









自 20 个月前 ChatGPT 革命性的推出以来,生成式人工智能(GenAI)领域经历了显著的发展和创新。最初,大语言模型(LLMs)和向量数据库吸引了最多的关注。然而,GenAI 生态系统远不止这两个部分,它更加广泛和复杂。向量数据库是是赋能 GenAI 应用的关键基础设施,作为其构建者我对于快速的技术进步及向量数据库对行业的影响感到非常兴奋。在本文中,我想回顾一下,并分享对 GenAI 生态系统现状的一些思考。
生成式 AI 应用大致可以分为两种主要类型:检索增强生成(RAG)和多媒体生成。RAG 结合了信息检索技术与生成式语言模型,以产生相关且连贯的输出。另一方面,多媒体生成利用生成式模型创造复杂的视觉内容,包括创意广告和数字孪生(Digital twins)。
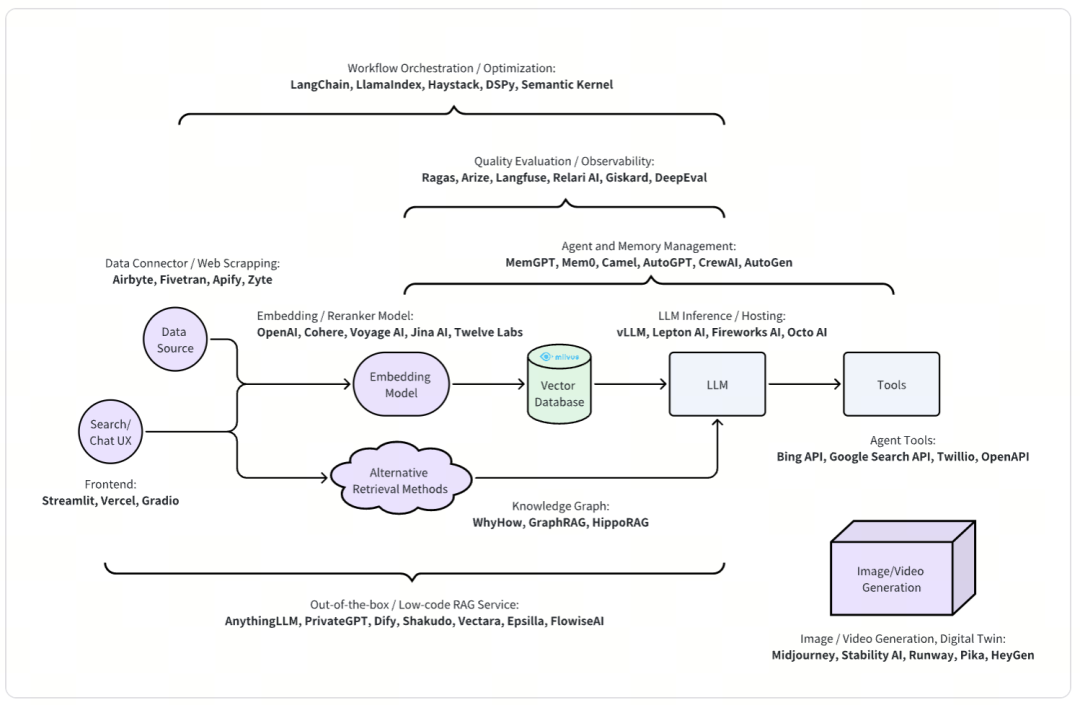
检索增强生成(RAG)
检索增强生成(Retrieval-Augmented Generation, RAG)是当前 GenAI 领域中非常流行的一种应用。RAG 系统通常由数据清洗、Embedding 模型、向量数据库和 LLM 等组件构成。更高级的生产级 RAG 系统通常包括额外的组件来增强质量和用户体验。
典型的搜索系统可以分为两个主要部分:离线索引部分和在线查询服务部分。类似地,RAG 包括索引阶段和在线查询服务阶段:
-
索引阶段:索引阶段涉及从各种来源获取数据,包括数据库、API 和文件系统。这些数据经过文件解析和文本分块处理,为分析做准备。处理后,数据被 Embedding 到适当的格式,并加载到向量数据库中,以便有效检索。一些 RAG 系统甚至采用高级数据挖掘技术,如标签提取、知识图谱构建和摘要,以丰富数据并改进检索过程。
-
服务阶段:在线查询服务阶段专注于理解用户的查询意图,并采用各种检索方法,包括向量相似性搜索,以找到最相关的信息。检索结果随后被发送到 LLM 进行生成。在这一步中,LLM 基于检索到的数据生成连贯且符合上下文的输出。此外,LLM 还可以作为代理,利用外部工具来增强其能力,并提供更全面和准确的响应。
因此,许多编排项目提供了各种组件的实现和配置选项。架构的复杂性也要求系统既要作为白盒也要作为黑盒进行评估,这促进了评估框架的发展。
每个组件还吸引了旨在构建更好、更丰富功能的开发者,例如每个数据源的 Connector 和针对特定用例量身定制的 Embedding 模型。LLM 推理框架为 LLM 提供了更灵活的部署选项,不仅仅是 API 服务。此外,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 778
778

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









