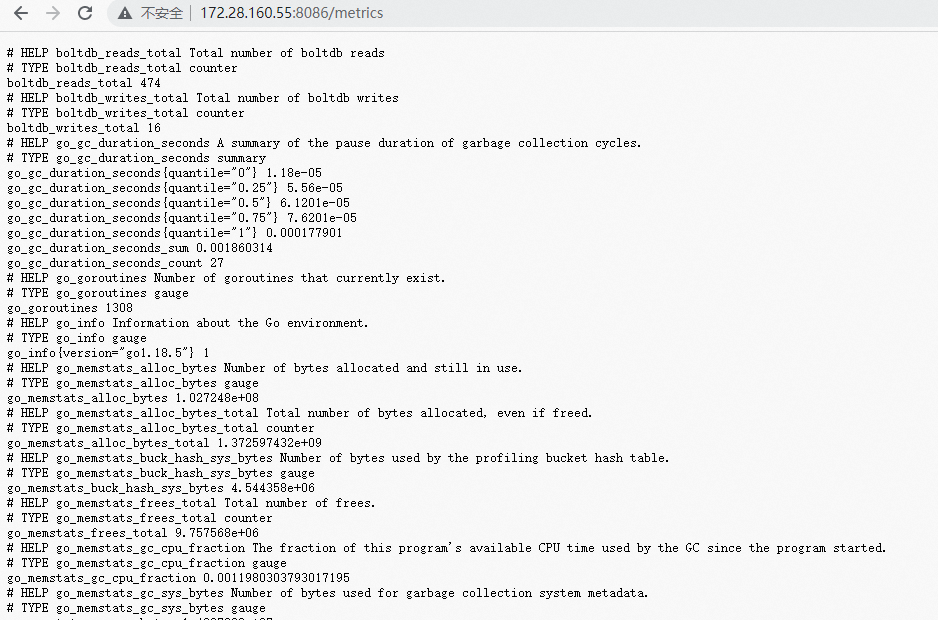
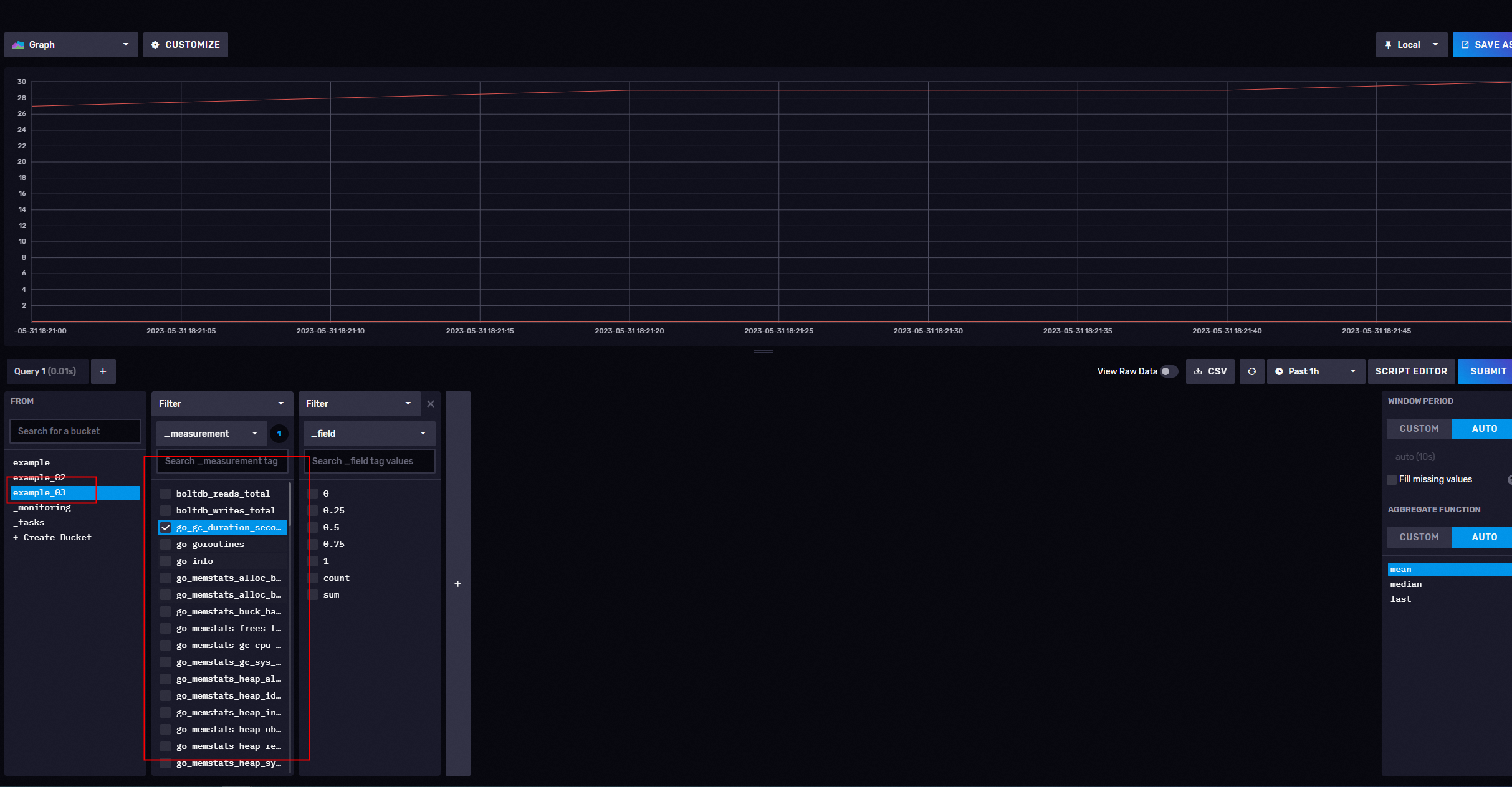
以及各个 API 的使用情况,如图所示,说的是各个 API 被谁请求过多少次。

注意:截止当前版本,用户无法去自定义抓取间隔。InfluxDB 会每隔 10 秒一次去
抓取数据
3.1.7 API token
influxdb 会向外暴露一套 HTTP API。我们后面要学的命令行工具什么的, 其实都是封装的对 influxdb 的 http 请求。所以,在 InfluxDB 中,对权限的管理主要体现 在 API 的 Tokens 上。客户端会将 token 放到 http 的请求头上,influxdb 服端就根据客户 端发来的请求头部的 token,来判断你能不能对某个存储桶读写,能不能删除存储桶,创建仪表盘等。
2.2 查询工具
2.2.1 Date Explorer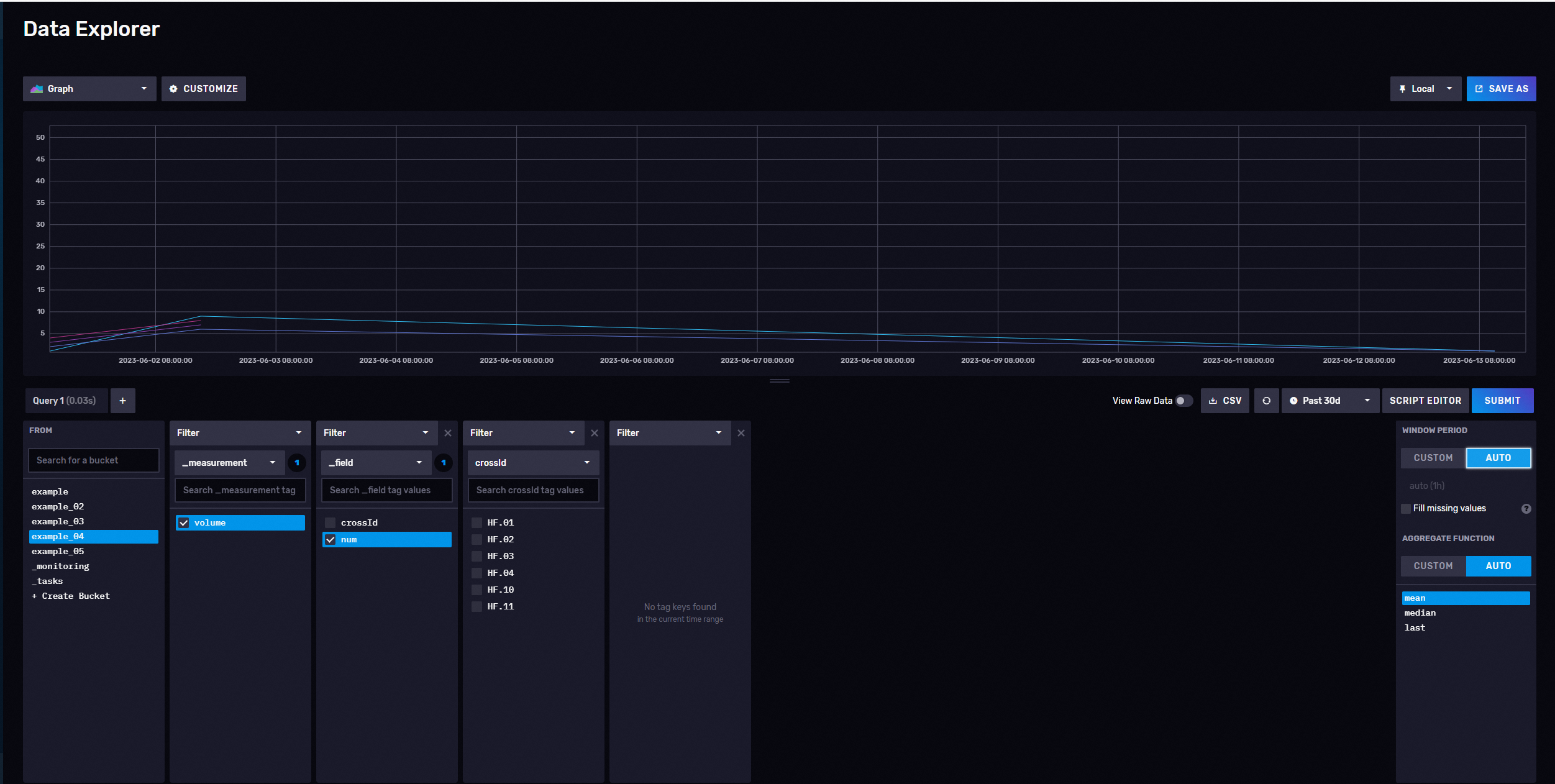
2.2.2 Notebook
Notebook 是 InfluxDB2.x 推出的功能,交互上模仿了 Jupyter NoteBook。它可以用于开
发、文档编写、运行代码和展示结果。
你可以将 InfluxDB 笔记本视为按照顺序处理数据的集合。每个步骤都由一个“单元格”
表示。一个单元格可以执行查询、可视化、处理或将数据写入存储桶等操作。Notebook 可
以帮你完成下述操作 :
- 执行 FLUX 代码、可视化数据和添加注释性的片段
- 报警或者计划任务
- 数据进行降采样或者清洗
- 生成要和团队分享的 Runbooks
- 将数据回写到存储桶
Notebook 和 DataExplorer 相比,主要是交互风格上的不同。DataExplorer 倾向于一锤
子买卖,而 Notebook 可以将数据展示拆分为一个又一个具体的步骤。另外,NoteBook 可
以用来开发告警任务 DataExplorer 则不能。
三、Http Api
1、新增
curl --request POST 'http://172.28.160.55:8086/api/v2/write?org=banma&bucket=example_05&precision=s' \
--header 'Authorization: Token eFbagosKUBZyDMAGzhSPPe-uSAiBRz_Niq4Wosb6ule2xLNbwF_IPA-RzxeTk8Ay7zb72O3pXP1C0a1QI2hFbQ==' \
--header 'Content-Type: text/plain' \
--header 'Accept: application/json' \
--data '
volume,crossId=HF.01 num=5 1686624185
volume,crossId=HF.02 num=6 1686624185
'
precision指定时间戳格式:“ms” “s” “us” “ns”
2、查询
curl --request POST 'http://172.28.160.55:8086/api/v2/query?org=banma' \
--header 'Content-Type: application/vnd.flux' \
--header 'Accept: application/csv' \
--header 'Authorization: Token eFbagosKUBZyDMAGzhSPPe-uSAiBRz_Niq4Wosb6ule2xLNbwF_IPA-RzxeTk8Ay7zb72O3pXP1C0a1QI2hFbQ==' \
--data 'from(bucket:"example_05")
|> range(start: -10d)
|> filter(fn: (r) => r._measurement == "volume")'
四、命令行工具
1、下载influx-cli
https://github.com/influxdata/influx-cli/releases/tag/v2.4.0
解压:tar -zxvf influxdb2-client-2.4.0-linux-amd64.tar.gz
2、连接
./influx config create --config-name influx.conf \
--host-url http://localhost:8086 \
--org banma --token eFbagosKUBZyDMAGzhSPPe-uSAiBRz_Niq4Wosb6ule2xLNbwF_IPA-RzxeTk8Ay7zb72O3pXP1C0a1QI2hFbQ== \
--active
3、常用命令
1)展示所有bucket


- 创建bucket
./influx bucket create \
--name example_04 \
--retention 30d

3)新增数据
./influx write --bucket example_04 "
volume,crossId=HF.01 num=1
volume,crossId=HF.02 num=2
volume,crossId=HF.03 num=3
volume,crossId=HF.04 num=4
"

4)查询数据
./influx query 'from(bucket: "example_04")
|> range(start: -15d)
|> filter(fn: (r) => r["_measurement"] == "volume")
|> filter(fn: (r) => r["crossId"] == "HF.01")'

具体参考:https://docs.influxdata.com/influxdb/v2.4/reference/cli/
4、influxQL查询
InfluxDB 1.x数据存储在数据库(database)中,InfluxDB OSS 2.0之后,数据存储在桶(bucket)中。因为InfluxQL使用了1.x数据模型,在使用InfluxQL进行查询之前,必须将桶映射到一个数据库和保留策略(DBRP)。可以这样理解:InfluxQL只有数据库才能使用,如果想要在桶上也能使用只有将桶映射成数据库。
使用InfluxQL查询桶数据,需要完成以下步骤:
1)确认桶有映射;
influx v1 dbrp list
或者
influx v1 dbrp list --bucket-id 167a05e4c5cb110f

2)映射未映射的桶;
./influx v1 dbrp create \
--db example_04_db \
--rp example_04_rp \
--bucket-id 167a05e4c5cb110f \
--default

3)使用InfluxQL查询已映射的桶。
1、启动influxQL Shell
./influx v1 shell
2、查询
SELECT * FROM example_04_db.example_04_rp.volume where crossId = 'HF.01'
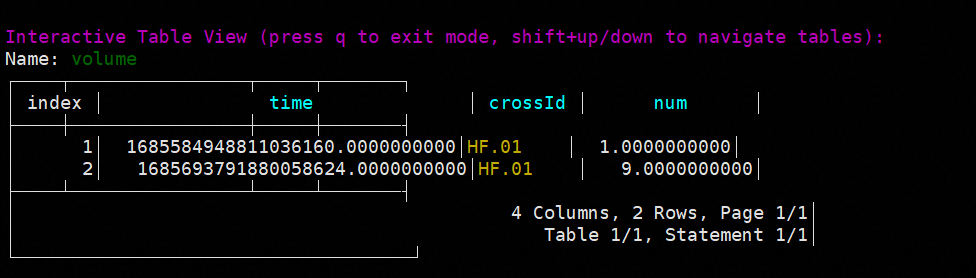
或者
curl --get http://localhost:8086/query?db=example_04_db \
--header "Authorization: Token eFbagosKUBZyDMAGzhSPPe-uSAiBRz_Niq4Wosb6ule2xLNbwF_IPA-RzxeTk8Ay7zb72O3pXP1C0a1QI2hFbQ==" \
--data-urlencode "q=SELECT * FROM example_04_db.example_04_rp.volume"



















 1022
1022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









