









代理(Agent)系统能够帮助开发人员创建智能的自主系统,因此变得越来越流行。大语言模型(LLM)能够遵循各种指令,是管理 Agent 的理想选择,在许多场景中帮助我们尽可能减少人工干预、处理更多复杂任务。例如,Agent 系统解答客户咨询的问题,甚至根据客户偏好进行交叉销售。
本文将探讨如何使用 Llama-agents 和 Milvus 构建 Agent 系统。通过将 LLM 的强大功能与 Milvus 的向量相似性搜索能力相结合,我们可以创建智能且高效、可扩展的复杂 Agent 系统。
本文还将探讨如何使用不同的 LLM 来实现各种操作。对于较简单的任务,我们将使用规模较小且更价格更低的 Mistral Nemo 模型。对于更复杂的任务,如协调不同 Agent,我们将使用 Mistral Large 模型。
01.
Llama-agents、Ollama、Mistral Nemo 和 Milvus Lite 简介
Llama-agents:LlamaIndex 的扩展,通常与 LLM 配套使用,构建强大的 stateful、多 Actor 应用。
Ollama 和 Mistral Nemo: Ollama 是一个 AI 工具,允许用户在本地计算机上运行大语言模型(如 Mistral Nemo),无需持续连接互联网或依赖外部服务器。
Milvus Lite: Milvus 的轻量版,您可以在笔记本电脑、Jupyter Notebook 或 Google Colab 上本地运行 Milvus Lite。它能够帮助您高效存储和检索非结构化数据。
Llama-agents 原理
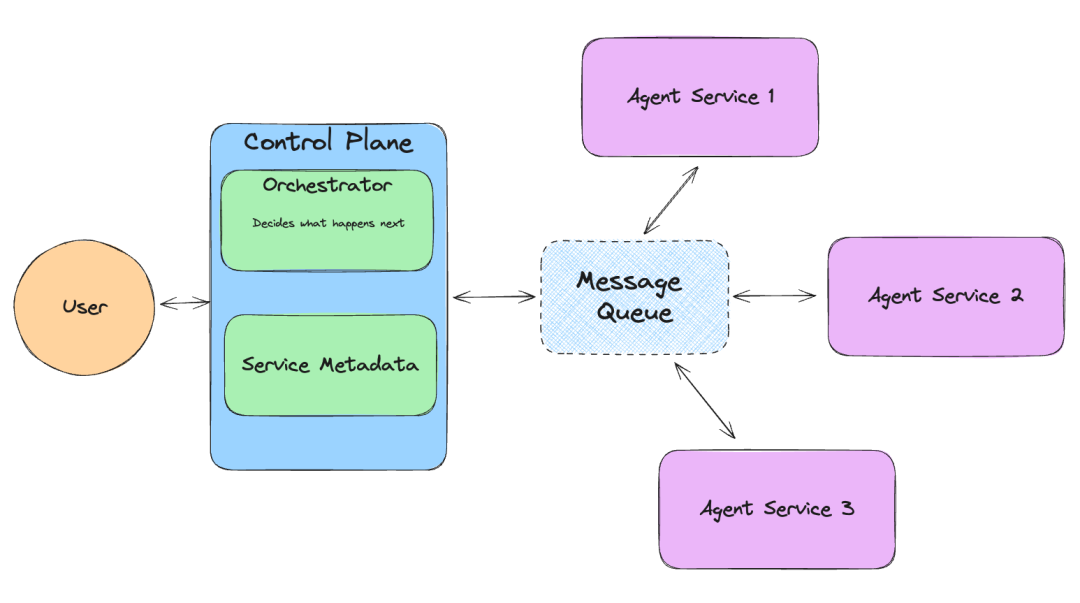
LlamaIndex 推出的 Llama-agents 是一个异步框架,可用于构建和迭代生产环境中的多 Agent 系统,包括多代理通信、分布式工具执行、人机协作等功能!
在 Llama-agents 中,每个 Agent 被视为一个服务,不断处理传入的任务。每个 Agent 从消息队列中提取和发布消息。
02.
安装依赖
第一步先安装所需依赖。
! pip install llama-agents pymilvus python-dotenv
! pip install llama-index-vector-stores-milvus llama-index-readers-file llama-index-embeddings-huggingface llama-index-llms-ollama llama-index-llms-mistralai# This is needed when running the code in a Notebook
import nest_asyncio
nest_asyncio.apply()
from dotenv import load_dotenv
import os
load_dotenv()03.
将数据加载到 Milvus
从 Llama-index 上下载示例数据。其中包含有关 Uber 和 Lyft 的 PDF 文件。
!mkdir -p 'data/10k/'
!wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/10k/uber_2021.pdf' -O 'data/10k/uber_2021.pdf'
!wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/10k/lyft_2021.pdf' -O 'data/10k/lyft_2021.pdf'现在,我们可以提取数据内容,然后使用 Embedding 模型将数据转换为 Embedding 向量,最终存储在 Milvus 向量数据库中。本文使用的模型为 bge-small-en-v1.5 文本 Embedding 模型。该模型较小且资源消耗量更低。
接着,在 Milvus 中创建 Collection 用于存储和检索数据。本文使用 Milvus 轻量版—— Milvus Lite。Milvus 是一款高性能的向量向量数据库,提供向量相似性搜索能力,适用于搭建 AI 应用。仅需通过简单的 pip install pymilvus 命令即可快速安装 Milvus Lite。
PDF 文件被转换为向量,我们将向量数据库存储到 Milvus 中。
from llama_index.vector_stores.milvus import MilvusVectorStore
from llama_index.core import Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex, StorageContext, load_index_from_storage
from llama_index.core.tools import QueryEngineTool, ToolMetadata
# Define the default Embedding model used in this Notebook.
# bge-small-en-v1.5 is a small Embedding model, it's perfect to use locally
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-en-v1.5"
)
input_files=["./data/10k/lyft_2021.pdf", "./data/10k/uber_2021.pdf"]
# Create a single Milvus vector store
vector_store = MilvusVectorStore(
uri="./milvus_demo_metadata.db",
collection_name="companies_docs"
dim=384,
overwrite=False,
)
# Create a storage context with the Milvus vector store
storage_context = StorageContex 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 443
443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









