






【ElasticSearch】数据分析引擎学习笔记
【一】ElasticSearch是什么?
ElasticSearch是一个分布式、Restful风格的搜索和数据分析引擎,Stark的核心。可以应用在比如全文搜索、购物推荐、附近等位推荐等等。
elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,可以帮助我们从海量数据中快速找到需要的内容
(1)在GitHub搜索代码
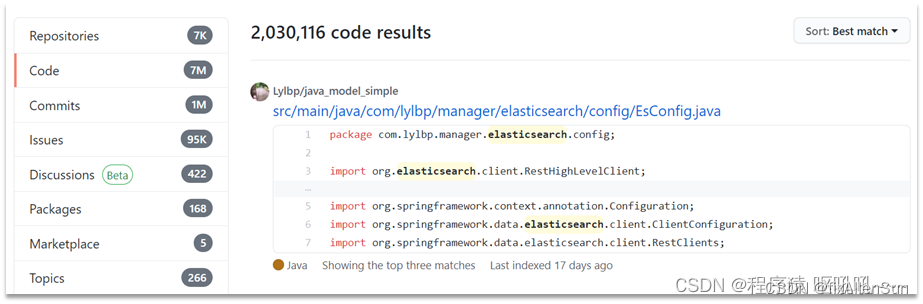
(2)在电商网站搜索商品
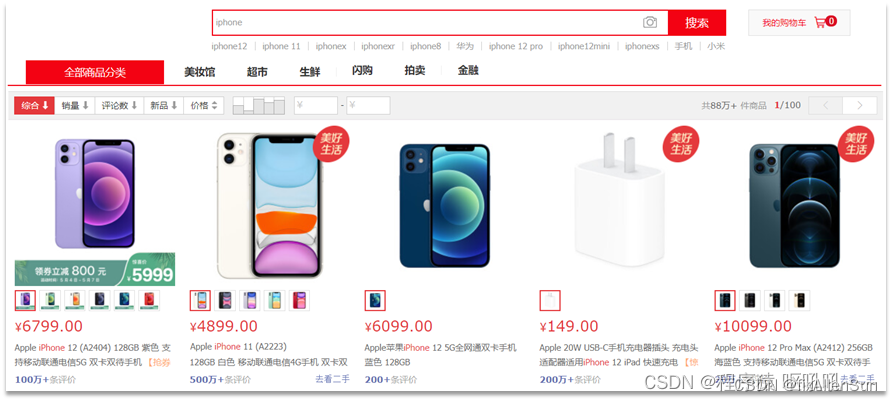
(3)在谷歌搜索答案
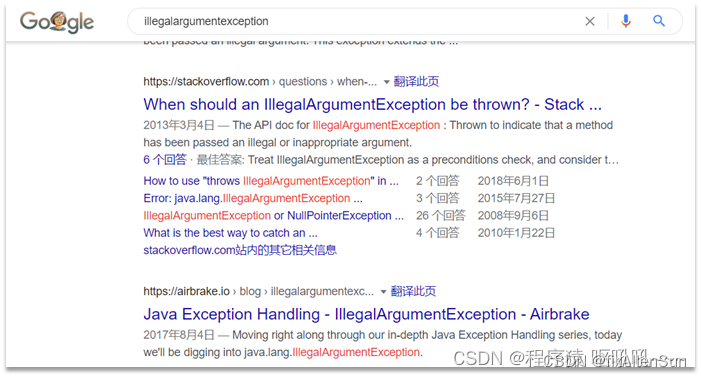
【二】Mac安装ElasticSearch
(1)Elasticsearch 依赖于JDK, 并且JDK 版本1.8+
(2)下载Elasticsearch安装包
去官网下载:官网
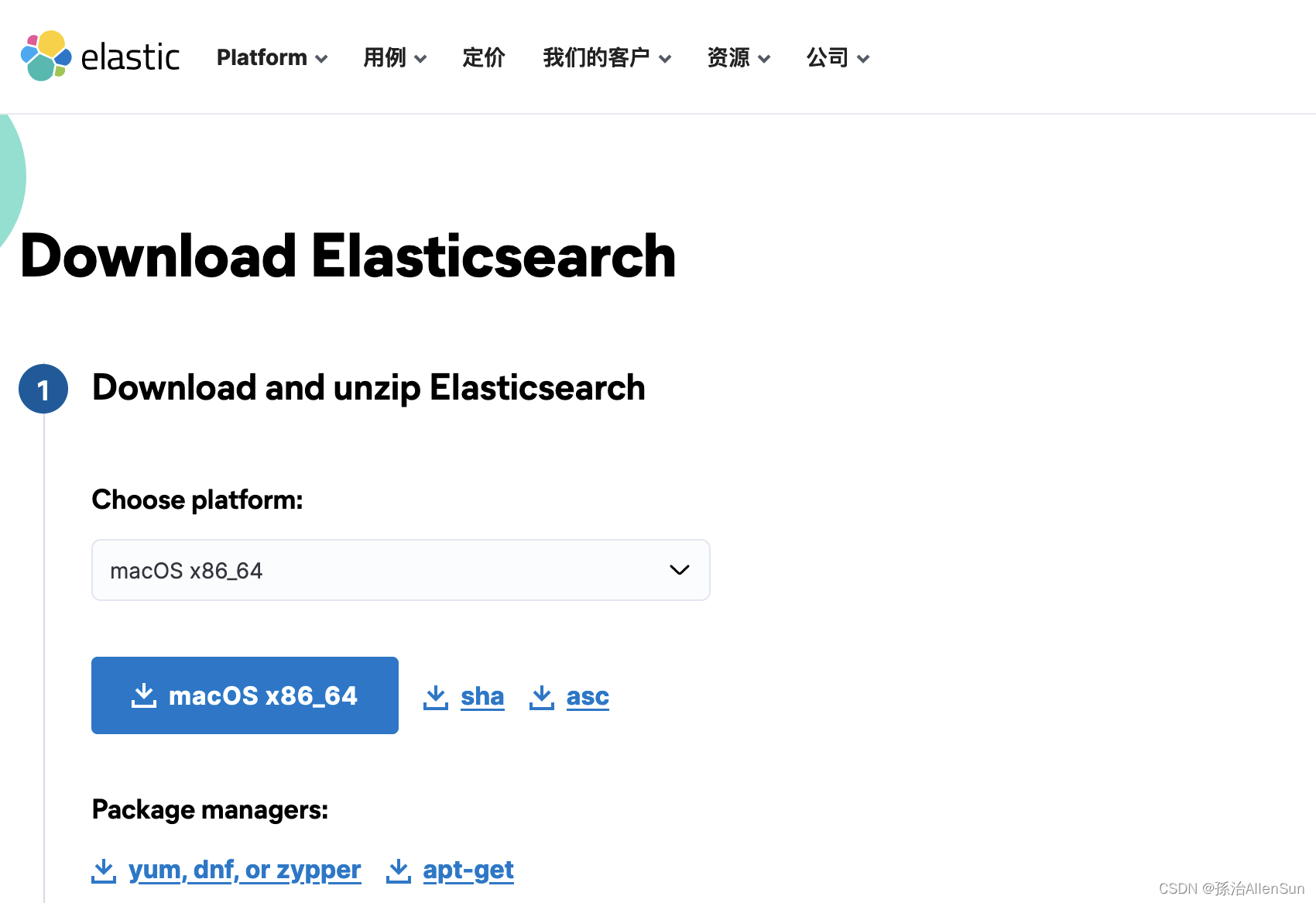
(3)解压安装
(4)启动
cd /Library/Java/AllenElasticSearch/elasticsearch-8.8.1/bin
./elasticsearch
./elasticsearch -d (这是后台启动)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
✅ Elasticsearch security features have been automatically configured!
✅ Authentication is enabled and cluster connections are encrypted.
ℹ️ Password for the elastic user (reset with bin/elasticsearch-reset-password -u elastic):
qnWihd7R3smEQF*T+YqD
ℹ️ HTTP CA certificate SHA-256 fingerprint:
72c84da88bd1eb6e0324c3377803155224a1c6aa3399c8f782aaea4178820940
ℹ️ Configure Kibana to use this cluster:
• Run Kibana and click the configuration link in the terminal when Kibana starts.
• Copy the following enrollment token and paste it into Kibana in your browser (valid for the next 30 minutes):
eyJ2ZXIiOiI4LjguMSIsImFkciI6WyIxOTIuMTY4LjEwLjEwMjo5MjAwIl0sImZnciI6IjcyYzg0ZGE4OGJkMWViNmUwMzI0YzMzNzc4MDMxNTUyMjRhMWM2YWEzMzk5YzhmNzgyYWFlYTQxNzg4MjA5NDAiLCJrZXkiOiI5Z2Y2cW9nQktRMi1LRW9kM1dlRTp5ZTh3UkNUalRzRzdvSFJqYUl5Rnp3In0=
ℹ️ Configure other nodes to join this cluster:
• On this node:
⁃ Create an enrollment token with bin/elasticsearch-create-enrollment-token -s node.
⁃ Uncomment the transport.host setting at the end of config/elasticsearch.yml.
⁃ Restart Elasticsearch.
• On other nodes:
⁃ Start Elasticsearch with bin/elasticsearch --enrollment-token <token>, using the enrollment token that you generated.
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
(5)检验是否启动成功
http://127.0.0.1:9200/
(6)网址访问报错
received plaintext http traffic on an https channel, closing connection Netty4HttpChannel
ES8默认开启了ssl认证,导致无法访问9200端口
找到config/目录下面的elasticsearch.yml配置文件,把安全认证开关从原先的true都改成false,实现免密登录访问即可,修改这两处都为false后:

重新启动,重新访问
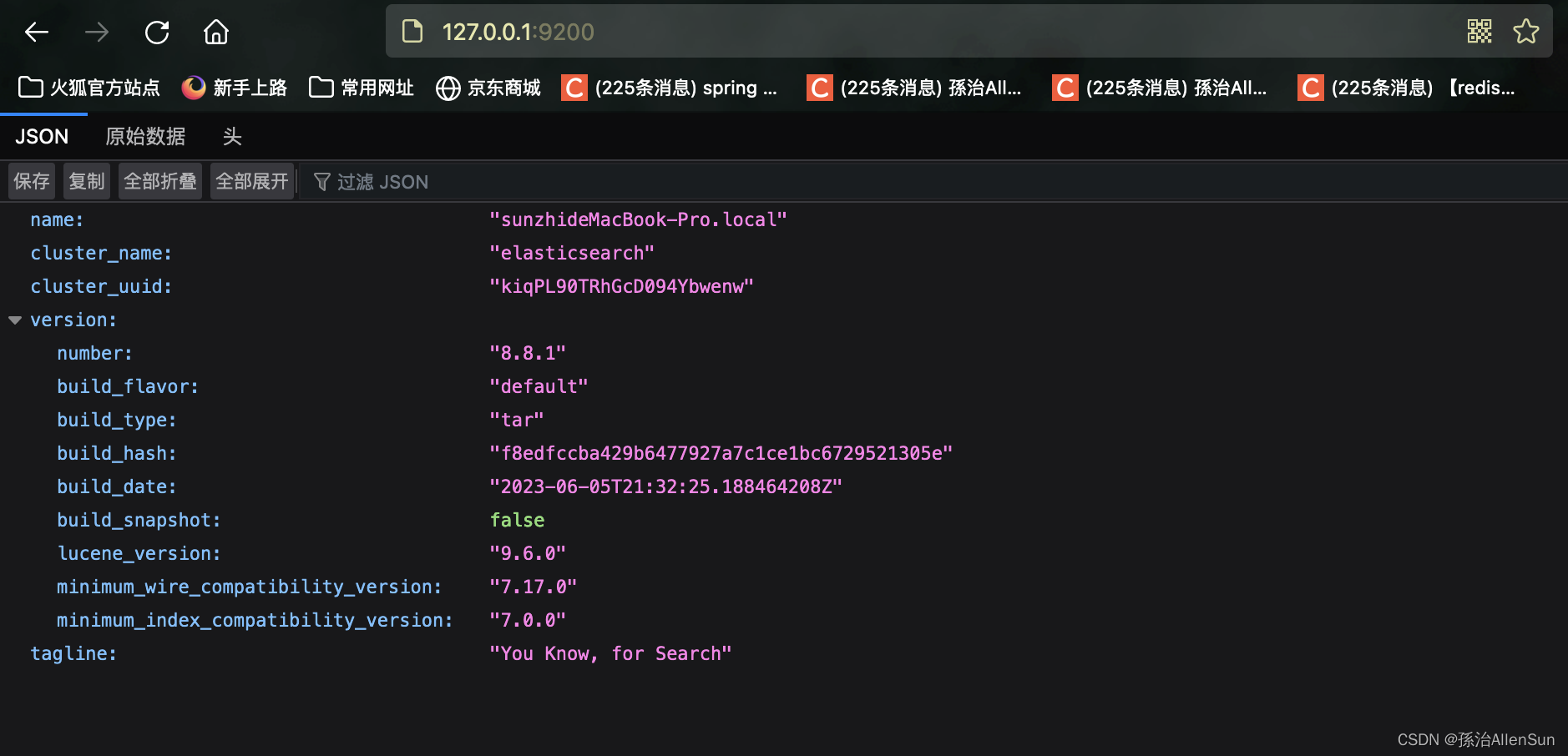
(6)熟悉Elasticsearch的文件
1)bin 目录下是一些脚本文件,包括 Elasticsearch 的启动执行文件。
2)config 目录下是一些配置文件。
3)jdk 目录下是内置的 Java 运行环境。
4)lib 目录下是一些 Java 类库文件。
5)logs 目录下会生成一些日志文件。
6)modules 目录下是一些 Elasticsearch 的模块。
7)plugins 目录下可以放一些 Elasticsearch 的插件。
直接双击 bin 目录下的 elasticsearch.bat 文件就可以启动 Elasticsearch 服务了。
启动后输出了很多信息,只需要看启动日志中是否有started字眼,就表示启动成功了。
确认是否真正启动成功,可以在浏览器的地址栏里输入 http://localhost:9200 进行查看(9200 是 Elasticsearch 的默认端口号)。
【三】Mac安装可视化界面Kibana
(1)简介
Kibana是一个针对ElasticSearch的开源分析及可视化平台,用来搜索、查看交互存储在ElasticSearch索引中的数据。使用Kibana,可以通过各种图表进行高级数据分析及展示。Kibana让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板(dashboard)实时显示ElasticSearch查询动态。设置设置Kibana非常简单。无需编码或者额外的基础架构,几分钟内就可以完成Kibana安装并启动ElasticSearch索引监测。
(2)下载
首先要知道自己ES的版本,去官网下载与ES版本一致的Kibana。
官网:https://www.elastic.co/cn/kibana
首先要知道自己ES的版本,去官网下载与ES版本一致的Kibana。
(3)启动
解压之后,修改配置文件kibana.yml
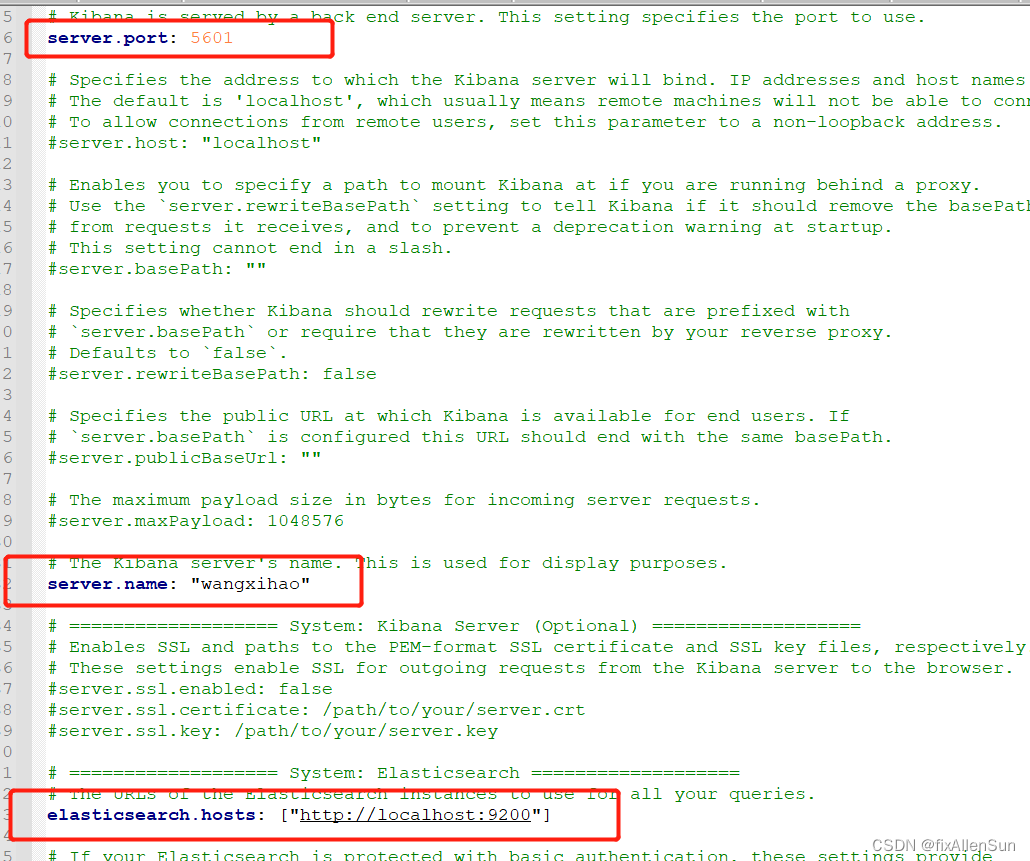
默认是注释掉的,将注释去掉,名字自己起。
cd /Library/Java/AllenKibana/kibana-8.8.1/bin
./kibana
./kibana -d (这是后台启动)
直接点击bin目录下的kibana.bat即可启动
当看到 [Kibana][http] http server running 的信息后,说明服务启动成功了。
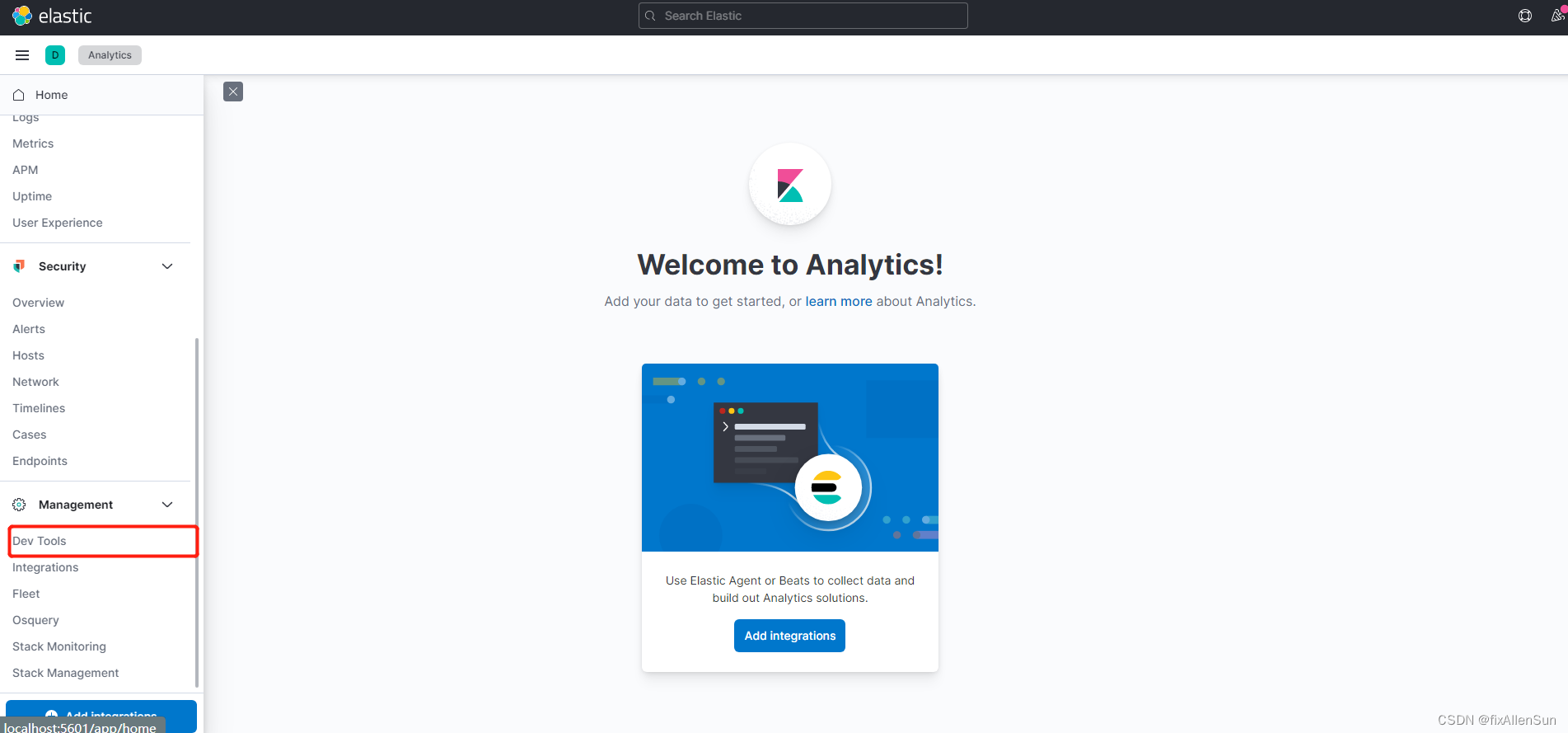
(4)验证启动是否成功
在浏览器地址栏输入 http://localhost:5601 查看 Kibana 的图形化界面。
成功,点击Dev tools 就可以使用ElasticSecrch。
【四】Linux安装elasticSearch、Kibana、IK分词器
【1】准备jdk环境
(1)注意ES和JDK的对应版本要求
查看连接:注意ES和JDK的对应版本要求
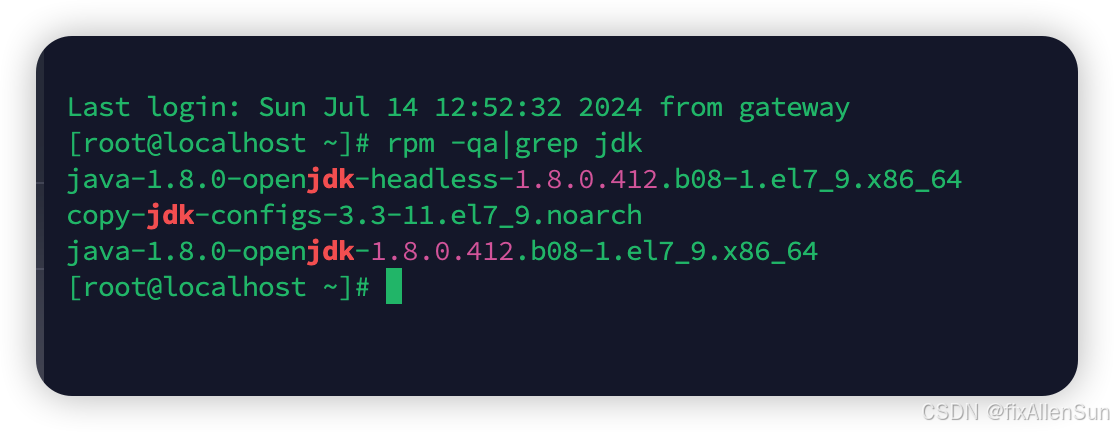
(2)先查看本地的JDK版本
rpm -qa|grep jdk
可以看到本地的JDK版本是1.8的
(3)删除旧的JDK
yum -y remove java-1.8.0-openjdk-headless-1.8.0.412.b08-1.el7_9.x86_64
(4)安装JDK11
yum search java-11-openjdk
yum install java-11-openjdk-headless.x86_64
(5)检查是否安装成功
java -version
(6)修改JDK环境变量
vim /etc/profile
JAVA_HOME=/usr/lib/jvm/java-11-openjdk-11.0.23.0.9-2.el7_9.x86_64 # 注意版本
JRE_HOME=$JAVA_HOME/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
修改文件后运行# source /etc/profile ,使新的配置内容生效
【2】安装ES
(1)安装ES
切换到 root 用户
su root
进入到 /opt 下 创建 /es 文件夹
cd /opt
mkdir es
进入到es文件夹内下载 elasticsearch-7.7.0
(2)下载ES
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.7.0-linux-x86_64.tar.gz
(3)解压elasticsearch安装包
tar -xf elasticsearch-7.7.0-linux-x86_64.tar.gz
(4)修改配置文件 elasticsearch.yml
[root@localhost es]# vim elasticsearch-7.7.0/config/elasticsearch.yml
# ======================== Elasticsearch Configuration =========================
#
# NOTE: Elasticsearch comes with reasonable defaults for most settings.
# Before you set out to tweak and tune the configuration, make sure you
# understand what are you trying to accomplish and the consequences.
#
# The primary way of configuring a node is via this file. This template lists
# the most important settings you may want to configure for a production cluster.
#
# Please consult the documentation for further information on configuration options:
# https://www.elastic.co/guide/en/elasticsearch/reference/index.html
#
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
# 如有需求可自定义
cluster.name: my-application
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
# 如有需求可自定义
node.name: node-1
#
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
#path.data: /path/to/data
#
# Path to log files:
#
#path.logs: /path/to/logs
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
#bootstrap.memory_lock: true
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
# 可以定义为0.0.0.0,表示允许所有ip访问。但是这样不太安全,可以定义为当前虚拟机的ip
# 如果是桥接模式的话,ip可能会变,虚拟机建议使用0.0.0.0
network.host: 0.0.0.0
#
# Set a custom port for HTTP:
#
http.port: 9200
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when this node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
#discovery.seed_hosts: ["host1", "host2"]
#
# Bootstrap the cluster using an initial set of master-eligible nodes:
# 与node.name对应
cluster.initial_master_nodes: ["node-1"]
#
# For more information, consult the discovery and cluster formation module documentation.
#
# ---------------------------------- Gateway -----------------------------------
#
# Block initial recovery after a full cluster restart until N nodes are started:
#
#gateway.recover_after_nodes: 3
#
# For more information, consult the gateway module documentation.
#
# ---------------------------------- Various -----------------------------------
#
# Require explicit names when deleting indices:
#
#action.destructive_requires_name: true
(1)修改堆栈内存建议为机器内存的50%(当然也可以不改)
[root@localhost bin]# vim /opt/es/elasticsearch-7.7.0/config/jvm.options
-Xms1g
-Xmx1g
改为:
-Xms256m
-Xmx256m
(2)修改每个进程最大同时打开文件数 limits.conf 文件
ES因为需要大量的创建索引文件,需要大量的打开系统的文件,所以我们需要解除linux系统当中打开文件最大数目的限制,不然ES启动就会抛错,改完之后启动还是会报这个错,需要用户重新登陆再重启即可
[root@localhost ~]# vim /etc/security/limits.conf
esuser hard nofile 65536
esuser soft nofile 65536
* soft nproc 4096
* hard nproc 4096
可以查看当前系统同时打开进程数的默认值:
ulimit -Hn
ulimit -Sn
(3)修改 elasticsearch用户拥有的内存权限大小 sysctl.conf文件
调大系统的虚拟内存
[root@localhost ~]# vim /etc/sysctl.conf
文件最后添加一行内容:
vm.max_map_count=655360
添加完毕之后,执行命令刷新:
sysctl -p
(5)启动ES
注意: 启动es服务的时候,是不允许使用超级管理员root账户,那么接下来,我们需要创建一个普通用户
[root@localhost es]# adduser esuser
[root@localhost es]# passwd esuser
12345678
给esuser用户赋权限
[root@localhost es]# chown -R esuser /opt/es/elasticsearch-7.7.0
切换用户
[root@localhost es]# su - esuser
启动ES
[esuser@localhost ~]$ cd /opt/es/elasticsearch-7.7.0/bin/
[esuser@localhost bin]$ ./elasticsearch -d
判断是否启动成功,可执行如下命令,查看是否启用9200端口即可
[root@localhost es]# ss -tanl
(6)访问9200端口是否是以下内容
关闭防火墙
service firewalld status
service firewalld stop
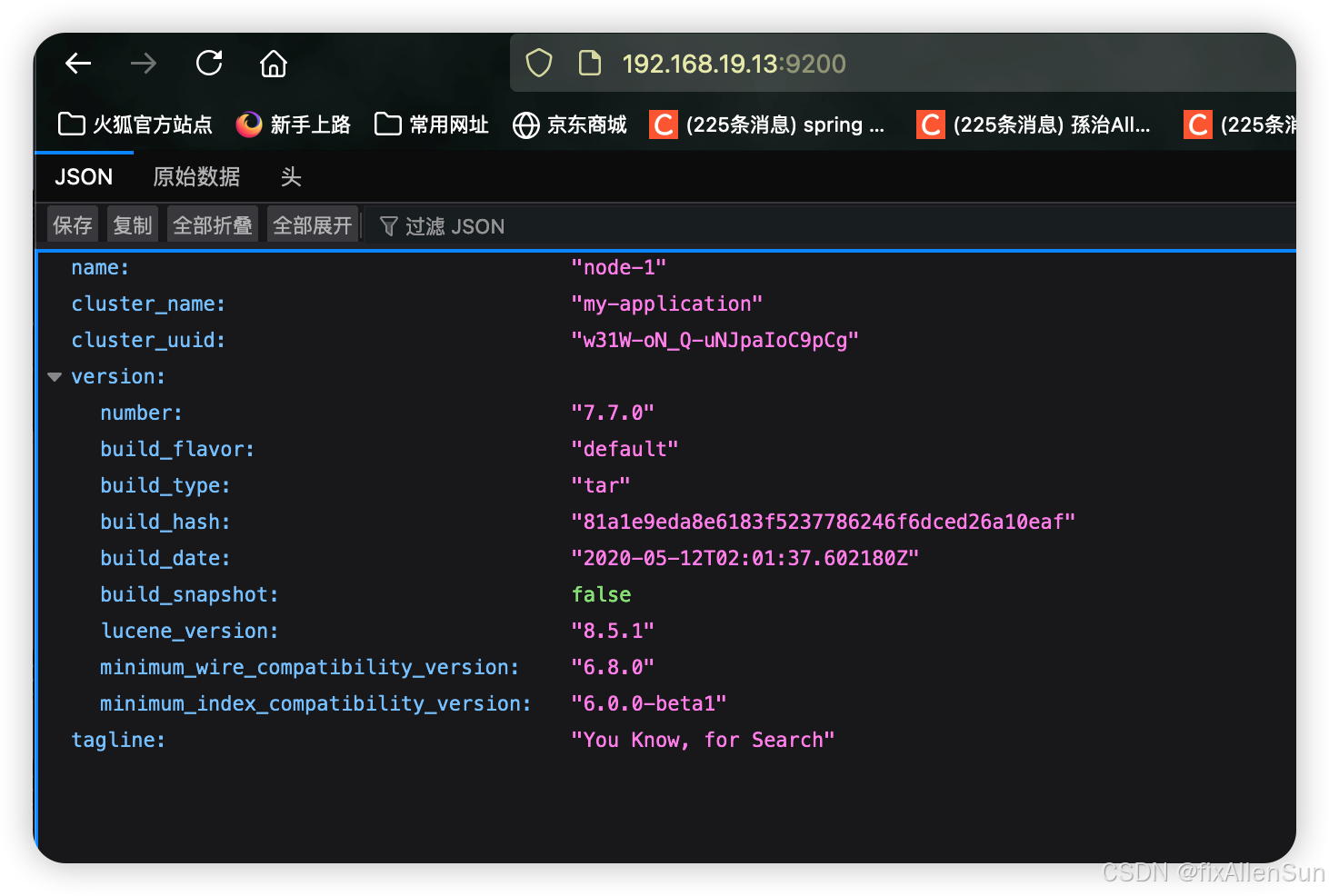
[esuser@localhost es] curl 127.0.0.1:9200
{
"name" : "nYjxCs3",
"cluster_name" : "my-application",
"cluster_uuid" : "_4ODdDaESQatC4LU9AzSVQ",
"version" : {
"number" : "6.6.1",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "1fd8f69",
"build_date" : "2019-02-13T17:10:04.160291Z",
"build_snapshot" : false,
"lucene_version" : "7.6.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
如果显示如上信息,则代表Linux下ES已经搭建完毕(单机)
或者
(7)如果端口被占用
ps -ef | grep elastic
kill -9 18578
cd /opt/es/elasticsearch-7.7.0/bin/
./elasticsearch
【3】安装Kibana
(1)下载kibana
进入es目录,将kibana和elasticsearch放在同一个目录下,保证kibana和es的版本一致
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.7.0-linux-x86_64.tar.gz
解压安装包
tar -xf kibana-7.7.0-linux-x86_64.tar.gz
(2)修改配置
(1)修改 kibana.yml 配置
进入config目录,编辑kibana.yml,主要修改这三个参数:
server.port: 5601
server.host: "服务器IP" #可以用0.0.0.0
elasticsearch.hosts: ["http://IP:9200"] # 这里是elasticsearch的访问地址
(3)启动kibana
这就已经配置完毕了,然后进入到bin目录下,进行后台启动
可以使用root用户启动
nohup ./kibana &
或者
./kibana --allow-root
Kibana 启动报错 Error: Unable to write Kibana UUID file, please check the uuid.server configuration value in kibana.yml
给 Kibana 的安装目录授权或者使用上面的root
然后通过ip:5601即可访问(记得开放相应端口)
【4】安装ik分词器
同样是7.7版本,保持一致
(1)在/elasticsearch-7.7.0/plugins/的目录下新建ik文件夹
mkdir -p /opt/es/elasticsearch-7.7.0/plugins/ik
进入这个目录,线上下载ik分词器
https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.7.0/elasticsearch-analysis-ik-7.7.0.zip
将下载的分词器zip放到ik文件夹,解压文件
unzip elasticsearch-analysis-ik-7.7.0.zip
没有的话就安装unzip
sudo yum install unzip
(2)重启es生效
ps -ef |grep elasticsearch
kill -9 ID
./elasticsearch -d
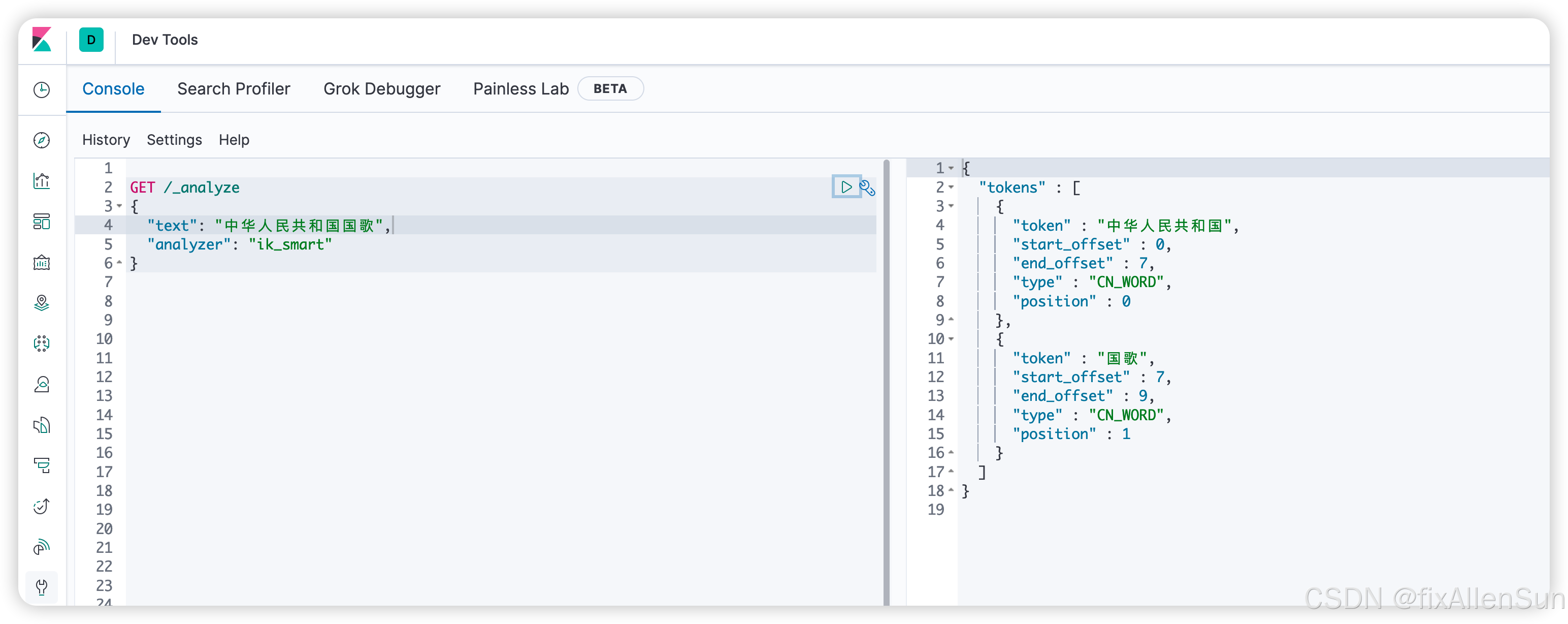
测试ik安装成功
GET /_analyze
{
"text": "中华人民共和国国歌",
"analyzer": "ik_smart"
}
(3)在线安装IK配置文件
es安装目录中config目录analysis-ik/IKAnalyzer.cfg.xml
【五】基本使用
【六】es知识点
【1】数据类型介绍
(1)结构化数据
例如用户信息,包括姓名年龄性别等等,这些信息是有关系的,可以保存到关系型数据库中,比如mysql,并可以通过sql语句来进行数据查询,还可以通过索引来提高查询效率。这种数据的存储方式的优点就是方便查询和方便管理,缺点就是不方便扩展,机构确定以后扩展起来很不方便。
(2)非结构化数据
非结构化数据也就是我们无法用二维表来表示的数据,例如服务器日志,工作文档报表等等,维度广数据量大,数据查询和存储的成本是非常大的,往往需要专业人员和大量的统计模型来进行处理,一般会把这种数据保存到nosql数据库中,比如mangob、redis等。这种一般都是以k-v结构来保存的,通过key来查询value,相对较快。
(3)半结构化数据
将数据的结构和内容混在一起,没有明显的区分,比如xml、html,这种文档其实就是半结构化数据,这种数据一般也都是保存到mangodb、hbase这样的数据库当中,缺点就是查询内容不容易,生活中很多场景下我们搜索的对象并非都是关系型结构化的数据,我们无法像数据库模糊查询那样模糊匹配,更不可能遍历所有的内容做匹配
es就是用来准确的查询结构化数据和非结构化数据
【2】技术选型
数据平台的建设中最常见的需求就是数据采集,数据存储,分析查询已以展示,而大数据开源社区正好有相对应的开源项目,我们接下来所学习的elastic search就是用于存储搜索数据的项目,而beats和 logstash就是用于采集和传输数据的项目,kibana是用于展示数据的项目。
这些项目组合在一块儿所形成的技术站,我们简称为elk stack,在整个技术战当中我们的elastic search是它提供的核心,我们简称为es,它是一个开源的,高扩展的分布式的全文搜索引擎,我们这里提到了一个叫全文搜索。那么所谓的全文搜索,我们可以简单的理解为叫全站搜索,比如在博客网站当中,用户可以在网站里面去写一些文章。那么其他的用户呢可以根据热门词汇内容,关键字等等进行搜索,查询整个网站当中所有匹配的文章,并以列表的形式展现结果。
当传统数据库进行这样的全文检索时,效率其实是非常低的,即使进行一些sql的优化,索引的优化效果也不会很明显。所以在生产环境中这种常规的搜索方式效果是比较差的,那么这就需要我们采用专门用于全文检索的搜索引擎。提到搜索引擎就不得不提到一个由JAVA语言开发的免费开源工具,我们叫做lucene,是阿帕奇软件基金会的一个项目,它提供了进行全文检索的程序接口,但是它本身并不能够独立使用,需要在它的基础上搭建完善的服务器框架才能应用。那么我们的es和solar其实这两个搜索引擎软件就是lucene开发的,他们是基于lucene进行开发,所以从内核的角度他们区别不大,那我们选择什么呢?需要从以下几点来进行考虑。
那么首先我们考虑的比较多的是我们搜索之外要进行的统计分析,es表现的会更好一些。还有既然要对我海量数据进行查询,那么我们就需要我们的搜索服务器要是集群,而且应该是可以扩展的,所以对于我们搜索引擎进行可扩展和我们性能的这种操作是很重要的,es是表现的也是非常不错的。那么还有一个就是我们的分析指标,我们希望对我们的数据呢进行大量的分析,统计出不同的指标,那么我们就需要我们的搜索引擎,它具有一些很重要的关键性指标,那我们统计完之后便于我们的分析,所以说从这几个点来讲,es还是一个首选。
【3】认识Restful和JSON
elastic search它支持分布式restful风格的搜索和分析,那么这就表示elastic search它允许采用restful风格的方式发请求进行软件的访问,它其实就是一种特定互联网软件的架构原则,这个原则我们称之为叫restful的原则。restful其实是几个单词的缩写,它表示资源状态转换。
我们在请求的资源其实有状态的,而这个状态呢会根据一些原则进行改变和转换。符合这个原则的软件架构我们就称之为叫restful风格的架构。我们的HTTP协议就遵循了restful的原则,比如在web中资源的唯一标识是uri,我们要统一资源路径,我们可以在浏览器中输入这个路径来作为网上的资源,比方说http://lcalhost:9200/test/test.txt。这个路径呢其实就是可以为网络上的一个资源,在这个路径中是不应该包含对资源的操作的,比方说增加呀,修改路径中是不应该存在的。
那么我们的restful风格它的架构中就要求我们要遵循统一的接口原则,统一接口就包含了一组受限制的预定义的操作,无论什么样的资源都应该通过使用相同的接口对资源进行访问,那么这里的接口应该符合标准的HTTP的方法,比方说我们的get、head请求,还有我们的post请求,这个在我们web开发当中,我们表单提交通常会用这两个请求,那么这两个是标准的HTTP的方法,那么除了这两个以外还有什么呢?还有我们的delete等等,那么我们就需要遵循一些方法,那也就意味着我们的路径它是资源的定位,我们的方法是对资源的操作。
那如果按照我们HTTP的方法呢,它来暴露咱们的资源,那么我们的接口就会将具有安全性和幂等性的特性。比方说get和head的请求都是安全的,无论你请求多少次都不会改变服务器资源的状态。而我们的这个get、head、put、delete,其实他们的请求都是幂等性的,就是说你无论对资源操作了多少次,结果总是一样的,后面的请求并不会比第一次请求产生更多的影响。put的时候你插入的东西永远是相同的,但是你的pose它就不是幂等性的,所以当我们采用restful风格像软件发出请求之后,软件就会返回响应。
那么它的返回的数据格式呢是一个叫JSON格式,其实我们可以在请求体当中也发送符合json格式的字符串发给服务器,让服务器拿到以后也可以做相应的处理,所以软件它的数据发送和数据的返回其实都是以json为标准格式的。
json其实它是几个字母的或者叫单词的缩写,叫JAVA script Object notation他表示的是一种特殊标记的JavaScript对象,在我们的JavaScript这门语言当中,他表现对象有很多种方式,其中有一个比较简单的表述方式,
这种格式现在应用在很多的软件当中,为什么呢?按理说这个不应该是JavaScript当中的吗,主要是因为这种格式它更容易转换成一个字符串,然后在网络中传递,网络中是传不了对象的,比方说你JAVA当中有一个叫new object,这个你没有办法在网络中传递,你只能把它序列化,通过网络传递方呢再去反序列化,这样的话就会稍微显得有点麻烦。那如果我们能把这样格式的内容转换成字符串,那他不也就能够在网络中传递了吗?而且识别起来会更加容易。所以json在很多的软件很多的框架当中都在使用。
【4】倒排索引
倒排索引的概念是基于MySQL这样的正向索引而言的。
(1)为什么会出现正排索引和倒排索引?
es是面向文档型的nosql存储数据库,它存储一条数据就等同于存储了一个文档。存储结构中有索引index、类型type、文档document和字段fields的概念。软件设计师将这些概念和关系数据库进行了类比,方便大家的理解和使用。
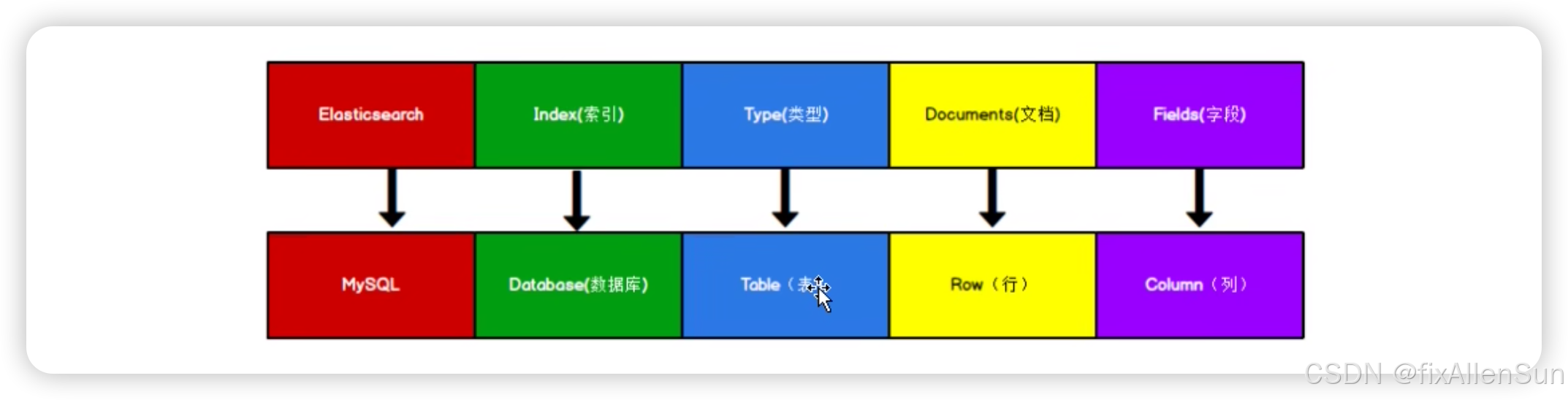
我们查询某一个数据库某张表的数据,我们会写sql,那么同样的道理,我们在es中想查询某条数据也会按照类似的规则,比方说索引、类型、文档、字段,按照这个规则去进行查询。那么早期版本这么设计是没有任何问题的,可是这种概念它违背了全文检索的原则和基本思想,首先咱们先说索引的问题,在关系数据库中索引其实是为了优化查询所设计的数据库对象,没有索引也能查询,它就是慢。而es软件专门用于全文检索数据,所以索引是整个搜索引擎当中的关键,甚至我们说在搜索引擎中万物皆索引也不为过,那么es中为了能够做到快速准确的查询,他使用了一个特殊的概念来进行数据的存储和查询,这个概念我们称之为叫倒排索引。
那么倒排索引就对应正排索引,咱们举个例子,比如我保存一篇文章,那么里面应该有文章编号,文章内容,作者以及发布时间。我们可以对文章编号id做正向索引,根据索引检索到id,然后就可以根据id查询到对应的文章所有信息记录。

如果想要查询文章的内容中包含了哪些热门词汇,这个时候就比较麻烦了,因为我们需要做模糊查询,模糊查询的效率就明显差了很多,而且他要每条数据要去遍历一下,而且你查询内容的大小写,时态等等都会影响查询的准确率。比方说我想查询zhangsan,那如果你的这个zhangsan是个大写的怎么办?你这个是小写,我想查的是大写,那你说他算不算?他算匹配了呢,还算不匹配呢?
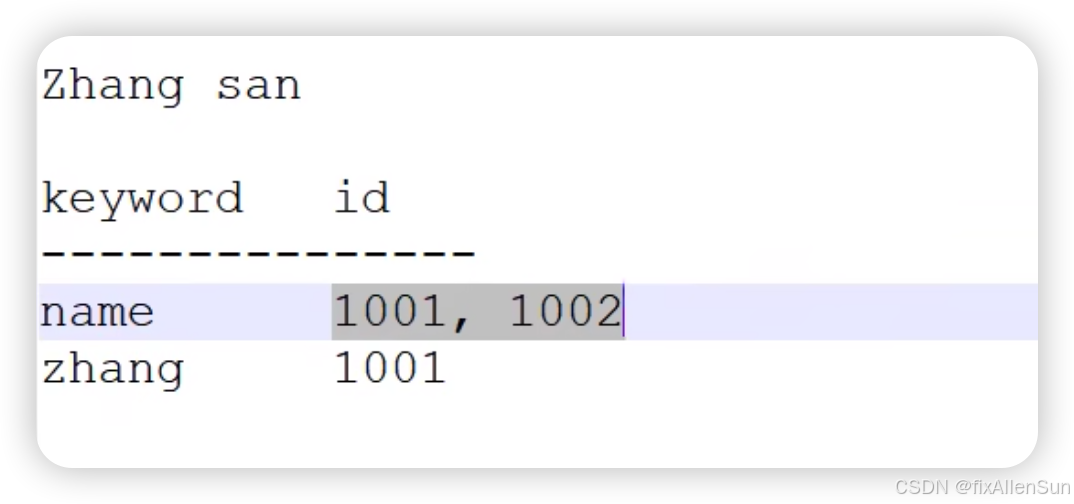
所以这就需要我们换一种方式来将索引和数据关联,这就需要用到我们之前所提到的叫倒排索引。举个例子,我们现在把这个ID保存数据保持不变,但是我们的索引不像刚才一样了,换一种方式,把这个关键字和咱们那个文章的ID做一个关联,比方说我想查询这个name,拿name做一个关键字,对应了1001。如果我想查询包含zhangsan的那个文章,通过关键字来查询ID,然后再关联文章内容,以前是通过组建ID关联文件内容再去找他的关键字,所以正好跟之前是相反的,这个就统称为叫倒排索引。
倒排索引的查询效率是比较快的,可是这里不会体现表的概念。如果是模糊查询的话,会告诉你这个数据它在哪张表里面,它的模糊查询的规则是什么。但是在倒牌索引中,他强调的是关键字和这个文档编号的一个关联,所以那个表的作用已经没有那么明显了。所以最开始说的和关系数据库的类比关系已经村不存在了。
(2)什么是正向索引
那么什么是正向索引呢?例如给下表(tb_goods)中的id创建索引:
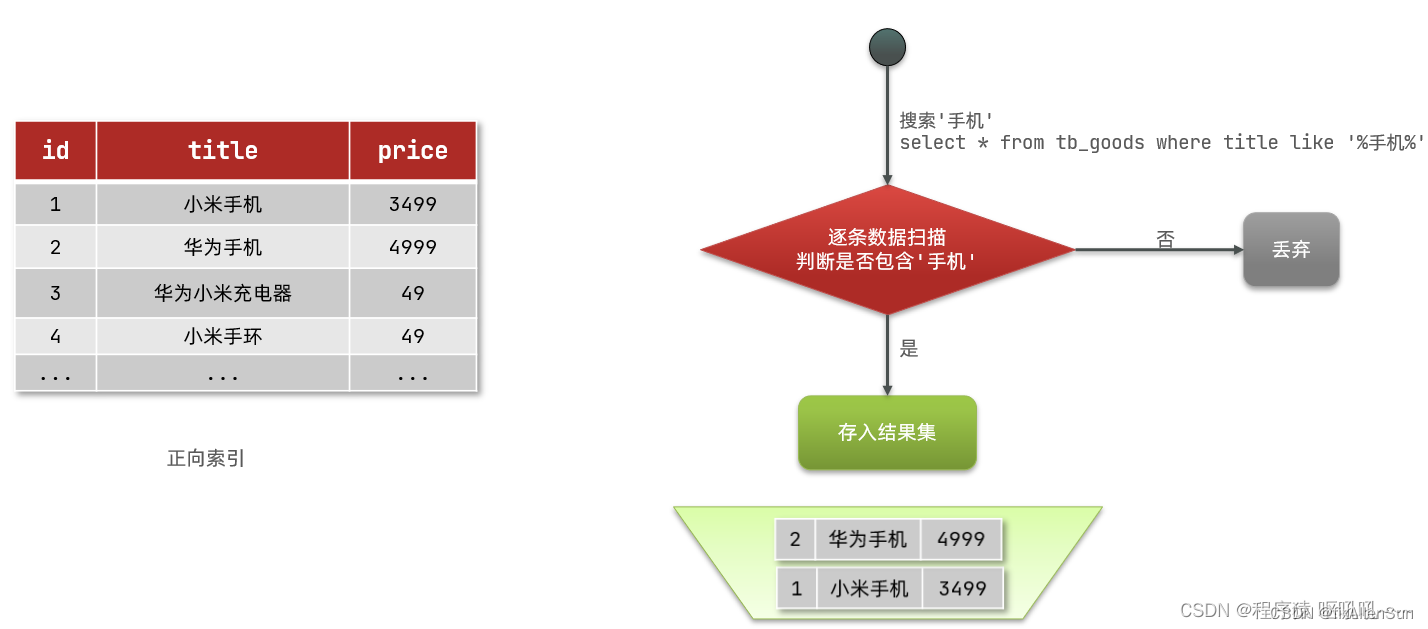
如果是根据id查询,那么直接走索引,查询速度非常快。
但如果是基于title做模糊查询,只能是逐行扫描数据,流程如下:
1)用户搜索数据,条件是title符合"%手机%"
2)逐行获取数据,比如id为1的数据
3)判断数据中的title是否符合用户搜索条件
4)如果符合则放入结果集,不符合则丢弃。回到步骤1
逐行扫描,也就是全表扫描,随着数据量增加,其查询效率也会越来越低。当数据量达到数百万时,就是一场灾难。
(3)什么是倒排索引
倒排索引中有两个非常重要的概念:
(1)文档(Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息
(2)词条(Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
创建倒排索引是对正向索引的一种特殊处理,流程如下:
(1)将每一个文档的数据利用算法分词,得到一个个词条
(2)创建表,每行数据包括词条、词条所在文档id、位置等信息
(3)因为词条唯一性,可以给词条创建索引,例如hash表结构索引

倒排索引的搜索流程如下(以搜索"华为手机"为例):
1)用户输入条件"华为手机"进行搜索。
2)对用户输入内容分词,得到词条:华为、手机。
3)拿着词条在倒排索引中查找,可以得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档。

虽然要先查询倒排索引,再查询倒排索引,但是无论是词条、还是文档id都建立了索引,查询速度非常快!无需全表扫描。
(4)正向和倒排
那么为什么一个叫做正向索引,一个叫做倒排索引呢?
(1)正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
(2)而倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
(5)正向索引优缺点
(1)优点:
1-可以给多个字段创建索引
2-根据索引字段搜索、排序速度非常快
(2)缺点:
根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。
(6)倒排索引优缺点
(1)优点:
1-根据词条搜索、模糊搜索时,速度非常快
(2)缺点:
1-只能给词条创建索引,而不是字段
2-无法根据字段做排序
【5】es的一些概念
elasticsearch中有很多独有的概念,与mysql中略有差别,但也有相似之处。
(1)文档和字段
elasticsearch是面向**文档(Document)**存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中:

而Json文档中往往包含很多的字段(Field),类似于数据库中的列。
(2)索引和映射
索引(Index),就是相同类型的文档的集合。
例如:
(1)所有用户文档,就可以组织在一起,称为用户的索引;
(2)所有商品的文档,可以组织在一起,称为商品的索引;
(3)所有订单的文档,可以组织在一起,称为订单的索引;

因此,我们可以把索引当做是数据库中的表。
数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束。
(3)mysql与elasticsearch
我们统一的把mysql与elasticsearch的概念做一下对比:
 (1)两者的特长
(1)两者的特长
1-Mysql:擅长事务类型操作,可以确保数据的安全和一致性
2-Elasticsearch:擅长海量数据的搜索、分析、计算
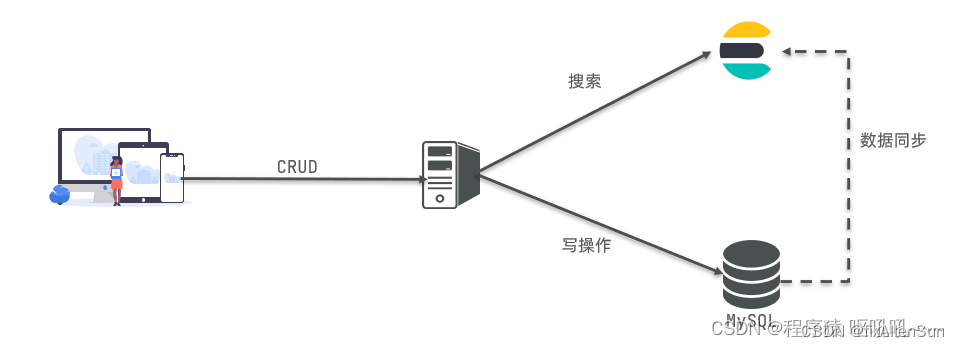
因此在企业中,往往是两者结合使用:
1-对安全性要求较高的写操作,使用mysql实现
2-对查询性能要求较高的搜索需求,使用elasticsearch实现
3-两者再基于某种方式,实现数据的同步,保证一致性
【6】分词器
(1)分词器的作用是什么?
1-创建倒排索引时对文档分词
2-用户搜索时,对输入的内容分词
(2)IK分词器有几种模式?
1-ik_smart:智能切分,粗粒度
2-ik_max_word:最细切分,细粒度
(3)IK分词器如何拓展词条?如何停用词条?
1-利用config目录的IkAnalyzer.cfg.xml文件添加拓展词典和停用词典
2-在词典中添加拓展词条或者停用词条
【七】索引库操作
索引库就类似数据库表,mapping映射就类似表的结构。
我们要向es中存储数据,必须先创建“库”和“表”。
【1】mapping映射属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
(1)type:字段数据类型,常见的简单类型有:
字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
数值:long、integer、short、byte、double、float、
布尔:boolean
日期:date
对象:object
(2)index:是否创建索引,默认为true
(3)analyzer:使用哪种分词器
(4)properties:该字段的子字段
例如下面的json文档:
{
"age": 21,
"weight": 52.1,
"isMarried": false,
"info": "黑马程序员Java讲师",
"email": "zy@itcast.cn",
"score": [99.1, 99.5, 98.9],
"name": {
"firstName": "云",
"lastName": "赵"
}
}
对应的每个字段映射(mapping):
(1)age:类型为 integer;参与搜索,因此需要index为true;无需分词器
(2)weight:类型为float;参与搜索,因此需要index为true;无需分词器
(3)isMarried:类型为boolean;参与搜索,因此需要index为true;无需分词器
(4)info:类型为字符串,需要分词,因此是text;参与搜索,因此需要index为true;分词器可以用ik_smart
(5)email:类型为字符串,但是不需要分词,因此是keyword;不参与搜索,因此需要index为false;无需分词器
(6)score:虽然是数组,但是我们只看元素的类型,类型为float;参与搜索,因此需要index为true;无需分词器
(7)name:类型为object,需要定义多个子属性
1-name.firstName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
2-name.lastName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
【2】Kibana进行索引库的CRUD
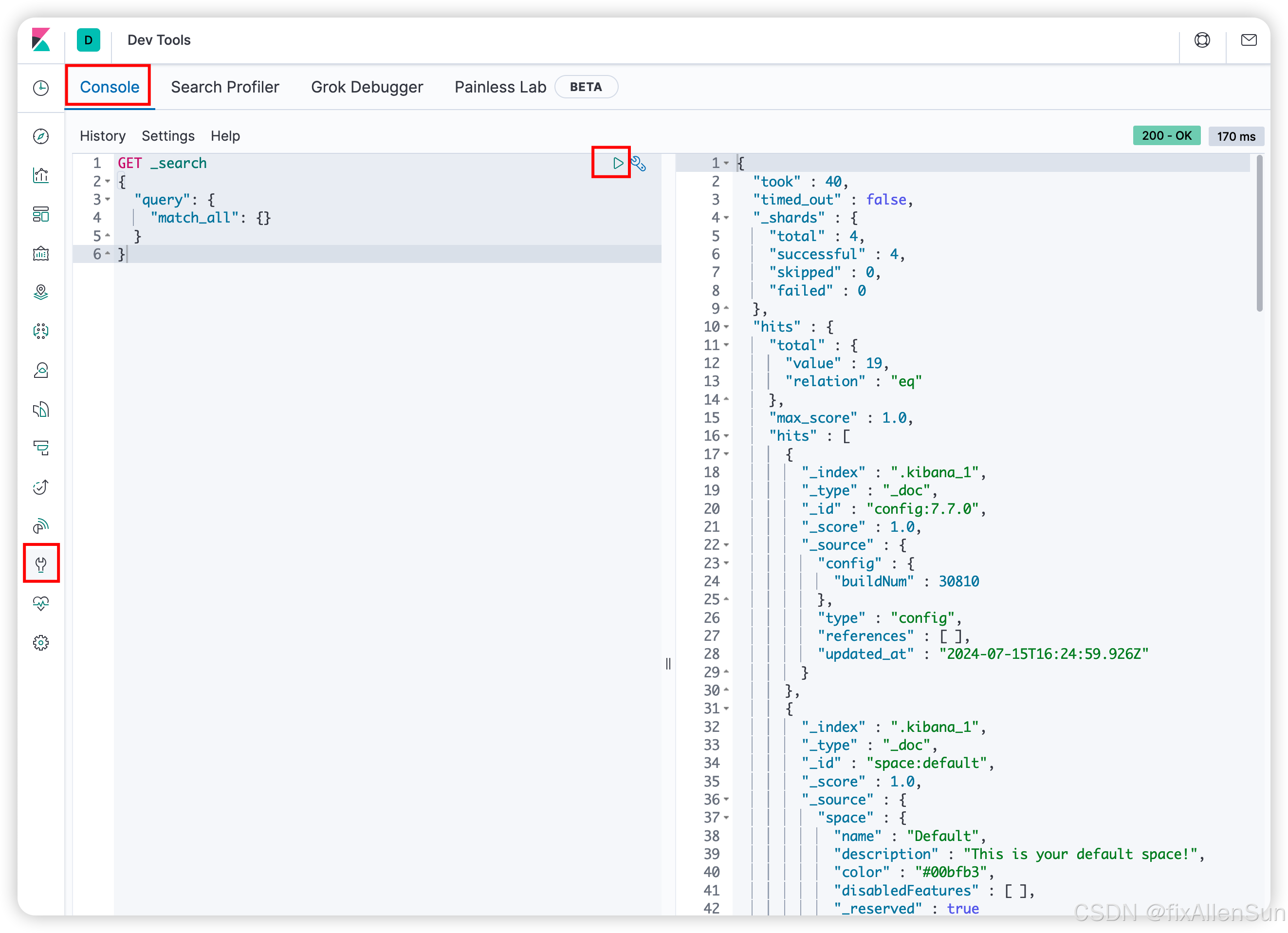
ES是面向文档的,存储文档的同时对其进行索引使其能够被搜索到。这里我们统一使用Kibana编写DSL的方式来演示。
(1)创建索引
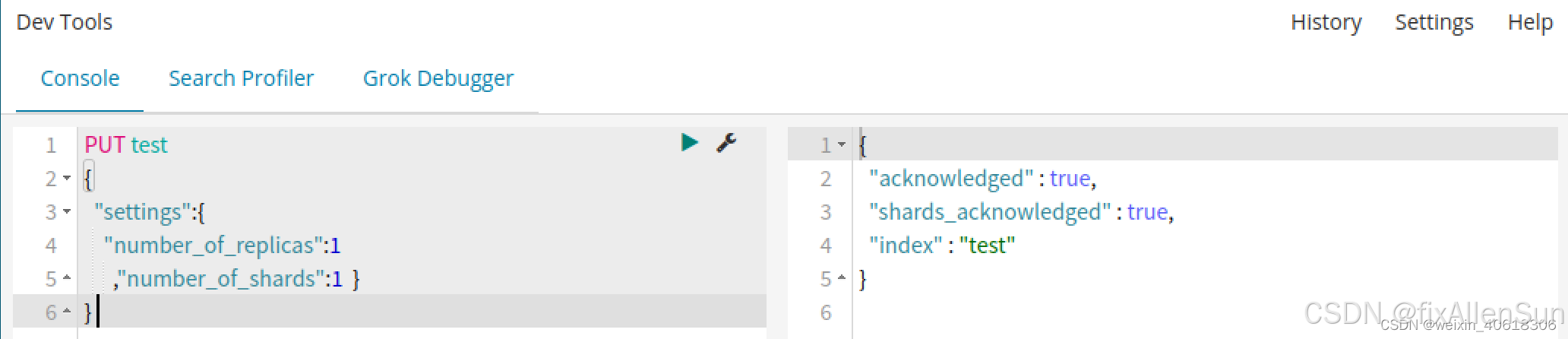
Elasticsearch采用Rest API风格,因此其API就是一次HTTP请求,可以使用任何工具发起http请求创建索引的请求格式。由于遵循REST风格,可以很直观的想到操作名。
POST新增
GET查询
DELETE删除
PUT修改
 number_of_replicas:设置索引库分片副本数量
number_of_replicas:设置索引库分片副本数量
number_of_shards: 设置索引库分片数量
(2)查看索引
(1)查看某一个特定索引库
GET 索引库名
(2)查看所有的索引库
GET *
(3)删除索引
DELETE 索引库名
(4)映射配置
索引有了,接下来就是添加数据,但是在添加数据之前必须定义映射。 映射就是定义文档的过程,文档包含哪些字段,这些字段是否保存,是否索引,是否分词等。只有配置清楚,Elasticsearch才会帮我们进行索引库的创建。
(3)创建映射字段
请求方式依然是PUT
PUT /索引库名/_mapping/类型名称
{
"properties": {
"字段名": {
"type": "类型",
"index": true,
"store": true,
"analyzer": "分词器"
}
}
}
(1)类型名称:就是type的概念,类似于数据库中不同表字段名;任意填写,可以指定很多属性。
(2)type:类型,可以是text、long、short、date、integer、object等
(3)index:是否索引,默认为true
(4)store:是否存储,默认为false(会自动生成一个_source备份)
(5)analyzer:分词器,这里的ik_max_word即使用ik分词器
发起请求示例
PUT test/_mapping/goods
{
"properties":{
"title":{
"type":"text",
"analyzer":"ik_max_word"
},
"images":{
"type":"keyword",
"index":false
},
"price":{
"type":"float"
}
}
}
字符串类型一共有两种,text代表进行分词,下面要加上分词器,这里使用的ik分词器中ik_max_word代表按照最大程度划分。
keyword不进行分词。
如果遇到问题:analyzer[ik_max_word] not found for field[title],说明是IK分词器插件未安装好
(4)查看映射关系
GET /索引库名/_mapping
(5)字段属性详解
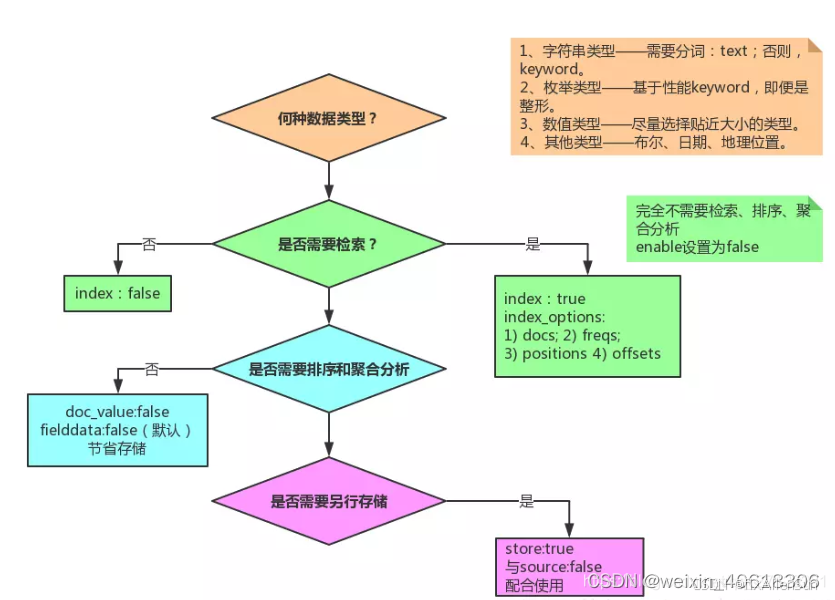
(1)type
Elasticsearch中支持的数据类型非常丰富:
下面我们介绍几个关键的:
String类型,又分两种:
1-text:可分词,不可参与聚合
2-keyword:不可分词,数据作为完整字段进行匹配,可以参与聚合
Numberical:数值类型,分两类
基本数据类型:long、integer、short、byte、double、float、half_float
浮点数的高精度类型:scaled_float
需要指定一个精度因子,比如说10或者100,elasticseach会把真实值乘以这个因子存储,取出时再还原。
Date:日期类型
elasticsearch可以对日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为long,节省空间。
(2)index
index影响字段的索引情况
1-true:字段会被索引,则可以用来进行搜索,默认值就是true
2-false: 字段不会索引,不能用来搜索
** index的默认值就是true,也就是说不进行任何配置,所有字段都会被索引。**
但是有些字段是我们不希望被索引的,比如商品的图片信息,就需要手动设置index为false。
(3)store
是否将数据进行额外存储。
在学习lucene和solr时,我们知道如果一个字段的store的值设置为false,那么在文档列表中就不会有这个字段的值,用户的搜索结果中不会显示出来。
但是在elasticsearch中,即使store设置为false,也可以搜索到结果,
原因是Elasticsearch在创建文档索引时,会将文档中的原始数据备份,保存在一个交_source的属性中,而且我们可以通过过滤_source来选择哪些要显示,哪些不显示。
而如果设置store为true,就会在_source以外额外存储一份数据,比较多余,因此一般我们都会将store设置为false,事实上,store的默认值就是false。
(6)字段映射设置流程
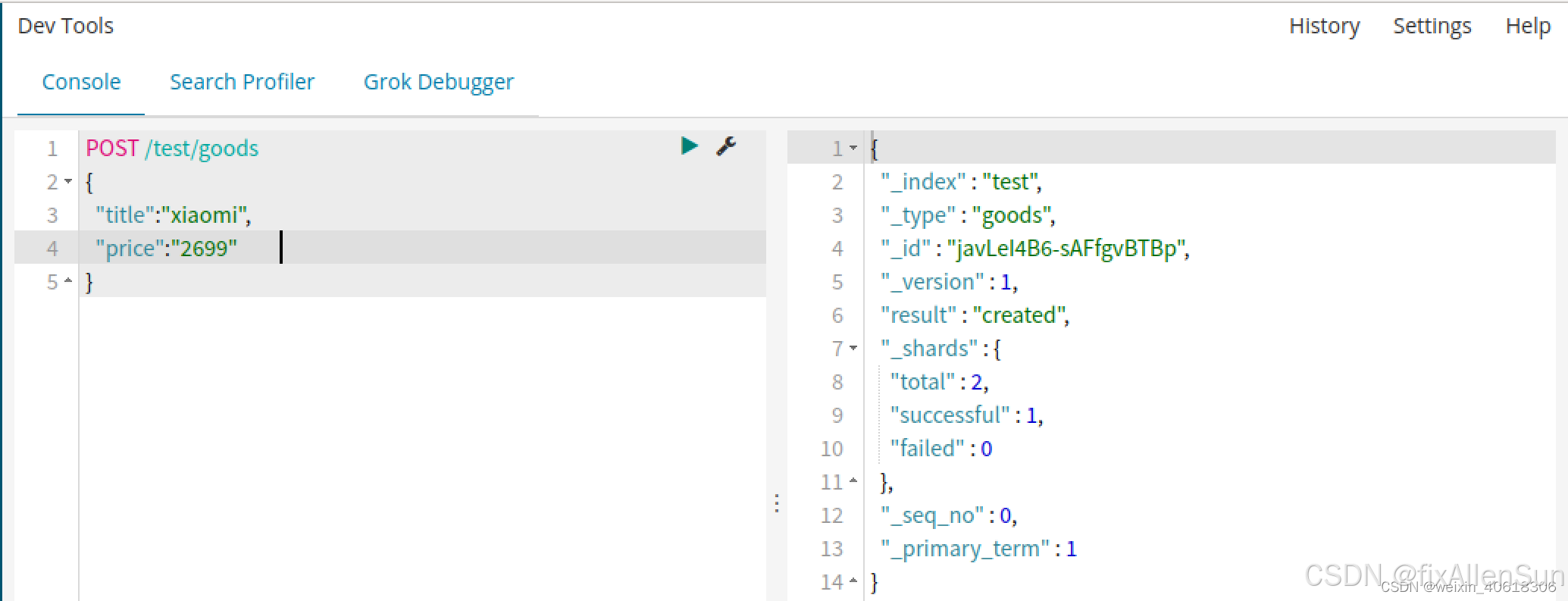
(7)新增数据
(1)新增会随机生成id
POST /索引库/类型名
{
“key”:"value"
}
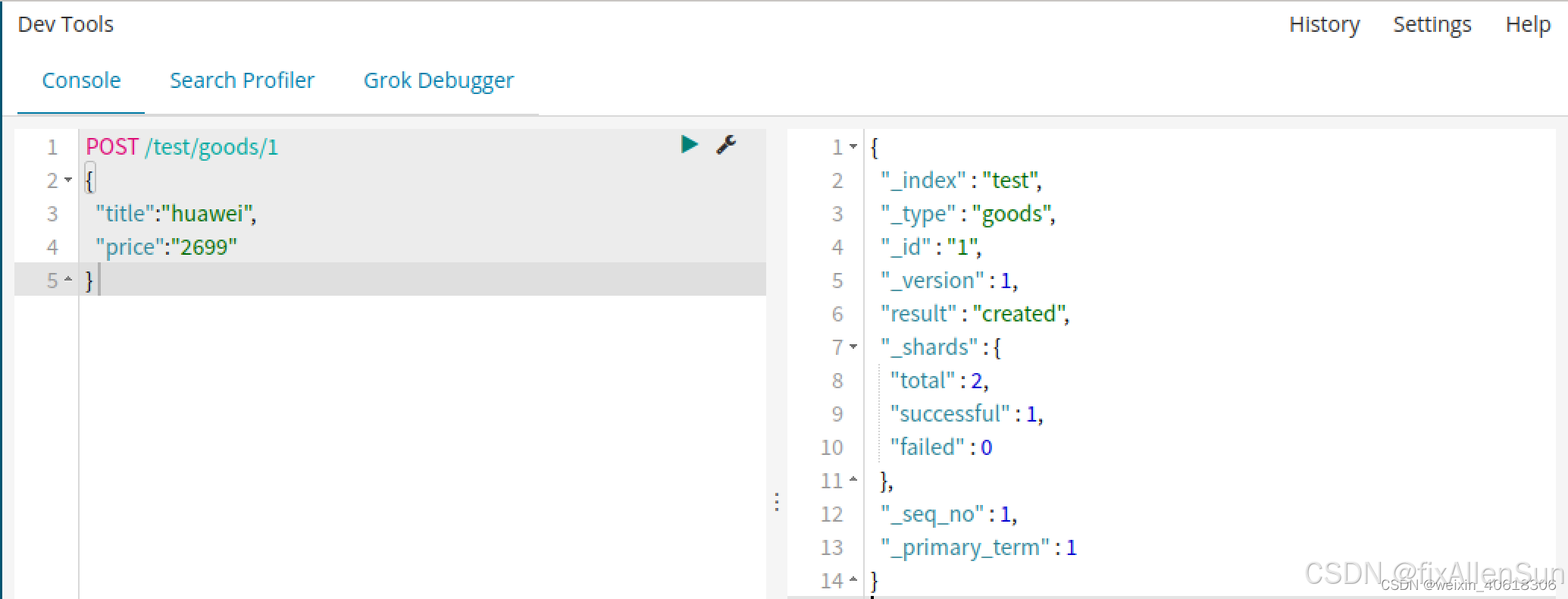
 (2)新增自定义id
(2)新增自定义id
如果我们想要自己新增的时候指定id,可以这么做
POST /索引库/类型/id值
{
}
(3)智能判断
在学习Solr时我们发现,我们在新增数据时,只能使用提前配置好映射属性的字段,否则就会报错。不过在Elasticsearch中并没有这样的规定。
事实上Elasticsearch非常智能,你不需要给索引库设置任何mapping映射,它也可以根据你输入的数据来判断类型,动态添加数据映射。
 相对上个例子来说,我这里新增了color和address两个字段。再看下索引库的映射关系
相对上个例子来说,我这里新增了color和address两个字段。再看下索引库的映射关系
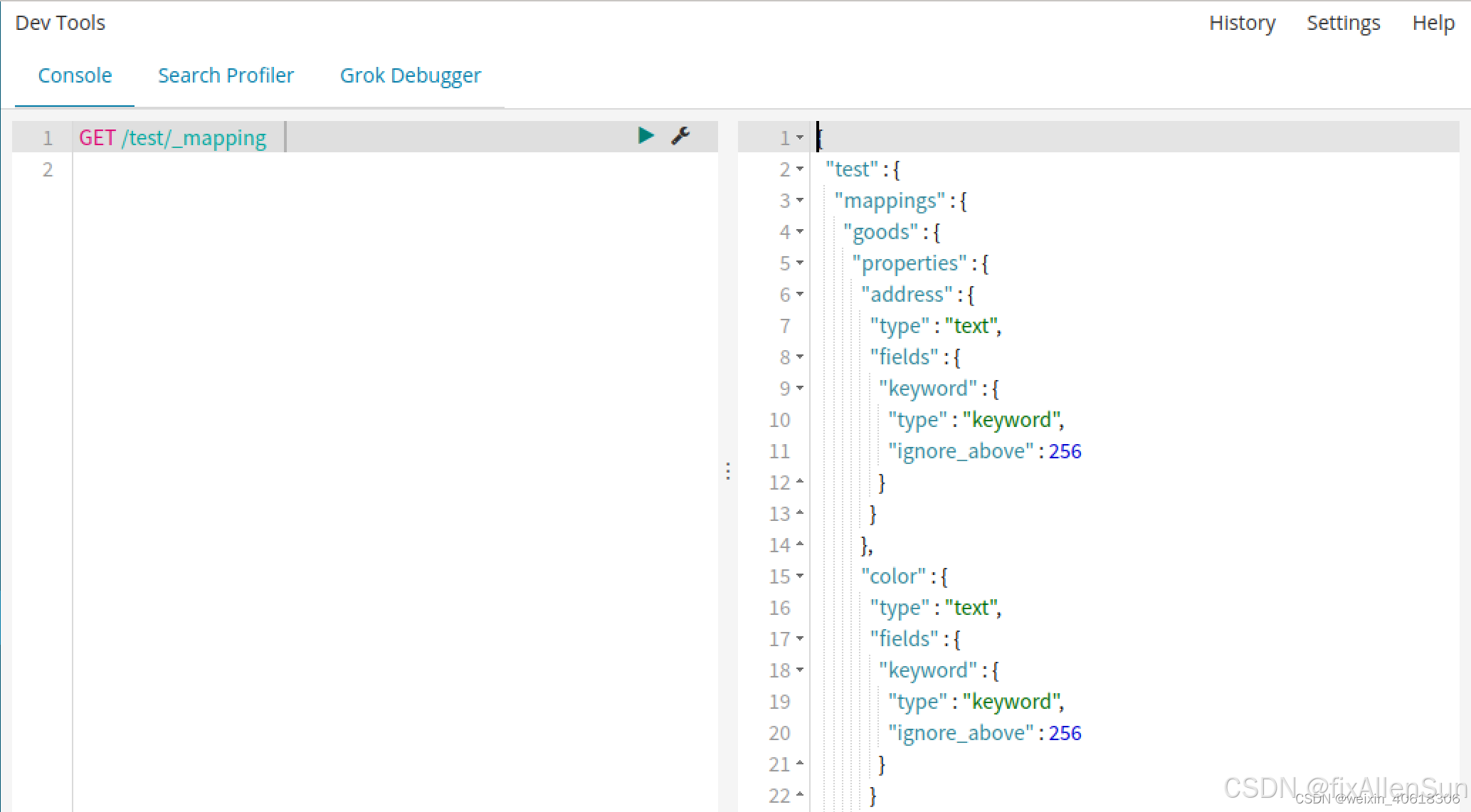 color和address都被成功映射了。
color和address都被成功映射了。
(8)修改数据
把刚才新增的请求方式改为PUT,就是修改数据操作不过修改操作必须要指定id。
id对应文档存在,则修改
id对应文档不存在,则新增
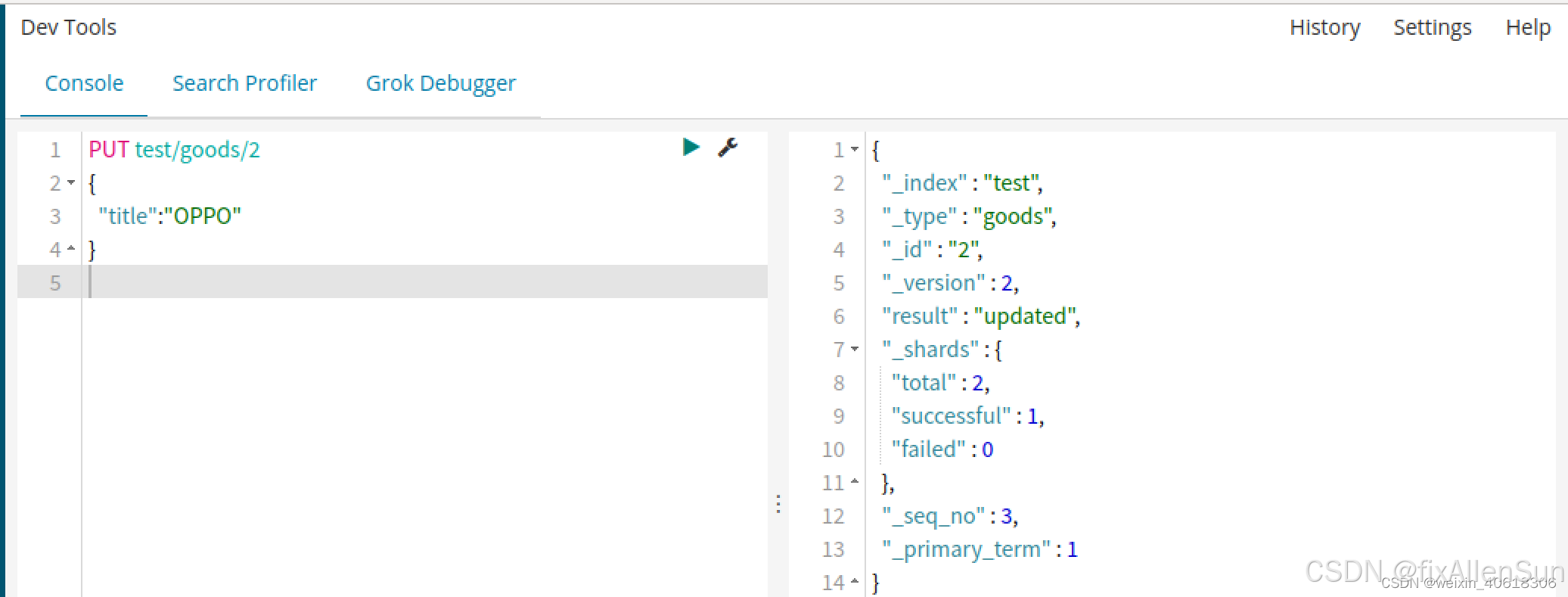 注意:如果只修改了一个字段,那么原有的其他字段都会消失,只保留当前的这次修改,相当于覆盖
注意:如果只修改了一个字段,那么原有的其他字段都会消失,只保留当前的这次修改,相当于覆盖
(9)删除数据
DELETE test/goods/2
(10)查询数据
基本查询
_source过滤
结果过滤
高级查询
排序
(1)基本查询
不能设置查询多个条件,如果需要请用后面的高级bool查询
GET /索引库名/_search
{
"query":{
“查询类型”:{
“查询条件”:“查询条件值”
}
}
}
这里的query代表一个查询对象,里面可以有不同的查询属性
1-查询类型:match_all,match,term,range等等
2-查询条件:查询条件会根据类型的不同,写法也有差异,后面根据示例进行详细讲解。
(2)查询所有(match_all)
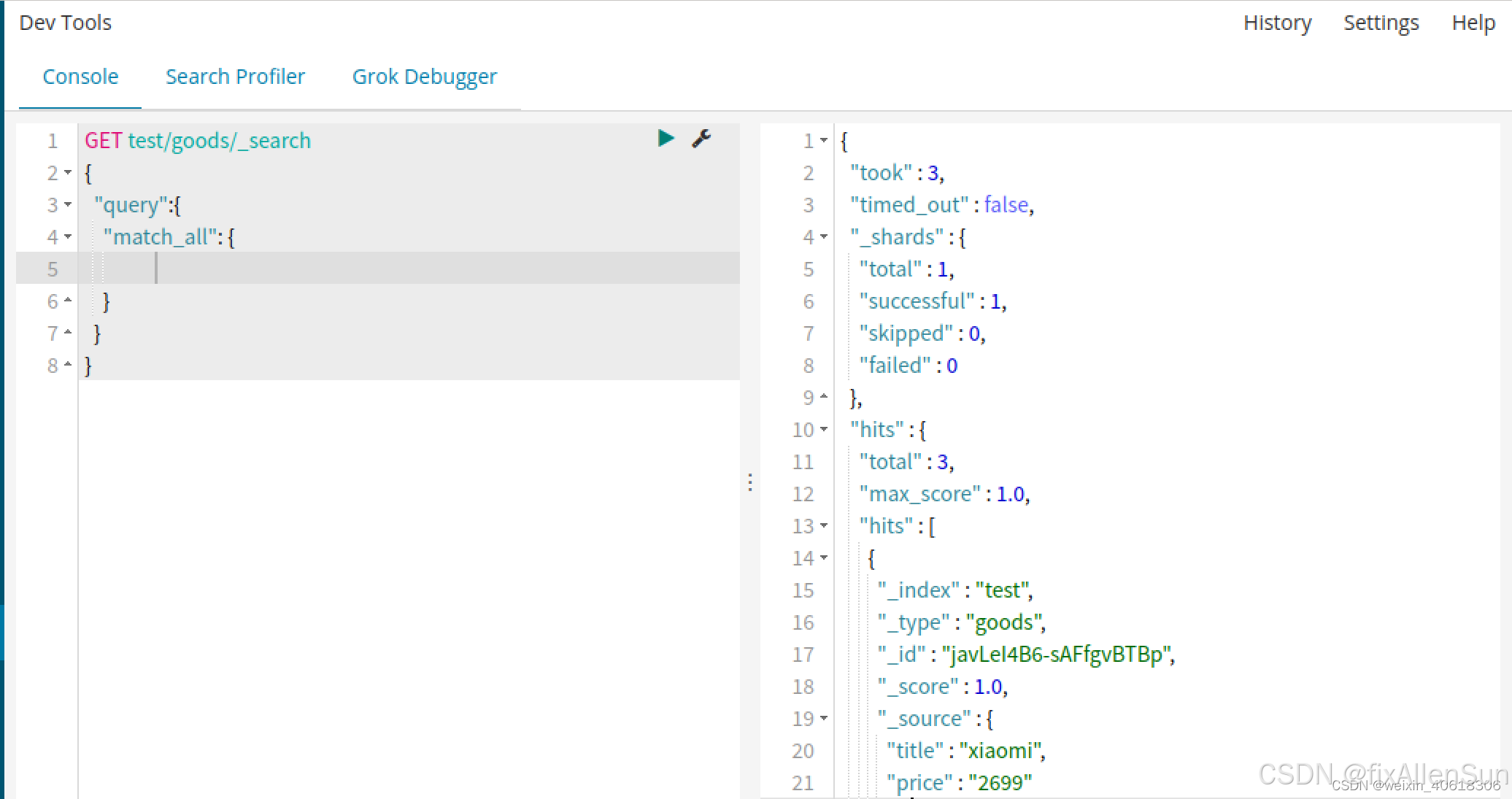
搜索结果的文档对象数组,每个元素是一条搜索到的文档信息。
_index:索引库
_type:文档类型
_id:文档id
_score:文档得分
_source:文档的源数据
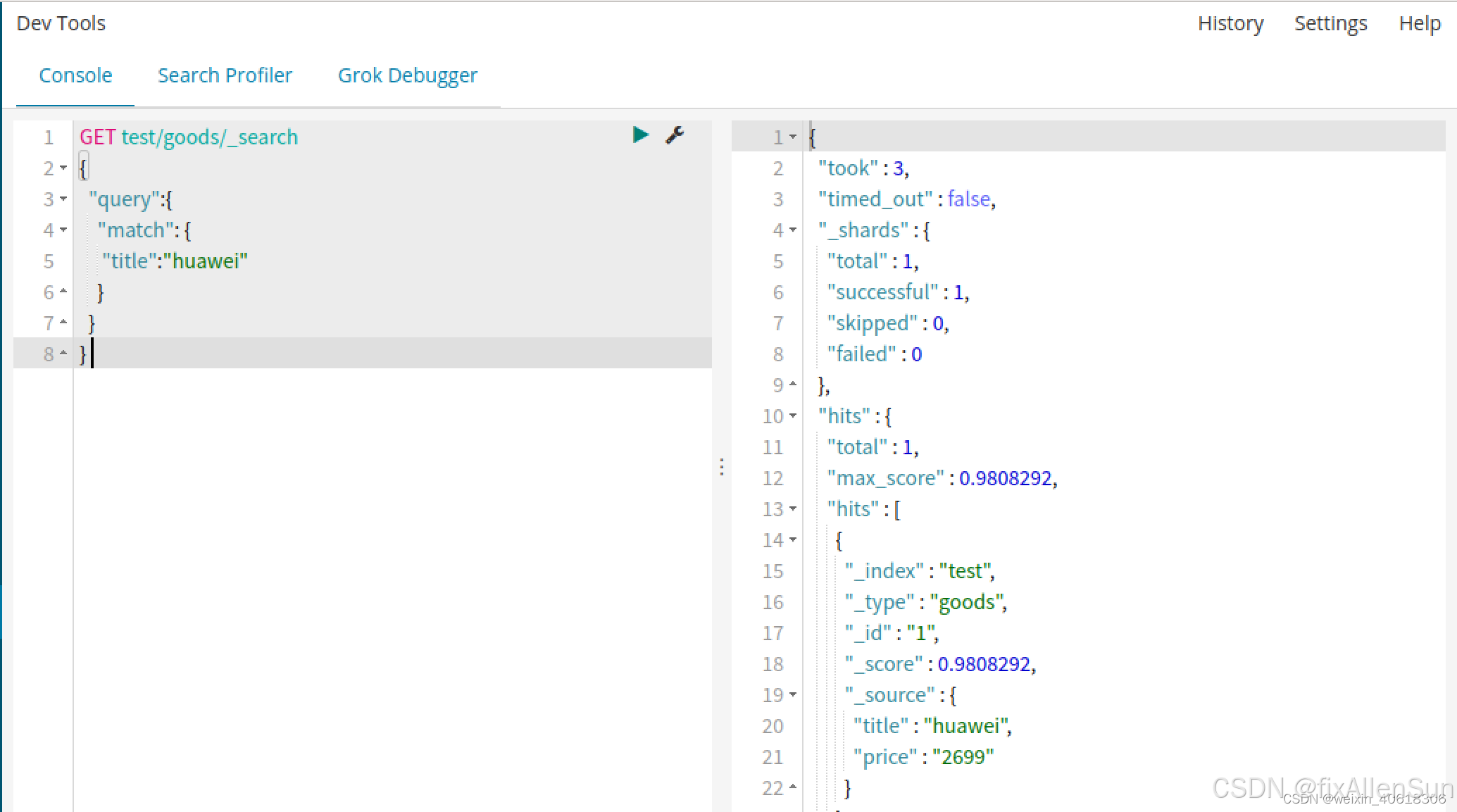
(3)匹配查询
(4)多字段查询
multi_match与match类似,不同的是它可以在多个字段中查询
GET /test/_search
{
"query":{
"multi_match": {
"query": "小米",
"fields": [ "title", "subTitle" ]
}
}
在本例中,我们会在title和subtitle字段中查询小米这个词。
(5)词条匹配
term查询被用于精确值匹配
这些精确值可能是数字、时间、布尔或者那些未分词的字符串(keyword)
GET /test/_search
{
"query":{
"term":{
"price":2699.00
}
}
}
(6)多词条精确匹配
terms查询和term查询一样,但它允许你指定多值进行匹配,如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件。
GET /test/_search
{
"query":{
"terms":{
"price":[2699.00,2899.00,3899.00]
}
}
}
(11)结果过滤
默认情况下,elasticsearch在搜索的结果中,会把文档中保存在_source的所有字段都返回。如果我们只想获取其中的部分字段,我们可以添加_source的过滤。
(1)直接指定该字段
GET /heima/_search
{
"_source": ["title","price"],
"query": {
"term": {
"price": 2699
}
}
}
(2)指定includes和excludes
我们也可以通过下面的方法来实现过滤
1-includes:来指定想要显示的字段
2-excludes:来指定不想显示的字段
GET /test/_search
{
"_source": {
"includes":["title","price"]
},
"query": {
"term": {
"price": 2699
}
}
}
与下面的结果将是一样的:
GET /test/_search
{
"_source": {
"excludes": ["images"]
},
"query": {
"term": {
"price": 2699
}
}
}
(3)布尔组合(多条件查询)
GET test/goods/_search
{
"query": {
"bool": {
"must": [
{"match": {
"title": "小米电视"
}}
],
"must_not": [
{
"match": {
"title": "电视"
}
}
]
}
}
}
查询bool里面结果全为true的情况。
(4)范围查询
range查询找出那些落在指定区间内的数字或者时间,range允许以下操作符。
gt:大于
gte:大于等于
lt:小于
lte:小于等于
GET test/goods/_search
{
"query": {
"range": {
"price": {
"gte": 3000,
"lte": 9909
}
}
}
}
(5)模糊查询
fuzzy查询是term查询的模糊等价,它允许用户搜索词条与实际词条的拼写出现偏差,但是偏差的距离不得超过2.
GET /test/_search
{
"query": {
"fuzzy": {
"title": "appla"
}
}
}
根据上面的示例,能够查询到apple的结果。我们也可以通过fuzziness来指定允许的编辑距离。
GET /test/_search
{
"query": {
"fuzzy": {
"title": {
"value":"appla",
"fuzziness":1
}
}
}
}
(6)单字段排序
sort可以让我们按照不同的字段进行排序,并且通过order指定排序的方式。
GET /test/_search
{
"query": {
"match": {
"title": "小米手机"
}
},
"sort": [
{
"price": {
"order": "desc"
}
}
]
}
sort是对查询后做的,不属于查询和过滤的条件,因此在query查询对象外面。
(7)多字段查询
假定我们想要结合使用price和_score(得分)进行查询,并且匹配的结果首先按照价格排序,然后按照相关性得分排序。
GET test/goods/_search
{
"query": {
"bool": {"must": [
{"match": {
"title": "小米"
}}
]}
},
"sort": [
{
"price": {
"order": "desc"
}
},
{
"_score": {
"order": "desc"
}
}
]
}
(8)聚合
聚合可以让我们及其方便的实现对数据的统计分析
Elasticsearch中的聚合,包含多种类型,最常用的两种,一个叫桶,一个叫度量。
(9)桶(bucket)类似于数据库中的分组group_by
桶的作用,是按照某种方式对数据进行分组,每一组数据在ES中被称为一个桶。Elasticsearch中提供的划分桶的方式有很多:
1-Date Histogram Aggregation:根据日期阶梯分组,例如给定阶梯为周,会自动每周分为一组。
2-Histogram Aggregation:根据数值阶梯分组,与日期类似;
3-Terms Aggregation:根据词条内容分组,词条内容完全匹配的为一组;
4-Range Aggregation:数值和日期的范围分组,指定开始和结束,然后按照阶段分组。
【3】操作案例
(1)创建索引
PUT 索引名称
注意点:
(1)索引名称需要小写
(2)已经存在的索引名称 ,重复创建会报错
可以使用head名称查询索引是否存在,根据状态码判断是否存在,200存在,404不存在
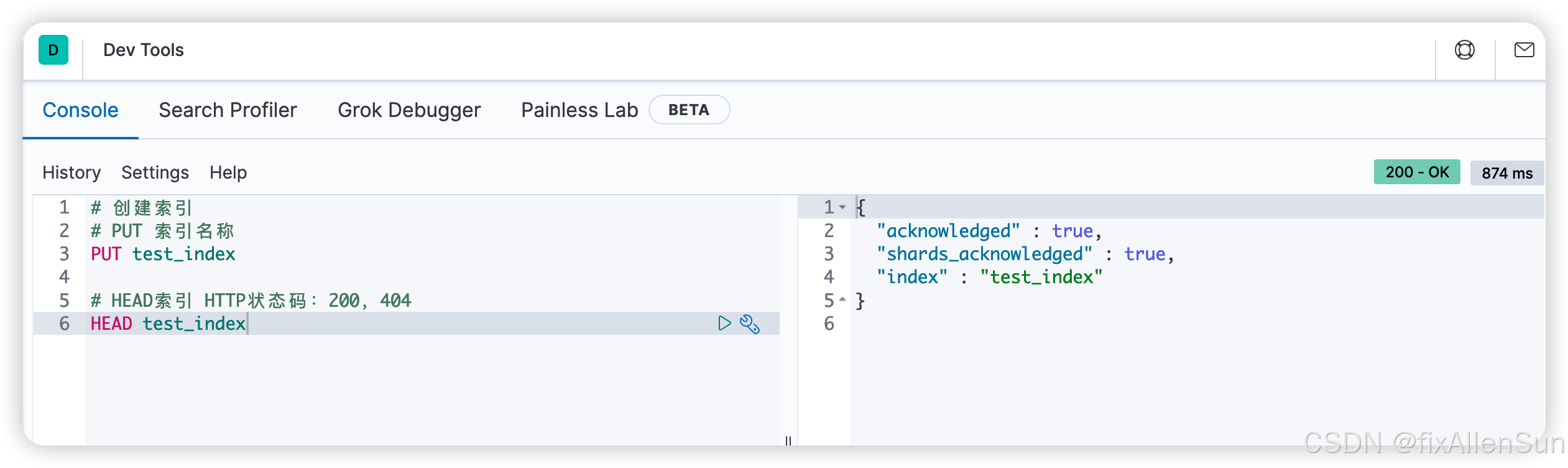
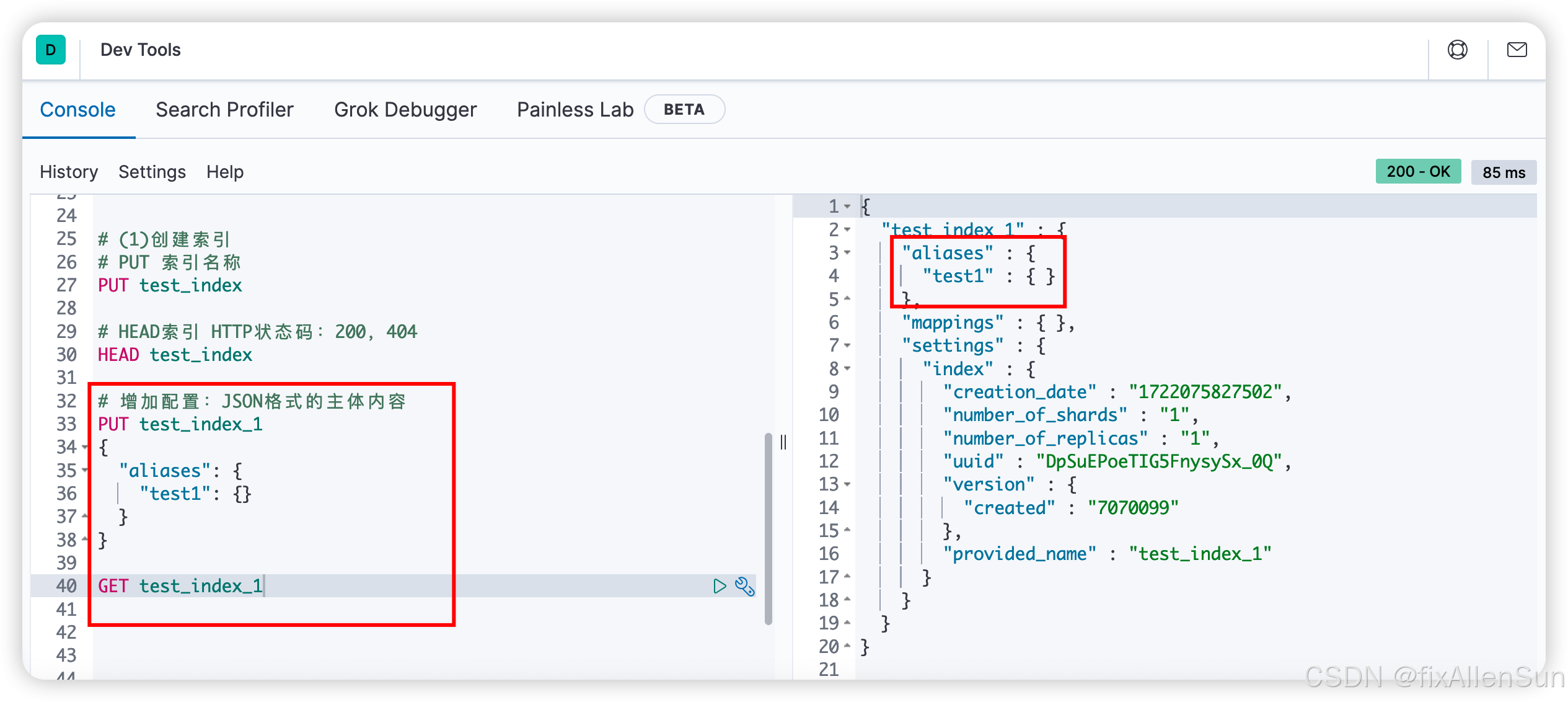
创建索引,并且添加配置信息
# 增加配置:JSON格式的主体内容
PUT test_index_1
{
"aliases": {
"test1": {}
}
}
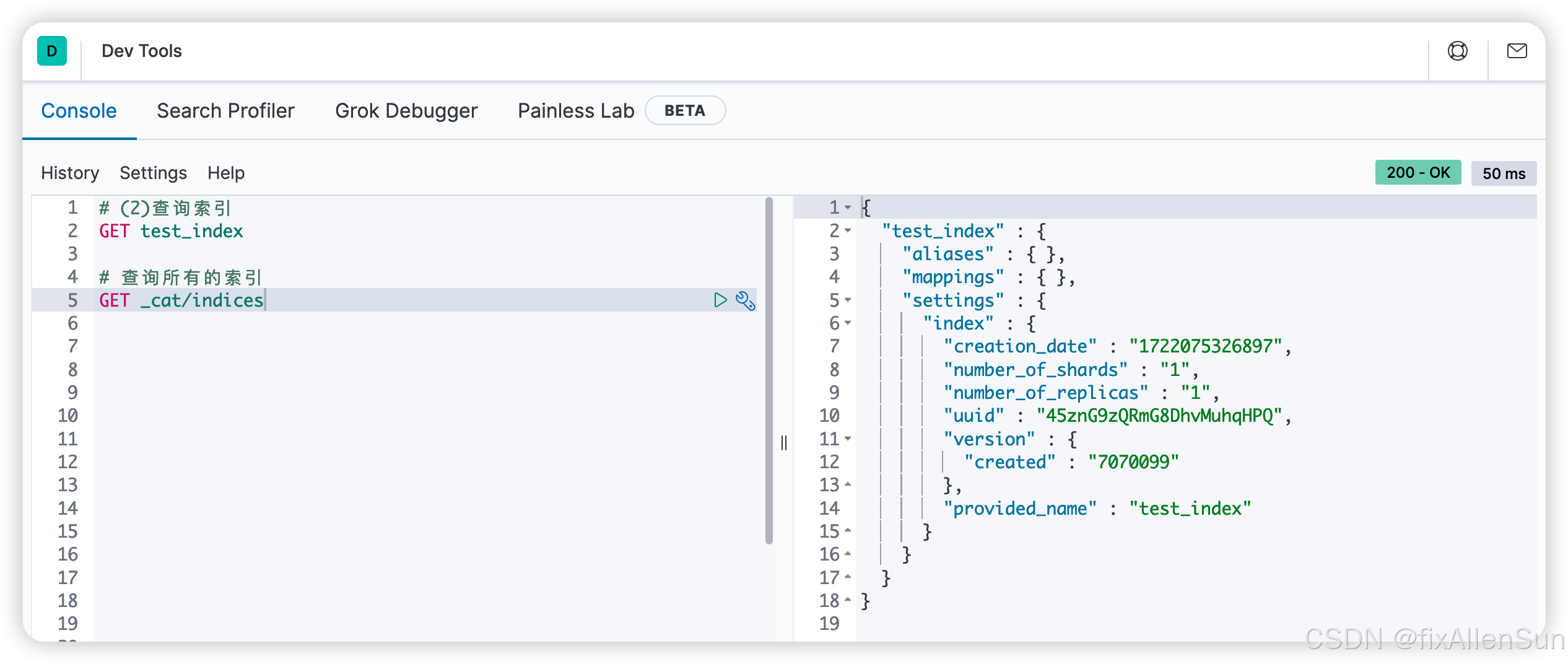
(2)查询索引
# (2)查询索引
GET test_index
es帮我们补充了其他的信息
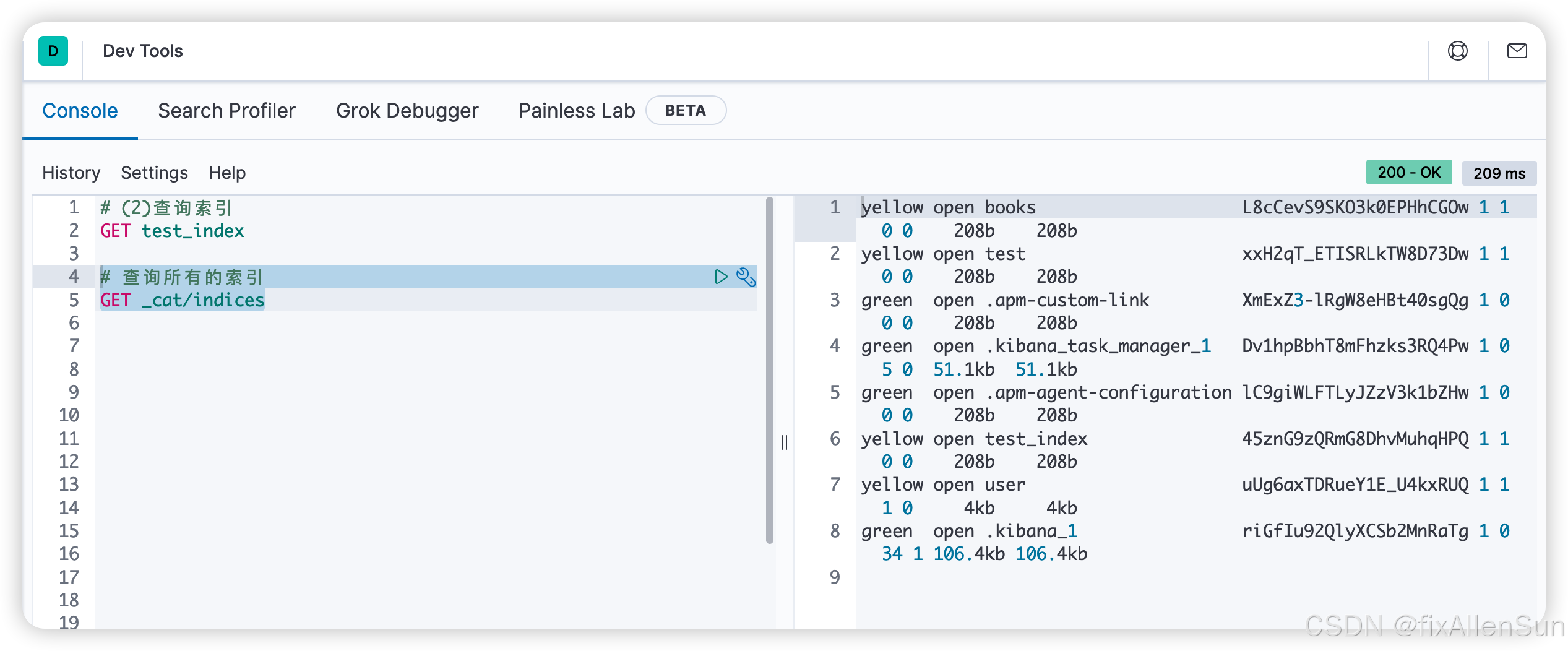
查询所有的索引
# 查询所有的索引
GET _cat/indices
(3)修改索引(不允许修改)
索引修改以后,所有数据都需要重新分配,所以不允许修改
(4)删除索引
# 删除索引
DELETE test_index_1
(5)创建文档
文档是es软件搜索数据的最小单位,不依赖预先定义的模式,所以可以把文档类比为表的一行json类型的数据。在关系型数据库中,要提前定义字段才能使用,在es中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
索引创建好了以后,接下来就是从创建文档,并且添加数据,这里的文档可以类比为关系型数据库中的表数据,添加的数据格式是JSON格式
# (3)创建文档(也即是创建索引的数据)
PUT test_doc
# 不指定唯一标识
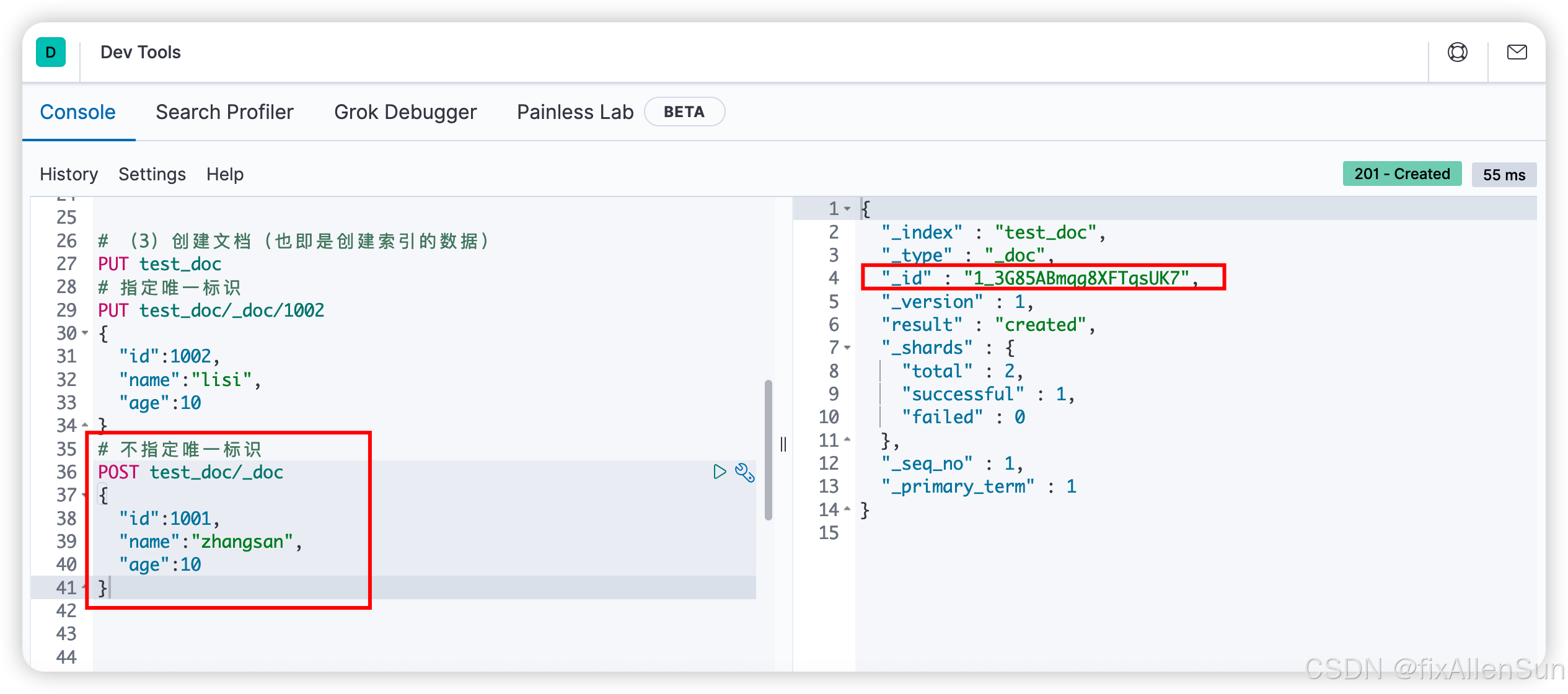
POST test_doc/_doc
{
"id":1001,
"name":"zhangsan",
"age":10
}
# 指定唯一标识
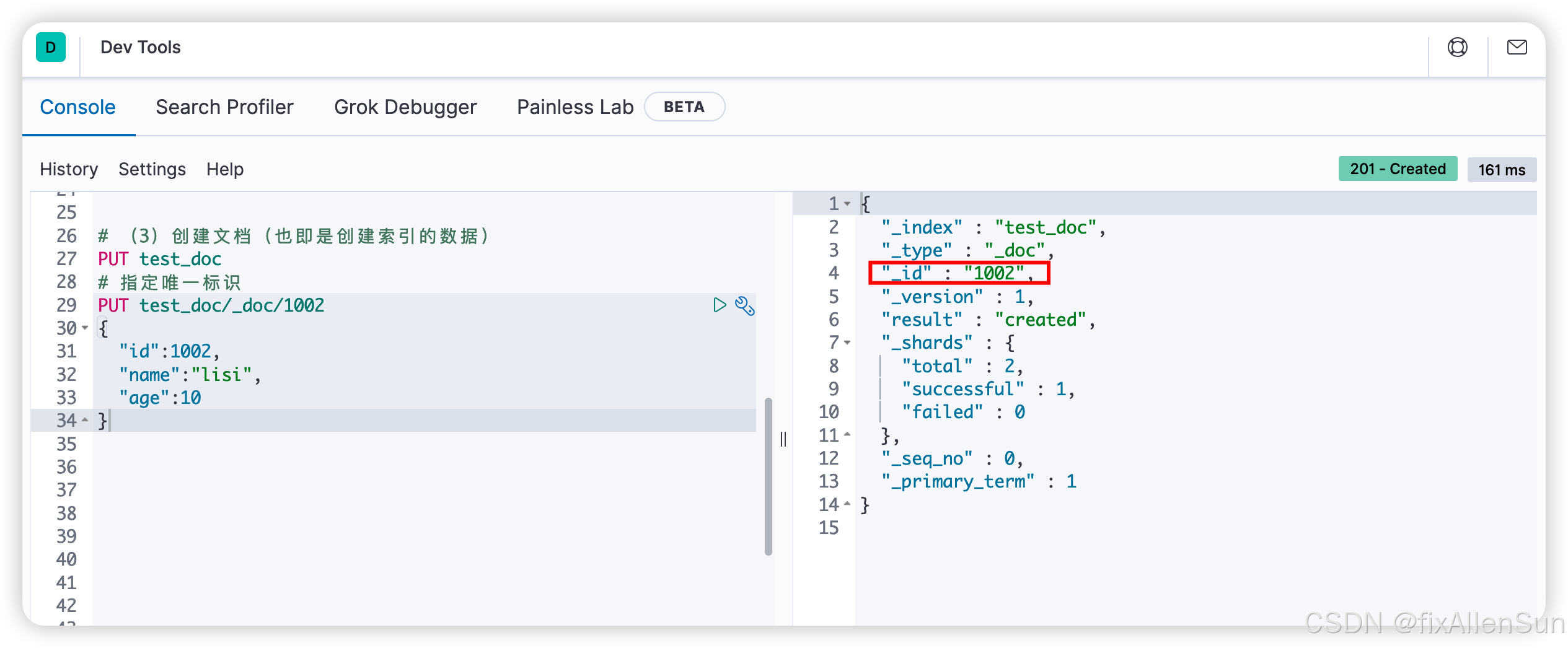
PUT test_doc/_doc/1002
{
"id":1002,
"name":"lisi",
"age":10
}
POST为创建文档,需要添加唯一性标识,类似数据的主键id,如果不手动指定,es会创建一个随机的唯一标识。_doc表示添加文档,添加的JSON内容就等于给索引添加了一条数据。
(6)查询文档
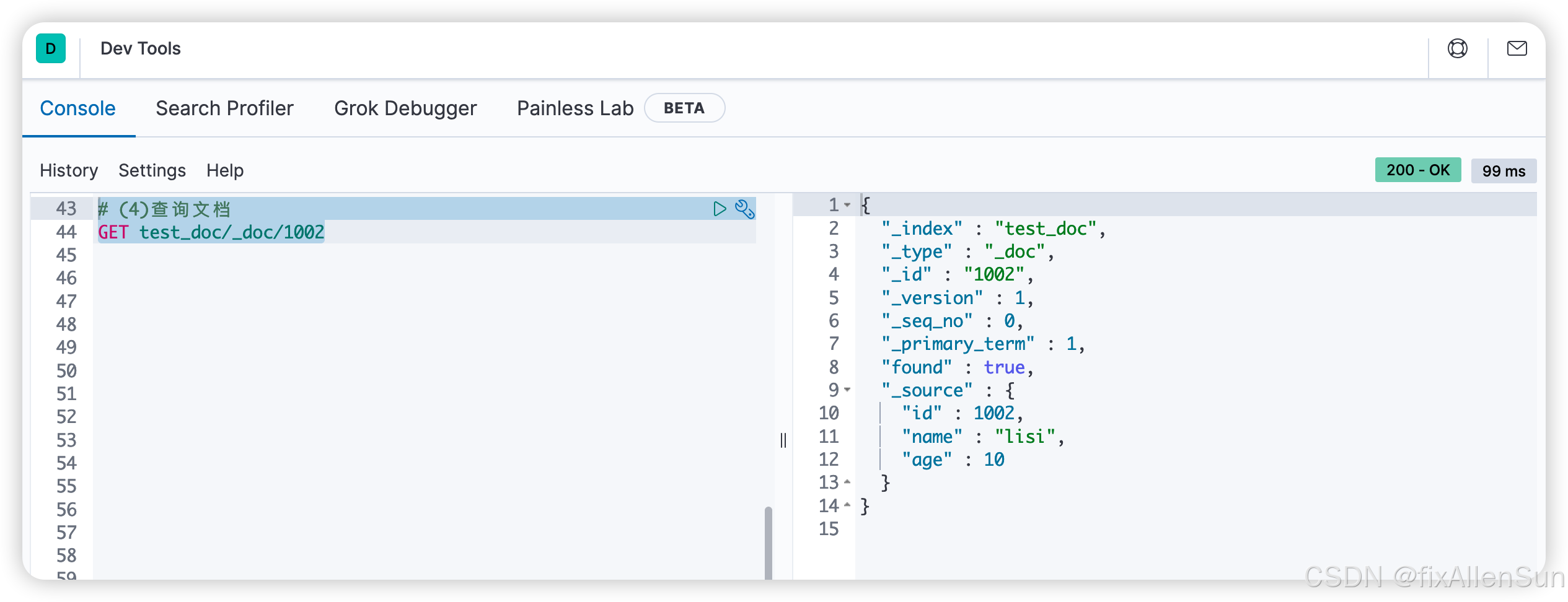
# (4)查询文档
GET test_doc/_doc/1002
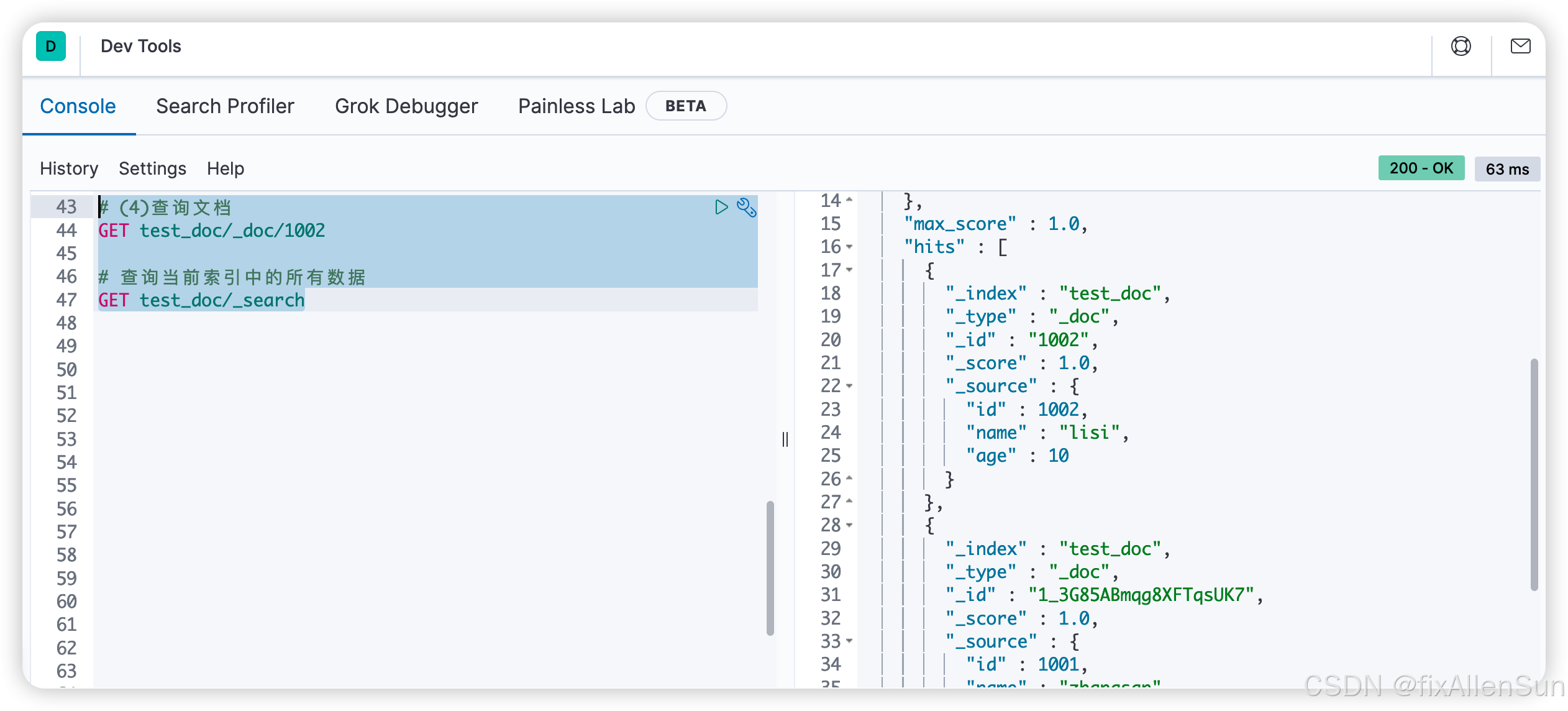
# 查询当前索引中的所有数据
GET test_doc/_search
(7)修改文档
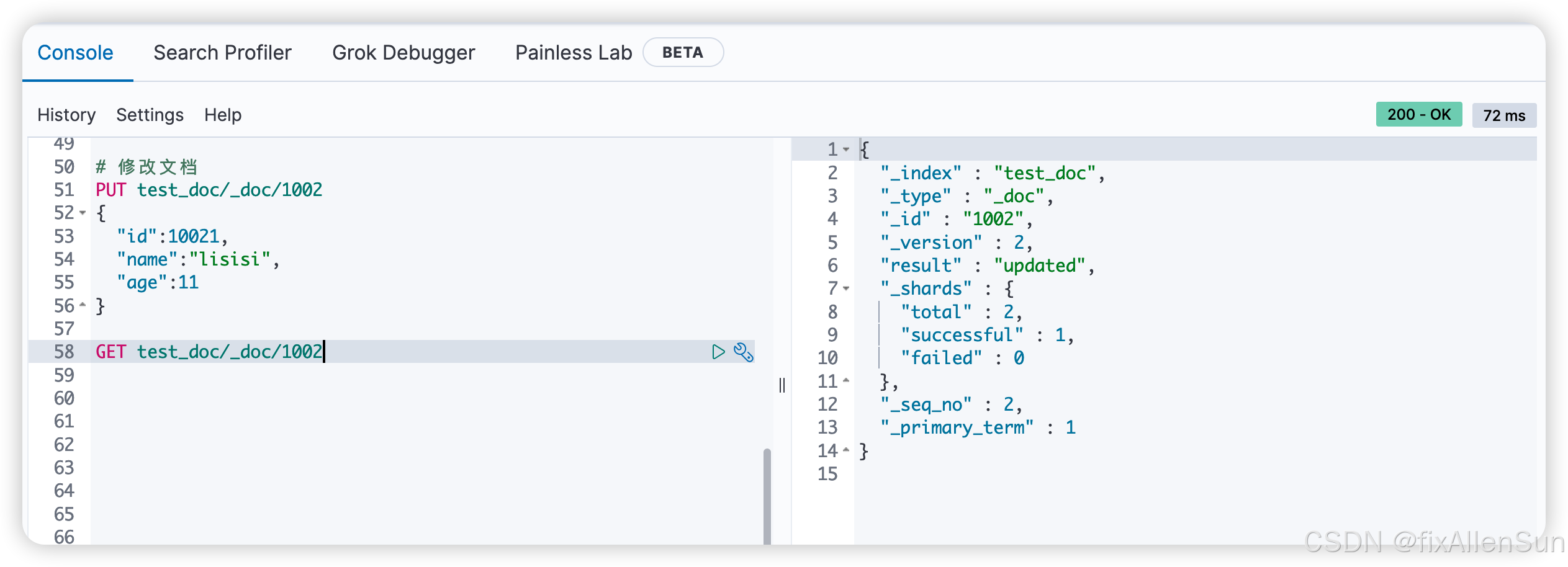
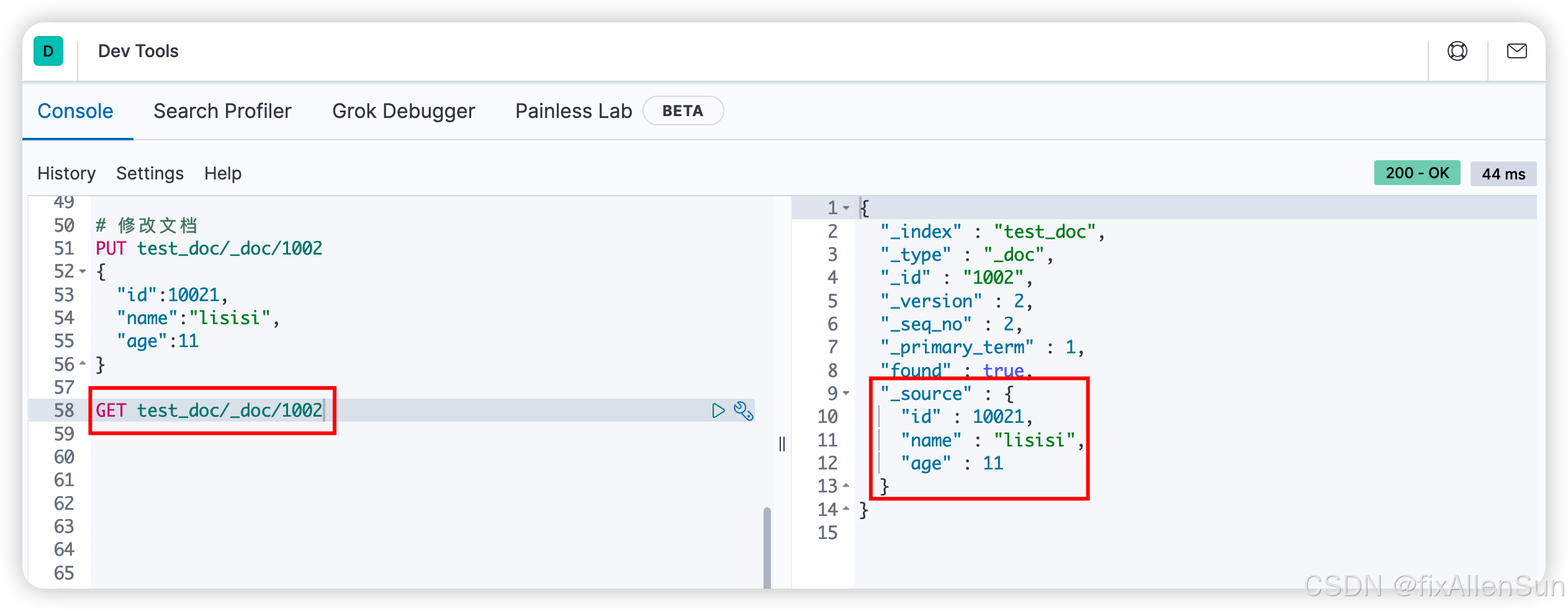
# 修改文档
PUT test_doc/_doc/1002
{
"id":10021,
"name":"lisisi",
"age":11
}
GET test_doc/_doc/1002
也可以是会用POST修改,但是都要指定清楚唯一标识
(8)删除文档
DELETE test_doc/_doc/1002
(9)数据搜索
(1)先创建索引
PUT test_query
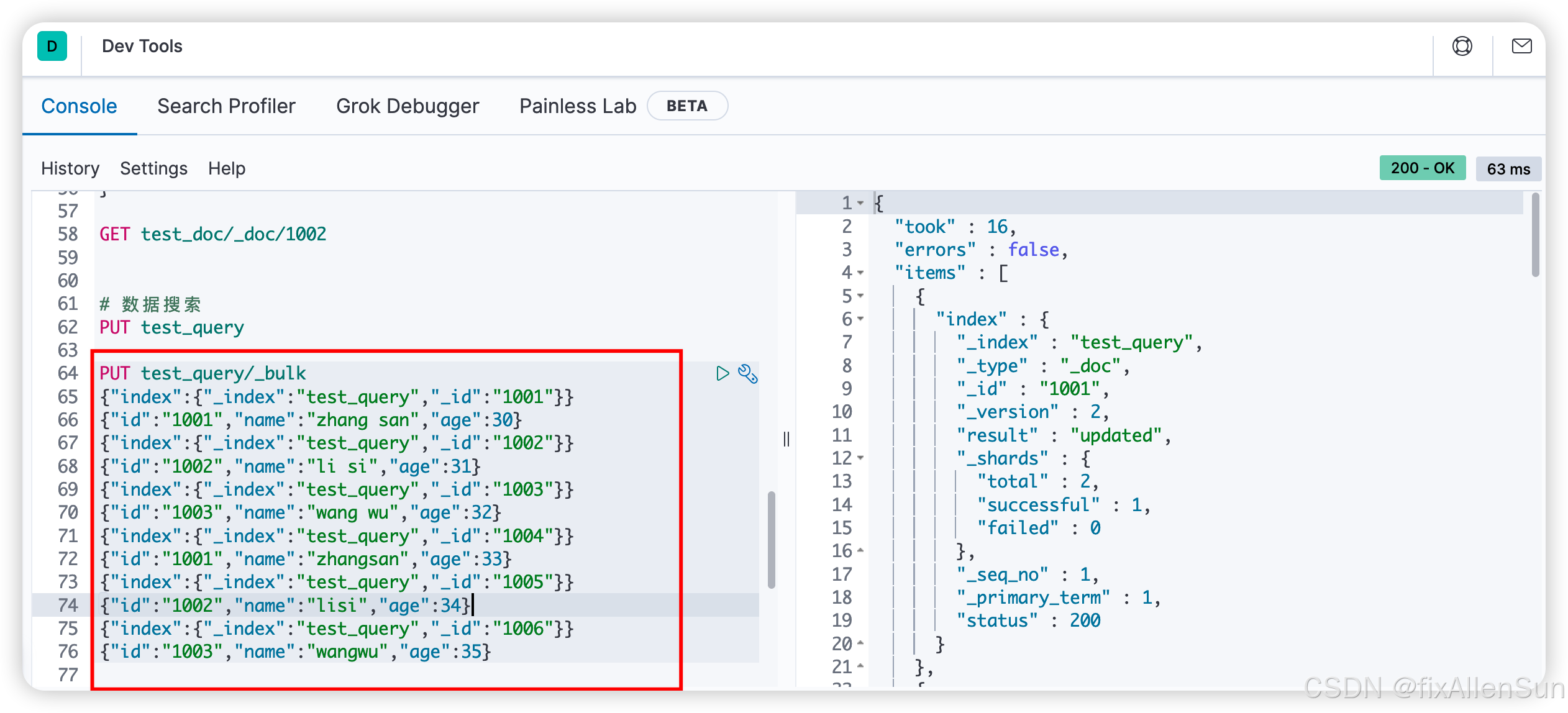
(2)再创建索引下的文档数据
PUT test_query/_bulk
{"index":{"_index":"test_query","_id":"1001"}}
{"id":"1001","name":"zhang san","age":30}
{"index":{"_index":"test_query","_id":"1002"}}
{"id":"1002","name":"li si","age":31}
{"index":{"_index":"test_query","_id":"1003"}}
{"id":"1003","name":"wang wu","age":32}
{"index":{"_index":"test_query","_id":"1004"}}
{"id":"1001","name":"zhangsan","age":33}
{"index":{"_index":"test_query","_id":"1005"}}
{"id":"1002","name":"lisi","age":34}
{"index":{"_index":"test_query","_id":"1006"}}
{"id":"1003","name":"wangwu","age":35}
(3)查询所有数据
# 查询所有
GET test_query/_search
(4)条件查询
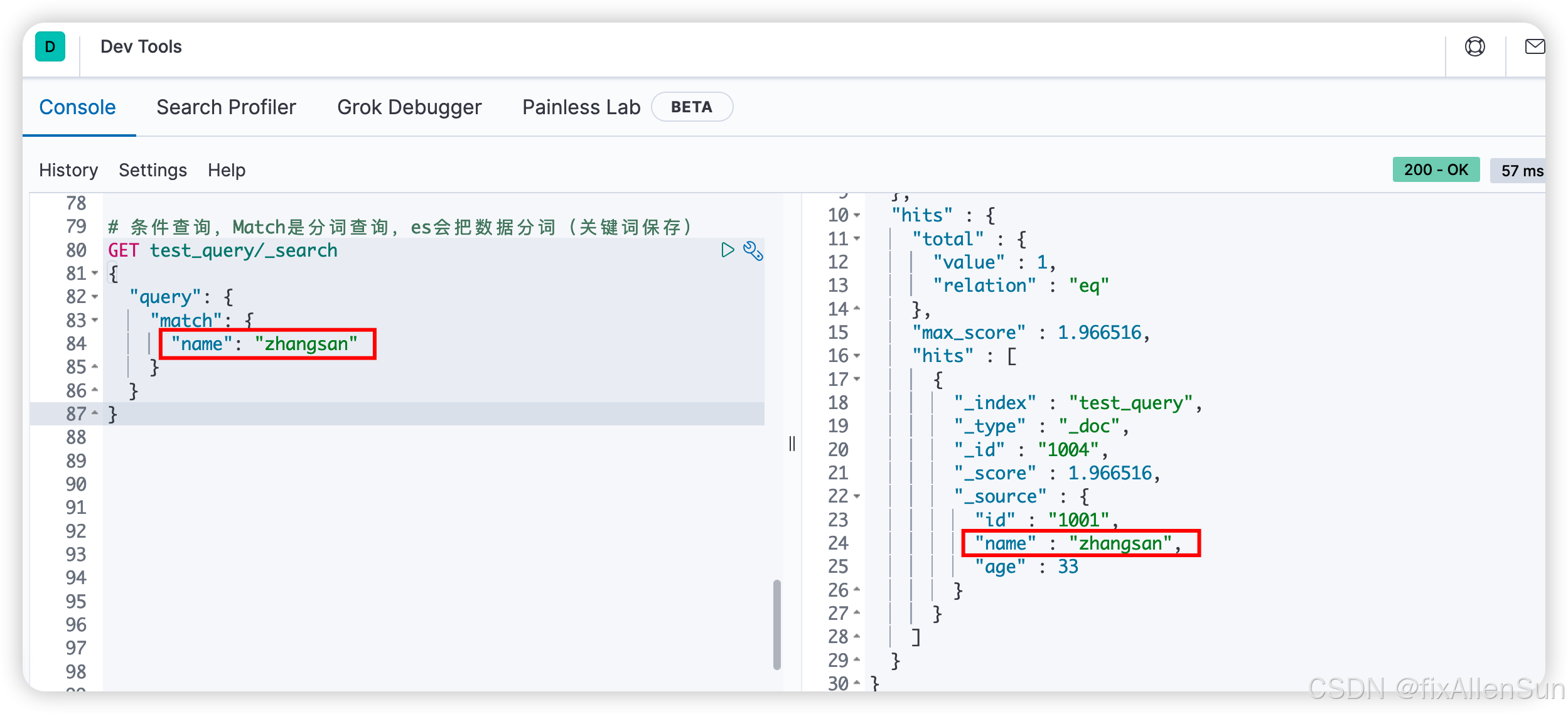
# 条件查询,Match是分词查询,es会把数据分词(关键词保存)
GET test_query/_search
{
"query": {
"match": {
"name": "zhangsan"
}
}
}
(5)根据分词来查询
# 条件查询,Match是分词查询,es会把数据分词(关键词保存)
GET test_query/_search
{
"query": {
"match": {
"name": "zhang li"
}
}
}
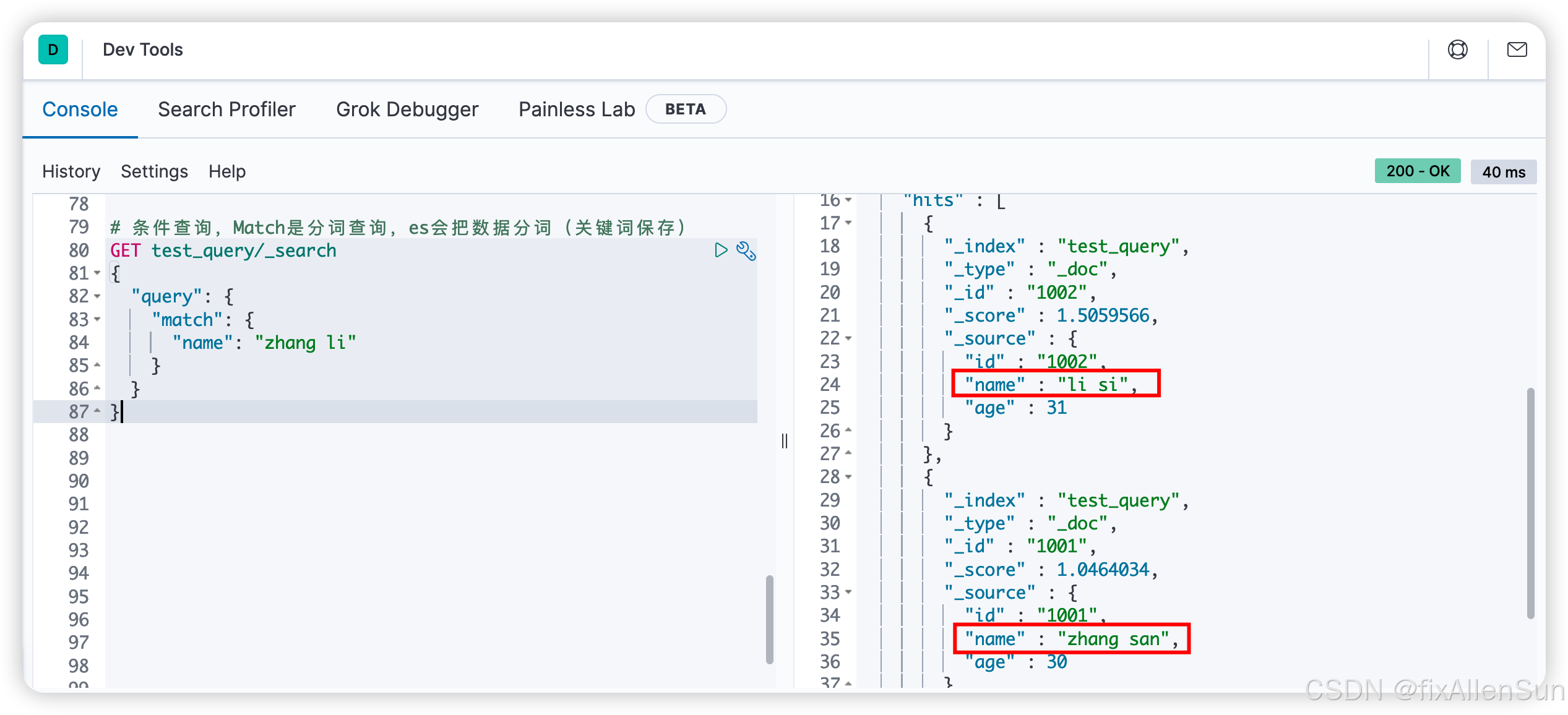
(6)对完整的关键词做匹配,不用分词
把match改成term,表示完整的匹配
GET test_query/_search
{
"query": {
"term": {
"name": "zhang san"
}
}
}
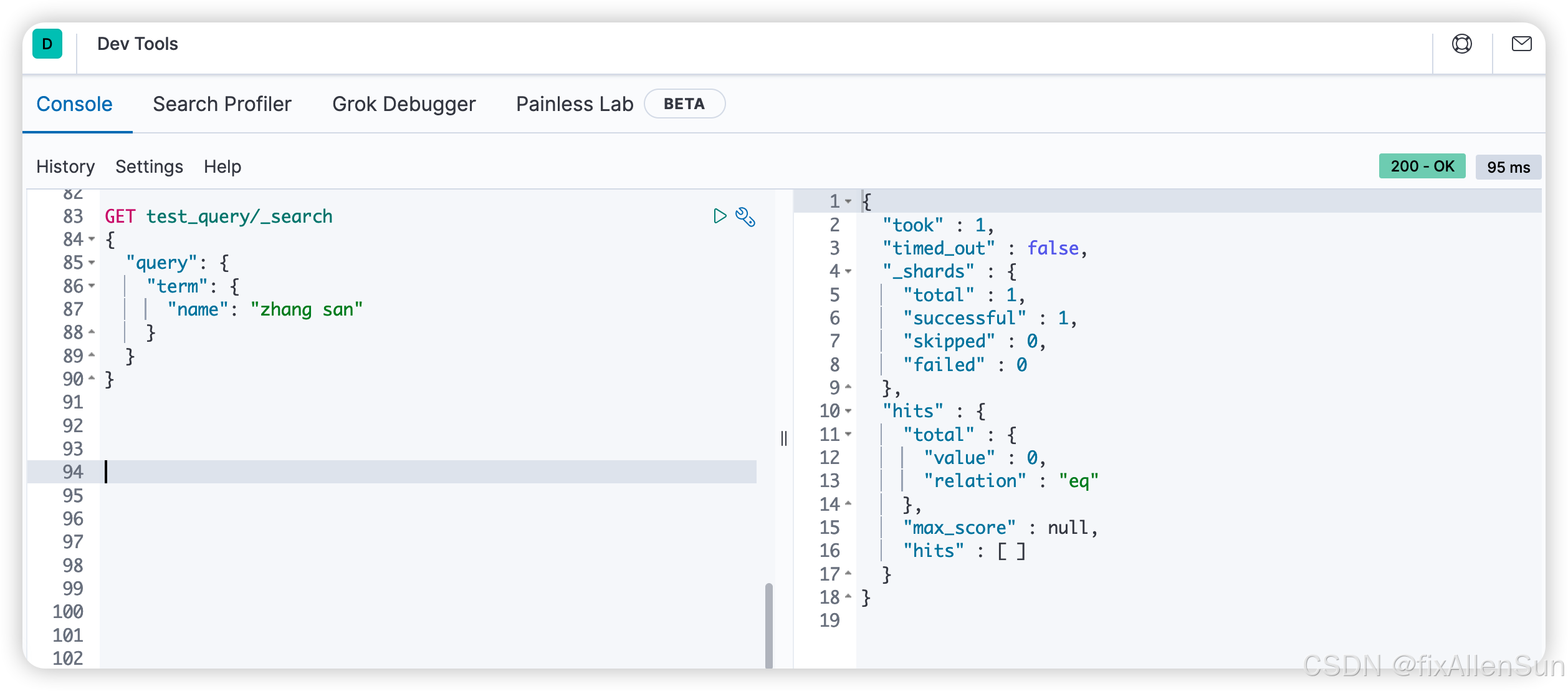
发现是查不到结果的,因为es在存数据的时候,会把zhang san拆分成zhang和san来分别存储,所有在完整匹配的时候是匹配不到的。换成zhangsan是可以查到的
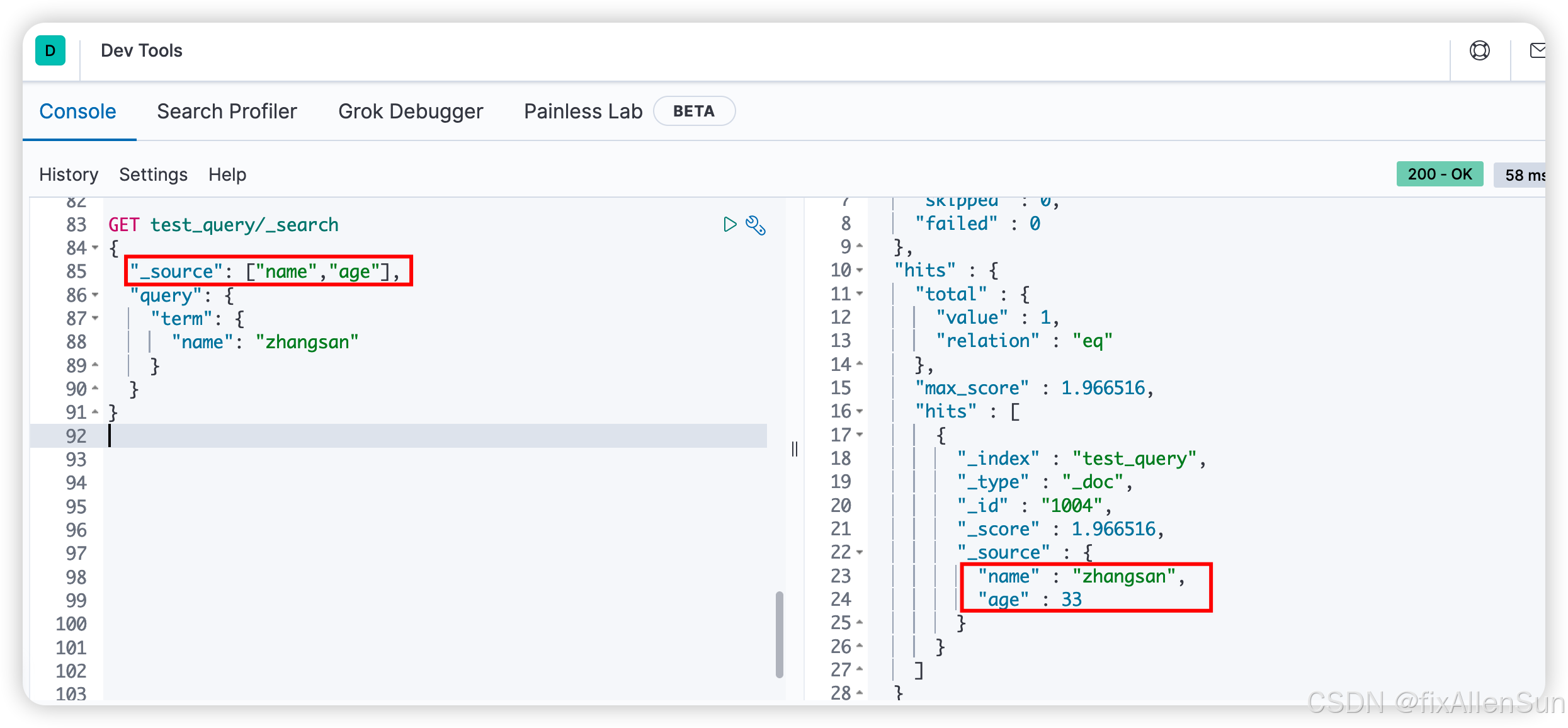
(7)限制查询的范围
例如我只查名字,或者只查年龄
GET test_query/_search
{
"_source": ["name","age"],
"query": {
"term": {
"name": "zhangsan"
}
}
}
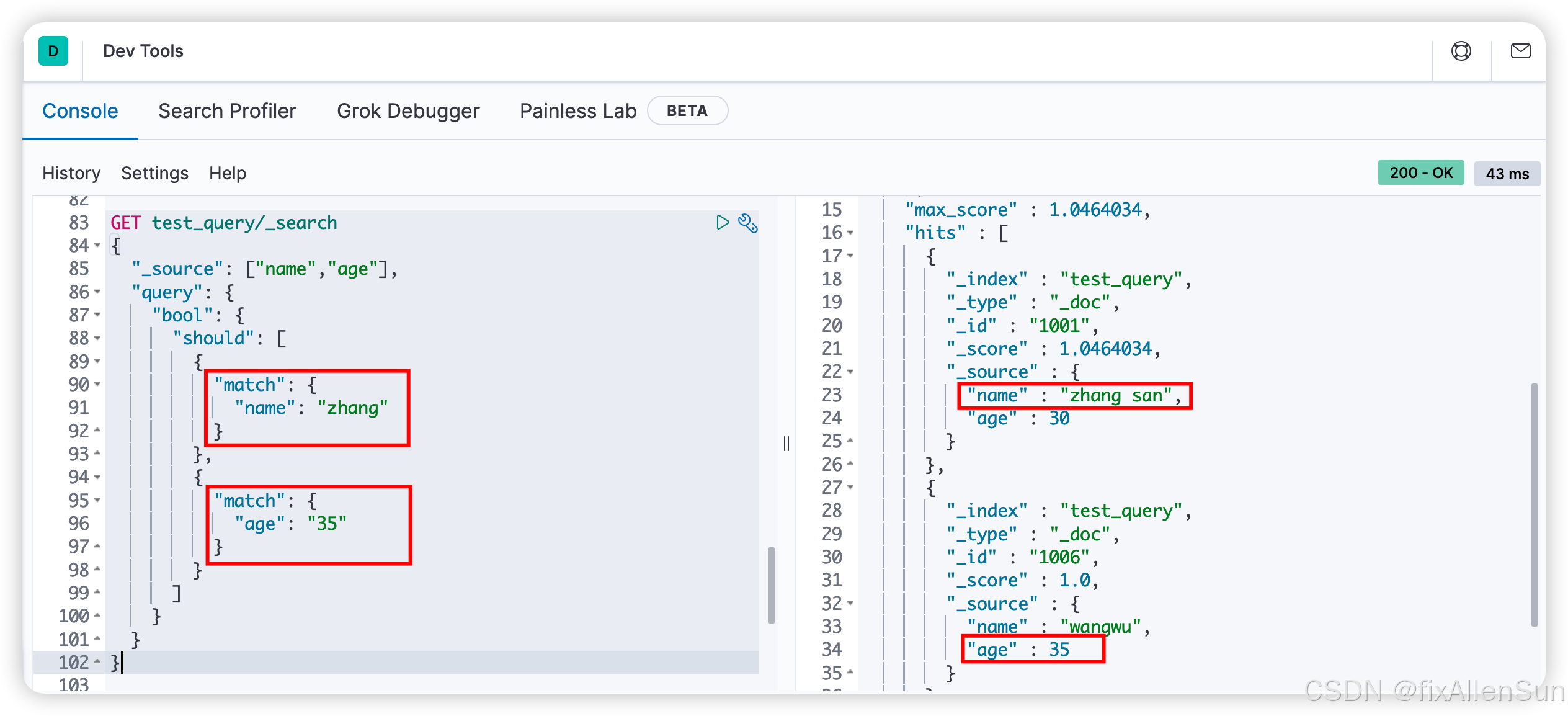
(8)组合多个条件
GET test_query/_search
{
"_source": ["name","age"],
"query": {
"bool": {
"should": [
{
"match": {
"name": "zhang"
}
},
{
"match": {
"age": "35"
}
}
]
}
}
}
(9)排序后查询
GET test_query/_search
{
"_source": ["name","age"],
"query": {
"match": {
"name": "zhang li"
}
},
"sort": [
{
"age": {
"order": "asc"
}
}
]
}
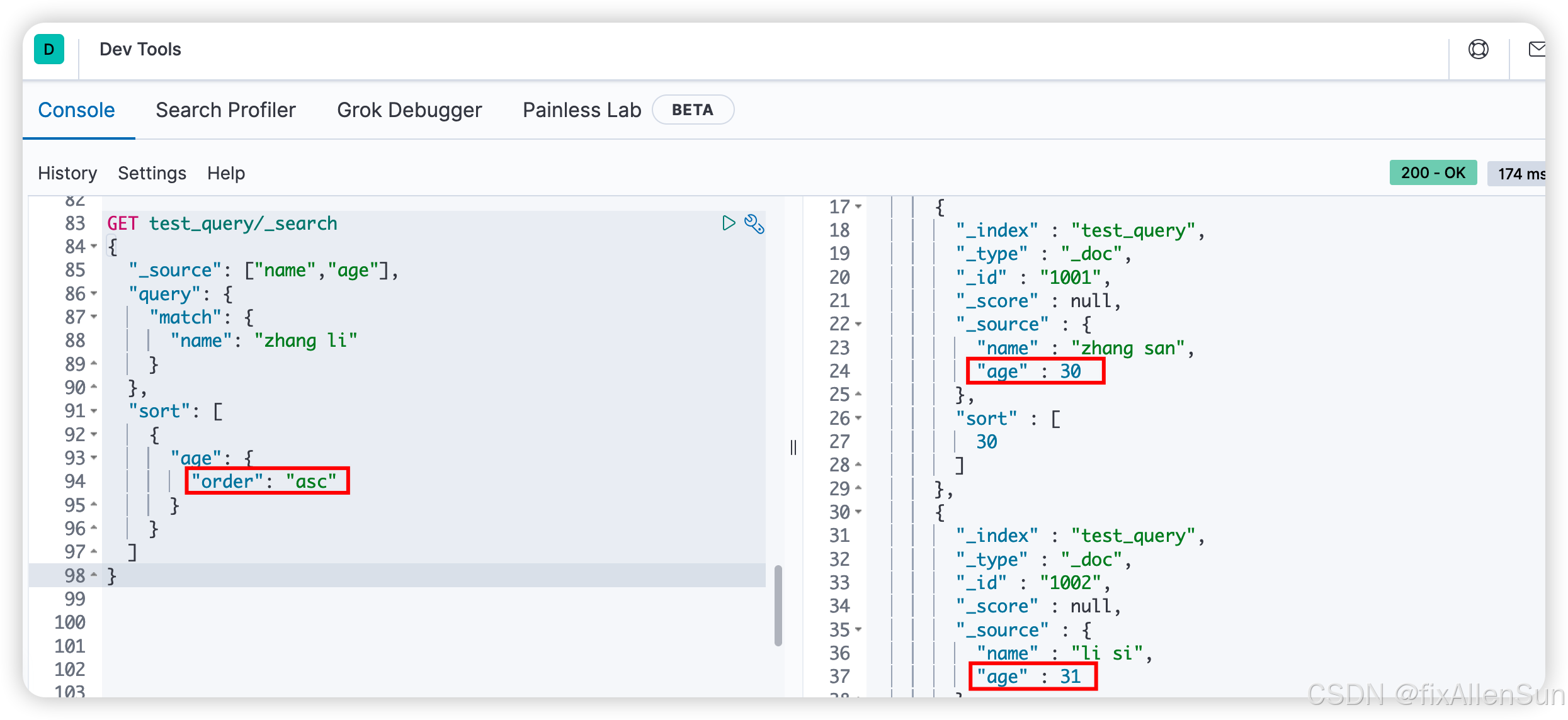
(10)分页查询
GET test_query/_search
{
"_source": ["name","age"],
"query": {
"match_all": {
}
},
"from": 2,
"size": 4
}
(10)聚合搜索
聚合允许使用者对es文档进行统计分析,类似于关系型数据库中的group by,当然还有很多其他的聚合,例如取最大值、平均值等等
(1)聚合搜索
GET test_query/_search
{
"aggs": {
"ageGroup": {
"terms": {
"field": "age"
}
}
}
}
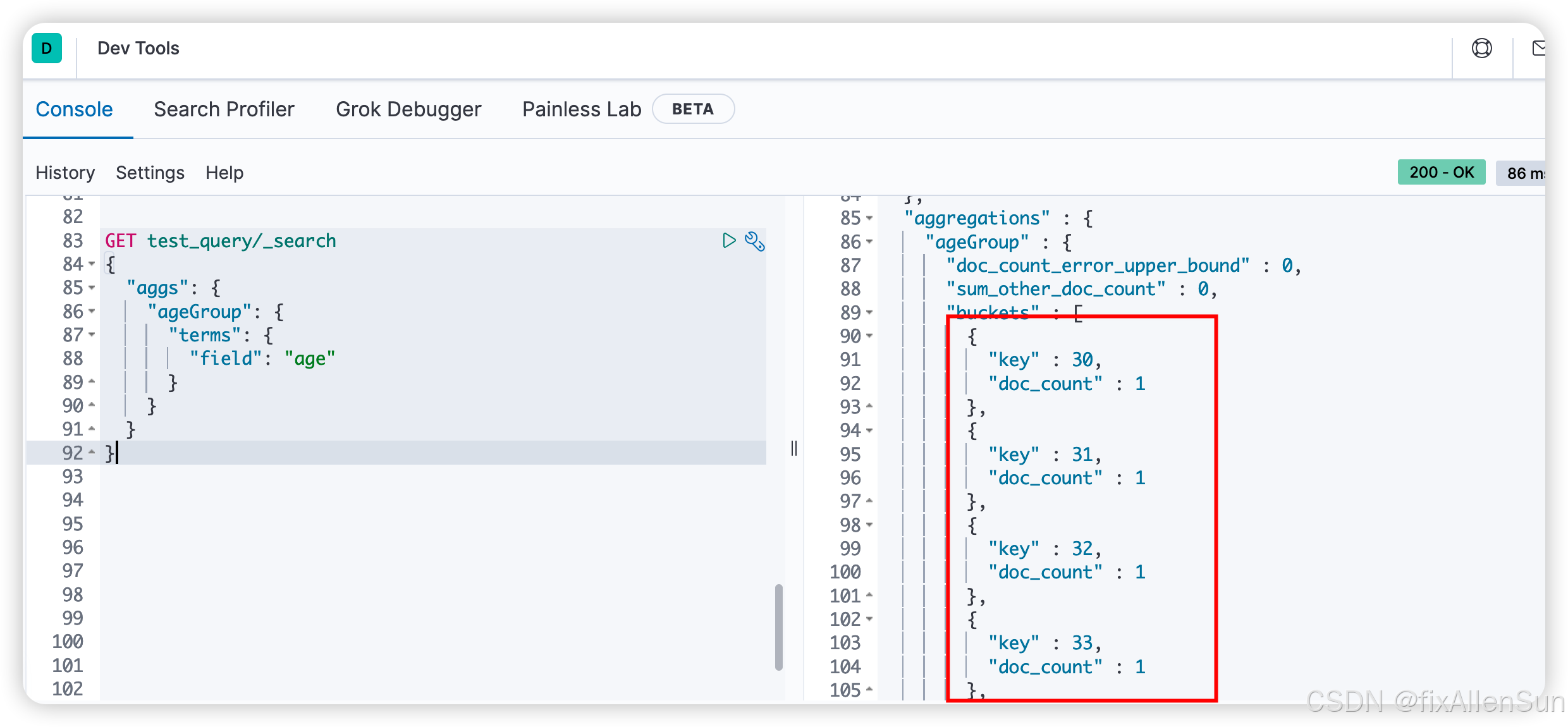
(2)只查聚合的结果
GET test_query/_search
{
"aggs": {
"ageGroup": {
"terms": {
"field": "age"
}
}
},
"size": 0
}
(3)分组之后的数据再聚合
GET test_query/_search
{
"aggs": {
"ageGroup": {
"terms": {
"field": "age"
},
"aggs": {
"ageSum": {
"sum": {
"field": "age"
}
}
}
}
},
"size": 0
}
(4)求平均值
GET test_query/_search
{
"aggs": {
"avgAge": {
"avg": {
"field": "age"
}
}
},
"size": 0
}
(5)取前几名,根据年龄拍完序后再查询
GET test_query/_search
{
"aggs": {
"top3": {
"top_hits": {
"sort": [
{
"age": {
"order": "desc"
}
}
],
"size": 3
}
}
},
"size": 0
}
【八】文档操作
【1】新增文档
语法
POST /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子属性1": "值3",
"子属性2": "值4"
},
// ...
}
示例
POST /heima/_doc/1
{
"info": "黑马程序员Java讲师",
"email": "zy@itcast.cn",
"name": {
"firstName": "云",
"lastName": "赵"
}
}
响应
【2】查询文档
根据rest风格,新增是post,查询应该是get,不过查询一般都需要条件,这里我们把文档id带上。
语法
GET /{索引库名称}/_doc/{id}
通过kibana查看数据:
GET /heima/_doc/1
查看结果:
【3】删除文档
删除使用DELETE请求,同样,需要根据id进行删除:
语法
DELETE /{索引库名}/_doc/id值
示例
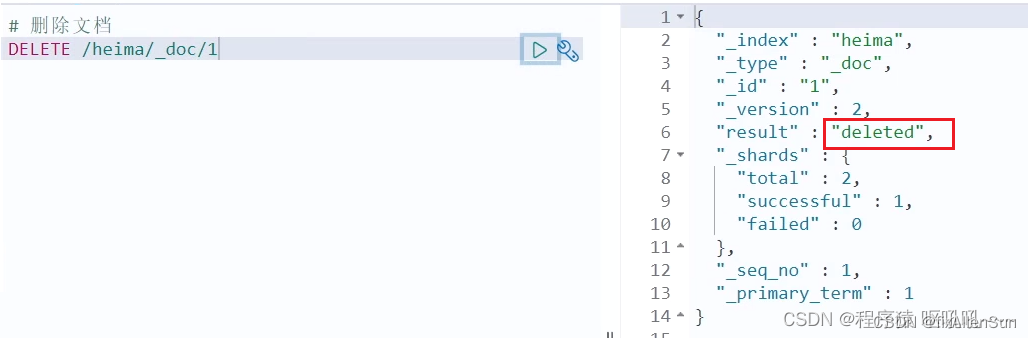
# 根据id删除数据
DELETE /heima/_doc/1
结果
【4】修改文档
修改有两种方式:
(1)全量修改:直接覆盖原来的文档
(2)增量修改:修改文档中的部分字段
(1)全量修改
全量修改是覆盖原来的文档,其本质是:
(1)根据指定的id删除文档
(2)新增一个相同id的文档
注意:如果根据id删除时,id不存在,第二步的新增也会执行,也就从修改变成了新增操作了。
语法:
PUT /{索引库名}/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
// ... 略
}
示例:
PUT /heima/_doc/1
{
"info": "黑马程序员高级Java讲师",
"email": "zy@itcast.cn",
"name": {
"firstName": "云",
"lastName": "赵"
}
}
(2)增量修改
增量修改是只修改指定id匹配的文档中的部分字段。
语法
POST /{索引库名}/_update/文档id
{
"doc": {
"字段名": "新的值",
}
}
示例
POST /heima/_update/1
{
"doc": {
"email": "ZhaoYun@itcast.cn"
}
}
【5】总结
文档操作有哪些?
(1)创建文档:POST /{索引库名}/_doc/文档id { json文档 }
(2)查询文档:GET /{索引库名}/_doc/文档id
(3)删除文档:DELETE /{索引库名}/_doc/文档id
(4)修改文档:
1-全量修改:PUT /{索引库名}/_doc/文档id { json文档 }
2-增量修改:POST /{索引库名}/_update/文档id { “doc”: {字段}}
【九】Sringboot整合RestHighLevelClient,测试增删改查
ES官方提供了各种不同语言的客户端,用来操作ES。这些客户端的本质就是组装DSL语句,通过http请求发送给ES。官方文档地址:https://www.elastic.co/guide/en/elasticsearch/client/index.html
其中的Java Rest Client又包括两种:
(1)Java Low Level Rest Client
(2)Java High Level Rest Client
 我们学习的是Java HighLevel Rest Client客户端API
我们学习的是Java HighLevel Rest Client客户端API
【1】数据准备
# 数据搜索
PUT test_query
PUT test_query/_bulk
{"index":{"_index":"test_query","_id":"1001"}}
{"id":"1001","name":"zhang san","age":30}
{"index":{"_index":"test_query","_id":"1002"}}
{"id":"1002","name":"li si","age":31}
{"index":{"_index":"test_query","_id":"1003"}}
{"id":"1003","name":"wang wu","age":32}
{"index":{"_index":"test_query","_id":"1004"}}
{"id":"1001","name":"zhangsan","age":33}
{"index":{"_index":"test_query","_id":"1005"}}
{"id":"1002","name":"lisi","age":34}
{"index":{"_index":"test_query","_id":"1006"}}
{"id":"1003","name":"wangwu","age":35}
【2】添加pom依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.5.12</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--elasticsearch-->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.7.0</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.9</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-test</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.5</version>
</dependency>
</dependencies>
【3】yaml配置
server:
port: 8083
spring:
elasticsearch:
rest:
uris: 192.168.19.13:9200
connection-timeout: 1s
read-timeout: 30s
# 配置日志级别,开启debug日志
logging:
level: debug
【4】添加实体类对象
@Data
@AllArgsConstructor
@NoArgsConstructor
@ToString
public class User {
private String name;
private String sex;
private Integer age;
}
【5】索引的增删查
(1)增加索引
public class ESTest_Index_Create {
public static void main(String[] args) throws IOException {
// 创建es客户端
RestHighLevelClient esclient = new RestHighLevelClient(
RestClient.builder(new HttpHost("192.168.19.13",9200, "http"))
);
CreateIndexRequest user = new CreateIndexRequest("user");
CreateIndexResponse createIndexResponse = esclient.indices().create(user, RequestOptions.DEFAULT);
// 响应状态
boolean acknowledged = createIndexResponse.isAcknowledged();
System.out.println("索引操作:"+acknowledged);
// 关闭es客户端
esclient.close();
}
}
(2)删除索引
public class ESTest_Index_Delete {
public static void main(String[] args) throws IOException {
// 创建es客户端
RestHighLevelClient esclient = new RestHighLevelClient(
RestClient.builder(new HttpHost("192.168.19.13",9200, "http"))
);
System.out.println("连接成功————————————————————");
DeleteIndexRequest user = new DeleteIndexRequest("user");
AcknowledgedResponse delete = esclient.indices().delete(user, RequestOptions.DEFAULT);
// 响应状态
System.out.println("执行成功————————————————————");
System.out.println("响应结果:"+delete.isAcknowledged());
// 关闭es客户端
esclient.close();
System.out.println("关闭成功————————————————————");
}
}
(3)查询索引
public class ESTest_Index_Search {
public static void main(String[] args) throws IOException {
// 创建es客户端
RestHighLevelClient esclient = new RestHighLevelClient(
RestClient.builder(new HttpHost("192.168.19.13",9200, "http"))
);
System.out.println("连接成功————————————————————");
GetIndexRequest user = new GetIndexRequest("user");
GetIndexResponse getIndexResponse = esclient.indices().get(user, RequestOptions.DEFAULT);
// 响应状态
System.out.println("执行成功————————————————————");
System.out.println(getIndexResponse.getAliases());
System.out.println(getIndexResponse.getIndices());
System.out.println(getIndexResponse.getMappings());
System.out.println(getIndexResponse.getSettings());
// 关闭es客户端
esclient.close();
System.out.println("关闭成功————————————————————");
}
}
【6】文档的增删改查
(1)增加文档
public class ESTest_Doc_Insert {
public static void main(String[] args) throws IOException {
// 创建es客户端
RestHighLevelClient esclient = new RestHighLevelClient(
RestClient.builder(new HttpHost("192.168.19.13",9200, "http"))
);
System.out.println("连接成功————————————————————");
// 插入数据
IndexRequest indexRequest = new IndexRequest();
indexRequest.index("user").id("1001");
User user = new User("zhangsan","男",22);
// 向es插入数据
String userJson = JSONUtil.toJsonStr(user);
indexRequest.source(userJson, XContentType.JSON);
IndexResponse indexResponse = esclient.index(indexRequest, RequestOptions.DEFAULT);
System.out.println("执行成功————————————————————");
System.out.println(indexResponse.getResult());
// 关闭es客户端
esclient.close();
System.out.println("关闭成功————————————————————");
}
}
(2)批量增加索引
public class ESTest_Doc_Insert_Batch {
public static void main(String[] args) throws IOException {
// 创建es客户端
RestHighLevelClient esclient = new RestHighLevelClient(
RestClient.builder(new HttpHost("192.168.19.13",9200, "http"))
);
System.out.println("连接成功————————————————————");
// 插入数据
BulkRequest indexRequest = new BulkRequest();
indexRequest.add(new IndexRequest().index("user").id("1001").source(XContentType.JSON,"name","zhangsan","age"
,20,"sex","男"));
indexRequest.add(new IndexRequest().index("user").id("1002").source(XContentType.JSON,"name","lisi","age"
,30,"sex","男"));
indexRequest.add(new IndexRequest().index("user").id("1003").source(XContentType.JSON,"name","wangwu","age"
,20,"sex","男"));
indexRequest.add(new IndexRequest().index("user").id("1004").source(XContentType.JSON,"name","wangwu1","age"
,30,"sex","女"));
indexRequest.add(new IndexRequest().index("user").id("1005").source(XContentType.JSON,"name","wangwu2","age"
,30,"sex","女"));
indexRequest.add(new IndexRequest().index("user").id("1006").source(XContentType.JSON,"name","wangwu3","age"
,20,"sex","女"));
BulkResponse bulk = esclient.bulk(indexRequest, RequestOptions.DEFAULT);
System.out.println("执行成功————————————————————");
System.out.println(bulk.getTook());
System.out.println(bulk.getItems());
// 关闭es客户端
esclient.close();
System.out.println("关闭成功————————————————————");
}
}
(3)删除文档
public class ESTest_Doc_Delete {
public static void main(String[] args) throws IOException {
// 创建es客户端
RestHighLevelClient esclient = new RestHighLevelClient(
RestClient.builder(new HttpHost("192.168.19.13",9200, "http"))
);
System.out.println("连接成功————————————————————");
// 查询数据
DeleteRequest indexRequest = new DeleteRequest();
indexRequest.index("user").id("1001");
DeleteResponse delete = esclient.delete(indexRequest, RequestOptions.DEFAULT);
System.out.println("执行成功————————————————————");
System.out.println(delete.toString());
// 关闭es客户端
esclient.close();
System.out.println("关闭成功————————————————————");
}
}
(4)批量删除文档
public class ESTest_Doc_Delete_Batch {
public static void main(String[] args) throws IOException {
// 创建es客户端
RestHighLevelClient esclient = new RestHighLevelClient(
RestClient.builder(new HttpHost("192.168.19.13",9200, "http"))
);
System.out.println("连接成功————————————————————");
// 插入数据
BulkRequest indexRequest = new BulkRequest();
indexRequest.add(new DeleteRequest().index("user").id("1001"));
indexRequest.add(new DeleteRequest().index("user").id("1002"));
indexRequest.add(new DeleteRequest().index("user").id("1003"));
indexRequest.add(new DeleteRequest().index("user").id("1004"));
indexRequest.add(new DeleteRequest().index("user").id("1005"));
indexRequest.add(new DeleteRequest().index("user").id("1006"));
BulkResponse bulk = esclient.bulk(indexRequest, RequestOptions.DEFAULT);
System.out.println("执行成功————————————————————");
System.out.println(bulk.getTook());
System.out.println(bulk.getItems());
// 关闭es客户端
esclient.close();
System.out.println("关闭成功————————————————————");
}
}
(5)更新文档
public class ESTest_Doc_Update {
public static void main(String[] args) throws IOException {
// 创建es客户端
RestHighLevelClient esclient = new RestHighLevelClient(
RestClient.builder(new HttpHost("192.168.19.13",9200, "http"))
);
System.out.println("连接成功————————————————————");
// 插入数据
UpdateRequest indexRequest = new UpdateRequest();
indexRequest.index("user").id("1001");
// 向es插入数据
indexRequest.doc(XContentType.JSON,"sex","女");
UpdateResponse update = esclient.update(indexRequest, RequestOptions.DEFAULT);
System.out.println("执行成功————————————————————");
System.out.println(update.getResult());
// 关闭es客户端
esclient.close();
System.out.println("关闭成功————————————————————");
}
}
(6)查询文档
public class ESTest_Doc_Get {
public static void main(String[] args) throws IOException {
// 创建es客户端
RestHighLevelClient esclient = new RestHighLevelClient(
RestClient.builder(new HttpHost("192.168.19.13",9200, "http"))
);
System.out.println("连接成功————————————————————");
// 查询数据
GetRequest indexRequest = new GetRequest();
indexRequest.index("user").id("1001");
GetResponse documentFields = esclient.get(indexRequest, RequestOptions.DEFAULT);
System.out.println("执行成功————————————————————");
System.out.println(documentFields.getSourceAsString());
// 关闭es客户端
esclient.close();
System.out.println("关闭成功————————————————————");
}
}
(7)查询文档
public class ESTest_Doc_Query {
public static void main(String[] args) throws IOException {
// 创建es客户端
RestHighLevelClient esclient = new RestHighLevelClient(
RestClient.builder(new HttpHost("192.168.19.13",9200, "http"))
);
System.out.println("连接成功————————————————————");
// 查询数据
SearchRequest indexRequest = new SearchRequest();
indexRequest.indices("user");
indexRequest.source(new SearchSourceBuilder().query(QueryBuilders.matchAllQuery()));
SearchResponse search = esclient.search(indexRequest, RequestOptions.DEFAULT);
SearchHits hits = search.getHits();
System.out.println("执行成功————————————————————");
System.out.println(hits.getTotalHits());
System.out.println(search.getTook());
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
}
// 关闭es客户端
esclient.close();
System.out.println("关闭成功————————————————————");
}
}
【十】Springboot整合RestHighLevelClient
【1】数据准备
# 1)创建索引
PUT /demo1_blog
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 1
}
},
"mappings": {
"dynamic": false,
"properties": {
"id": {
"type": "integer"
},
"author": {
"type": "keyword"
},
"influence": {
"type": "integer_range"
},
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"content": {
"type": "text",
"analyzer": "ik_smart"
},
"tag": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword":{
"type":"keyword"
}
}
},
"vote": {
"type": "integer"
},
"view": {
"type": "integer"
},
"createAt": {
"type": "date",
"format": "yyyy-MM-dd HH:mm"
}
}
}
}
# 2)导入数据
POST _bulk
{"index":{"_index":"demo1_blog","_id":"1"}}
{"id":1,"author":"方才兄","influence":{"gte":10,"lte":12},"title":"ElasticSearch系列01:如何系统学习ES","content":"最后附上小编的学习记录图,后续小编会持续输出ElasticSearch技术系列文章,欢迎关注,共同探讨学习。","tag":["ElasticSearch","入门学习"],"vote":10,"view":100,"createAt":"2020-04-24 10:56"}
{"index":{"_index":"demo1_blog","_id":"2"}}
{"id":2,"author":"方才兄","influence":{"gte":10,"lte":12},"title":"ElasticSearch系列05:倒排序索引与分词Analysis","content":"系统学习ES】一、 倒排索引是什么?倒排索引是 Elasticsearch 中非常重要的索引结构,是从文档单词到文档 ID 的映射过程","tag":["倒排序索引","分词Analysis"],"vote":9,"view":90,"createAt":"2020-05-17 10:56"}
{"index":{"_index":"demo1_blog","_id":"3"}}
{"id":3,"author":"学堂","influence":{"gte":5,"lte":8},"title":"ElasticSearch安装以及和SpringBoot的整合","content":"自己正好学习一下,ElasticSearch也是nosql中的一种","tag":["ElasticSearch安装","springBoot整合"],"vote":0,"view":61,"createAt":"2020-06-01 10:56"}
{"index":{"_index":"demo1_blog","_id":"4"}}
{"id":4,"author":"阿里云","influence":{"gte":20,"lte":35},"title":"使用ElasticSearch快速搭建检索系统","content":"一个好的搜索系统可以直接促进页面的访问量提升","tag":["ElasticSearch","检索系统"],"vote":30,"view":200,"createAt":"2020-02-24 10:56"}
{"index":{"_index":"demo1_blog","_id":"5"}}
{"id":5,"author":" 铭毅天下","influence":{"gte":15,"lte":20},"title":"Elasticsearch学习,请先看这一篇!","content":"Elasticsearch研究有一段时间了,现特将Elasticsearch相关核心知识、原理从初学者认知、学习的角度,从以下9个方面进行详细梳理。","tag":["ElasticSearch","核心知识"],"vote":30,"view":4200,"createAt":"2020-06-04 10:56"}
{"index":{"_index":"demo1_blog","_id":"6"}}
{"id":6,"author":" 方才兄","influence":{"gte":15,"lte":20},"title":"Elasticsearch系列13:彻底掌握相关度","content":"最后,如果你有更好的相关度控制方式,或者在es的学习过程中有疑问,欢迎加入es交流群,和大家一起系统学习ElasticSearch。","tag":["ES","相关度"],"vote":10,"view":170,"createAt":"2020-06-08 10:56"}
【2】添加pom依赖
<properties>
<revision>20200607.0900</revision>
<type>SNAPSHOT</type>
<java.version>1.8</java.version>
<es.version>7.7.0</es.version>
<swagger.version>2.8.0</swagger.version>
<fastjson.version>1.2.70</fastjson.version>
<commons-lang3.version>3.10</commons-lang3.version>
</properties>
<dependencies>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>${es.version}</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>${es.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.commons/commons-lang3 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>${commons-lang3.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${fastjson.version}</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>${swagger.version}</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>${swagger.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
【3】yaml配置
server:
port: 6700
# 关闭es健康检查
management:
health:
elasticsearch:
enabled: false
spring:
data:
elasticsearch:
nodes: 192.168.19.13:9200 # es地址
repositories:
enabled: true
# 开启es健康检查
# rest:
# uris: ["http://192.168.1.181:9200"]
【4】封装RestHighLevelClient
package com.fangcai.es.common.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.DisposableBean;
import org.springframework.beans.factory.FactoryBean;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Configuration;
import java.util.ArrayList;
import java.util.List;
@Configuration
public class EsConfig implements FactoryBean<RestHighLevelClient>, InitializingBean, DisposableBean {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
private final static String SCHEME = "http";
private RestHighLevelClient restHighLevelClient;
@Value ("${spring.data.elasticsearch.nodes}")
private String nodes;
/**
* 控制Bean的实例化过程
*
* @return
*/
@Override
public RestHighLevelClient getObject() {
return restHighLevelClient;
}
/**
* 获取接口返回的实例的class
*
* @return
*/
@Override
public Class<?> getObjectType() {
return RestHighLevelClient.class;
}
@Override
public void destroy() {
try {
if (null != restHighLevelClient) {
restHighLevelClient.close();
}
} catch (final Exception e) {
logger.error("Error closing ElasticSearch client: ", e);
}
}
@Override
public boolean isSingleton() {
return false;
}
@Override
public void afterPropertiesSet() {
restHighLevelClient = buildClient();
}
private RestHighLevelClient buildClient() {
try {
String[] hosts = nodes.split(",");
List<HttpHost> httpHosts = new ArrayList<>(hosts.length);
for (String node : hosts) {
HttpHost host = new HttpHost(
node.split(":")[0],
Integer.parseInt(node.split(":")[1]),
SCHEME);
httpHosts.add(host);
}
restHighLevelClient = new RestHighLevelClient(
RestClient.builder(httpHosts.toArray(new HttpHost[0]))
);
} catch (Exception e) {
logger.error(e.getMessage());
}
return restHighLevelClient;
}
}
【5】封装EsUtil
提供了查询、聚合、文档的CURD等公用接口
package com.fangcai.es.common.util;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.fangcai.es.common.exception.EsDemoException;
import com.fangcai.es.common.response.PageResponse;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.HttpStatus;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@Component
public class EsUtil {
private Logger logger = LoggerFactory.getLogger(this.getClass());
@Autowired
private RestHighLevelClient esClient;
private static int retryLimit = 3;
/**
* 搜索
*
* @param index
* @param searchSourceBuilder
* @param clazz 需要封装的obj
* @param pageNum
* @param pageSize
* @return PageResponse<T>
*/
public <T> PageResponse<T> search(String index, SearchSourceBuilder searchSourceBuilder, Class<T> clazz,
Integer pageNum, Integer pageSize){
SearchRequest searchRequest = new SearchRequest(index);
searchRequest.source(searchSourceBuilder);
logger.info("DSL语句为:{}",searchRequest.source().toString());
try {
SearchResponse response = esClient.search(searchRequest, RequestOptions.DEFAULT);
PageResponse<T> pageResponse = new PageResponse<>();
pageResponse.setPageNum(pageNum);
pageResponse.setPageSize(pageSize);
pageResponse.setTotal(response.getHits().getTotalHits().value);
List<T> dataList = new ArrayList<>();
SearchHits hits = response.getHits();
for(SearchHit hit : hits){
dataList.add(JSONObject.parseObject(hit.getSourceAsString(), clazz));
}
pageResponse.setData(dataList);
return pageResponse;
} catch (Exception e) {
logger.error(e.getMessage());
throw new EsDemoException(String.valueOf(HttpStatus.BAD_REQUEST),
"error to execute searching,because of " + e.getMessage());
}
}
/**
* 聚合
*
* @param index
* @param searchSourceBuilder
* @param aggName 聚合名
* @return Map<Integer, Long> key:aggName value: doc_count
*/
public Map<Integer, Long> aggSearch(String index, SearchSourceBuilder searchSourceBuilder, String aggName){
SearchRequest searchRequest = new SearchRequest(index);
searchRequest.source(searchSourceBuilder);
logger.info("DSL语句为:{}",searchRequest.source().toString());
try {
SearchResponse response = esClient.search(searchRequest, RequestOptions.DEFAULT);
Aggregations aggregations = response.getAggregations();
Terms terms = aggregations.get(aggName);
List<? extends Terms.Bucket> buckets = terms.getBuckets();
Map<Integer, Long> responseMap = new HashMap<>(buckets.size());
buckets.forEach(bucket-> {
responseMap.put(bucket.getKeyAsNumber().intValue(), bucket.getDocCount());
});
return responseMap;
} catch (Exception e) {
logger.error(e.getMessage());
throw new EsDemoException(String.valueOf(HttpStatus.BAD_REQUEST),
"error to execute aggregation searching,because of " + e.getMessage());
}
}
/**
* 新增或者更新文档
*
* 对于更新文档,建议可以直接使用新增文档的API,替代 UpdateRequest
* 避免因对应id的doc不存在而抛异常:document_missing_exception
* @param obj
* @param index
* @return
*/
public Boolean addOrUptDocToEs(Object obj, String index){
try {
IndexRequest indexRequest = new IndexRequest(index).id(getESId(obj))
.source(JSON.toJSONString(obj), XContentType.JSON);
int times = 0;
while (times < retryLimit) {
IndexResponse indexResponse = esClient.index(indexRequest, RequestOptions.DEFAULT);
if (indexResponse.status().equals(RestStatus.CREATED) || indexResponse.status().equals(RestStatus.OK)) {
return true;
} else {
logger.info(JSON.toJSONString(indexResponse));
times++;
}
}
return false;
} catch (Exception e) {
logger.error("Object = {}, index = {}, id = {} , exception = {}", obj, index, getESId(obj) , e.getMessage());
throw new EsDemoException(String.valueOf(HttpStatus.BAD_REQUEST),
"error to execute add doc,because of " + e.getMessage());
}
}
/**
* 删除文档
*
* @param index
* @param id
* @return
*/
public Boolean deleteDocToEs(Integer id, String index) {
try {
DeleteRequest request = new DeleteRequest(index, id.toString());
int times = 0;
while (times < retryLimit) {
DeleteResponse delete = esClient.delete(request, RequestOptions.DEFAULT);
if (delete.status().equals(RestStatus.OK)) {
return true;
} else {
logger.info(JSON.toJSONString(delete));
times++;
}
}
return false;
} catch (Exception e) {
logger.error("index = {}, id = {} , exception = {}", index, id , e.getMessage());
throw new EsDemoException(String.valueOf(HttpStatus.BAD_REQUEST),
"error to execute update doc,because of " + e.getMessage());
}
}
/**
* 批量插入 或者 更新
*
* @param array 数据集合
* @param index
* @return
*/
public Boolean batchAddOrUptToEs(JSONArray array, String index) {
try {
BulkRequest request = new BulkRequest();
for (Object obj : array) {
IndexRequest indexRequest = new IndexRequest(index).id(getESId(obj))
.source(JSON.toJSONString(obj), XContentType.JSON);
request.add(indexRequest);
}
BulkResponse bulk = esClient.bulk(request, RequestOptions.DEFAULT);
return bulk.status().equals(RestStatus.OK);
} catch (Exception e) {
logger.error("index = {}, exception = {}", index, e.getMessage());
throw new EsDemoException(String.valueOf(HttpStatus.BAD_REQUEST),
"error to execute batch add doc,because of " + e.getMessage());
}
}
/**
* 批量删除
* @param deleteIds 待删除的 _id list
* @param index
* @return
*/
public Boolean batchDeleteToEs(List<Integer> deleteIds, String index){
try {
BulkRequest request = new BulkRequest();
for (Integer deleteId : deleteIds) {
DeleteRequest deleteRequest = new DeleteRequest(index, deleteId.toString());
request.add(deleteRequest);
}
BulkResponse bulk = esClient.bulk(request, RequestOptions.DEFAULT);
return bulk.status().equals(RestStatus.OK);
} catch (Exception e) {
logger.error("index = {}, exception = {}", index, e.getMessage());
throw new EsDemoException(String.valueOf(HttpStatus.BAD_REQUEST),
"error to execute batch update doc,because of " + e.getMessage());
}
}
/**
* 将obj的id 作为 doc的_id
* @param obj
* @return
*/
private String getESId(Object obj) {
JSONObject jsonObject = JSON.parseObject(JSON.toJSONString(obj));
Object id = jsonObject.get("id");
return JSON.toJSONString(id);
}
}
【6】枚举
public enum EsIndexEnum {
BLOG("demo1_blog");
private String indexName;
EsIndexEnum (String indexName) {
this.indexName = indexName;
}
public String getIndexName () {
return indexName;
}
}
【7】业务代码
@RestController
@RequestMapping ("es/test")
public class EsTestController{
@Autowired
private EsUtil esUtil;
/**
* 根据 title 、content 、tag 进行简单检索,使用rescore利用match_phrase重新算分排序;
*
* @param pageNum
* @param pageSize
* @return
*/
@GetMapping("case1")
public PageResponse<Blog> case1 (@RequestParam(defaultValue = "1") Integer pageNum,
@RequestParam(defaultValue = "10") Integer pageSize) {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 根据 title 、content 、tag 进行 match query
MultiMatchQueryBuilder multiMatchQuery = QueryBuilders.multiMatchQuery("系统学习ElasticSearch",
"title","content","tag");
searchSourceBuilder.query(multiMatchQuery);
// 使用 reScore 利用 match_phrase 重新算分排
MultiMatchQueryBuilder reScoreQuery = QueryBuilders.multiMatchQuery("系统学习ElasticSearch",
"title","content","tag")
.type(MultiMatchQueryBuilder.Type.PHRASE);
QueryRescorerBuilder queryRescorerBuilder = new QueryRescorerBuilder(reScoreQuery);
searchSourceBuilder.addRescorer(queryRescorerBuilder);
// 分页
int from = pageSize * (pageNum - 1);
searchSourceBuilder.size(pageSize).from(from);
return esUtil.search(EsIndexEnum.BLOG.getIndexName(), searchSourceBuilder,
Blog.class, pageNum, pageSize);
}
/**
* 提升 tag 的权重为3,title的权重为2,使用默认排序
*
* @param pageNum
* @param pageSize
* @return
*/
@GetMapping("case2")
public PageResponse<Blog> case2 (@RequestParam(defaultValue = "1") Integer pageNum,
@RequestParam(defaultValue = "10") Integer pageSize) {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 提升 tag 的权重为3,title的权重为2,使用默认排序
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.should(QueryBuilders.matchQuery("tag", "系统学习ElasticSearch").boost(3))
.should(QueryBuilders.matchQuery("title", "系统学习ElasticSearch").boost(2))
.should(QueryBuilders.matchQuery("content", "系统学习ElasticSearch"));
searchSourceBuilder.query(boolQuery);
// 分页
int from = pageSize * (pageNum - 1);
searchSourceBuilder.size(pageSize).from(from);
return esUtil.search(EsIndexEnum.BLOG.getIndexName(), searchSourceBuilder,
Blog.class, pageNum, pageSize);
}
/**
* 在case2的基础上增加过滤条件:author、tag、createAt、influence
*
* @param pageNum
* @param pageSize
* @return
*/
@GetMapping("case3")
public PageResponse<Blog> case3 (@RequestParam(defaultValue = "1") Integer pageNum,
@RequestParam(defaultValue = "10") Integer pageSize) {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 提升 tag 的权重为3,title的权重为2,使用默认排序
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.should(QueryBuilders.matchQuery("tag", "系统学习ElasticSearch").boost(3))
.should(QueryBuilders.matchQuery("title", "系统学习ElasticSearch").boost(2))
.should(QueryBuilders.matchQuery("content", "系统学习ElasticSearch"));
// 过滤
boolQuery.filter(QueryBuilders.termQuery("author", "方才兄"));
boolQuery.filter(QueryBuilders.termsQuery("tag.keyword", "ElasticSearch", "倒排序索引"));
boolQuery.filter(QueryBuilders.rangeQuery("createAt").gte("now-3M/d").lte("now/d"));
boolQuery.filter(QueryBuilders.rangeQuery("influence").gte(5).lte(15));
searchSourceBuilder.query(boolQuery);
// 分页
int from = pageSize * (pageNum - 1);
searchSourceBuilder.size(pageSize).from(from);
return esUtil.search(EsIndexEnum.BLOG.getIndexName(), searchSourceBuilder,
Blog.class, pageNum, pageSize);
}
/**
* 在3的基础上用户指定排序条件:createAt、vote、view
*
* @param pageNum
* @param pageSize
* @return
*/
@GetMapping("case4")
public PageResponse<Blog> case4 (@RequestParam(defaultValue = "1") Integer pageNum,
@RequestParam(defaultValue = "10") Integer pageSize) {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 通过 filterContext 查询,忽略评分,增加缓存的可能性,提高查询性能
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
MultiMatchQueryBuilder multiMatchQuery = QueryBuilders.multiMatchQuery("系统学习ElasticSearch",
"title","content","tag");
boolQuery.filter(multiMatchQuery);
// 过滤
boolQuery.filter(QueryBuilders.termQuery("author", "方才兄"));
boolQuery.filter(QueryBuilders.termsQuery("tag.keyword", "ElasticSearch", "倒排序索引"));
boolQuery.filter(QueryBuilders.rangeQuery("createAt").gte("now-3M/d").lte("now/d"));
boolQuery.filter(QueryBuilders.rangeQuery("influence").gte(5).lte(15));
searchSourceBuilder.query(boolQuery);
searchSourceBuilder.sort("view", SortOrder.DESC);
// 分页
int from = pageSize * (pageNum - 1);
searchSourceBuilder.size(pageSize).from(from);
return esUtil.search(EsIndexEnum.BLOG.getIndexName(), searchSourceBuilder,
Blog.class, pageNum, pageSize);
}
}

















 270
270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









