







全文一览
一、前言
1.1 需求来源
很多英雄联盟的元老级玩家都认可 LOL 的美工做得很好,不乏玩家将英雄的皮肤设为手机、电脑的壁纸或个人社交账号的头像。
作为 LOL 发烧友,如果想每天换一张电脑壁纸,该如何爬取 LOL 全英雄的全部皮肤呢?由于皮肤数量过多,最好能按英雄名分文件夹存储,找起来也比较方便。
1.2 准备工作
python:3.11.3(≥3.7)
selenium 库:4.9.1
Firefox 浏览器:114.0.2 (64 位)
geckodriver:geckodriver-v0.33.0-win64.zip
如何安装 geckodriver?
1.3 思路解析
LOL 英雄界面上有全部英雄的信息,点击头像图片,可以进入个英雄主页,点击主页下的一排小图标,可以切换不同的皮肤,右键皮肤可以查看高清皮肤的下载链接。
其中,英雄主页可以由英雄的 id (后端设定)来映射;高清皮肤的链接跟小图的链接可以互相转换。
1.4 算法流程设计
1). 从 LOL 英雄界面获取每个英雄的全名和 id
2). 遍历全部英雄,对每个英雄:
① 根据全称创建文件夹
② 根据 id 定位到主页面
③ 获取全部皮肤小图标的链接
④ 将小图标链接转化为高清皮肤链接
⑤ 将高清皮肤保存到该英雄的文件夹中
1.5 算法实现方案
1). 使用列表保存数据用于遍历
2). 使用 webdriver(geckodriver)获取网页信息、定位元素、下载资源
3). 使用 try-except 处理异常情景
4). 使用 time.sleep 反爬
5). 使用 str.replace 替换 “K//DA” 中特殊字符
二、代码解析
2.1 获取全部英雄姓名、id
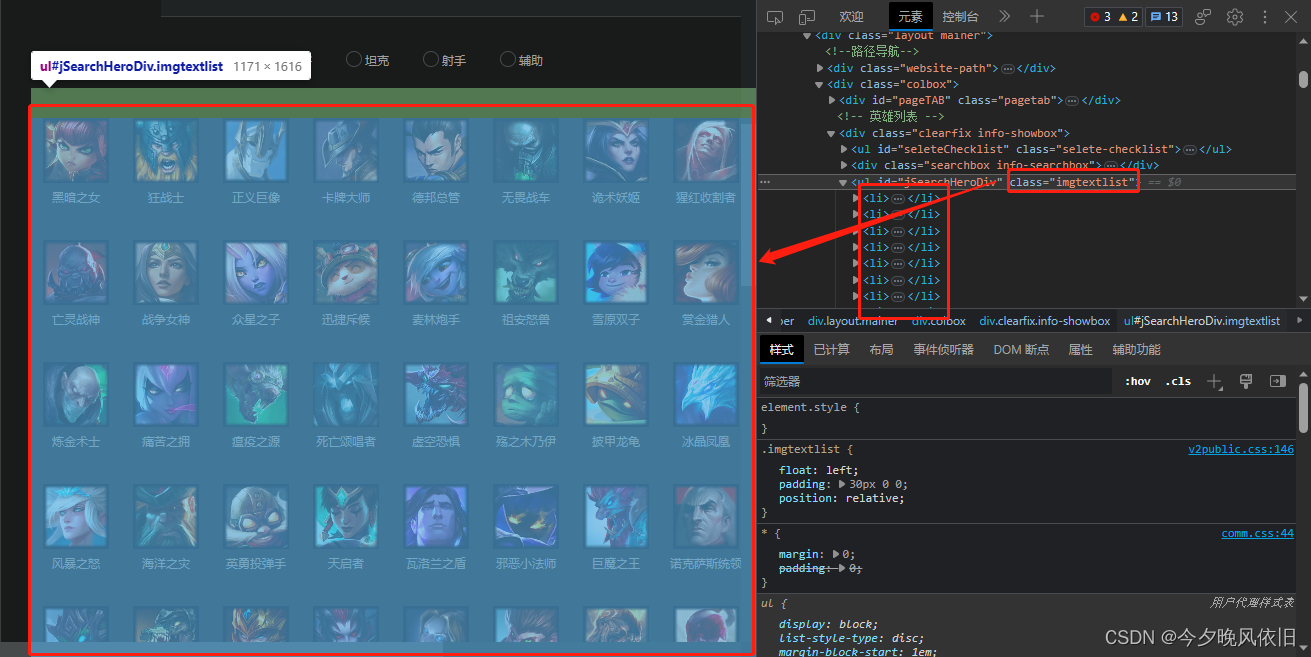
使用 “imgtextlist” 类定位到全部英雄的元素块,再获取所有 “li” 标签的信息,存入列表中等待进一步解析。
# 获取全部英雄概览信息
def getHeros(driver):
# 英雄联盟英雄信息前置界面
driver.get('https://lol.qq.com/data/info-heros.shtml')
# 获取全部英雄的信息概览
heros_res = driver.find_element(By.CLASS_NAME, "imgtextlist")
# 获取每个英雄信息的列表
heros = heros_res.find_elements(By.TAG_NAME, "li")
return heros
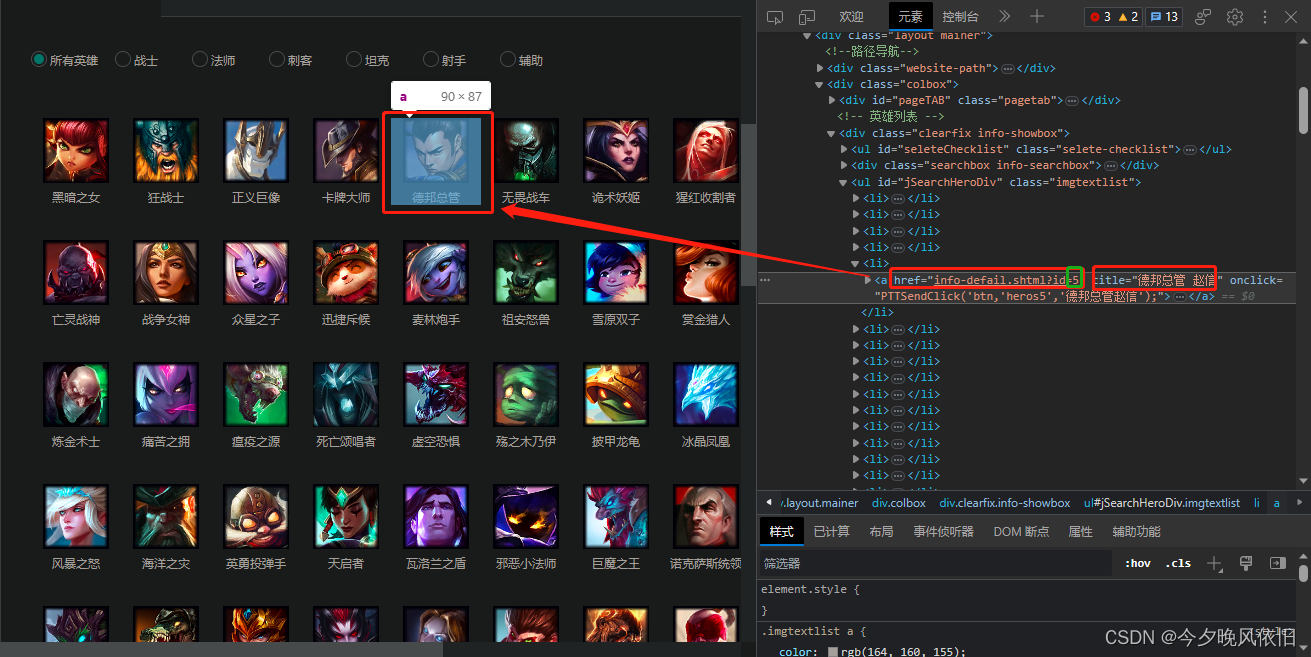
进一步解析可以获得英雄的全称和 id ,这里使用两个函数分别返还结果:
# 获取英雄名称,用于单独建立文件夹存储
def getHerosName(heros):
hero_name = [] # 记录英雄全名,如“德邦总管 赵信”
for h in heros:
hero_name.append(h.find_element(By.TAG_NAME, "a").get_attribute("title")) # 获取英雄全名
print("hero_name:", hero_name)
return hero_name
# 获取英雄排名id,用于后续获取皮肤图片等
def getHerosId(heros):
hero_id = [] # 记录英雄的排名id
for h in heros:
hero_href = h.find_element(By.TAG_NAME, "a").get_attribute("href") # 获取英雄个人链接
hero_id.append(hero_href.split('=')[1]) # 获取英雄的排名id
return hero_id
注意:获取id是很重要的,因为id并不是和英雄的推出顺序是一致的,如新英雄明烛的id是902,而LOL显然没有那么多英雄。获取皮肤是必须要有英雄id的。(不知道这是不是官方刻意设置的一种反爬机制?)也可以直接保存英雄的跳转链接进行跳转。
2.2 遍历全部英雄
total_num = len(hero_name)
for i in range(total_num):
2.2.1 创建各英雄的文件夹
# 为每一个英雄单独创建文件夹,来保存皮肤
def createPath(name):
global savePath
filepath = f"{savePath}{name}\\" # 为每一个英雄单独创建一个路径,以其全名命名
if not os.path.exists(filepath):
os.makedirs(filepath)
print(filepath + "文件夹创建成功!")
2.2.2 根据 id 定位到主页面
根据 id 跳转到英雄主界面:
url = "https://lol.qq.com/data/info-defail.shtml?id=" + str(n) # 根据 id 可以获取英雄的个人链接
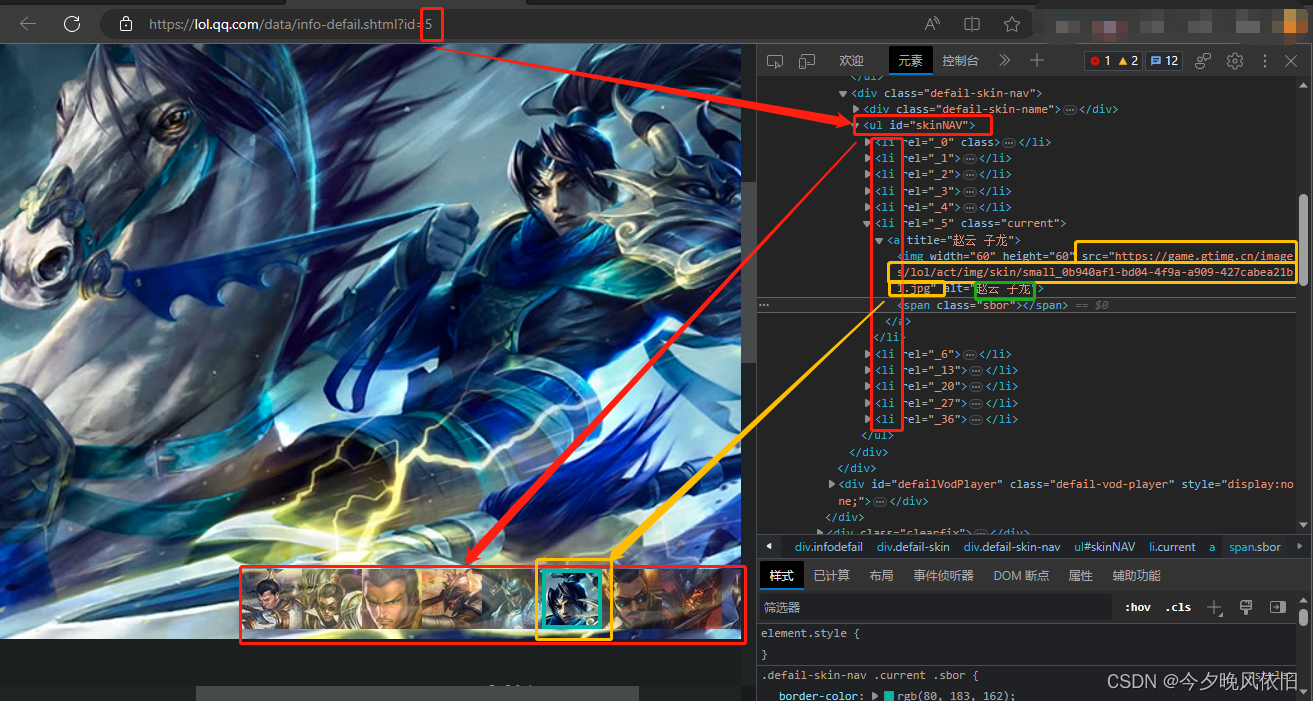
进而可以定位到小图标及其链接:
driver.get(url)
skins_res = driver.find_element(By.ID, "skinNAV") # 定位到皮肤栏
skins = skins_res.find_elements(By.TAG_NAME, "img") # 获取小图标的列表
for skin in skins:
skin_name = skin.get_attribute("alt")
skin_link_small = skin.get_attribute("src") # 获取每个小图的链接
# https://game.gtimg.cn/images/lol/act/img/skin/small_0b940af1-bd04-4f9a-a909-427cabea21b1.jpg
2.2.3 转换小图标链接为高清图链接
小图标的链接为:
https://game.gtimg.cn/images/lol/act/img/skin/small_0b940af1-bd04-4f9a-a909-427cabea21b1.jpg
高清图的链接为:
https://game.gtimg.cn/images/lol/act/img/skin/big_0b940af1-bd04-4f9a-a909-427cabea21b1.jpg
通过简单的字符串替换即可实现:
skin_link_big = str(skin_link_small).replace("small", "big") # 替换为大图的链接
# https://game.gtimg.cn/images/lol/act/img/skin/big_0b940af1-bd04-4f9a-a909-427cabea21b1.jpg
2.2.4 保存高清皮肤图片
给图片确定存储路径时,要考虑 “K/DA” 字符串的影响,替换掉 “/” 为 “” 避免识别为路径而报错:
filename = f"{savePath}{hero_name[i]}\\{str(skin_name).replace('/', '')}.jpg" # 防止 K/DA 下载出错
之后就可以开始下载了:
try:
urlretrieve(skin_link_big, filename=filename)
except urllib.error.ContentTooShortError:
driver.sleep(5)
urlretrieve(skin_link_big, filename=filename)
except:
print("未知错误!")
print(skin_name + "图片下载完成!") # 输出提示:英雄的该个皮肤图片下载完成
三、运行截图
运行过程中打印提示数据:
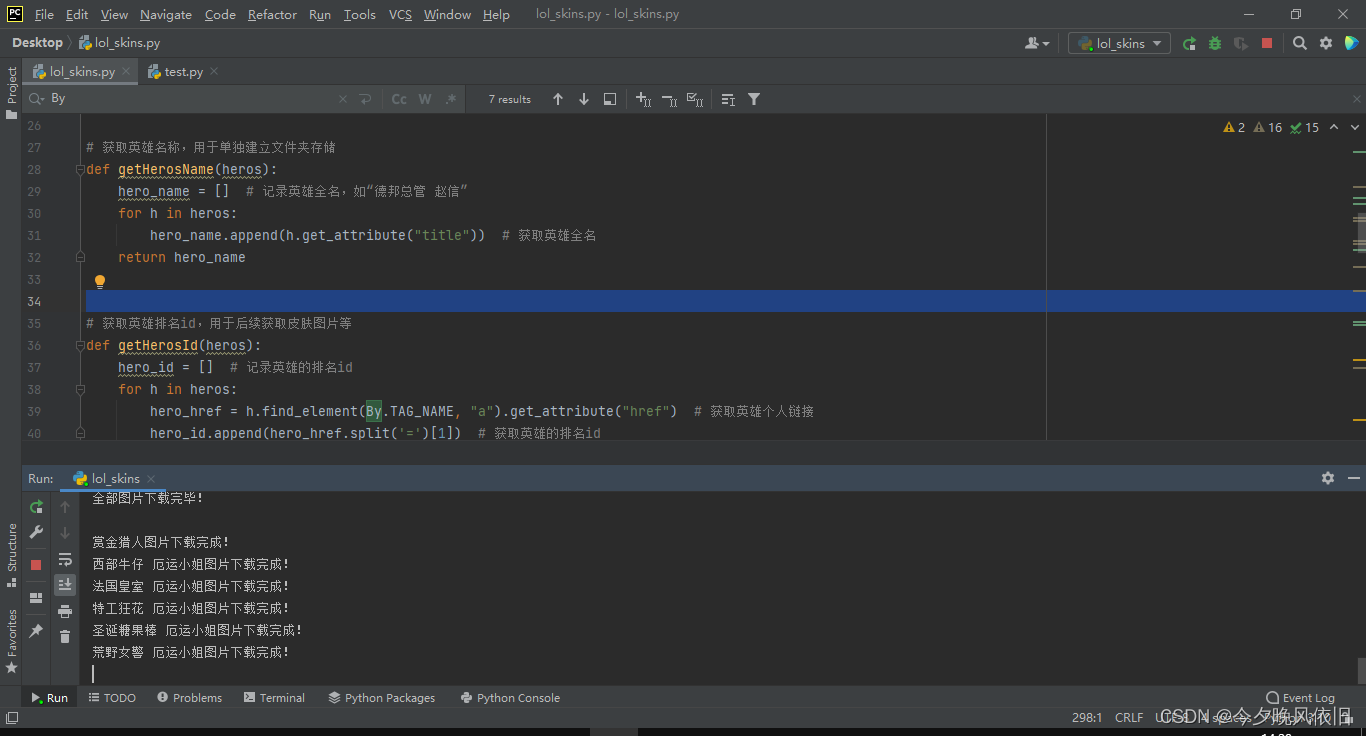
文件夹中查看保存皮肤:
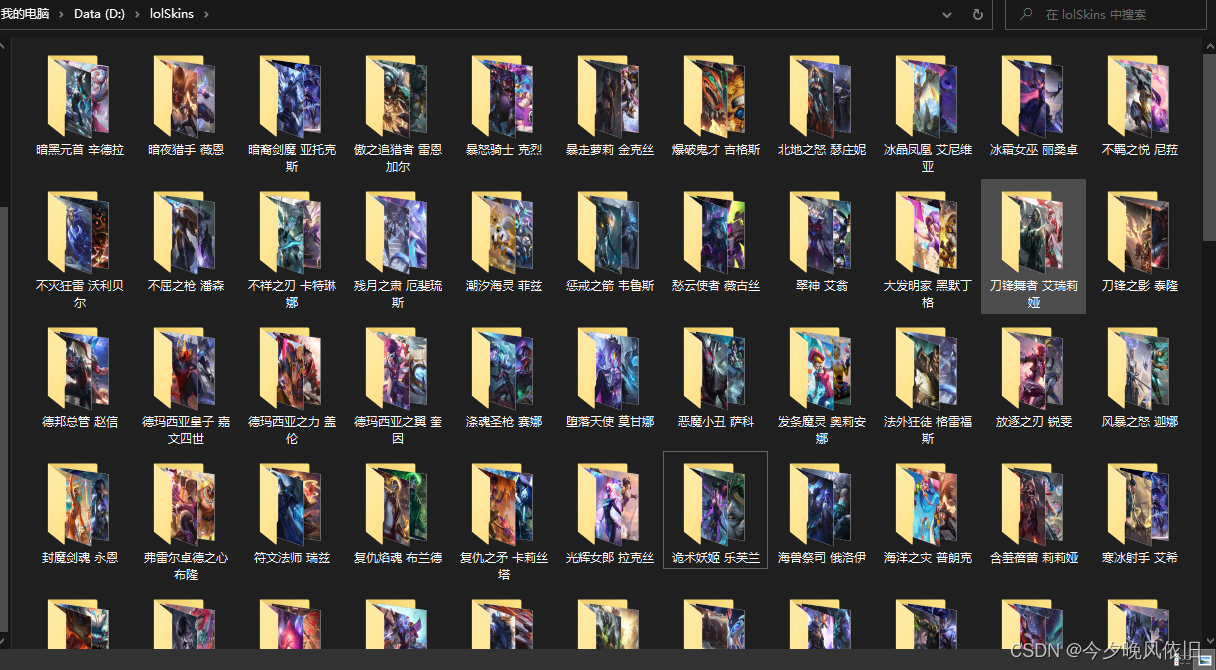
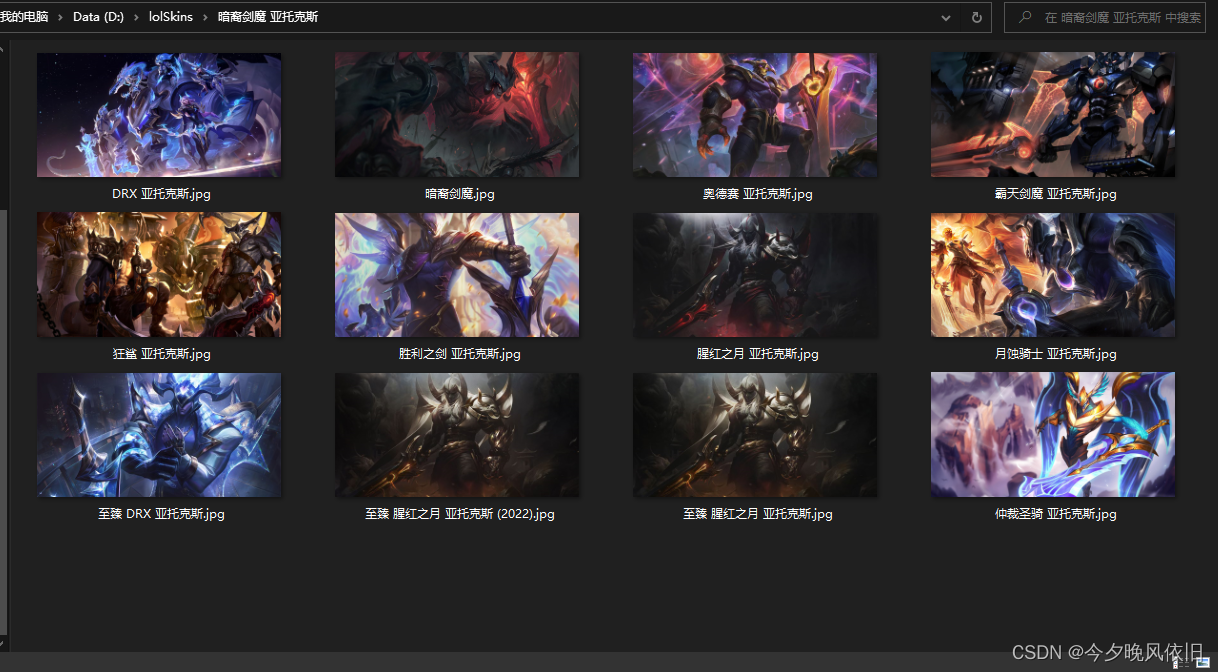
四、完整代码
import os
import time
import urllib
from selenium import webdriver
from urllib.request import urlretrieve
from selenium.webdriver.common.by import By
# 模拟请求头
user_agent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/" \
"605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15"
# 配置 webdriver
opt = webdriver.FirefoxOptions()
opt.add_argument('--user-agent=%s' % user_agent)
# opt.add_argument("--headless") # 开启此选项,浏览器不会显示动作
# 获取全部英雄概览信息
def getHeros(driver):
# 英雄联盟英雄信息前置界面
driver.get('https://lol.qq.com/data/info-heros.shtml')
# 获取全部英雄的信息概览
heros_res = driver.find_element(By.CLASS_NAME, "imgtextlist")
# 获取每个英雄信息的列表
heros = heros_res.find_elements(By.TAG_NAME, "li")
return heros
# 获取英雄名称,用于单独建立文件夹存储
def getHerosName(heros):
hero_name = [] # 记录英雄全名,如“德邦总管 赵信”
for h in heros:
hero_name.append(h.find_element(By.TAG_NAME, "a").get_attribute("title")) # 获取英雄全名
print("hero_name:", hero_name)
return hero_name
# 获取英雄排名id,用于后续获取皮肤图片等
def getHerosId(heros):
hero_id = [] # 记录英雄的排名id
for h in heros:
hero_href = h.find_element(By.TAG_NAME, "a").get_attribute("href") # 获取英雄个人链接
hero_id.append(hero_href.split('=')[1]) # 获取英雄的排名id
return hero_id
# 为每一个英雄单独创建文件夹,来保存皮肤
def createPath(name):
global savePath
filepath = f"{savePath}{name}\\" # 为每一个英雄单独创建一个路径,以其全名命名
if not os.path.exists(filepath):
os.makedirs(filepath)
print(filepath + "文件夹创建成功!")
# 获取英雄皮肤,规避反爬机制,并进行异常处理
def getAndSaveSkins(driver, hero_name, hero_id):
global savePath
# 遍历全部英雄
total_num = len(hero_name)
for i in range(total_num):
createPath(hero_name[i]) # 为每个英雄单独开辟一个文件夹
n = hero_id[i] # 提取英雄对应的id。注意:id 和 name 列表顺序并不是一一对应的,因此有必要单独获取
driver.implicitly_wait(10)
url = "https://lol.qq.com/data/info-defail.shtml?id=" + str(n) # 根据 id 可以获取英雄的个人链接
driver.get(url)
skins_res = driver.find_element(By.ID, "skinNAV") # 定位到皮肤栏
skins = skins_res.find_elements(By.TAG_NAME, "img") # 获取小图标的列表
for skin in skins:
skin_name = skin.get_attribute("alt")
skin_link_small = skin.get_attribute("src") # 获取每个小图的链接
# https://game.gtimg.cn/images/lol/act/img/skin/small_0b940af1-bd04-4f9a-a909-427cabea21b1.jpg
skin_link_big = str(skin_link_small).replace("small", "big") # 替换为大图的链接
# https://game.gtimg.cn/images/lol/act/img/skin/big_0b940af1-bd04-4f9a-a909-427cabea21b1.jpg
filename = f"{savePath}{hero_name[i]}\\{str(skin_name).replace('/', '')}.jpg" # 防止 K/DA 下载出错
try:
urlretrieve(skin_link_big, filename=filename)
except urllib.error.ContentTooShortError:
driver.sleep(5)
urlretrieve(skin_link_big, filename=filename)
except:
print("未知错误!")
print(skin_name + "图片下载完成!") # 输出提示:英雄的该个皮肤图片下载完成
print("************" + hero_name[i] + "全部图片下载完毕!************\n") # 输出提示:该英雄的全部高清皮肤下载完成
# time.sleep(2) # 设置时间间隔,规避反爬机制
if __name__ == "__main__":
savePath = "D:\\lolSkins\\"
driver = webdriver.Firefox(options=opt) # 启动 webdriver
# 如果 driver 文件没有放在系统路径下,可以指定文件路径,也可以不带“.exe”
# driver = webdriver.Firefox(executable_path='D:/driver/geckodriver.exe', options=opt)
# 新版 selenium 推荐使用 service 写法。个人推荐第一种,把 webdriver 放在系统路径下
# service = Service(executable_path=executable_path='D:/driver/geckodriver.exe')
# driver = webdriver.Firefox(service=service,options=opt)
driver.implicitly_wait(10) # 设置界面等待的最长时间
heros = getHeros(driver) # 获取英雄信息概览
hero_name = getHerosName(heros) # 获取英雄名,用于存储皮肤
hero_id = getHerosId(heros) # 获取英雄id,用于爬取皮肤
getAndSaveSkins(driver, hero_name, hero_id) # 获取皮肤并保存到对应的文件夹中
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}
{kind=link}