







创建Hadoop平台
下载镜像
安装虚拟机
使用VMwareWorkstation
打开虚拟机进入软件,配置网络


解压jdk
1.sudo apt update
2.sudo apt upgrade
3.sudo apt autoremove
4.ftp 10.13.32.2
- name : ftpuser
- password:123456
- ls
- get jdk-15.0.2_linux-x64_bin.tar.gz
- 退出(bye)
- 创建新文件夹 sudo mkdir usr/lib/jvm
- 解压jdk
sudo tar -zxvf jdk-15.0.2_linux-x64_bin.tar.gz -C /usr/lib/jvm - 下载vim
sudo apt install vim - 进入cd目录,编辑.bashrc文件
vim .bashrc
加入两行代码
export JAVA_HOME=/usr/lib/jvm/jdk-15.0.2
export PATH=${JAVA_HOME}/bin:$PATH
:wq保存
source .bashrc
11.查看解压成功
java -version
解压Hadoop
- 进入ftp获得hadoop压缩包
ftp 10.13.32.2
username:ftpuser
password:123456
get hadoop-3.2.2.tar.gz - 解压 sudo tar -zxvf hadoop-3.2.2.tar.gz -C /usr/local
- 授权用户(建虚拟机时自己命名的用户)
chown R h123 usr/local/hadoop-3.2.2 - 查看hadoop中的内容
ls /usr/local/hadoop-3.2.2/etc/hadoop
免密登录SSH
-
sudo apt install ssh
-
ssh localhost
-
ssh-keygen
-
ls .ssh

-
cat .ssh/id_rsa.pub >>.ssh/authorized_keys
进行配置
- vim /usr/local/hadoop-3.2.2/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/jdk-15.0.2
- vim /usr/local/hadoop-3.2.2/etc/hadoop/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-3.2.2/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
- vim /usr/local/hadoop-3.2.2/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-3.2.2/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-3.2.2/hadoop_data/hdfs/datanode</value>
</property>
</configuration>
- 编译vim /usr/local/hadoop-3.2.2/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
- vim /usr/local/hadoop-3.2.2/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,
HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,
HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
- vim .bashrc(hadoop的环境配置)
export HADOOP_HOME=/usr/local/hadoop-3.2.2
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- source .bashrc
- 格式化 hadf namenode -format(命令执行完,会出来successfuly,若没有则以上的配置文件有问题)
- 开启dfs
start-dfs.sh(关闭服务对应的是stop-dfs.sh) - 输入jsp会开启三个节点

如果dataNode节点没有出来,可能是格式化多次
执行rm -r hadoop date,然后再格式化一遍。 - 开启yarm start-yarn.sh
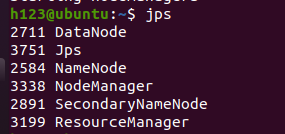
- 这就成功搭建hadoop平台了,开始跑个程序
cd 目录下
输入 hadoop jar /usr/local/hadoop-3.2.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar pi 5 10
如果出现Job failed,则按以下步骤
在命令行输入:hadoop classpath
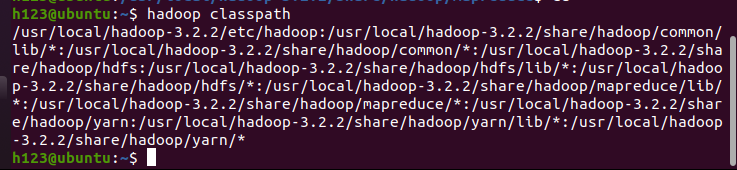 把上述输出的值添加到yarn-site.xml文件对应的属性 yarn.application.classpath下面,然后进入配置文件vim /usr/local/hadoop-3.2.2/etc/hadoop/yarn-site.xml
把上述输出的值添加到yarn-site.xml文件对应的属性 yarn.application.classpath下面,然后进入配置文件vim /usr/local/hadoop-3.2.2/etc/hadoop/yarn-site.xml<property> <name>yarn.application.classpath</name> <value>/opt/module/hadoop/etc/hadoop:/opt/module/hadoop/share/hadoop/common/lib/*:/opt/module/hadoop/share/hadoop/common/*:/opt/module/hadoop/share/hadoop/hdfs:/opt/module/hadoop/share/hadoop/hdfs/lib/*:/opt/module/hadoop/share/hadoop/hdfs/*:/opt/module/hadoop/share/hadoop/mapreduce/lib/*:/opt/module/hadoop/share/hadoop/mapreduce/*:/opt/module/hadoop/share/hadoop/yarn:/opt/module/hadoop/share/hadoop/yarn/lib/*:/opt/module/hadoop/share/hadoop/yarn/*</value>
重启服务就成功了















 7297
7297











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









