






服务雪崩
微服务架构中服务的调用是链式的,一旦其中一个服务出现问题,可能导致整个服务调用链条是失效。
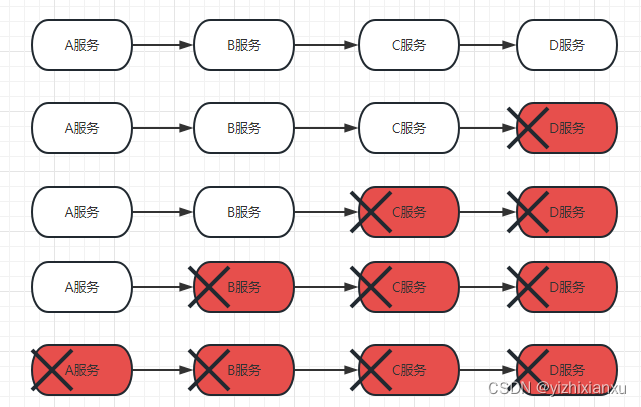
可能造成服务雪崩的原因
- 硬件问题:出现天灾人祸。解决:异地多活(在不同的地方部署多台服务器),多机房容灾等。
- 软件bug:死锁、死循环、异常。解决:测试,代码评审。
- 网络问题:网络连接,网络失效。解决:升级网络,加入网络超时
- 流量激增:某服务器访问数突然增加。解决:限流
- 缓存失效:解决:缓存并发问题处理、集群、双检锁、布隆过滤器
- 同步等待:解决:设置熔断、返回兜底数据
Hystrix熔断器的作用
SpringCloud Netflix网飞公司提供的的熔断器,为了解决服务雪崩造成服务不可用的问题
重要功能:
- 资源隔离:线程池隔离和信号量隔离,每个服务调用都是独立的,不相互影响
- 优雅的降级机制:当资源不足或者调用超时进行降级,调用降级返回兜底数据。
- 熔断:服务调用失败率超过一定的阈值,触发熔断。快速返回
- 请求缓存和监控、报警等。
Hystrix熔断器的使用
1.导入Hystrix依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
2.在启动类上加@EnableHystrix注解
3.在需要熔断的地方加@HystrixCommand
4.设置降低方法返回兜底数据
//调用方法超过一秒会触发熔断,调用降级方法
@HystrixCommand(fallbackMethod = "getOrderByIdFallback")
@Override
public Order getOrderById(Long id) {
Order order = orderMapper.selectById(id);
//改用Eureka后,调用时使用服务注册名称调用
ResponseEntity<Product> entity = restTemplate.getForEntity(
"http://product-service/product/" + order.getProductId(),
Product.class);
order.setProduct(entity.getBody());
return order;
}
/**
* 降级方法
* @param id
* @return
*/
public Order getOrderByIdFallback(Long id) {
// 返回兜底数据
Order order = new Order();
return order;
}熔断时间的设置(默认为1s)
# 设置熔断时间
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=3000
Hystrix的资源隔离机制
Hystrix对服务消费者调用的每个方法(加@HystrixCommand注解),单独配置资源,互不影响
隔离机制有两种:
1.线程池隔离
每一个方法单独开一个线程池,可以通过线程数来控制并发量,请求超过一定的线程量后,进入等待队列慢慢处理。
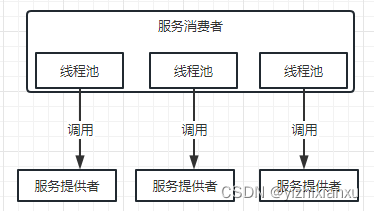
优点:
-
可以控制并发量,削峰
-
异步处理,效率高
缺点:
-
占用系统资源大
-
线程池控制比较复杂
2.信号量隔离
每个方法有一个信号量,请求数一旦超过阈值,就直接放弃
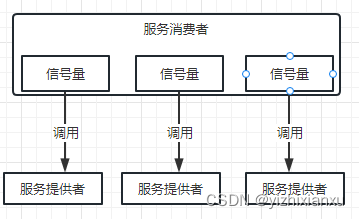
优点:
-
占用资源少
-
控制简单
缺点:
-
功能简单,请求不能等待
-
同步处理,执行效率低
配置方法
# 设置隔离策略 THREAD\SEMAPHORE
hystrix.command.default.execution.isolation.strategy=THREAD















 158
158











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









