








2024年,各种大模型轮番登场,但是从体感上来说,带给大家的智能体验边际效益却在逐步减少。
直到9月13号,OpenAI发布了一个全新的模型o1-preview。不同于之前的LLM在接收到问题后会立刻开始回答,o1-preview回像一位侦探一样先分析问题,再将问题拆解成一系列子问题,然后分析每个子问题可以用哪些方案,并评估每个方案的可行性,遇到了阻碍之后o1-preview还会尝试换一种思路解决问题。在所有的情报收集完毕后,才缓缓地开始吐出答案的第一个字。
这种被称为“推理scaling law”的技术重新让大家感受到了大模型智能程度的质的提升。在"快思考"受限于数据和算力短期内无法快速突破的时候,这种让思考慢一些的思路,带来了意想不到的效果。
虽然外界现在对于o1-preview的具体做法并不清楚,但是经过各方讨论形成的一个共识是:这类模型通过强化学习可以让模型自己产生思维链(也即是思路),进而规划出解决问题的路径,并且在发现错误时反思错误原因,甚至质疑问题的合理性(条件中是否存在错误),这让o1-preview不仅在各种智力测试中取得了优异的成绩,也同时展现了大模型在“预训练暴力出奇迹”之外的“推力侧思考能力进化”,进而展现出了LLM在探索前沿科学问题中的潜力。
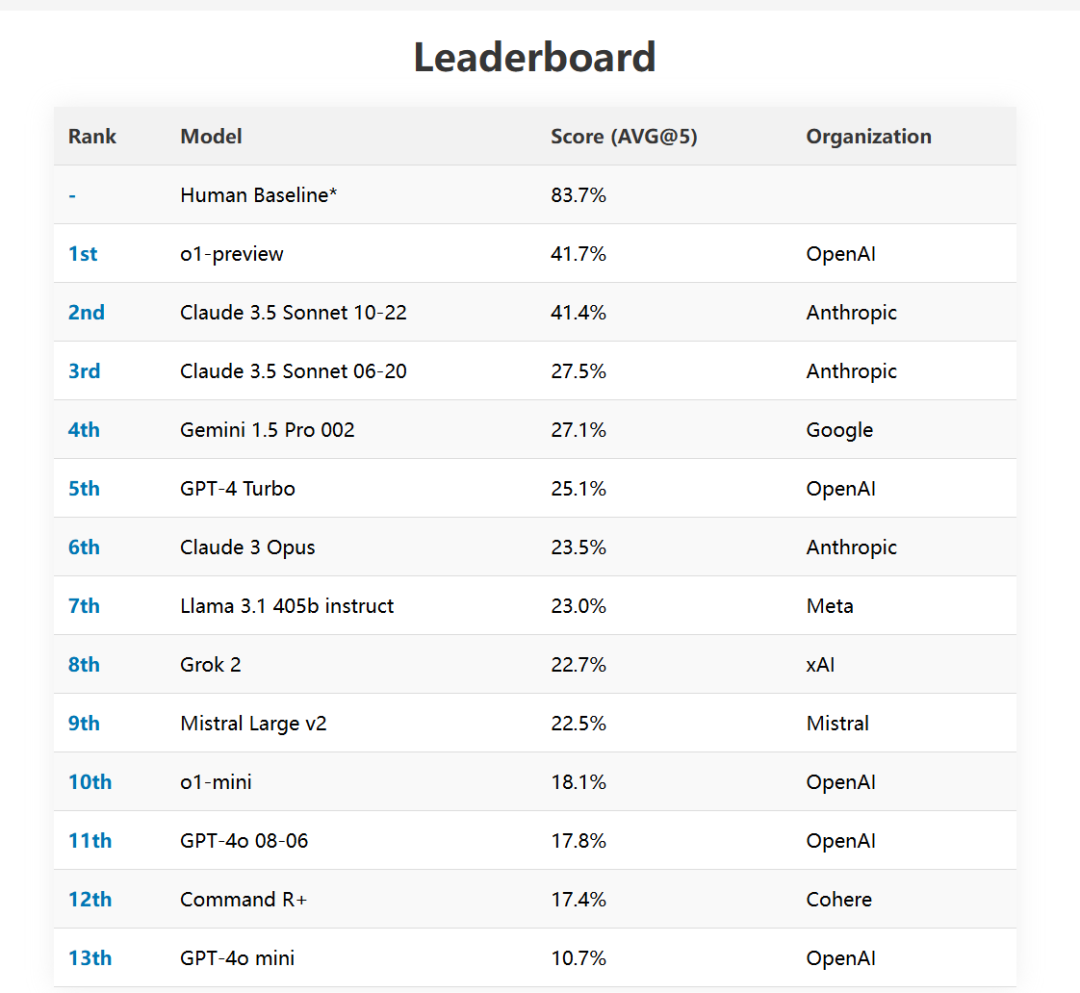
SimpleBench的结果
基于这种“思考能力”的进化,o1在独立解决复杂问题、长链路问题上的能力提升,也是其核心亮点之一。
在2023年GPT4刚问世时,拥有视觉能力的大模型激发了开发者无尽的想象力。但是,如何让大模型,根据我们画好的UI,自动写出一个完整的应用,即使如今最先进的GPT-4o,也很难独立完整实现,需要人工将这一复杂问题,拆解成若干子问题,来一步步交互式地让大模型辅助完成。而现在的o1-preview已经可以完整编写一个小型程序,或者一个大程序的子模块。
再比如,过去的GPT-4o尽管已经拥有很强的视觉感知能力,但是依然无法处理复杂的视觉推理任务,一是其缺乏对空间中的细节与位置感知,二是对于推理类的问题容易出现幻觉和方差较大的情况(例如根据query对于一系列图像结果打分排序)。而这些会使得模型在理解信息密度较高的示意图(例如软件的截图,论文里的图示)时遇到困难。
但是,最近有网友意外发现,带有视觉能力的o1,曾在OpenAI的官网短暂上线,并展示出了不少基于图片的完整推理与思考能力。
接下来,让我们根据网友的分享来提前感受一下o1完全体的魅力。
案例一:请分析这张图片
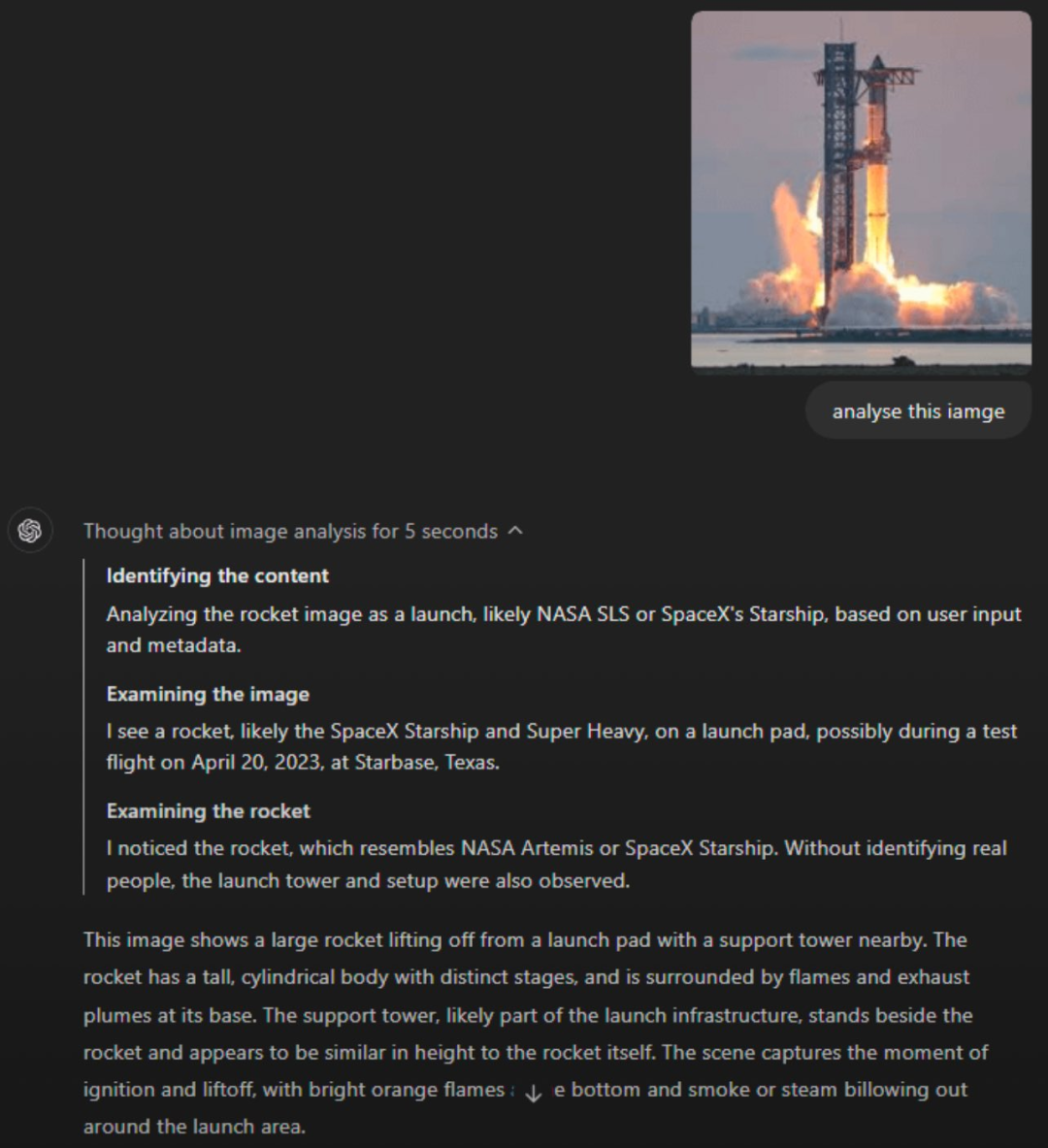

可以看到,这个回答展示出了o1的强大的视觉分析能力,识别出这个发射的火箭是星舰,并且对图片中每部分的详细信息都进行了描述与介绍。
案例二:钟表上的时间是多少?

从这个回答上,似乎可以看出目前的o1用着和GPT-4o相似的图像编码器,并且o1无法确定时针的具体位置,从而无法完成从时钟图像中读取时间的任务。
这也说明了即使是当前最先进的VLM与推理技术,也依然无法处理细粒度较高的定位问题,对于细节的感知能力也同样存在短板。
案例三:请描述这种图像的详细内容
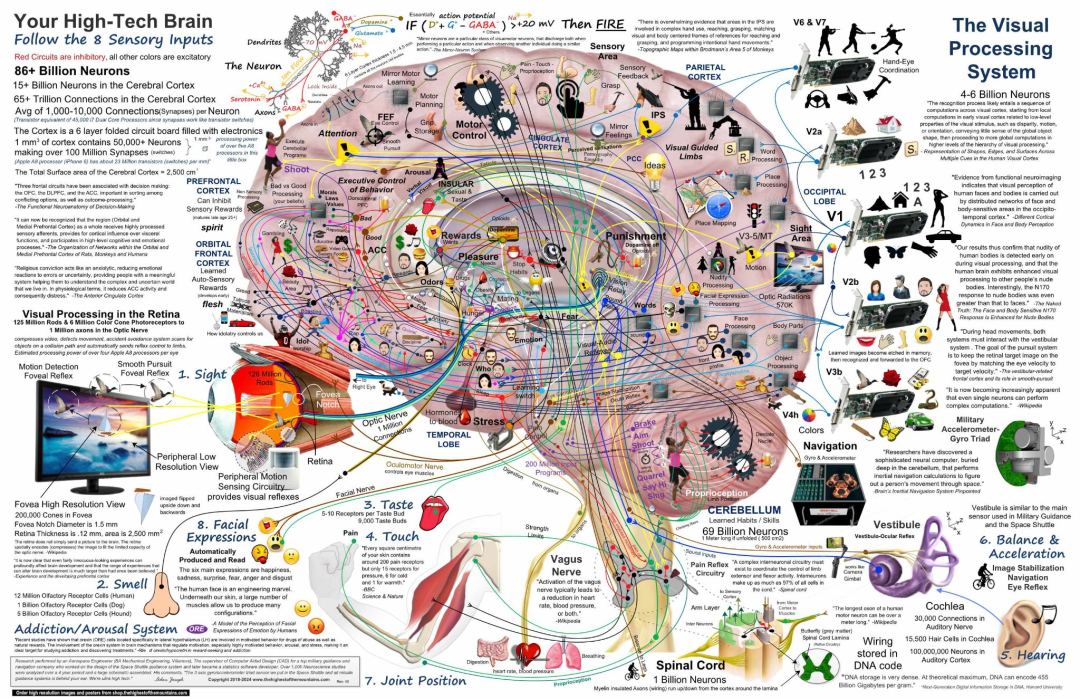
回答:完整请参见这里 https://github.com/DannyMac180/conversations/blob/main/o1-full-first-contact-2024-11-02.md
这张图是一张非常复杂,信息量巨大的图,o1详尽全面地列出了这张图对于脑结构的各个部分的描述,不过,整体来说,这个问题还是偏向于图像OCR的层面,但是值得注意的是,在原本的图片中文字OCR的基础上,o1还指出了
红线表示抑制回路,而其他颜色的线(蓝色、绿色、紫色、橙色等)表示兴奋回路。每个标记区域或通路都有图标或小图形来描述其功能或相关概念:
例如,“惩罚”区域包含负面表达或警告的图标。
“快乐”和“奖励”系统区域有笑脸或积极的图像
当然,鉴于这张图过于复杂,根据第二个例子中展现的o1对于图像细节的感知情况,让o1在没有文字提示的情况下,分析这种包含大量隐含信息的图像还是难度过高,不过,相信在有了足够的精标数据后,这一问题会在不远的未来被解决。
总结来说,o1本身最大的升级两点是分析与思考能力,它会反思,也会去探索解决问题的途径,并且会在收到反馈后制定新的计划,这是原先的各种agent框架很难做到的事情(它们很容易在几次尝试后把注意力完全转移到原始问题无关的地方,甚至会在陷入某个失败的循环中)。
模型的智能程度提升,是一个多条路径并举的过程,过去业界普遍押注的路线是算力和数据上的scaling law,但o1告诉我们scaling law并不是只局限在模型预训练阶段。
那么为了能够找到通往智能的路径上,我们还需要scaling什么?
推出o1的同时,OpenAI也推出了ChatGPT Search,通过LLM访问互联网上的信息来获取回答,这类的产品当前已经被大众所熟识。此外,去年也已出现了类似AutoGPT、BabyAGI这样的项目,利用agent来自主地让LLM通过寻找资料来解决问题。但是由于利用prompt engineering实现的agent技术很难克服一些固有缺陷,比如在“反思”“试错”能力上的缺失,导致这样的agent在落地时往往容易出现,在某个无法解决的问题上不断撞南墙进而形成死循环。
这两种方式是否能够对其进行融合取长补短呢?
答案是肯定的。
长期来看,随着o1这种具备自主路径规划能力的多模态大模型开始普及,智能的来源将从传统的完全通过预训练增加知识,向分出一部分资源往推理侧增加思考能力的方向转变。在推理过程中更多更复杂的检索也是一个放大推理规模的途径。在这一过程中向量数据库将发挥更加重要的作用,一方面是由智能体的自主检索带来的检索量的增加,另一方面则是对于图像推理过程中多模态检索需求的提升(获取训练时没有见过的数据信息)。在这一过程中,通过高性能数据库、RAG以及多模态检索的模式,补足其专业知识能力短板(比如案例三中的人类大脑结构等),相信在不久的未来,智能体的能力将出现进一步的提升。
作为全球广受欢迎的开源向量数据库,Milvus 具备处理数百万乃至数十亿级的向量数据的能力;Milvus 原厂打造的商业化产品Zilliz Cloud ,则能为用户提供百亿级向量数据毫秒级检索能力与开箱即用的向量数据库服务,是开发者们对大模型进行专业知识补足的重要工具。
作者介绍

王翔宇
Zilliz 算法工程师



















 500
500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









