









01
火热的多模态智能
回顾到2024的大型语言模型(LLM)的发展,让人欣喜的一点是scaling law依然奏效,智能随着资源的提高继续提高。但另一个让人担忧的点是高质量的文本语料似乎即将触及上限。为了加入更多的数据喂给模型,人们逐渐将目光转向除了文本之外的其他模态,还有这么多图像,音频,视频等其他模态数据没有像文本数据这样被充分利用起来。拥有了多模态能力的模型会对token在物理世界的原型有着更准确的理解,从而解锁除了纯文本之外的大量应用场景。2024年上半年,OpenAI发布了GPT-4o,Anthropic发布了 Claude 3,谷歌发布了Gemini1.5 Pro,苹果发布了端侧的多模态LLM Ferret-UI不约而同选择加强了其他模态的处理能力,这些产品级的大模型问世意味着“多模态”这个原本只在论文和高校中的时髦名词正变成一次又一次地API调用,促进着人们的生产,创作和学习。

02
组合图像检索(Composed Image Retrieval)
随着多模态大模型的逐渐成熟,多模态检索也开始获得了越来越多的注意力。多模态检索意味着用户的检索意图来自于多种模态的输入,最常见的情况是结合了来自文本端和图像端的输入。从图像搜索的角度来看,检索的相似性已经在大部分场景下满足了用户的需求,而一个更加具有想象力的需求是用户实际的检索意图和参考图片并不完全一致,最方便的表达这种差别的自然就是文字。而从文字检索图片的角度来看,当你的检索目标外观有了一定的限制,比起用冗长,准确的文字来去描述这个目标,不如用一张参考图片来表示这个目标,用剩下的文字进行补充说明。所以组合图像查询的一个典型场景就是用图片表达检索意图中细节最具体的一部分,用最可控的文本来去修正这个检索意图。
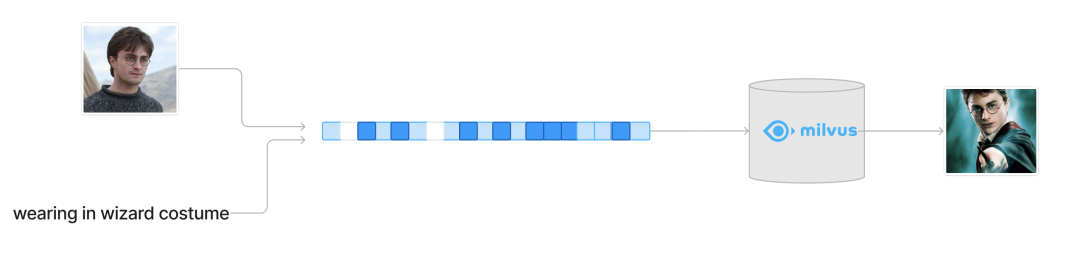
03
组合图像的方法简介
我们来介绍一些近两年在这个方向上的一些工作,近两年这个领域的方法逐渐朝着通用性(即zero-shot)的方向发展。因为CLIP带来通用的文图搜索能力,所以在训练数据少的情况下,主要的解决思路是将文本和图片的结合映射到CLIP的空间(从而巧妙地利用到了CLIP的通用性)。而如果资源足够多,那就可以朝着标注更多更准确的数据来去监督训练。此外,回顾历史,我们也可以发现,检索能力的提升,促进着数据标注的效率,数据质量的提升又提高着模型的能力,而模型的提升进一步促进着检索能力的提升,也是数据驱动的人工智能技术浪潮背后一次又一次的循环。

Pic2Word
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 442
442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









