







假设您拥有一台强大的计算机系统或一个应用,用于快速执行各种任务。但是,系统中有一个组件的速度跟不上其他部分,这个性能不佳的组件拉低了系统的整体性能,成为了整个系统的瓶颈。在软件领域中,瓶颈是指整个路径中吞吐量最低的部分。如果机器中的某个齿轮转得不够快,整个系统的速度都会受到影响。因此,及时识别和解决瓶颈问题的重要性不言而喻,能显著提升计算机系统和应用的效率。
在此前的文章中,我们已经介绍了评估各种向量数据库时使用的关键指标和性能测试工具。本文将以 Milvus 向量数据库为例,特别关注 Milvus 2.2 或以上版本,讲解如何监控搜索性能、识别瓶颈并优化向量数据库性能。
性能评估及监控指标
在向量数据库系统中,最常用且最重要的评估指标包括召回率(Recall)、延迟(Latency)和每秒查询数(QPS)。这些指标反映了系统的准确性、响应速度以及能够处理的请求量。
Recall
召回率是指在搜索查询中成功检索到的相关内容的比例。但是,通常并不是所有接近的向量都能被准确识别。这一不足往往源于索引算法的近似性(除了暴搜以外)。这些算法牺牲召回率以换取速度的提升。这些索引算法的配置旨在为特定生产需求寻找一个合适的平衡。更多详细信息,请参阅milvus的文档页面:内存索引和磁盘索引。
计算召回率可能会消耗大量资源,通常由客户端完成。由于确立 Ground truth 需要大量计算,因此通常不会显示在监控仪表板上。在接下来的指南中,我们假定已经达到了一个可接受的召回率水平,且已经为向量索引选定了适当的索引参数。
Latency
延迟指的是响应速度——即从发起查询到接收到结果所需的时间,就好比水从一端流到另一端所需要的时间。较低的延迟可以确保更快的响应速度,这对于实时应用来说非常关键。
QPS
QPS 是衡量系统吞吐量的一个重要指标,它显示了系统每秒能处理的查询数量,类似于水流通过管道的流速。更高的 QPS 值意味着系统能够更有效地处理大量并发请求,这是衡量系统性能的关键因素。
QPS 和延迟之间的关系通常较为复杂。在传统数据库系统中,当 QPS 接近系统的最大容量并耗尽所有资源时,延迟往往会增加。但在 Milvus 中,系统通过批量处理查询来优化性能。这种策略减小了网络数据包的大小,并可能同时提高延迟和 QPS,从而提升系统的整体效率。
性能监控工具
我们将使用 Prometheus 来收集和分析 Milvus 性能。此外,我们还会使用 Grafana 的可视化界面来及时发现性能瓶颈问题。
如何发现性能瓶颈
以下流程图展示了如何使用 Grafana 来有效识别性能瓶颈。图中的黄色菱形框代表需要评估的决策点,浅蓝框则提示具体操作或更多详细信息。在文章接下来的部分中,我们将指导您按照流程图所示的每一步骤监控和诊断性能问题。
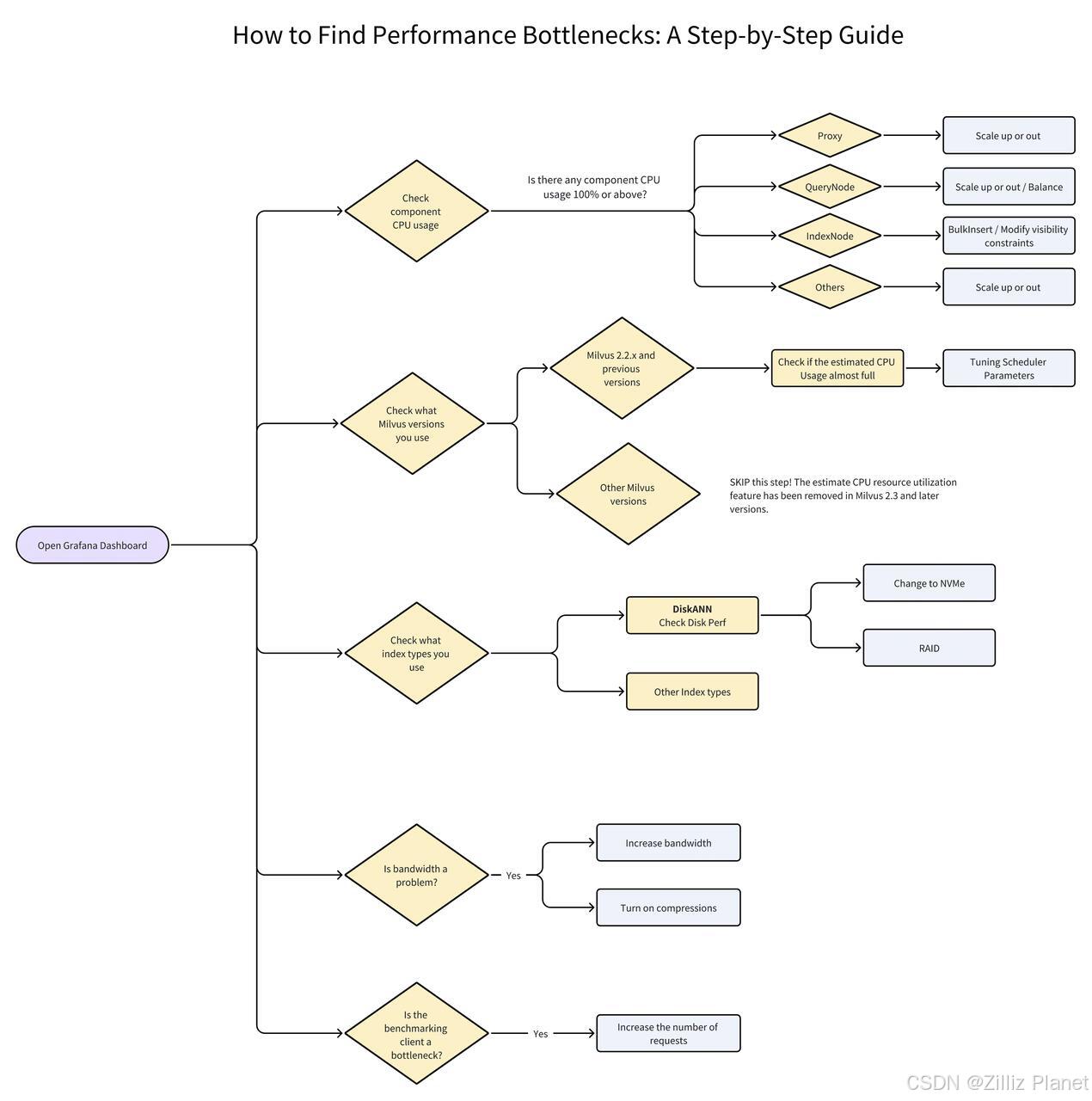
前提条件
在开始监控 Milvus 向量数据库的性能之前,请先在 Kubernetes 上部署监控服务,并通过 Grafana 仪表盘对收集的指标进行可视化处理。 更多详细信息,请查阅我们的相关文档页面:
重要提示:Grafana 的最小间隔会影响性能监控结果
在开始使用 Grafana 监控 Milvus 前,需要先注意 Grafana 中的最小显示间隔(Minimum interval)可能与设定的间隔不一致。因此,经过平均处理后,图表中的一些尖峰可能会变得更加平滑,或者甚至不再可见。
为了解决这个问题:
-
点击指标名称,选择 Edit (编辑)或按下 e 键。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1032
1032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









