









【Docker】中级篇
- (一)Docker复杂安装详说
- 【1】安装mysql主从复制
- (1)新建主服务器容器实例3307
- (2)进入/mydata/mysql-master/conf目录下新建my.cnf
- (3)修改完配置后重启master实例
- (4)进入mysql-master容器
- (5)master容器实例内创建数据同步用户
- (6)新建从服务器容器实例3308
- (7)进入/mydata/mysql-master/conf目录下新建my.cnf
- (8)修改完配置后重启slave实例
- (9)在主数据库中查看主从同步状态
- (10)进入mysql-slave容器
- (11)在从数据库中配置主从复制
- (12)在从数据库中查看主从同步状态
- (13)在从数据库中开启主从同步
- (14)查看从数据库状态发现已经同步
- (15)主从复制测试
- 【2】安装redis集群
- (二)DockerFile解析
- (三)Docker微服务实战
- (四)Docker网络
- (五)Docker-compose容器编排
- (六)Docker轻量级可视化工具Portainer
- (七)Docker容器监控之CAdvisor+InfluxDB+Granfana
- (八)终章&总结
(一)Docker复杂安装详说
【1】安装mysql主从复制
(1)新建主服务器容器实例3307
docker run -p 3307:3306 --name mysql-master -v /mydata/mysql-master/log:/var/log/mysql -v /mydata/mysql-master/data:/var/lib/mysql -v /mydata/mysql-master/conf:/etc/mysql -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7

(2)进入/mydata/mysql-master/conf目录下新建my.cnf

[mysqld]
##设置server-id,同一局域网中需要唯一
server_id=101
##指定不需要同步的数据库名称
binlog-ignore-db=mysql
##开启二进制日志功能
log-bin=mall-mysql-bin
##设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
##设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
##二进制日志过期清理时间。默认值为0,表示不自动清理
expire_logs_days=7
##跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断
##如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
(3)修改完配置后重启master实例
docker restart mysql-master

(4)进入mysql-master容器
docker exec -it mysql-master /bin/bash
mysql -uroot -proot
(5)master容器实例内创建数据同步用户
CREATE USER 'slave'@'%' IDENTIFIED BY '123456';
GRANT REPLICATION SLAVE,REPLICATION CLIENT ON *.* TO 'slave'@'%';
(6)新建从服务器容器实例3308
docker run -p 3308:3306 --name mysql-slave -v /mydata/mysql-slave/log:/var/log/mysql -v /mydata/mysql-slave/data:/var/lib/mysql -v /mydata/mysql-slave/conf:/etc/mysql -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7

(7)进入/mydata/mysql-master/conf目录下新建my.cnf

[mysqld]
##设置server-id,同一局域网中需要唯一
server_id=102
##指定不需要同步的数据库名称
binlog-ignore-db=mysql
##开启二进制日志功能
log-bin=mall-mysql-bin
##设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
##设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
##二进制日志过期清理时间。默认值为0,表示不自动清理
expire_logs_days=7
##跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断
##如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
##relay_log配置中继日志
relay_log=mall-mysql-relay-bin
##log_slave_updates表示slave将复制事件写进自己的二进制日志
log_slave_updates=1
##slave设置为只读(具有super权限的用户除外)
read_only=1
(8)修改完配置后重启slave实例
docker restart mysql-slave
(9)在主数据库中查看主从同步状态
show master status;

(10)进入mysql-slave容器
docker exec -it mysql-slave /bin/bash
mysql -uroot -proot
(11)在从数据库中配置主从复制
change master to master_host='192.168.19.11',master_user='slave',master_password='123456',master_port=3307,master_log_file='mall-mysql-bin.000001',master_log_pos=617,master_connect_retry=30;
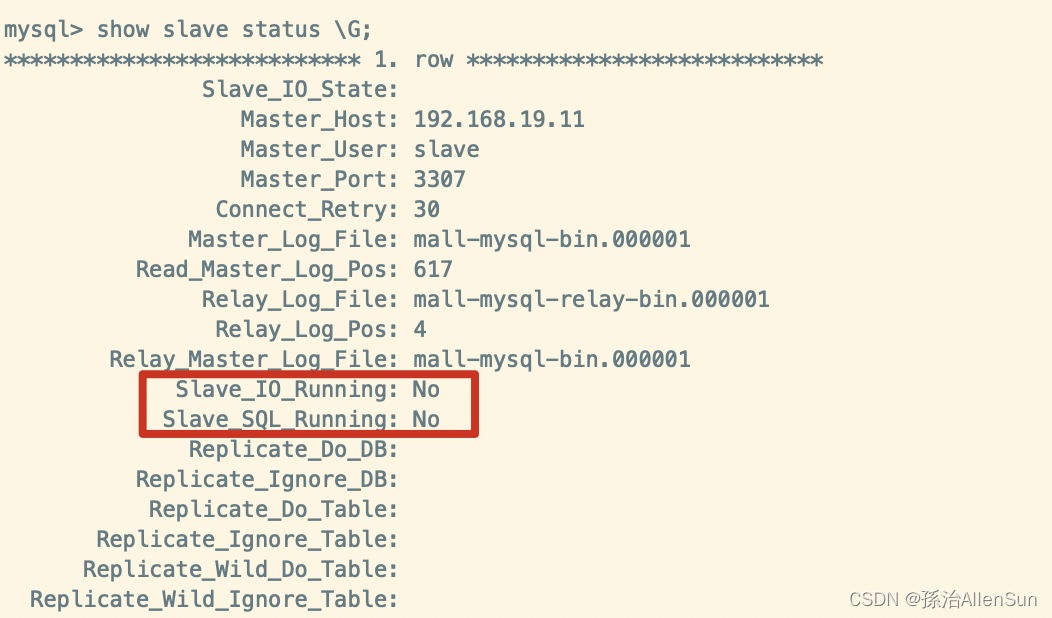
(12)在从数据库中查看主从同步状态
show slave status \G;
(13)在从数据库中开启主从同步
start slave;
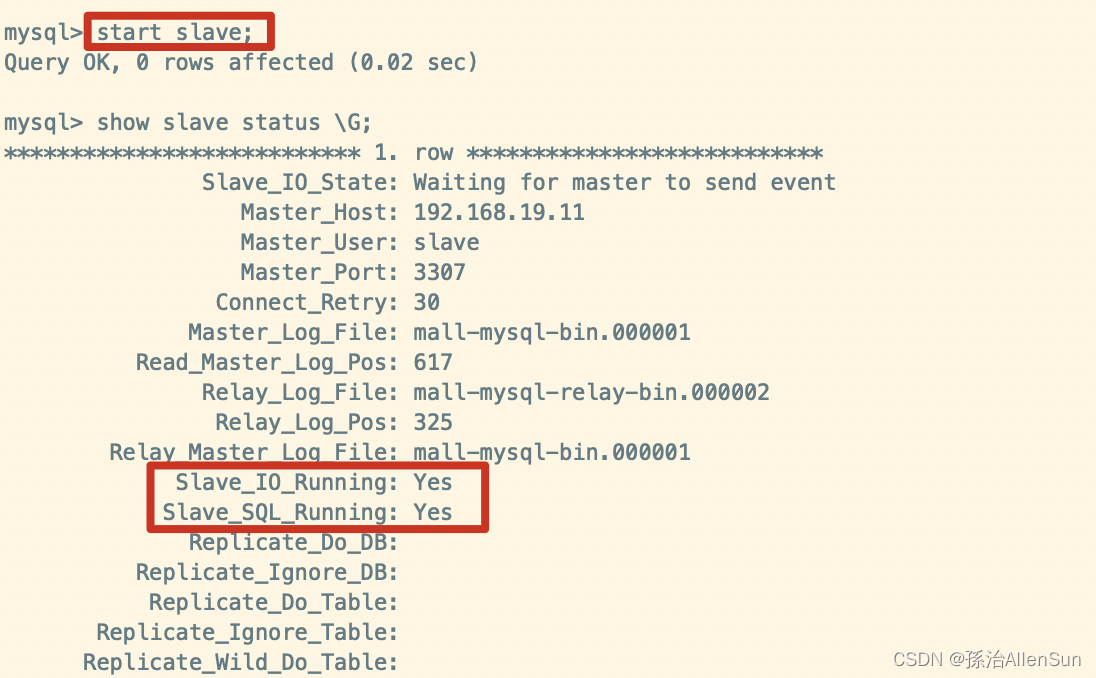
(14)查看从数据库状态发现已经同步
(15)主从复制测试
在主库执行以下sql
create database testslave;
use testslave;
CREATE TABLE hero ( id int(11) AUTO_INCREMENT, name varchar(30) , hp float , damage int(11) , PRIMARY KEY (id) ) DEFAULT CHARSET=utf8;
insert into hero values (null, '盖伦', 616, 100);
在从库进行查询,查询成功。
【2】安装redis集群
(1)面试题
1-2亿条数据需要缓存,请问如何设计这个存储案例?
单机单台100%不可能,肯定是分布式存储,用redis如何落地?既然是分布式,那么一个数据落在哪一台服务器上?能不能保证下次读的时候也是从那一台服务器上读出来?
2亿条记录就是2亿个k-v,我们单机不行,必须要分布式多机,假设有3台机器构成一个集群,用户每次读写操作都是根据公式:hash(key)%N个机器台数,计算出哈希值,用来决定数据映射到哪一个节点上。
(1)哈希取余分区

 (2)一致性哈希算法分区
(2)一致性哈希算法分区
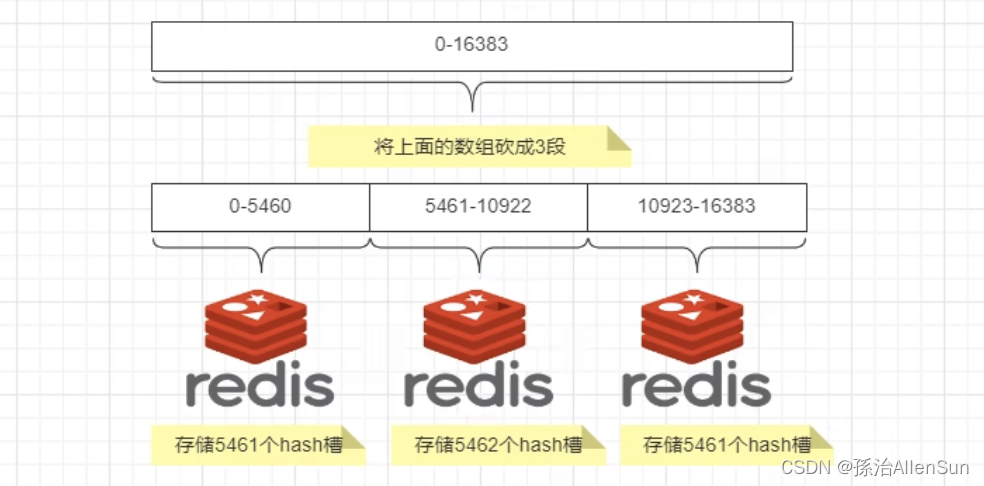
 (3)哈希槽分区
(3)哈希槽分区
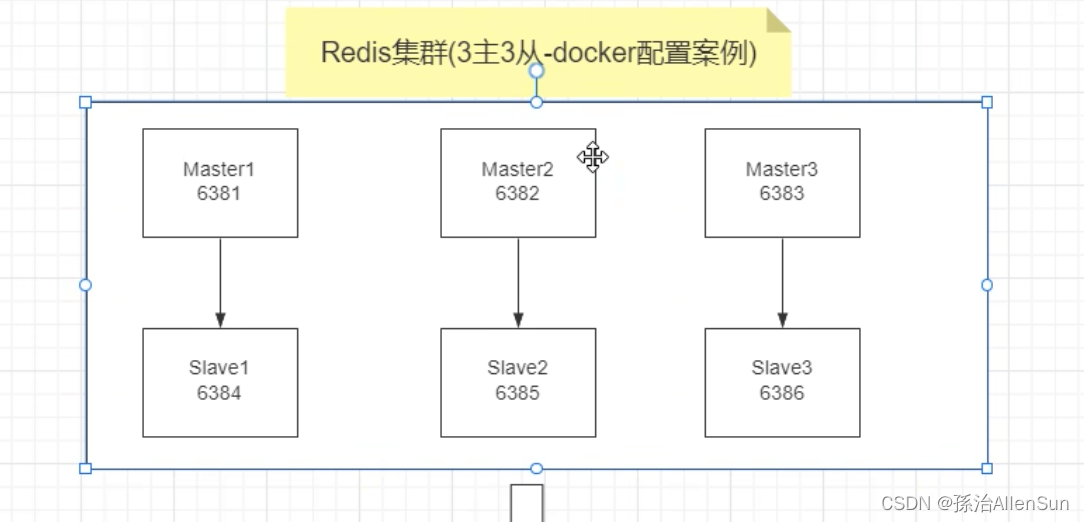
(2)搭建三主三从redis集群
(1)新建6个docker容器实例
docker run -d --name redis-node-1 --net host --privileged=true -v /data/redis/share/redis-node-1:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6381
docker run -d --name redis-node-2 --net host --privileged=true -v /data/redis/share/redis-node-2:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6382
docker run -d --name redis-node-3 --net host --privileged=true -v /data/redis/share/redis-node-3:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6383
docker run -d --name redis-node-4 --net host --privileged=true -v /data/redis/share/redis-node-4:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6384
docker run -d --name redis-node-5 --net host --privileged=true -v /data/redis/share/redis-node-5:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6385
docker run -d --name redis-node-6 --net host --privileged=true -v /data/redis/share/redis-node-6:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6386


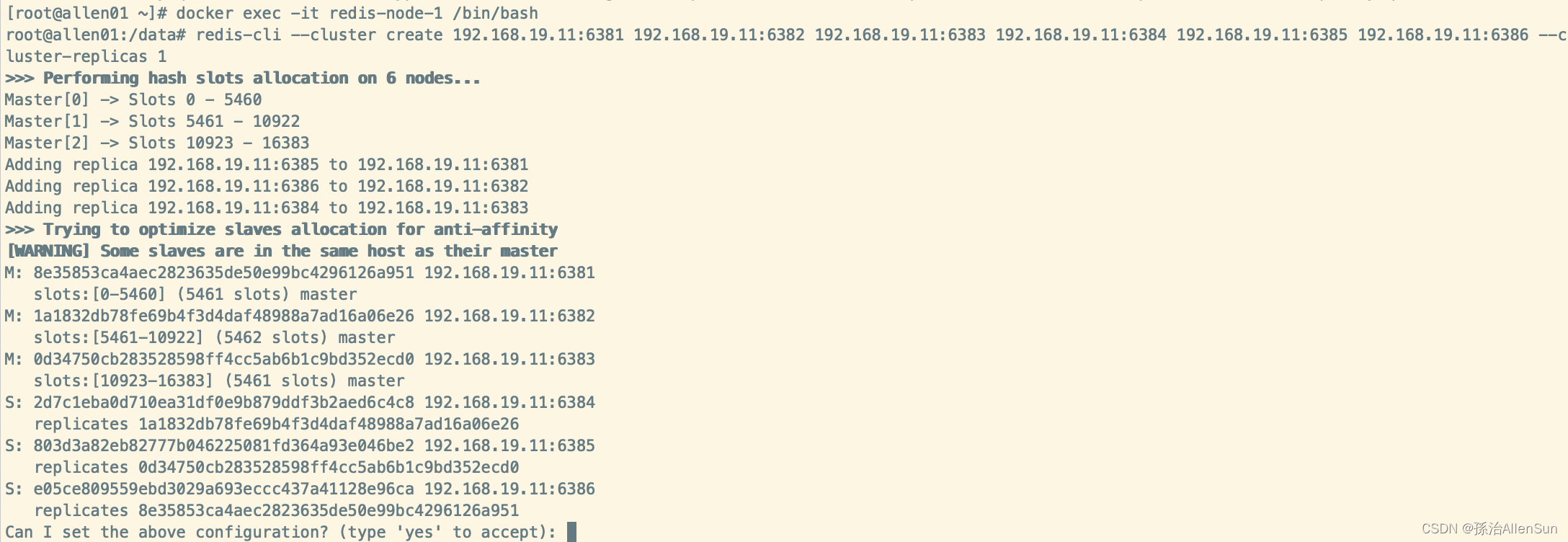
(2)进入容器redis-node-1并为6台机器构建集群关系
docker exec -it redis-node-1 /bin/bash
redis-cli --cluster create 192.168.19.11:6381 192.168.19.11:6382 192.168.19.11:6383 192.168.19.11:6384 192.168.19.11:6385 192.168.19.11:6386 --cluster-replicas 1
–cluster-replicas 1 表示为每个master创建一个slave节点
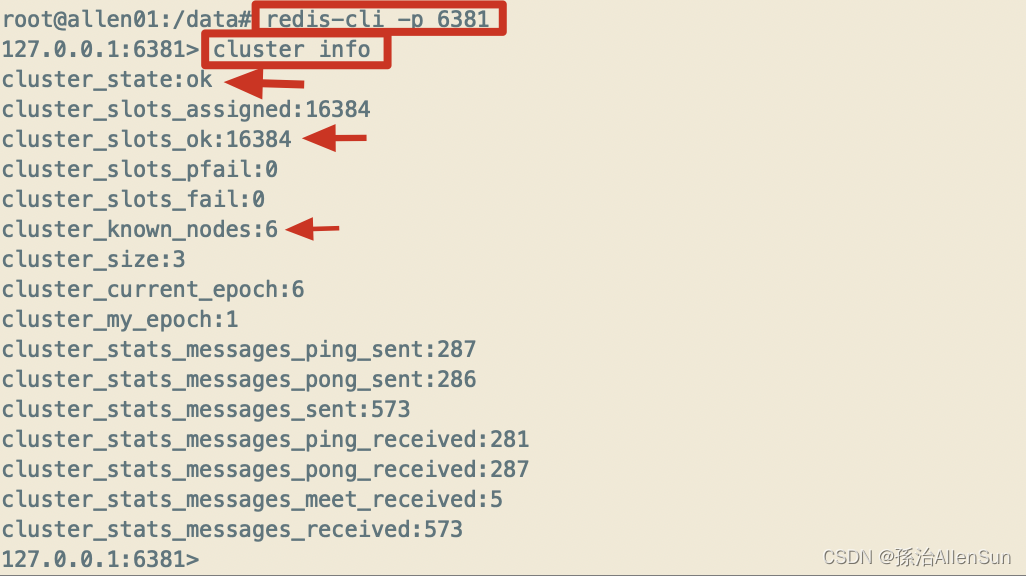
(3)链接进入6381作为切入点,查看节点状态
redis-cli -p 6381
cluster info

(3)主从容错切换迁移案例
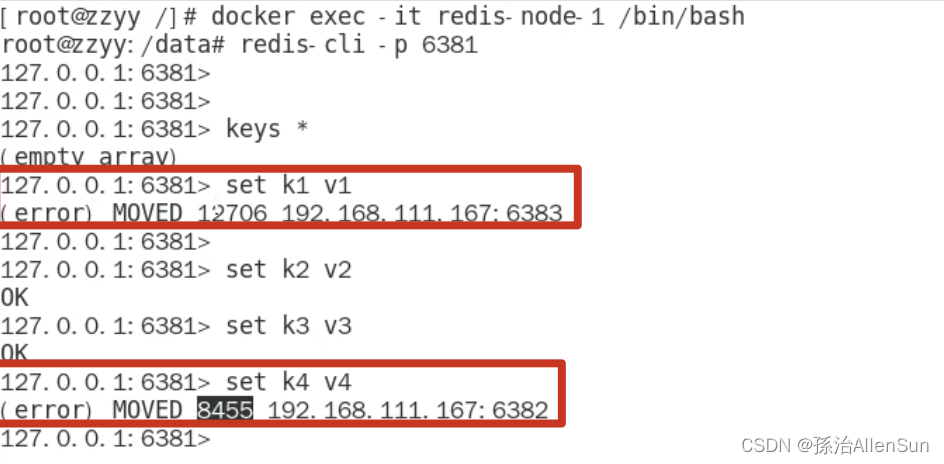
(1)数据读写存储
首先进入6381,尝试存储数据,发现有的数据槽位超过了6381分配的槽位,那么就会报错
docker exec -it redis-node-1 /bin/bash
单机模式连接
redis-cli -p 6381
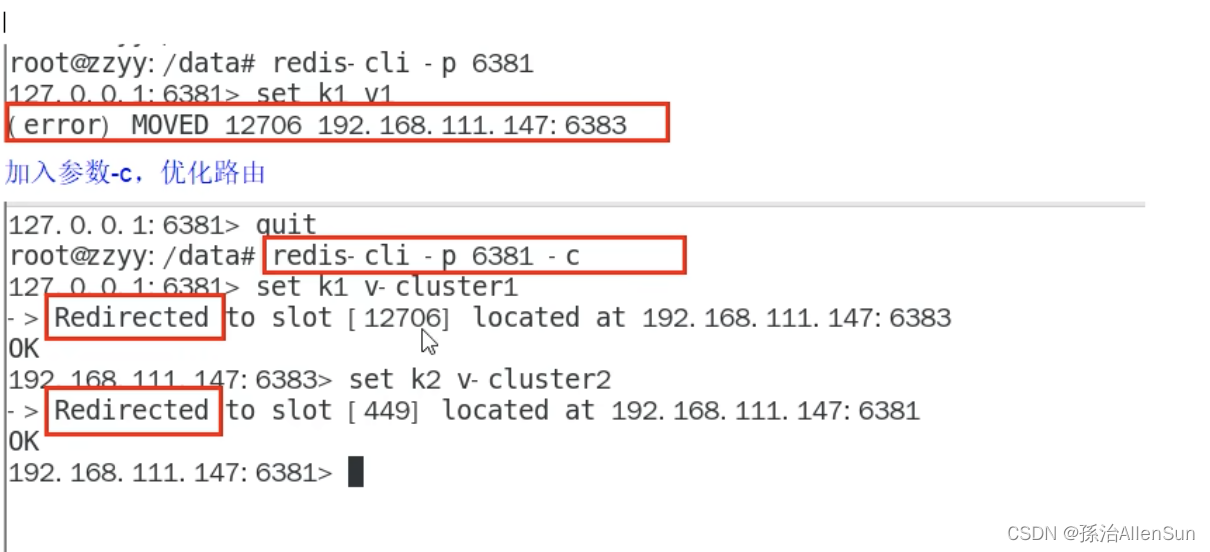
 改成用集群方式连接,优化路由
改成用集群方式连接,优化路由
redis-cli -p 6381 -c
 (2)容错切换迁移(测试主从切换)
(2)容错切换迁移(测试主从切换)
首先在6381主机中查看集群信息
 停掉6381主机
停掉6381主机
 重新进入6382
重新进入6382
docker exec -it redis-node-2 /bin/bash
redis-cli -p 6382 -c
查看集群信息,可以看到原来的6386从机已经变成了主机
 把6381启动以后,6381变成了新的从机,要想把6381重新变为主机,可以把现在6386停掉再重启
把6381启动以后,6381变成了新的从机,要想把6381重新变为主机,可以把现在6386停掉再重启
(4)主从扩容案例
(1)新建6387、6388两个节点,新建后启动,查看是否是8个节点
docker run -d --name redis-node-7 --net host --privileged=true -v /data/redis/share/redis-node-7:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6387
docker run -d --name redis-node-8 --net host --privileged=true -v /data/redis/share/redis-node-8:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6388
docker ps
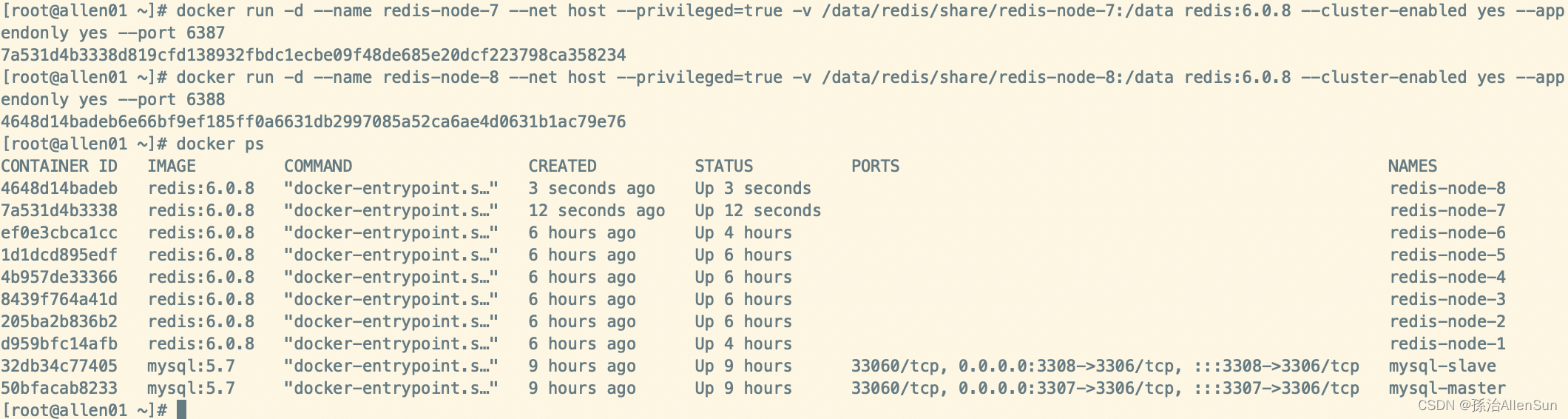
(2)进入6387容器实例内部
docker exec -it redis-node-7 /bin/bash
(3)把新增的6387节点(空槽位)作为master节点加入原集群
把新增的6387作为master节点加入集群,6381就是原来集群节点里面的领路人,相当于6387拜拜6381的码头从而找到组织加入集群
redis-cli --cluster add-node 192.168.19.11:6387 192.168.19.11:6381
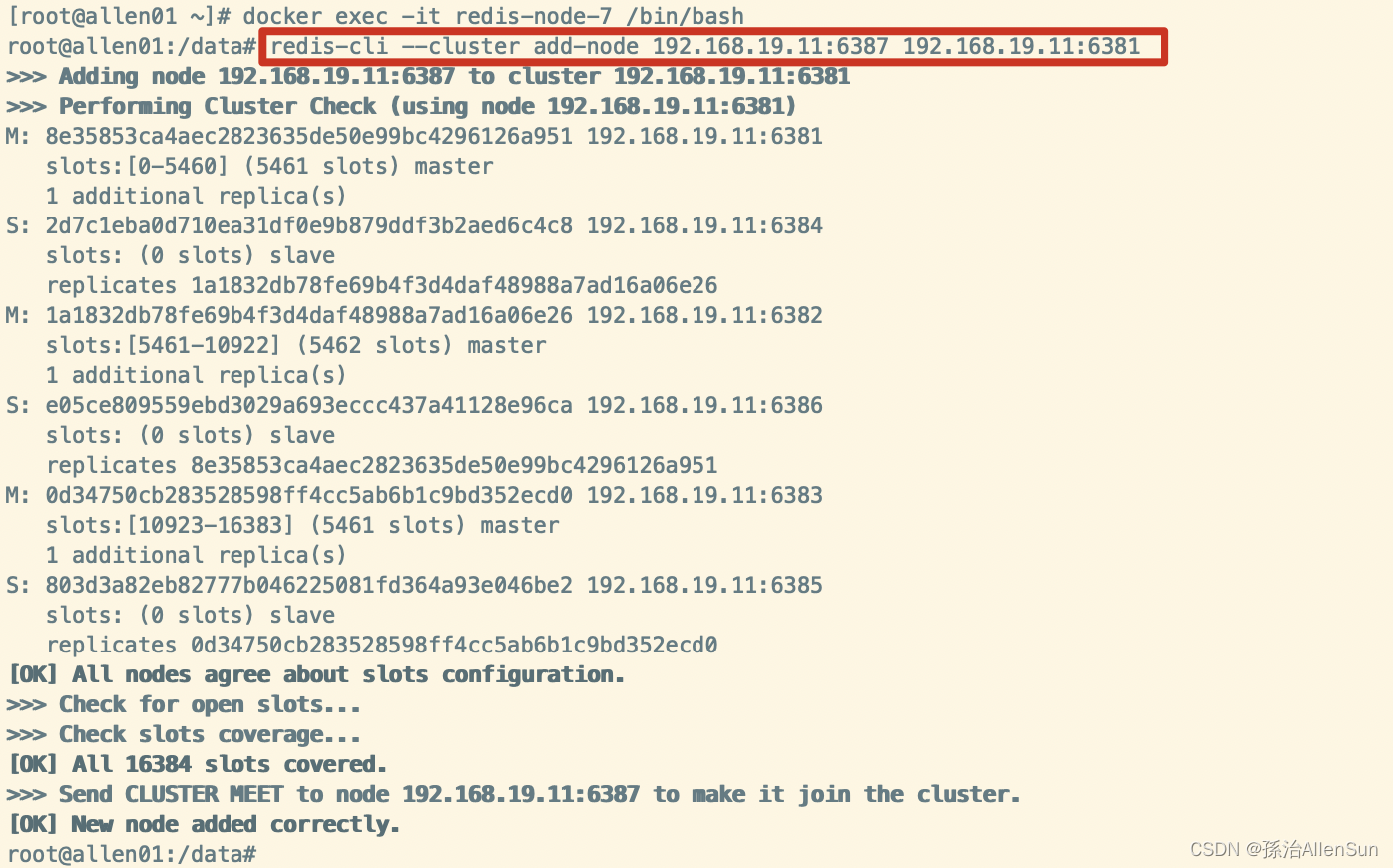 (4)第1次检查集群情况
(4)第1次检查集群情况
redis-cli --cluster check 192.168.19.11:6381
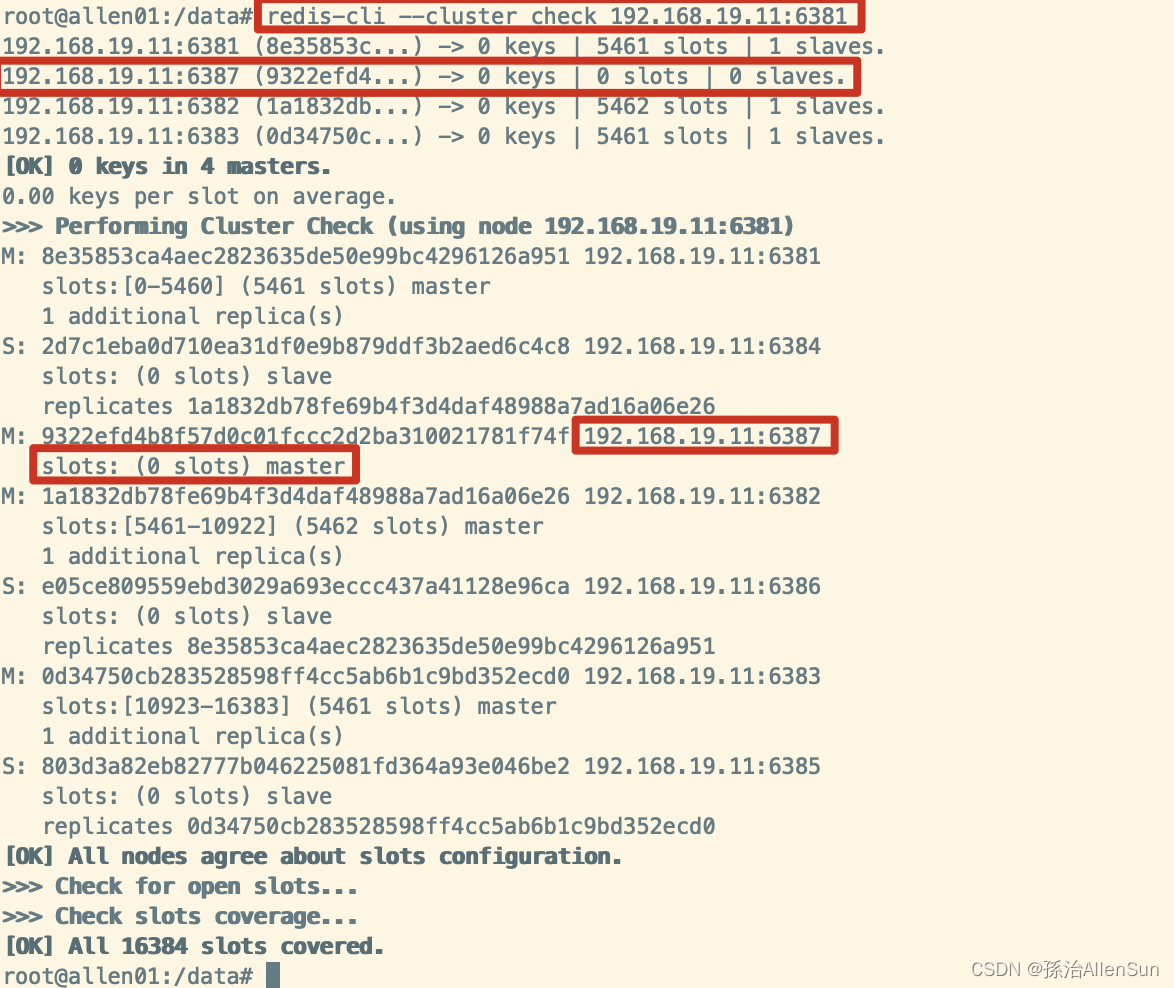
(5)重新分派槽号给6387
redis-cli --cluster reshard 192.168.19.11:6387
给新分配4096个槽位
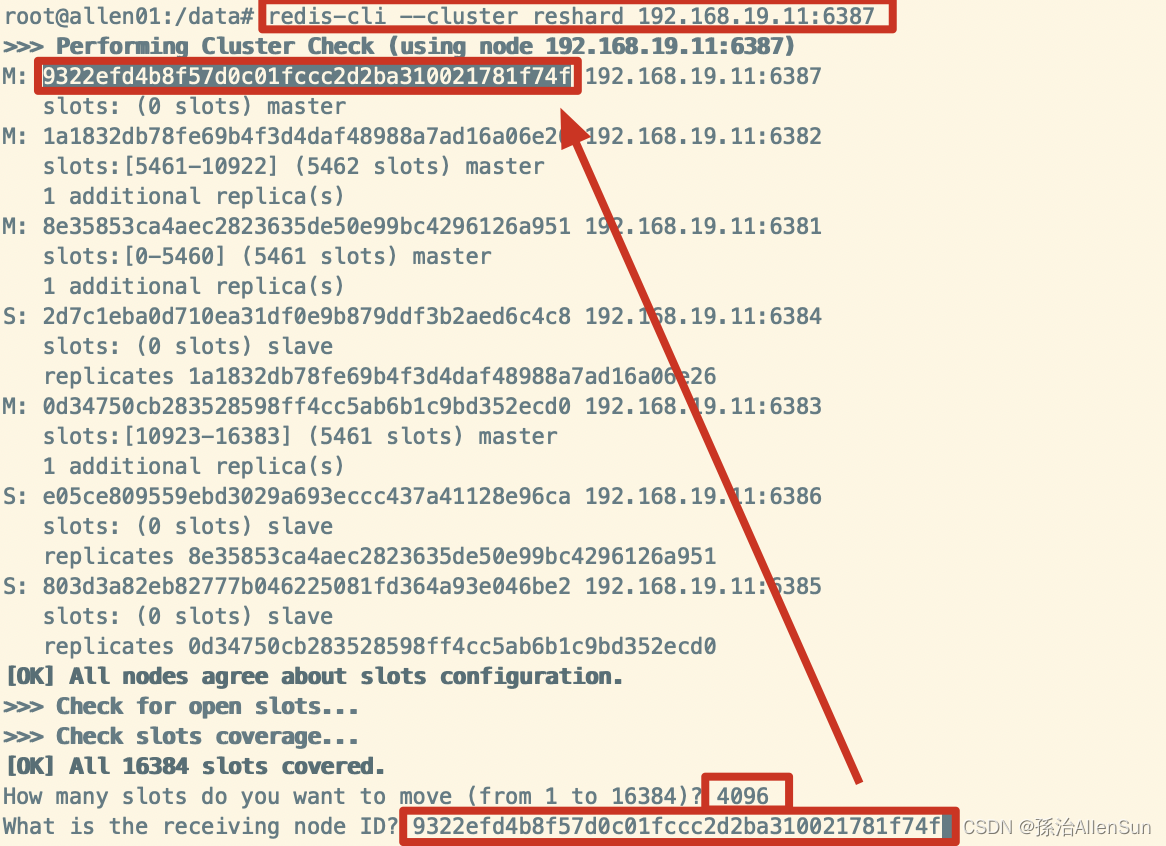 然后输入all,从每一个槽位上取一些过来
然后输入all,从每一个槽位上取一些过来
(6)第2次检查集群情况
redis-cli --cluster check 192.168.19.11:6381
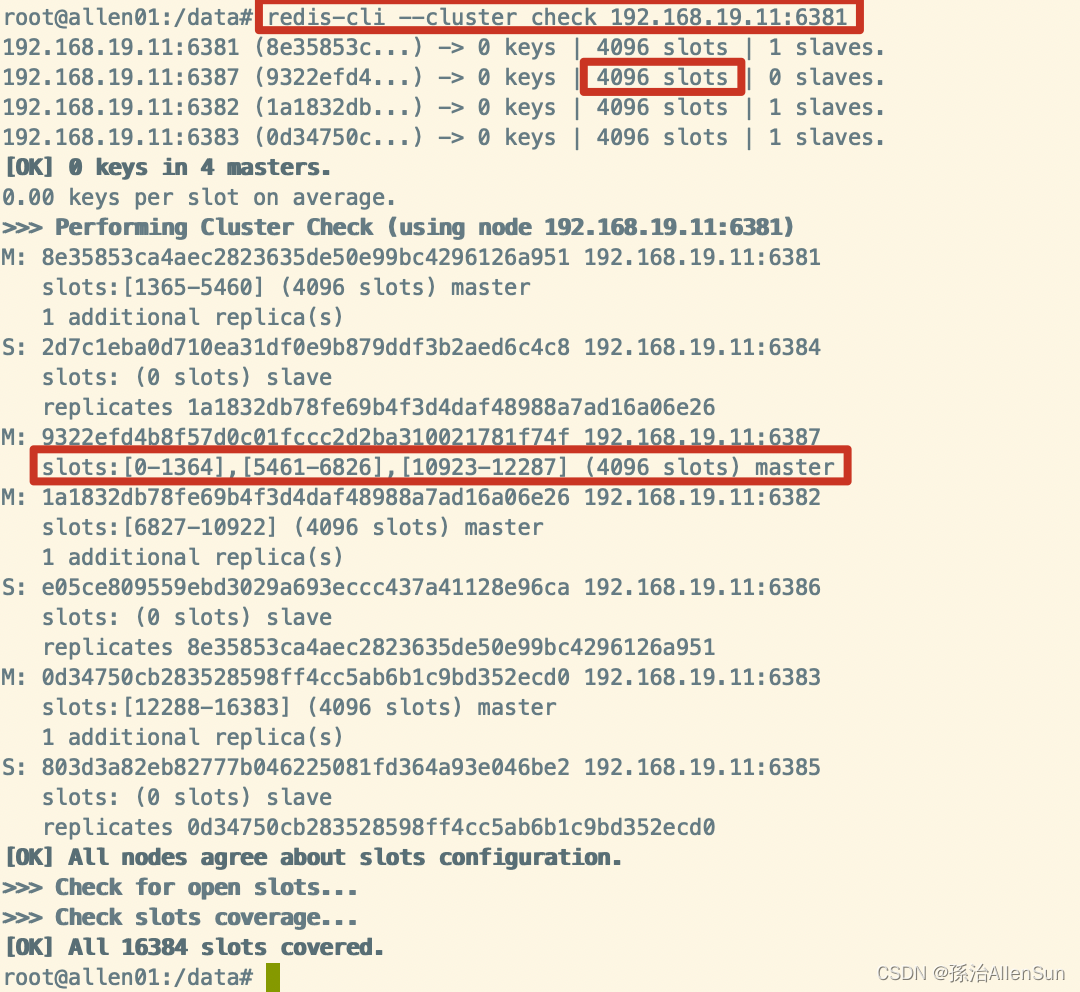
(7)为主节点6387分配从节点6388
最后的编号是6387的编号
redis-cli --cluster add-node 192.168.19.11:6388 192.168.19.11:6387 --cluster-slave --cluster-master-id 9322efd4b8f57d0c01fccc2d2ba310021781f74f
(8)第3次检查集群情况
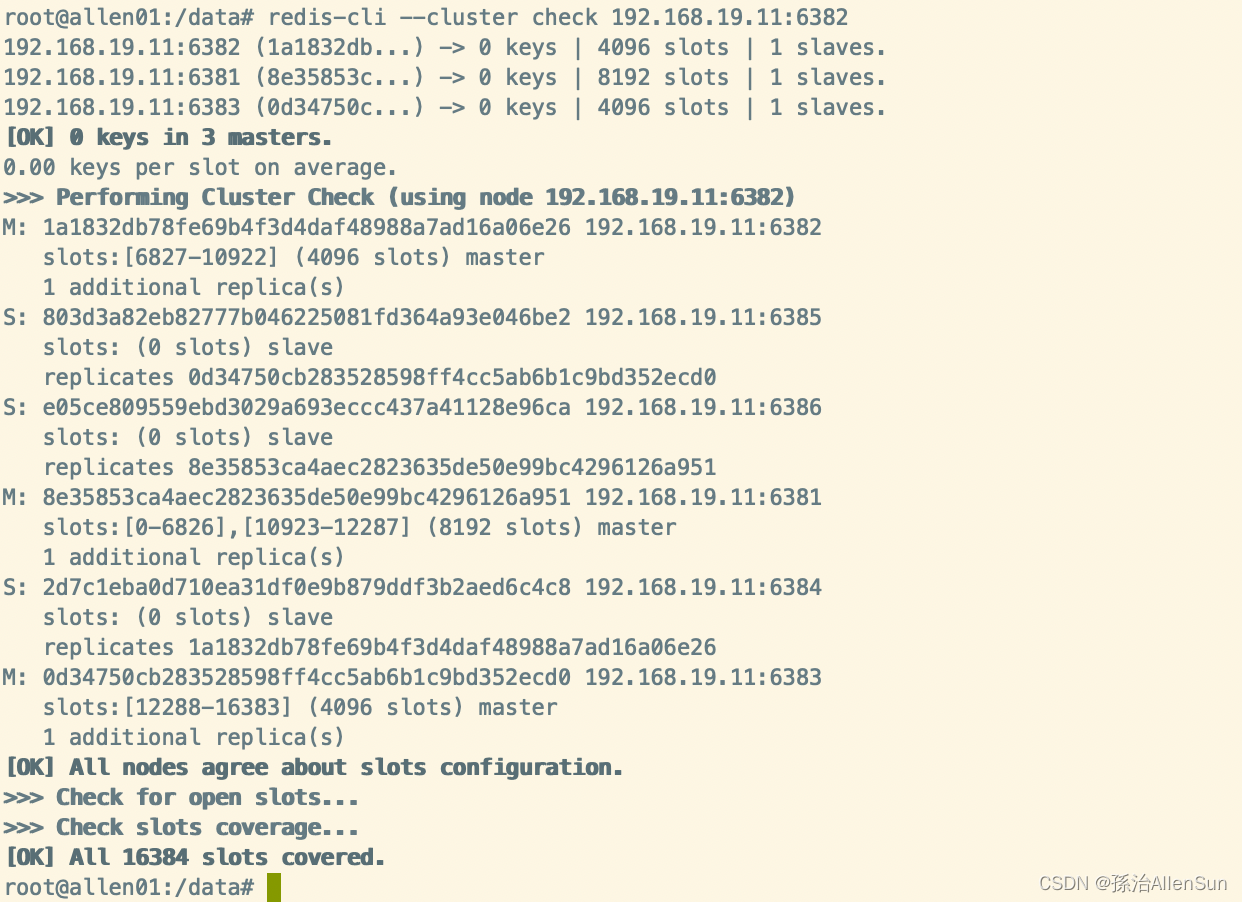
redis-cli --cluster check 192.168.19.11:6381
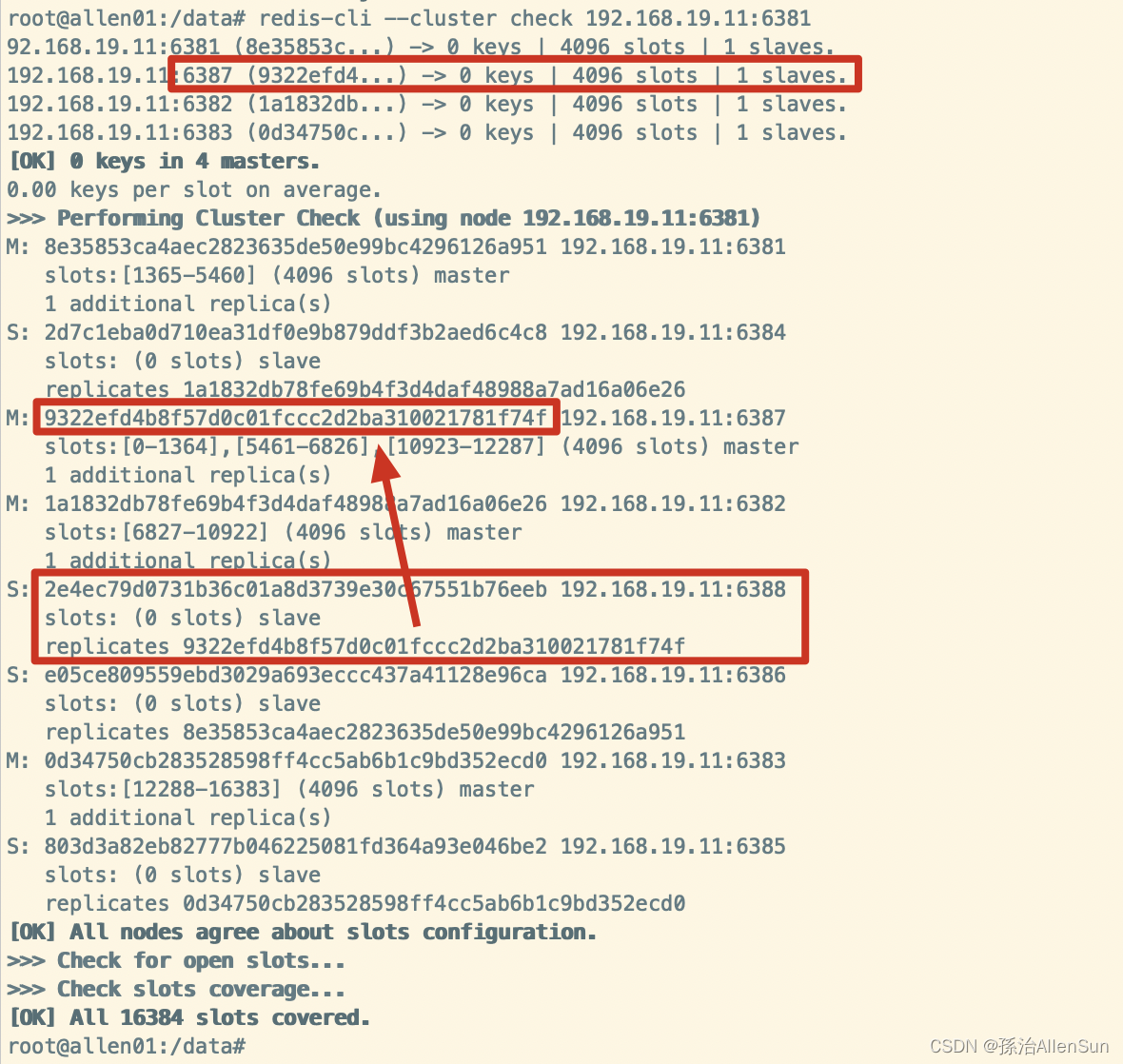
(5)主从缩容案例
(1)检查集群情况1获取6388的节点ID
redis-cli --cluster check 192.168.19.11:6382
(2)把6388删除,从集群中把4号从节点6388删除
最后跟的节点ID就是6388的节点ID
redis-cli --cluster del-node 192.168.19.11:6388 2e4ec79d0731b36c01a8d3739e30c67551b76eeb
(3)把6387的槽号清空,重新分配,本例把清出来的槽号都给6381
redis-cli --cluster reshard 192.168.19.11:6381
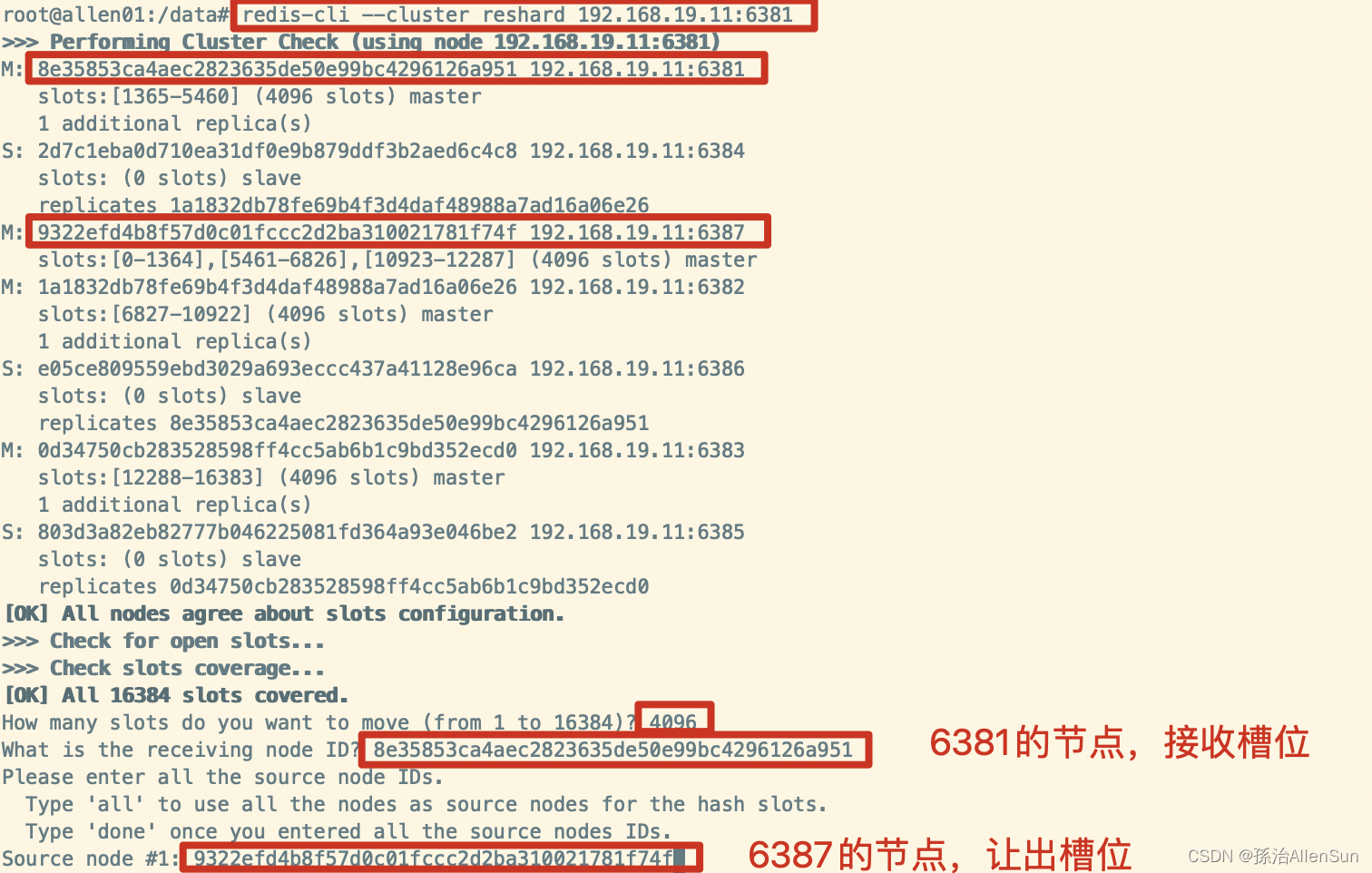
然后输出done表示结束

(4)第2次检查集群情况
redis-cli --cluster check 192.168.19.11:6382
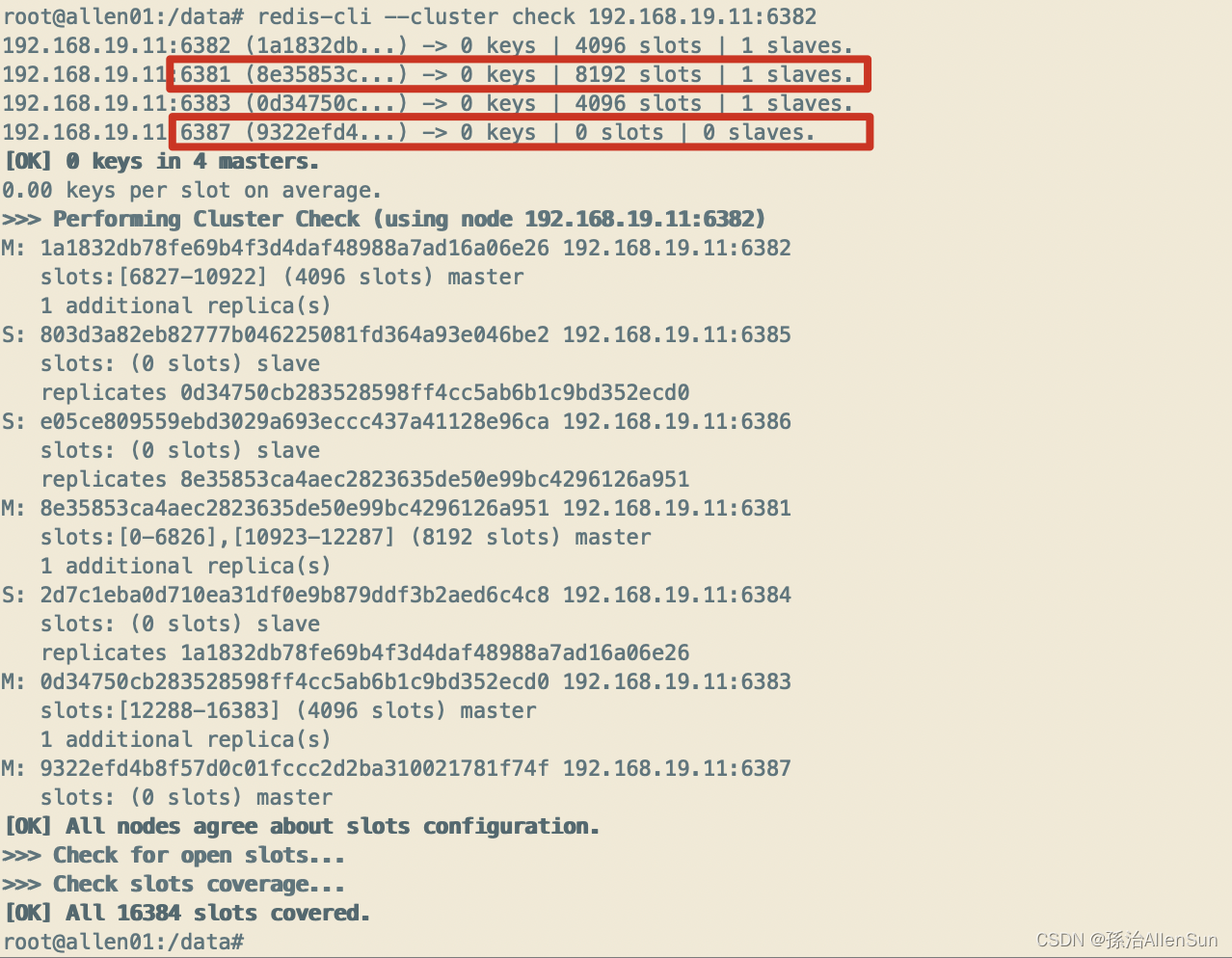 (5)把6387删除
(5)把6387删除
最后跟的节点ID就是6387的节点ID
redis-cli --cluster del-node 192.168.19.11:6387 9322efd4b8f57d0c01fccc2d2ba310021781f74f
(6)第3次检查集群情况
redis-cli --cluster check 192.168.19.11:6382
可以看到没有6387的节点了
(二)DockerFile解析
(1)dockerfile是什么
dockerfile是用来构建docker镜像的文本文件,是由一条条构建镜像所需的指令和参数构成的脚本
(2)dockerfile内容基本知识
(1)每条保留字指令都必须为大写字母且后面要跟随至少一个参数
(2)指令按照从上到下,顺序执行
(3)#表示注释
(4)每条指令都会创建一个新的镜像层并对镜像进行提交
(3)docker执行dockerfile的大致流程
(1)docker从基础镜像运行一个容器
(2)执行一条指令并对容器作出修改
(3)执行类似docker commit的操作提交一个新的镜像层
(4)docker再基于刚提交的镜像进行一个新容器
(5)执行dockerfile中的下一条指令直到所有指令都执行完成
(4)dockerfile、docker镜像和docker容器的关系
dockerfile、docker镜像和docker容器分别代表软件的三个不同阶段
(1)dockerfile是软件的原材料,定义了进程需要的一切东西,dockerfile涉及的内容包括执行代码或者是文件、环境变量、依赖包、运行时环境、动态链接库、操作系统的发行版、服务进程和内核进程(当应用进程需要和系统服务和内核进程打交道,这时需要考虑如何设计namespace的权限控制)等等。
(2)docker镜像是软件的交付品,在dockerfile定义一个文件之后,docker build时会产生一个docker镜像,当运行docker镜像时会真正开始提供服务
(3)docker容器则可以认为是软件镜像的运行态,也就是依照镜像运行的容器实例
dockerfile面向开发,docker镜像成为交付标准,docker容器则设计部署和运维,三者缺一不可,合力充当docker体系的基石
(5)dockerfile的常用保留字
(1)FROM:指定基础镜像,当前新镜像是基于哪个镜像的,指定一个已经存在的镜像作为模板,第一条必须是form
(2)MAINTAINER:镜像维护者的姓名和邮箱地址
(3)RUN:容器构建时需要运行的命令,两种格式,分别是shell格式和exec格式,RUN是在docker build的时候运行的
(4)EXPOSE:当前容器对外暴露的端口
(5)WORKDIR:指定在创建容器后,终端默认登陆的进来工作目录,一个落脚点
(6)USER:指定该镜像以什么样的用户去执行,如果都不指定,默认是root
(7)ENV:用来在构建镜像过程中设置环境变量

(8)ADD:把宿主机目录下的文件拷贝到镜像,并且会自动处理URL和解压tar压缩包
(9)COPY:类似于ADD,拷贝文件和目录到镜像中
(10)VOLUME:容器数据卷,用于数据保存和持久化工作
(11)CMD:
(12)ENTRYPOINT:
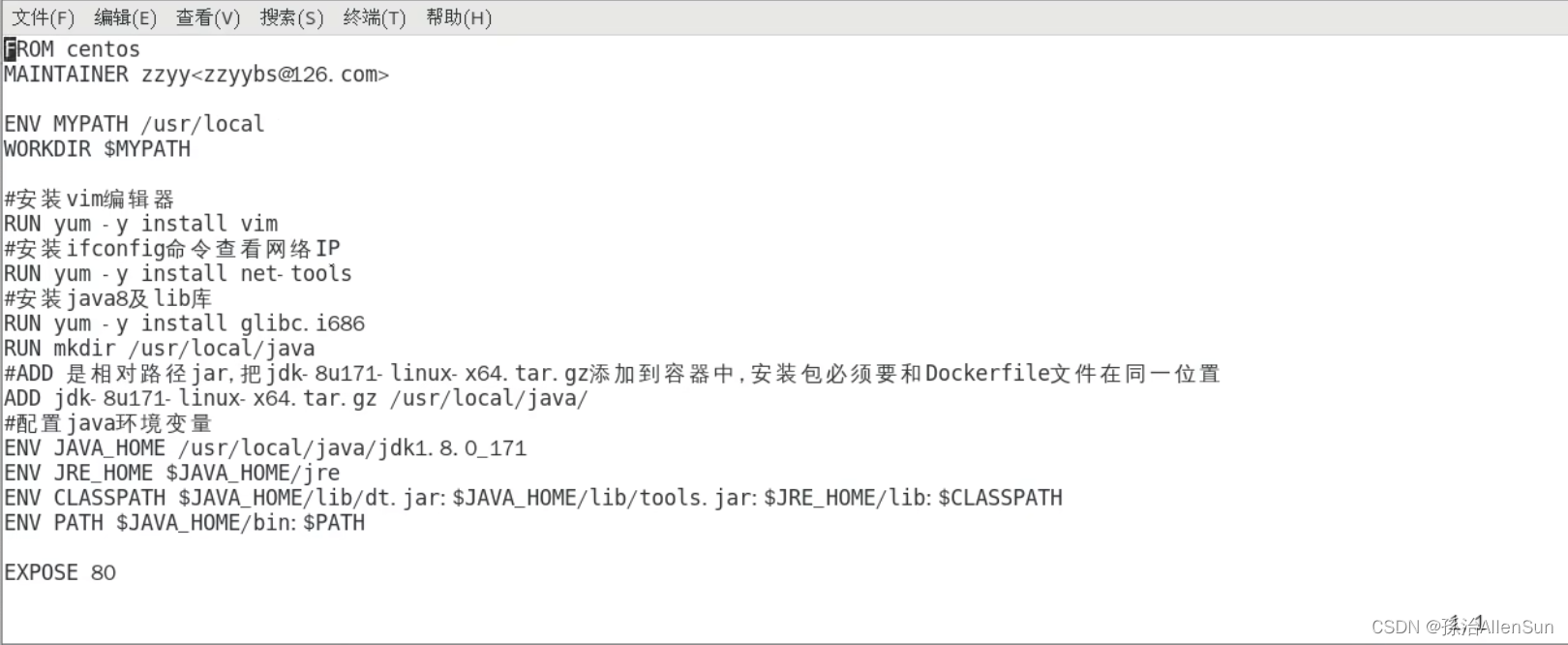
(6)centos之dockerfile演示案例
原始的centos7并不具备vim+ifconfig+jdk8等工具,想用dockerfile往centos7里默认加入这些工具
(三)Docker微服务实战
(四)Docker网络
(1)是什么
(2)常用基本命令
(3)能干嘛
(4)网络模式
(5)Docker平台架构图解
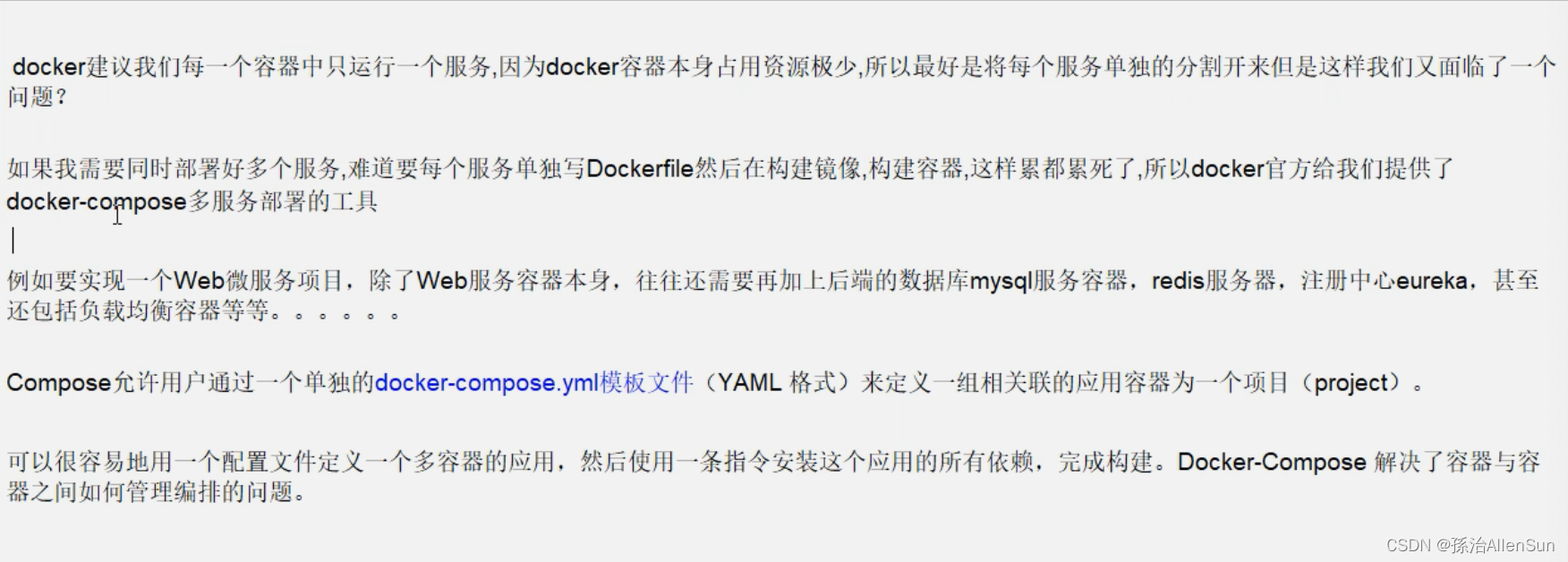
(五)Docker-compose容器编排
















 1136
1136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









